Python数据科学之处理数据工具教程2(Pandas前篇)
2018-01-03 19:35
726 查看
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas[1] 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
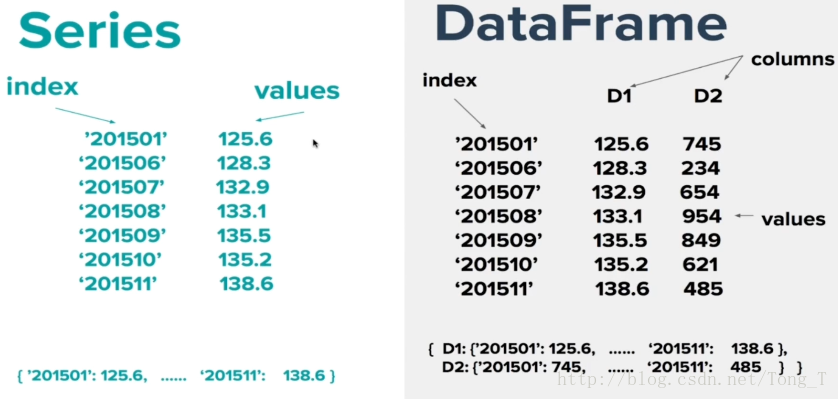
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
Panel :三维的数组,可以理解为DataFrame的容器。
依然是一样的,将代码复制到自己的环境下,运行每一行,自己琢磨一遍,什么懂明白了。
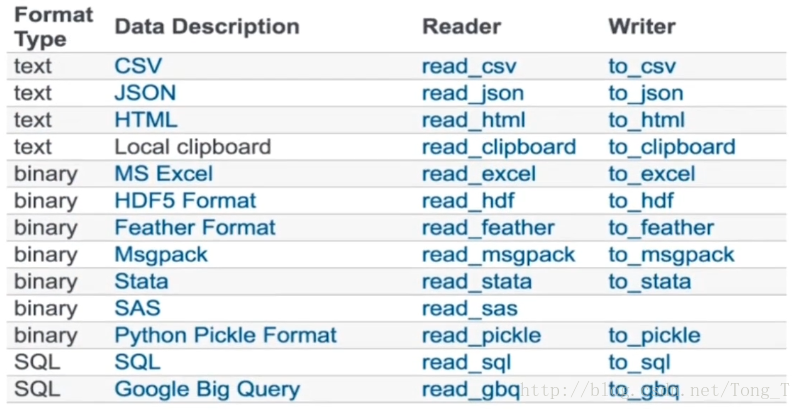
图片一:
PS:
Pandas[1] 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
Panel :三维的数组,可以理解为DataFrame的容器。
依然是一样的,将代码复制到自己的环境下,运行每一行,自己琢磨一遍,什么懂明白了。
import pandas as pd
import numpy as np
"""Series数据结构"""
s1 = pd.Series([1, 2, 3, 4])
print(s1)
print(s1.values)
print(s1.index)
s2 = pd.Series(np.arange(10))
print(s2)
s3 = pd.Series({'1': 1, '2': 2, '3': 3})
print(s3)
s4 = pd.Series([1, 2, 3, 4], index=['A', 'B', 'C', 'D'])
print(s4)
print(s4['A'])
print(s4[s4 > 2])
print(s4.to_dict())
print(pd.isnull(s4))
s4.name = 'demo'
s4.index.name = 'demo index'
print(s4)
print(s4.index)
"""DataFrame数据结构"""
from pandas import Series, DataFrame
# import webbrowser
# link = 'https://www.tiobe.com/tiobe-index/'
# webbrowser.open(link)
# 数据来源与上面这个网站
df = pd.read_csv('TIOBE_Index_for_December_2017.csv')
print(df)
print(type(df))
print(df.columns)
print(df.Ratings)
df_new = DataFrame(df, columns={'Programming Language', 'Dec-17'})
print(df_new)
df_new['Dec-19'] = Series(np.arange(0, 20))
print(df_new)
"""深入理解Series和DataFrame"""
data = {
'Country': ['Belgium', 'India', 'Brazil'], 'Capital': ['Brussels', 'New Delhi', 'Brasilia'],
'Population': [11190846, 1303171035, 207847528]
}
# Series
s1 = pd.Series(data['Country'])
print(s1)
print(s1.values, s1.index)
# Dataframe
df1 = DataFrame(data)
print(df1)
for row in df1.iterrows():
print(row)
# Series也是创建DataFrame
"""Dataframe IO操作"""
# 看代码后的图片一
"""DataFrame Selecting and Indexing"""
imdb = pd.read_csv('movie_metadata.csv')
print(imdb.shape)
# 返回头5行的信息
print(imdb.head(5))
# 切片 iloc() 按照index切
print(imdb.iloc[10:20, :4])
# 15,17是label。不是index
print(imdb.loc[15:17, :])
"""Series reindex"""
s1 = Series([1, 2, 3, 4], index=['A', 'B', 'C', 'D'])
print(s1)
s1 = s1.reindex(index=['A', 'B', 'C', 'D', 'E'])
print(s1)
"""NaN in Series"""
s1 = Series([1, 2, np.nan, 3, 4], index=['A', 'B', 'C', 'D', 'E'])
print(s1)
print(s1.isnull())
print(s1.dropna())
"""Nan in Dataframe"""
dframe = DataFrame([[1, 2, 3], [np.nan, 5, 6], [7, np.nan, 9], [np.nan, np.nan, np.nan]])
print(dframe)
print(dframe.isnull())
print(dframe.notnull())
# dropna()有很多参数,具体参考官方文档
df1 = dframe.dropna(axis=0)
print(df1)
# nan的填充
print(dframe.fillna(value={0: 0, 1: 1, 2: 2}))
"""Mapping和Replace"""
df1 = DataFrame({'城市': ['北京', '上海', '广州'], '人口': [1000, 2000
4000
, 1500]})
print(df1)
# df1['GDP'] = Series([1000, 2000, 1500])
# print(df1)
gdp_map = {'北京': 1000, '上海': 2000, '广州': 1500}
df1['GDP'] = df1['城市'].map(gdp_map)
print(df1)
s1 = Series(np.arange(10))
print(s1.replace(1, np.nan))图片一:
PS:

相关文章推荐
- Python数据科学之处理数据工具教程1(Numpy)
- 利用python进行数据分析(三):pandas--处理数据的工具
- Pyhton科学计算工具Pandas(六)—— 文本数据处理
- Python 数据科学入门教程:Pandas
- Python的网页爬虫&文本处理&科学计&机器学习&数据挖掘工具集
- Python的网页爬虫&文本处理&科学计&机器学习&数据挖掘工具集
- Python的网页爬虫&文本处理&科学计&机器学习&数据挖掘工具集
- Python的网页爬虫&文本处理&科学计&机器学习&数据挖掘工具集
- 人工智能:python 实现 第十一章,使用Pandas处理时间序列数据
- 图像处理工具包ImagXpress教程:Accusoft不同组件间的图像数据传递
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- python 科学计算学习一:numpy快速处理数据(3)
- Python Pandas数据科学入门实例演示(十九02)
- 针对科学数据处理的统计学习教程(scikit-learn教程2)
- [resource-]Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- pandas强大的Python数据分析工具
- python 科学计算学习一:numpy快速处理数据(3)
- python pandas 处理日期数据
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱