【演讲实录】RWP团队谈SQL优化
2018-01-10 15:01
162 查看
点击有惊喜
设定一个高的目标

如果您把一个SQL从一个小时优化到了1分钟,您会停止工作吗?会不会考虑是否能给它优化到1秒钟?
工作中,每个人都有压力,压力之下,很容易疏于思考。一个SQL多长时间能跑完,依赖于它跑在什么样的硬件和软件环境上。一个SQL能不能跑的更快,本质上是:它是否能够更加充分的利用硬件资源和软件能力。
做SQL优化,给自己设定一个高的目标非常重要!
去优化那些好的SQL

有了高的目标,接下来,还要找到那些好的SQL进行优化。那么,什么是好的SQL?
(1)有效的 SQL
数据库是为了执行SQL设计的,不是为了一执行就报错的无效SQL设计的。
如果执行一个SQL,报ORA的错误,那么这是一个无效的SQL,它不应该存在于您的系统里面,当然更不应该成为您优化的对象。
如果执行一个SQL,报ORA的错误,那么在数据库里面会是一个failure parse。如果您系统的AWR报告里面有failure parse,那么您要注意了,后果可能很严重。
(2)您知道业务含义的SQL
有很多时候,一些SQL和PL/SQL存储过程是根本就不需要被执行的。但是由于种种原因,那些SQL和PL/SQL存储过程存在在系统中,可能都已存在了很长时间,写那些SQL和PL/SQL存储过程的人可能早就跳槽了,为了所谓的“稳定”,没有人去动那些SQL和PL/SQL存储过程。去优化这些根本就不需要被执行的SQL和PL/SQL存储过程当然是没有任何意义的。
所以,在优化任何一条SQL之前,应该首先知道那条SQL业务上的含义,确定它确实是需要被执行的,再去优化它。
(3)构造好的SQL
如果一个SQL语句里面有IN列表,IN列表里面有几百个值,那么那几百个值,很有可能是来源于另外一个SQL,而非人工输入。由于IN列表中值的个数有一个允许的上限,有些SQL甚至会长成下面的样子:

几百几千几万个值在IN列表里面,那是不是SQL构造的不好,是不是应该先将它改成一个JOIN再去考虑其他?
(4)没有编写错误的SQL
N个表做JOIN的话,一般情况应该有N-1个JOIN条件。如果JOIN条件小于N-1个的话,就会有CARTESIAN
JOIN出现,结果集里面会有重复值。在SELECT LIST里面加上DISTINCT,通常就可以使得SQL得到功能上正确的结果集。这就好比您去银行取钱,实际只要取1000块钱,可是您先取了2000块钱,再把余下的1000存回去,多此一举,虽然实际结果是对的,您确实是取了1000块钱。
当SQL处理的数据量小的时候,这个多此一举对于响应时间的影响并不会很大。可是当SQL处理的数据量大的时候,这个影响就会完全凸显出来。还是那个取钱的例子,如果您实际只要取1000块钱,可是您先取了10001000块钱,再把余下的10000000块钱存回去。最后您也会得到1000块钱,可是银行员工为您取钱的时候数出10001000块钱的时间,和把钱存回去的时候再数好10000000块钱的时间,都是您办业务的时间,您取钱的时间就会变得相当长了。
SQL语句中WHERE条件里面的值的数据类型,应该与相应的列的数据类型一致。否则SQL语句虽不会报错,会隐式的用函数将那个列转换成与相应的值的数据类型一致,去执行SQL。这种隐式数据类型转换,可能会导致ORA-01722的错误,可能会导致相应的列上的索引不能被使用到,可能会导致明明可以使用分区裁剪但却用不上的情况,响应时间可能差好几个数量级。
给SQL一个好的执行环境

SQL需要在好的环境上执行才能够性能好。那么什么是好的执行环境呢?
正确的给软件打上补丁,是打造好的执行环境的第一步。明明您都花了钱买软件,明明人家软件厂家都出了补丁可以让软件跑的更好更快,为什么不打补丁呢?当然了,打补丁是个技术活,怎么正确的给软件打上补丁,肯定是要按照软件厂家的说明来,或者咨询软件厂家啦。
使用默认的init.ora参数设置,也是打造好的执行环境的重要一环。使用默认的init.ora参数设置,意味着您是按照Oracle内部研发团队设计软件的方法去使用它,意味着您使用的是经过Oracle内部测试团队严格测试的软件。当然了,有一些特定的应用软件,比如Oracle的EBS,要求修改init.ora参数,这种情况是要修改,因为那些修改是经过应用软件厂家严格测试过的。
如果是因为遇到bug,需要修改某些参数做为临时解决方案,那么当那个bug修复之后,您应该及时将相应的参数改回去,否则后果可能也会很严重噢。
另外,若随意修改init.ora参数,可能会导致售后的问题。
从数据库设计的角度优化SQL

现在Oracle数据库软件使用的是Cost Based Optimizer(CBO),基于成本的优化器。
本质上来讲,优化器就是一系列的算法。优化器会接受输入的信息来生成SQL的执行计划。输入的信息包括:
(1)统计信息
统计信息包括两个方面,系统的统计信息,和实际用户数据的统计信息。
系统的统计信息,推荐大家使用默认设置。实际用户数据的统计信息,最重要的是要有代表性,要能够反应数据的特征。
(2)约束
NOT NULL, PK, FK, UK等等约束,若实际数据是需要符合约束的,那么那些约束应该存在于数据库里面,应该让优化器知道这些约束的存在。
举个例子。多个表做JOIN,如果某张表只是被JOIN了,比如下面这样事儿的

customer表只出现在了JOIN部分,但是并没有出现在SELECTlist里面,也没有出现在查询条件里面,也没有出现在GROUP BY和ORDER BY的部分里面。那么如果lineorder表上的JOIN key(lo_custkey)上存在外键约束的话,优化器就会知道lo_custkey = c_custkey这个JOIN总是能够JOIN的上,那么在实际执行的时候就不会去JOIN
customer这个表了。
执行计划可以是下面这样事儿的:
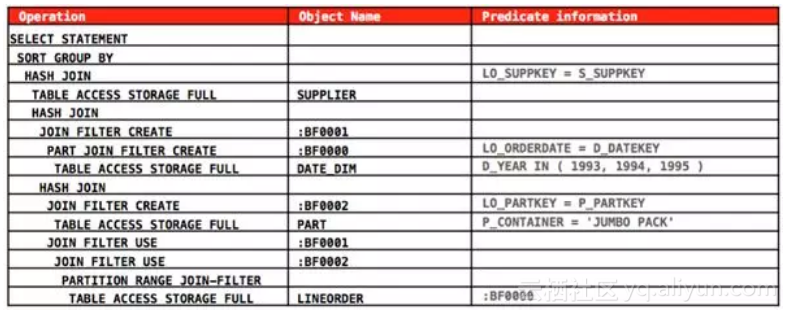
您擦亮双眼看好了么,customer表压根儿就没有出现在执行计划里面!您能做的最快的JOIN就是不JOIN啊哈哈哈。这种情况我们叫做JOIN elimination,发生的前提条件是相关约束的存在。
(3)Schema设计
Schema的设计,包括数据模型,索引,分区,压缩,clustering(数据根据相应的KEY值物理上存放在一起)等等,对SQL性能都有非常重要的影响。
有些SQL里面,一个表和自己JOIN几十次,就是因为数据模型设计得不好导致的。此时若只是专注于SQL本身,能够取得的性能提升恐怕就非常有限了。
Schema设计是门大学问,每一个方面都可以对SQL的性能有几个数量级的影响。想做好SQL优化的话,您必须要将schema设计重视起来。
从执行角度优化SQL

从执行的角度去优化SQL,主要是要考虑以下方面:
Access method,是通过索引访问数据,还是全表扫描。
Join方法,是Nested Loop Join,Hash Join,还是Merge Join。
Join顺序,是表A Join表B,再Join表C,还是反之。
并行执行时,生产者进程组和消费者进程组之间的数据分发方法,是hash,还是broadcast,还是其他的分发方法。
数据是否有倾斜,是否某些KEY值对应的数据特别多,其他KEY值对应的数据特别少。
点击有惊喜

设定一个高的目标
如果您把一个SQL从一个小时优化到了1分钟,您会停止工作吗?会不会考虑是否能给它优化到1秒钟?
工作中,每个人都有压力,压力之下,很容易疏于思考。一个SQL多长时间能跑完,依赖于它跑在什么样的硬件和软件环境上。一个SQL能不能跑的更快,本质上是:它是否能够更加充分的利用硬件资源和软件能力。
做SQL优化,给自己设定一个高的目标非常重要!
去优化那些好的SQL
有了高的目标,接下来,还要找到那些好的SQL进行优化。那么,什么是好的SQL?
(1)有效的 SQL
数据库是为了执行SQL设计的,不是为了一执行就报错的无效SQL设计的。
如果执行一个SQL,报ORA的错误,那么这是一个无效的SQL,它不应该存在于您的系统里面,当然更不应该成为您优化的对象。
如果执行一个SQL,报ORA的错误,那么在数据库里面会是一个failure parse。如果您系统的AWR报告里面有failure parse,那么您要注意了,后果可能很严重。
(2)您知道业务含义的SQL
有很多时候,一些SQL和PL/SQL存储过程是根本就不需要被执行的。但是由于种种原因,那些SQL和PL/SQL存储过程存在在系统中,可能都已存在了很长时间,写那些SQL和PL/SQL存储过程的人可能早就跳槽了,为了所谓的“稳定”,没有人去动那些SQL和PL/SQL存储过程。去优化这些根本就不需要被执行的SQL和PL/SQL存储过程当然是没有任何意义的。
所以,在优化任何一条SQL之前,应该首先知道那条SQL业务上的含义,确定它确实是需要被执行的,再去优化它。
(3)构造好的SQL
如果一个SQL语句里面有IN列表,IN列表里面有几百个值,那么那几百个值,很有可能是来源于另外一个SQL,而非人工输入。由于IN列表中值的个数有一个允许的上限,有些SQL甚至会长成下面的样子:
几百几千几万个值在IN列表里面,那是不是SQL构造的不好,是不是应该先将它改成一个JOIN再去考虑其他?
(4)没有编写错误的SQL
N个表做JOIN的话,一般情况应该有N-1个JOIN条件。如果JOIN条件小于N-1个的话,就会有CARTESIAN
JOIN出现,结果集里面会有重复值。在SELECT LIST里面加上DISTINCT,通常就可以使得SQL得到功能上正确的结果集。这就好比您去银行取钱,实际只要取1000块钱,可是您先取了2000块钱,再把余下的1000存回去,多此一举,虽然实际结果是对的,您确实是取了1000块钱。
当SQL处理的数据量小的时候,这个多此一举对于响应时间的影响并不会很大。可是当SQL处理的数据量大的时候,这个影响就会完全凸显出来。还是那个取钱的例子,如果您实际只要取1000块钱,可是您先取了10001000块钱,再把余下的10000000块钱存回去。最后您也会得到1000块钱,可是银行员工为您取钱的时候数出10001000块钱的时间,和把钱存回去的时候再数好10000000块钱的时间,都是您办业务的时间,您取钱的时间就会变得相当长了。
SQL语句中WHERE条件里面的值的数据类型,应该与相应的列的数据类型一致。否则SQL语句虽不会报错,会隐式的用函数将那个列转换成与相应的值的数据类型一致,去执行SQL。这种隐式数据类型转换,可能会导致ORA-01722的错误,可能会导致相应的列上的索引不能被使用到,可能会导致明明可以使用分区裁剪但却用不上的情况,响应时间可能差好几个数量级。
给SQL一个好的执行环境
SQL需要在好的环境上执行才能够性能好。那么什么是好的执行环境呢?
正确的给软件打上补丁,是打造好的执行环境的第一步。明明您都花了钱买软件,明明人家软件厂家都出了补丁可以让软件跑的更好更快,为什么不打补丁呢?当然了,打补丁是个技术活,怎么正确的给软件打上补丁,肯定是要按照软件厂家的说明来,或者咨询软件厂家啦。
使用默认的init.ora参数设置,也是打造好的执行环境的重要一环。使用默认的init.ora参数设置,意味着您是按照Oracle内部研发团队设计软件的方法去使用它,意味着您使用的是经过Oracle内部测试团队严格测试的软件。当然了,有一些特定的应用软件,比如Oracle的EBS,要求修改init.ora参数,这种情况是要修改,因为那些修改是经过应用软件厂家严格测试过的。
如果是因为遇到bug,需要修改某些参数做为临时解决方案,那么当那个bug修复之后,您应该及时将相应的参数改回去,否则后果可能也会很严重噢。
另外,若随意修改init.ora参数,可能会导致售后的问题。
从数据库设计的角度优化SQL
现在Oracle数据库软件使用的是Cost Based Optimizer(CBO),基于成本的优化器。
本质上来讲,优化器就是一系列的算法。优化器会接受输入的信息来生成SQL的执行计划。输入的信息包括:
(1)统计信息
统计信息包括两个方面,系统的统计信息,和实际用户数据的统计信息。
系统的统计信息,推荐大家使用默认设置。实际用户数据的统计信息,最重要的是要有代表性,要能够反应数据的特征。
(2)约束
NOT NULL, PK, FK, UK等等约束,若实际数据是需要符合约束的,那么那些约束应该存在于数据库里面,应该让优化器知道这些约束的存在。
举个例子。多个表做JOIN,如果某张表只是被JOIN了,比如下面这样事儿的
customer表只出现在了JOIN部分,但是并没有出现在SELECTlist里面,也没有出现在查询条件里面,也没有出现在GROUP BY和ORDER BY的部分里面。那么如果lineorder表上的JOIN key(lo_custkey)上存在外键约束的话,优化器就会知道lo_custkey = c_custkey这个JOIN总是能够JOIN的上,那么在实际执行的时候就不会去JOIN
customer这个表了。
执行计划可以是下面这样事儿的:
您擦亮双眼看好了么,customer表压根儿就没有出现在执行计划里面!您能做的最快的JOIN就是不JOIN啊哈哈哈。这种情况我们叫做JOIN elimination,发生的前提条件是相关约束的存在。
(3)Schema设计
Schema的设计,包括数据模型,索引,分区,压缩,clustering(数据根据相应的KEY值物理上存放在一起)等等,对SQL性能都有非常重要的影响。
有些SQL里面,一个表和自己JOIN几十次,就是因为数据模型设计得不好导致的。此时若只是专注于SQL本身,能够取得的性能提升恐怕就非常有限了。
Schema设计是门大学问,每一个方面都可以对SQL的性能有几个数量级的影响。想做好SQL优化的话,您必须要将schema设计重视起来。
从执行角度优化SQL
从执行的角度去优化SQL,主要是要考虑以下方面:
Access method,是通过索引访问数据,还是全表扫描。
Join方法,是Nested Loop Join,Hash Join,还是Merge Join。
Join顺序,是表A Join表B,再Join表C,还是反之。
并行执行时,生产者进程组和消费者进程组之间的数据分发方法,是hash,还是broadcast,还是其他的分发方法。
数据是否有倾斜,是否某些KEY值对应的数据特别多,其他KEY值对应的数据特别少。
点击有惊喜

相关文章推荐
- 【演讲实录】RWP团队谈SQL优化
- Android开发中的性能优化(摘录:陈彧堃演讲实录)
- Android开发中的性能优化(摘录:陈彧堃演讲实录)
- SQL优化建议工具:SQLAdvisor(美团)部署实录
- 深入浅出数据仓库中SQL性能优化之Hive篇
- sql 多表查询优化
- [MSSQL]SQL语句优化- while循环使用
- sql语句优化
- oracle11g中SQL优化(SQL TUNING)新特性之SQL Plan Management(SPM)
- SQL查询语句优化的实用方法
- SQL 性能优化几条建议
- Oracle+SQL优化第一弹(前人种树,后人乘凉,翻译加上部分自己的内容,希望能给大家带来帮助)
- 优化SQL语句需要注意的4点
- mysql中优化sql语句查询的30种方法(转)
- SQL优化第一章
- 非常好用的SQL语句优化34条
- Oracle SQL性能优化
- 特定场景下SQL的优化
- MySQL批量SQL插入性能优化
- Oracle之SQL语句性能优化(34条优化方法)