应对数据库高负载访问的几种方法
2018-01-06 13:55
162 查看
1.可以使用优化查询的方法
2.主从复制, 读写分离, 负载均衡
目前,大部分的主流关系型数据库都提供了主从复制的功能,通过配置两台(或多台)数据库的主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。网站可以利用数据库的这一功能,实现数据库的读写分离,从而改善数据库的负载压力。一个系统的读操作远远多于写操作,因此写操作发向 master,读操作发向 slaves 进行操作(简单的轮循算法来决定使用哪个slave)。利用数据库的读写分离,Web 服务器在写数据的时候,访问主数据库(Master),主数据库通过主从复制机制将数据更新同步到从数据库(Slave),这样当 Web 服务器读数据的时候,就可以通过从数据库获得数据。这一方案使得在大量读操作的 Web 应用可以轻松地读取数据,而主数据库也只会承受少量的写入操作,还可以实现数据热备份,可谓是一举两得的方案。
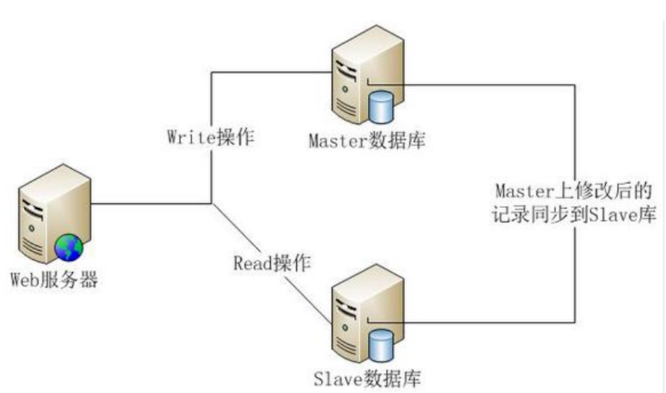
主从复制的原理:
影响 MySQL-A 数据库的操作,在数据库执行后,都会写入本地的日志系统 A 中。
假设,实时的将变化了的日志系统中的数据库事件操作,通过网络发给 MYSQL-B。MYSQL-B 收到后,写入本地日志系统 B,然后一条条的将数据库事件在数据库中完成。那么,MYSQL-A 的变化,MYSQL-B 也会变化,这样就是所谓的 MYSQL 的复制。
在上面的模型中,MYSQL-A 就是主服务器,即 master,MYSQL-B 就是从服务器,即slave。
日志系统 A,其实它是 MYSQL 的日志类型中的二进制日志,也就是专门用来保存修改数据库表的所有动作,即 bin log。【注意 MYSQL 会在执行语句之后,释放锁之前,写入二进制日志,确保事务安全】

日志系统 B,并不是二进制日志,由于它是从 MYSQL-A 的二进制日志复制过来的,并不是自己的数据库变化产生的,有点接力的感觉,称为中继日志,即 relay log。可以发现,通过上面的机制,可以保证 MYSQL-A 和 MYSQL-B 的数据库数据一致,但是时间上肯定有延迟,即 MYSQL-B 的数据是滞后的。
Mysql 主(称 master)从(称 slave)复制的原理:
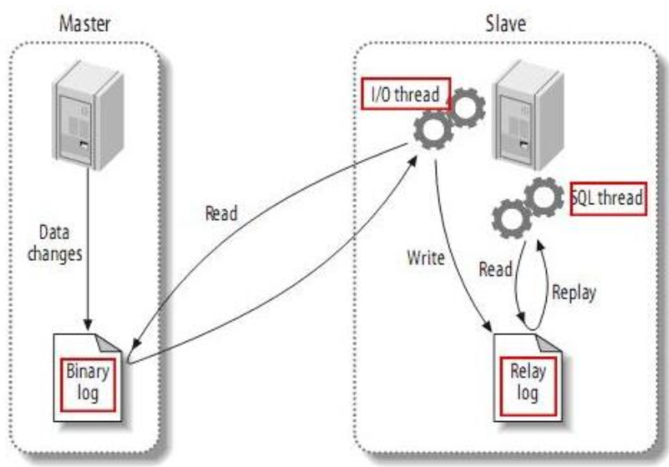
(1)master 将数据改变记录到二进制日志(binary log)中,也即是配置文件 log-bin 指定的文件(这些记录叫做二进制日志事件, binary log events)
PS:从图中可以看出,Slave 服务器中有一个 I/O线程(I/O Thread)在不停地监听 Master的二进制日志(Binary Log)是否有更新: 如果没有它会睡眠等待 Master 产生新的日志事件;如果有新的日志事件(Log Events), 则会将其拷贝至 Slave 服务器中的中继日志(Relay Log)。
(2).slave 将 master 的二进制日志事件(binary log events)拷贝到它的中继日志(relay log)
(3).slave 重做中继日志中的事件,将 Master 上的改变反映到它自己的数据库中。 , 所以两端的数据是完全一样的。
PS: 从图中可以看出, Slave 服务器中有一个 SQL 线程(SQL Thread)从中继日志读取事件, 并重做其中的事件, 从而更新 Slave 的数据, 使其与 Master 中的数据一致。 只要该线程与 I/O 线程保持一致,中继日志通常会位于 OS 的缓存中,所以中继日志的开销很小。
主从复制的方式:
1.同步复制:
主服务器在将更新的数据写入它的二进制日志(Binlog)文件中后,必须等待验证所有的从服务器的更新数据是否已经复制到其中,之后才可以自由处理其它进入的事务处理请求。
2.异步复制:
主服务器在将更新的数据写入它的二进制日志(Binlog)文件中后,无需等待验证更新数据是否已经复制到从服务器中,就可以自由处理其它进入的事务处理请求。
3.半同步复制:
主服务器在将更新的数据写入它的二进制日志(Binlog)文件中后,只需等待验证其中一台从服务器的更新数据是否已经复制到其中,就可以自由处理其它进入的事务处理请求,其他的从服务器不用管。
3.数据库分表, 分区, 分库
分表:通过拆分表可以提高表的访问效率。 有 2 种拆分方法
1.垂直拆分
把主键和一些列放在一个表中, 然后把主键和另外的列放在另一个表中。 如果一个表中某些列常用, 而另外一些不常用, 则可以采用垂直拆分。
2.水平拆分
根据一列或者多列数据的值把数据行放到二个独立的表中。
分区:
分区就是把一张表的数据分成多个区块,这些区块可以在一个磁盘上,也可以在不同的磁盘上,分区后,表面上还是一张表,但数据散列在多个位置,这样一来,多块硬盘同时处理不同的请求,从而提高磁盘 I/O 读写性能,实现比较简单。 包括水平分区和垂直分区。
分库:
分库是根据业务不同把相关的表切分到不同的数据库中,比如 web、bbs、blog 等库。

相关文章推荐
- spring+hibernate架构中Dao访问数据库的几种方法
- spring+hibernate架构中Dao访问数据库的几种方法
- 在Hibernate里面动态切换SChema实现访问不同的数据库的几种方法
- spring+hibernate架构中Dao访问数据库的几种方法
- 在Hibernate里面动态切换SChema实现访问不同的数据库的几种方法
- spring+hibernate架构中Dao访问数据库的几种方法
- LabVIEW中访问数据库的几种不同方法
- 在Hibernate里面动态切换SChema实现访问不同的数据库的几种方法
- 在Hibernate里面动态切换SChema实现访问不同的数据库的几种方法
- spring+hibernate架构中Dao访问数据库的几种方法
- 访问数据库的几种方法
- spring+hibernate架构中Dao访问数据库的几种方法
- 提高数据库访问性能的几种方法
- 【转摘】SilverLight跨域访问及其常用的几种解决方法
- 几种访问谷歌的方法
- mysql设置远程访问数据库的多种方法
- 获取数据库访问独占权,,因为数据库正在使用,所以无法获得对数据库的独占访问权---还原或删除数据库的解决方法
- 因为数据库正在使用,所以无法获得对数据库的独占访问权---还原或删除数据库的解决方法
- ASP.net中访问数据库的几种方式
- MSSQL附加数据库拒绝访问提示5120错误的处理方法