高级数据库十二(2):HIVE文件存储格式
2017-12-30 00:35
190 查看
数据库十二(2):HIVE文件存储格式
昨天在看HIVE的时候,突然发现HIVE的文件存储对数据的压缩刚好是前天看的数据库压缩的内容。所以刚好可以拿出来讲一下。
TextFile
Hive默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2、Snappy等朴素压缩算法使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件,它将数据以RCFile
RCFile文件格式是FaceBook开源的一种行列存储相结合的存储方式。首先将表分为几个行组,组成一个一个块。
再对每个块内的数据进行按列存储,每一列的数据都是分开存储。
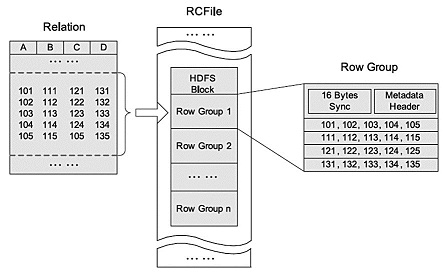
一个块主要包括:16字节的HDFS同步块信息,主要是为了区分一个HDFS块上的相邻行组;元数据的头部信息主要包括该行组内的存储的行数、列的字段信息等等;数据部分按列存储进行。
在一般的列存储中,会将不同的列分开存储,这样在查询的时候会跳过某些列,但是有时候存在一个表的有些列不在同一个HDFS块上(如下图),所以在查询的时候,Hive重组列的过程会浪费很多IO开销。
而RCFile则将一条记录的所有列都存在了一个HDFS块内,相比于普通的列存储会节约不少资源。
存储空间
RCFile采用游程编码(Run-length),相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候。懒加载
数据存储到表中都是压缩的数据,Hive读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。select c from table where a>1
针对行组来说,会对一个行组的a列进行解压缩,如果当前列中有a>1的值,然后才去解压缩c。若当前行组中不存在a>1的列,那就不用解压缩c,从而跳过整个行组。
实践证明RCFile目前没有性能优势, 只有存储上能省15%的空间, 作者自己都承认. Facebook用它也就是为了存储,. RCFile目前没有使用特殊的压缩手段, 例如算术编码, 后缀树等, 没有像InfoBright那样能节省大量io。
Parquet
这个并不是HIVE或者Hadoop生态系统独有的一种方式,而是由Google开发的Dremel系统。Parquet就是基于Dremel的数据模型和算法实现的。详细算法参见论文Dremel: Interactive Analysis of Web-Scale DatasetsParquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与Parquet配合的组件有:
查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
数据模型: Avro, Thrift, Protocol Buffers, POJOs
关于这个我先占个坑,感觉不太好理解,一时半伙应该总结不完。
ORCFile
ORC是在一定程度上扩展了RCFile,是对RCFile的优化。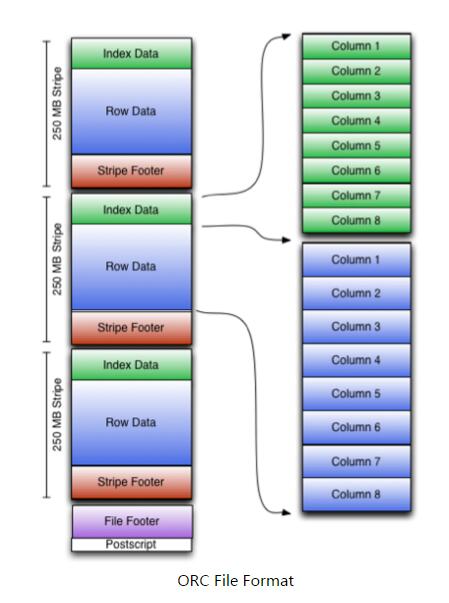
根据结构图,我们可以看到ORCFile在RCFile基础上引申出来Stripe和Footer等。
每个ORC文件首先会被横向切分成多个Stripe,而每个Stripe内部以列存储,所有的列存储在一个文件中,而且每个stripe默认的大小是250MB,相对于RCFile默认的行组大小是4MB,所以比RCFile更高效。
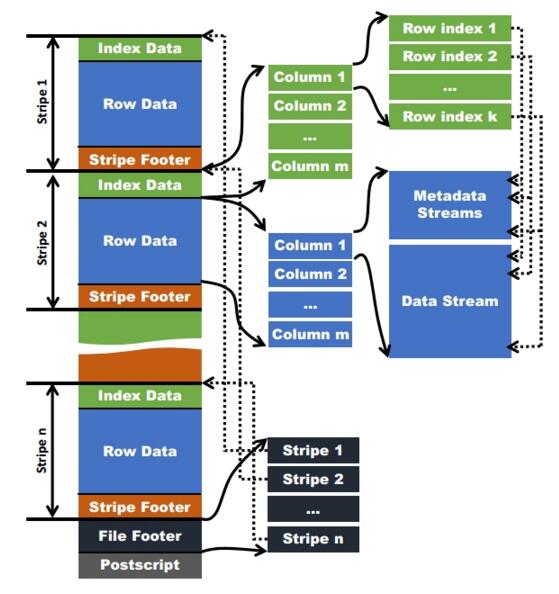
Postscripts中存储该表的行数,压缩参数,压缩大小,列等信息
Stripe Footer中包含该stripe的统计结果,包括Max,Min,count等信息
File Footer中包含该表的统计结果,以及各个Stripe的位置信息
Index Data中保存了该stripe上数据的位置信息,总行数等信息
RowData以stream的形式保存了数据的具体信息
Hive读取数据的时候,根据File Footer读出Stripe的信息,根据IndexData读出数据的偏移量从而读取出数据。
网友有一幅图,形象的说明了这个问题:
ORCFile扩展了RCFile的压缩,除了Run-length,引入了字典编码和BitMap。
采用字典编码,最后存储的数据便是字典中的值、每个字典值的长度以及字段在字典中的位置
至于BitMap,对所有字段都可采用Bit编码来判断该列是否为null,如果为null则Bit值存为0,否则存为1,对于为null的字段在实际编码的时候不需要存储,也就是说字段若为null,是不占用存储空间的。
参考资料
hive文件存储格式Hive-ORC文件存储格式

相关文章推荐
- Hive文件存储格式的测试比较
- hive文件存储格式
- Hive-RCFile文件存储格式
- HIVE文件存储格式的测试比较
- hive文件存储格式
- Hive-RCFile文件存储格式
- hive文件存储格式
- hive文件存储格式
- hive文件存储格式
- Hive文件存储格式
- hive文件存储格式
- HIVE 文件存储格式
- Hive-ORC文件存储格式
- Hive中压缩设置 和 Hive文件存储格式及使用
- Hive中文件存储格式及大小比较测试
- hive文件存储格式
- hive文件存储格式
- Hive-ORC文件存储格式
- 特殊格式文件(视频、声音等) 在数据库中的存储方式
- 大数据:Hive - ORC 文件存储格式