深度学习引论(四):手写数字识别(Step by step)
2018-01-04 13:11
465 查看
经过前面的学习,我们已经掌握了构建神经网络的整个过程,接下来使用手写数字识别这个例子来巩固一下。
MNIST数据库是一个手写数字的数据库,它提供了六万的训练集和一万的测试集。数字放在一个归一化的,固定尺寸(28*28)的图片的中心。
而MNIST_small是MNIST的一个子集,包含10000个训练样本和2000个测试样本。
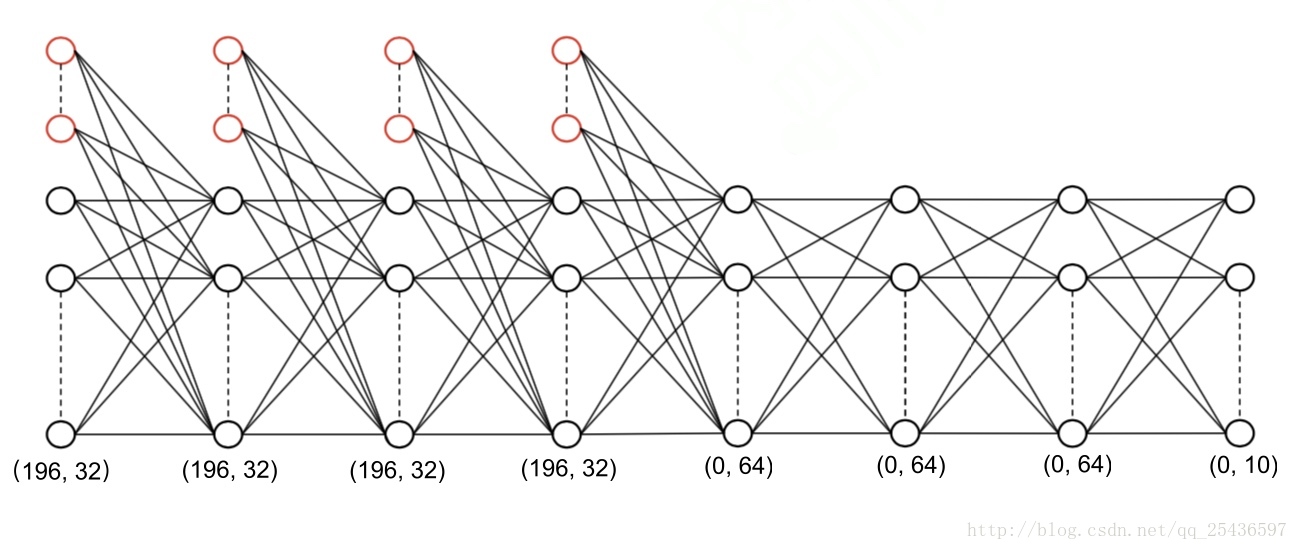
按照之前的思路,比较容易想到的是要将28*28的矩阵转换为784*1的向量作为第一层的输入。但现在我们有更好的处理方法,将28*28的矩阵拆成4个14*14的小矩阵,再分别向量化成196*1的4个列向量,将这4个列向量分别作为1到4层神经网络的输入。
为了加快神经网络的计算速度,我们将每一个样本的列向量堆起来,组成一个矩阵。以第一层神经网络为例,有10000个训练样本,每个输入是196*1的列向量,将这10000个列向量堆起来,组成一个196*10000的矩阵。这种方法的神经网络计算速度远远大于用for循环遍历10000个样本。
代码如下:
代码如下:
均匀分布:wlij ~ U(-rl, rl)
两种分布都可
需要说明:mini_batch表示每一次批处理的样本个数,即每次批处理100个样本,而不是直接处理10000个样本,每次处理的100个样本是随机从10000个样本中选择出来的。
神经网络的输出是一个有10个元素的列向量,这个列向量只能有一位为1,其余为0,第几位为1表示这是数字几。如第0位为1,则判断该数字为0.(从0开始数数)
考虑到神经网络的输出,我们在最后一层的前一层使用sigmoid函数作为激活函数,以保证输出的结果为0到1直接的数。举个栗子,以数字‘8’作为输入,若输出的结果向量中的第八位非常接近1,其余位接近0,则认为该样本为数字‘8’,神经网络的输出结果正确。
Sigmoid函数:
Sigmoid函数:
Accuracy of training set :
Accuracy of testing set :
完整代码:
实验结果:
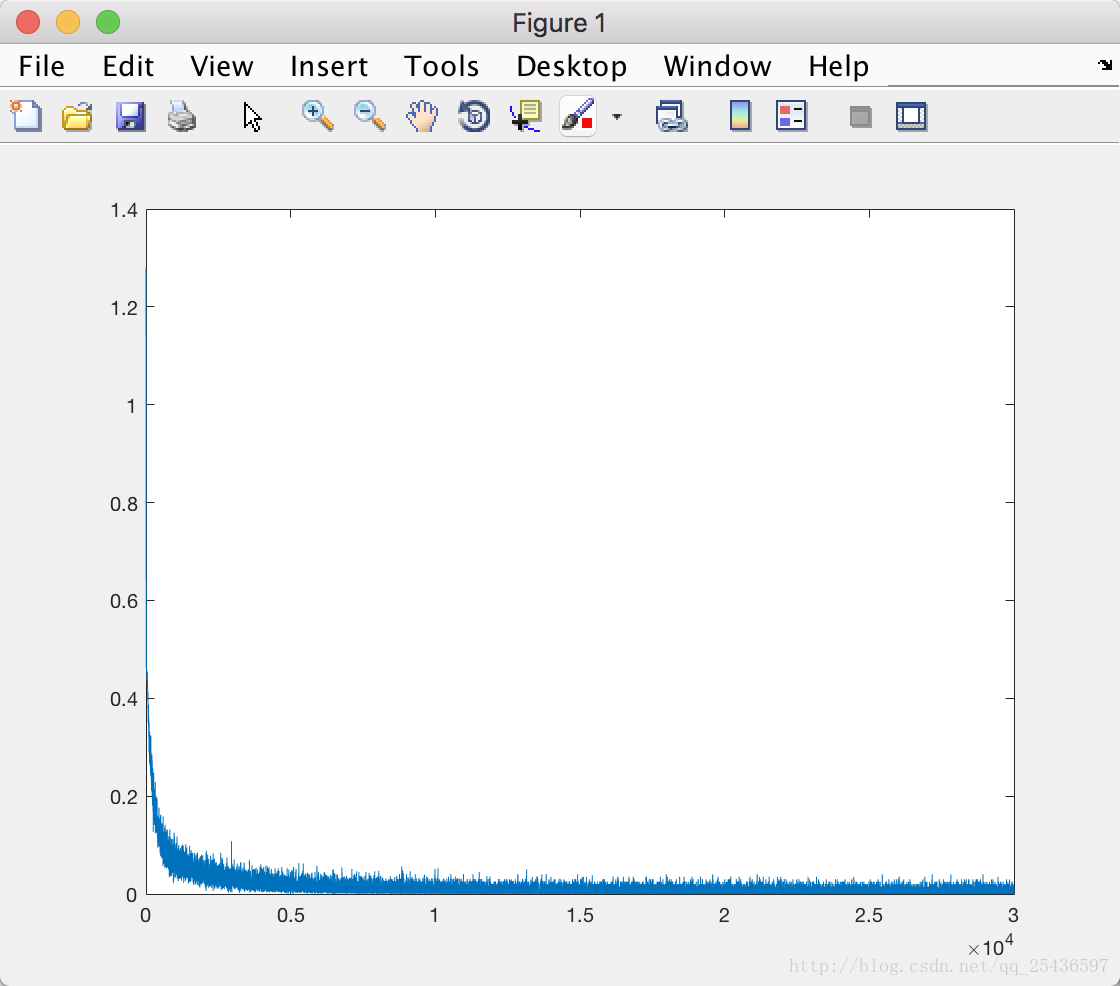
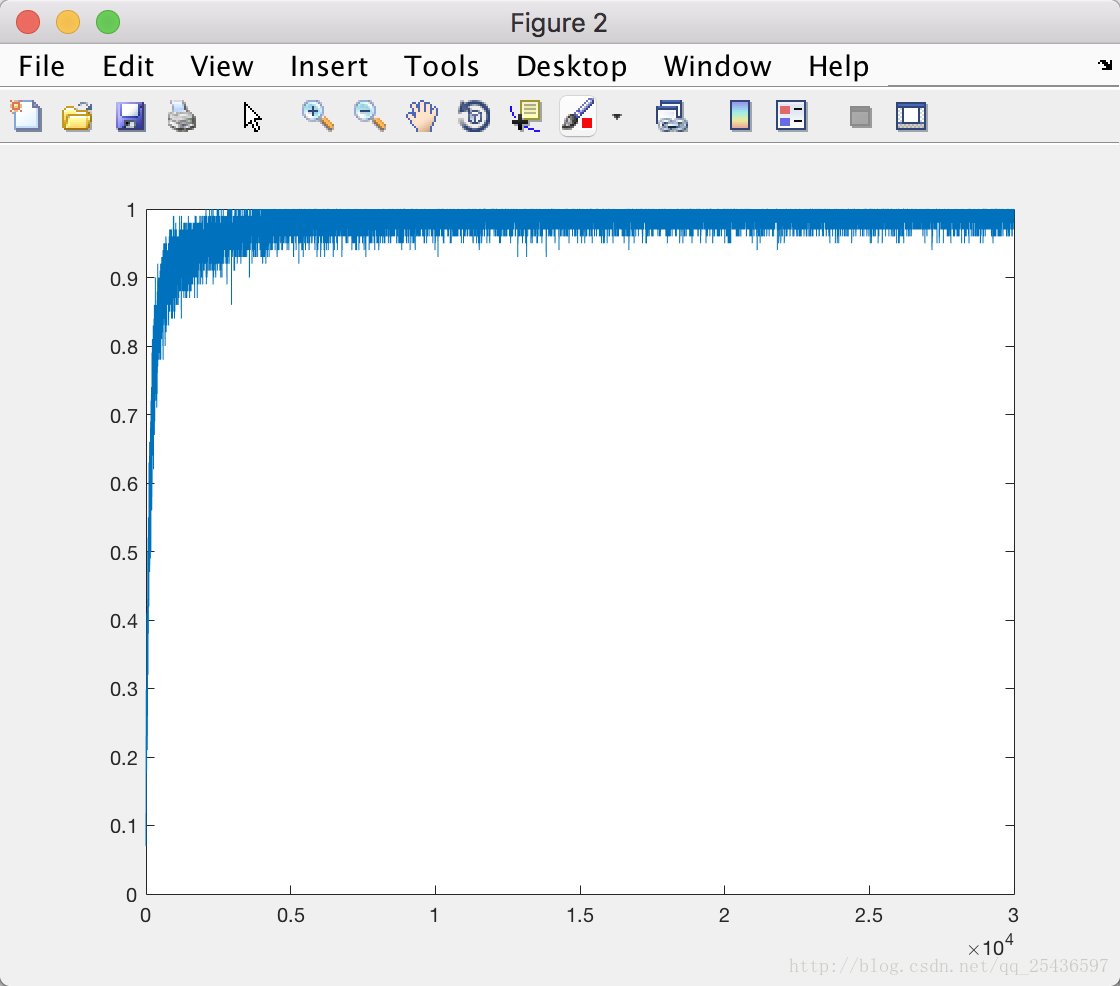
Accuracy on training dataset is 99.030000%
Accuracy on testing dataset is 94.200000%
Step1 : Prepare Data
Dataset : MNIST_small(下载地址)MNIST数据库是一个手写数字的数据库,它提供了六万的训练集和一万的测试集。数字放在一个归一化的,固定尺寸(28*28)的图片的中心。
而MNIST_small是MNIST的一个子集,包含10000个训练样本和2000个测试样本。
按照之前的思路,比较容易想到的是要将28*28的矩阵转换为784*1的向量作为第一层的输入。但现在我们有更好的处理方法,将28*28的矩阵拆成4个14*14的小矩阵,再分别向量化成196*1的4个列向量,将这4个列向量分别作为1到4层神经网络的输入。
为了加快神经网络的计算速度,我们将每一个样本的列向量堆起来,组成一个矩阵。以第一层神经网络为例,有10000个训练样本,每个输入是196*1的列向量,将这10000个列向量堆起来,组成一个196*10000的矩阵。这种方法的神经网络计算速度远远大于用for循环遍历10000个样本。
代码如下:
% prepare the data set
load mnist_small_matlab.mat;
train_size = 10000;
X_train{1} = reshape(trainData(1: 14, 1: 14, :), [], train_size);
X_train{2} = reshape(trainData(15: 28, 1: 14, :), [], train_size);
X_train{3} = reshape(trainData(15: 28, 15: 28, :), [], train_size);
X_train{4} = reshape(trainData(1: 14, 15: 28, :), [], train_size);
X_train{5} = zeros (0, train_size);
X_train{6} = zeros (0, train_size);
X_train{7} = zeros (0, train_size);
X_train{8} = zeros (0, train_size);
test_size = 2000;
X_test{1} = reshape(testData(1: 14, 1: 14, :), [], test_size);
X_test{2} = reshape(testData(15: 28, 1: 14, :), [], test_size);
X_test{3} = reshape(testData(15: 28, 15: 28, :), [], test_size);
X_test{4} = reshape(testData(1: 14, 15: 28, :), [], test_size);
X_test{5} = zeros (0, test_size);
X_test{6} = zeros (0, test_size);
X_test{7} = zeros (0, test_size);
X_test{8} = zeros (0, test_size);Step2 : Design Network Architecture
代码如下:
% define network architecture layer_size = [196 32 196 32 196 32 196 32 0 64 0 64 0 64 0 10]; L = 8;
Step3 : Initialize Parameters
Initialize Weights
高斯分布:wlij ~ N(0, 1)for l = 1: L - 1
w{l} = randn(layer_size(l + 1, 2), sum(layer_size(l, :)));
end均匀分布:wlij ~ U(-rl, rl)
for l = 1: L - 1
w{l} = (rand(layer_size(l + 1, 2), sum(layer_size(l, :))) * 2 - 1) * sqrt(6 / (layer_size(l + 1, 2) + sum(layer_size(l, :))));
end两种分布都可
Choose Parameters
alpha = 1; %learning rate 学习率 max_iter = 300; %number of iteration 迭代次数 mini_batch = 100; %number of samples in a batch 每一批处理的样本个数
需要说明:mini_batch表示每一次批处理的样本个数,即每次批处理100个样本,而不是直接处理10000个样本,每次处理的100个样本是随机从10000个样本中选择出来的。
Step4 : Run the Network
激活函数
经验表明,以ReLU函数作为激活函数往往能够取得较好的训练效果。在本次试验中,除倒数第二层外,其余层均使用ReLU函数作为激活函数。神经网络的输出是一个有10个元素的列向量,这个列向量只能有一位为1,其余为0,第几位为1表示这是数字几。如第0位为1,则判断该数字为0.(从0开始数数)
考虑到神经网络的输出,我们在最后一层的前一层使用sigmoid函数作为激活函数,以保证输出的结果为0到1直接的数。举个栗子,以数字‘8’作为输入,若输出的结果向量中的第八位非常接近1,其余位接近0,则认为该样本为数字‘8’,神经网络的输出结果正确。
前向计算
ReLU函数:function [a_next, z_next] = fc(w, a, x) % define the activation function f = @(s) max(0, s); %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Your code BELOW %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % forward computing (either component or vector form) a = [x a]; z_next = w * a; a_next = f(z_next); %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Your code ABOVE %%%%%%%%%%%%%%%%%%%%%%%%%%%%% end
Sigmoid函数:
function [a_next, z_next] = fc2(w, a, x) % define the activation function f = @(s) 1 ./ (1 + exp(-s)); %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Your code BELOW %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % forward computing (either component or vector form) a = [x a]; z_next = w * a; a_next = f(z_next); %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Your code ABOVE %%%%%%%%%%%%%%%%%%%%%%%%%%%%% end
Cost Function & Training Accuracy
J = [J 1/2/mini_batch*sum((a{L}(:) - y(:)).^2)];
[~, ind_y] = max(y);
[~, ind_pred] = max(a{L});
xxj = sum(ind_y == ind_pred) / mini_batch;
Acc = [Acc xxj];后向计算
ReLU函数:function delta = bc(w, z, delta_next) % define the activation function f = @(s) max(0, s); % define the derivative of activation function %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Your code BELOW %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % backward computing (either component or vector form) xxj = size(z, 1); delta = w' * delta_next; df = []; for i = 1 : size(z, 1) for j = 1 : size(z, 2) if z(i, j) > 0 df(i, j) = 1; else df(i, j) = 0; end end end delta = delta(1 : xxj, :) .* df; %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Your code ABOVE %%%%%%%%%%%%%%%%%%%%%%%%%%%%% end
Sigmoid函数:
function delta = bc2(w, z, delta_next) % define the activation function f = @(s) 1 ./ (1 + exp(-s)); % define the derivative of activation function df = @(s) f(s) .* (1 - f(s)); %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Your code BELOW %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % backward computing (either component or vector form) xxj = size(z, 1); delta = w' * delta_next; delta = delta(1 : xxj, :) .* df(z); %%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Your code ABOVE %%%%%%%%%%%%%%%%%%%%%%%%%%%%% end
更新权值
for l = 1 : L - 1
gw = delta{l + 1} * [x{l}; a{l}]' / mini_batch;
w{l} = w{l} - alpha * gw;
endStep5 : Evaluation
Acc = number of predictionsnumber of samplesAccuracy of training set :
a{1} = zeros(layer_size(1, 2), train_size);
for l = 1 : L - 1
a{l + 1} = fc(w{l}, a{l}, X_train{l});
end
[~, ind_train] = max(trainLabels);
[~, ind_pred] = max(a{L});
train_acc = sum(ind_train == ind_pred) / train_size;
fprintf('Accuracy on training dataset is %f%%\n', train_acc * 100);Accuracy of testing set :
a{1} = zeros(layer_size(1, 2), test_size);
for l = 1 : L - 1
a{l + 1} = fc(w{l}, a{l}, X_test{l});
end
[~, ind_test] = max(testLabels);
[~, ind_pred] = max(a{L});
test_acc = sum(ind_test == ind_pred) / test_size;
fprintf('Accuracy on testing dataset is %f%%\n', test_acc * 100);完整代码:
% clear workspace and close plot windows
clear;
close all;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Your code BELOW
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% prepare the data set load mnist_small_matlab.mat; train_size = 10000; X_train{1} = reshape(trainData(1: 14, 1: 14, :), [], train_size); X_train{2} = reshape(trainData(15: 28, 1: 14, :), [], train_size); X_train{3} = reshape(trainData(15: 28, 15: 28, :), [], train_size); X_train{4} = reshape(trainData(1: 14, 15: 28, :), [], train_size); X_train{5} = zeros (0, train_size); X_train{6} = zeros (0, train_size); X_train{7} = zeros (0, train_size); X_train{8} = zeros (0, train_size); test_size = 2000; X_test{1} = reshape(testData(1: 14, 1: 14, :), [], test_size); X_test{2} = reshape(testData(15: 28, 1: 14, :), [], test_size); X_test{3} = reshape(testData(15: 28, 15: 28, :), [], test_size); X_test{4} = reshape(testData(1: 14, 15: 28, :), [], test_size); X_test{5} = zeros (0, test_size); X_test{6} = zeros (0, test_size); X_test{7} = zeros (0, test_size); X_test{8} = zeros (0, test_size);
% choose parameters
alpha = 1;
max_iter = 300;
mini_batch = 100;
J = [];
Acc = [];
% define network architecture layer_size = [196 32 196 32 196 32 196 32 0 64 0 64 0 64 0 10]; L = 8;
% initialize weights
% 二选一
% for l = 1: L - 1
% w{l} = randn(layer_size(l + 1, 2), sum(layer_size(l, :)));
% end
for l = 1: L - 1 w{l} = (rand(layer_size(l + 1, 2), sum(layer_size(l, :))) * 2 - 1) * sqrt(6 / (layer_size(l + 1, 2) + sum(layer_size(l, :)))); end
% train
for iter = 1 : max_iter
ind = randperm(train_size);
for k = 1 : ceil(train_size / mini_batch)
a{1} = zeros(layer_size(1, 2), mini_batch);
for l = 1 : L
x{l} = X_train{l}(:, ind((k - 1) * mini_batch + 1 : min(k * mini_batch, train_size)));
end
y = double(trainLabels( :, ind((k - 1) * mini_batch + 1 : min(k * mini_batch, train_size))));
% 前向计算
for l = 1 : L-2
[a{l + 1}, z{l + 1}] = fc(w{l}, a{l}, x{l});
end
[a{L}, z{L}] = fc2(w{L - 1}, a{L - 1}, x{L - 1});
% cost function
J = [J 1/2/mini_batch*sum((a{L}(:) - y(:)).^2)];
% Acc of training data
[~, ind_y] = max(y);
[~, ind_pred] = max(a{L});
xxj = sum(ind_y == ind_pred) / mini_batch;
Acc = [Acc xxj];
% 后向计算
delta{L} = (a{L} - y) .* a{L} .* (1 - a{L});
delta{L - 1} = bc2(w{L - 1}, z{L - 1}, delta{L});
for l = L - 2 : -1 : 2
delta{l} = bc(w{l}, z{l}, delta{l + 1});
end
% 更新权值
for l = 1 : L - 1 gw = delta{l + 1} * [x{l}; a{l}]' / mini_batch; w{l} = w{l} - alpha * gw; end
end
end
figure
plot(J);
figure
plot(Acc);
% save model
save model.mat w layer_size
% test
a{1} = zeros(layer_size(1, 2), train_size); for l = 1 : L - 1 a{l + 1} = fc(w{l}, a{l}, X_train{l}); end [~, ind_train] = max(trainLabels); [~, ind_pred] = max(a{L}); train_acc = sum(ind_train == ind_pred) / train_size; fprintf('Accuracy on training dataset is %f%%\n', train_acc * 100);
a{1} = zeros(layer_size(1, 2), test_size); for l = 1 : L - 1 a{l + 1} = fc(w{l}, a{l}, X_test{l}); end [~, ind_test] = max(testLabels); [~, ind_pred] = max(a{L}); test_acc = sum(ind_test == ind_pred) / test_size; fprintf('Accuracy on testing dataset is %f%%\n', test_acc * 100);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Your code ABOVE
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
实验结果:
Accuracy on training dataset is 99.030000%
Accuracy on testing dataset is 94.200000%

相关文章推荐
- 深度学习-传统神经网络使用TensorFlow框架实现MNIST手写数字识别
- 机器学习深度学习基础笔记(2)——梯度下降之手写数字识别算法实现
- 深度学习--手写数字识别<三>
- 神经网络与深度学习笔记——第1章 使用神经网络识别手写数字
- 深度学习-使用cuda加速卷积神经网络-手写数字识别准确率99.7%
- 深度学习笔记(四)用Torch实现MNIST手写数字识别
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 一文全解:利用谷歌深度学习框架Tensorflow识别手写数字图片(初学者篇)
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 机器学习/深度学习个人进阶日志-基于Tensorflow的手写数字识别项目最终篇
- 深度学习四:tensorflow-使用卷积神经网络识别手写数字
- 深度学习--手写数字识别<二>--交叉熵损失函数(cross entropy cost function)
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 (zz)
- Python实现深度学习之-神经网络识别手写数字(更新中,更新日期:2017-07-12)
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 深度学习-随机梯度下降算法应用-手写数字识别
- 深度学习-Cross-Entropy Cost函数来实现MNIST手写数字识别