【田渊栋年度总结】FAIR强化学习研究进展,理论研究竞争也相当激烈
2017-12-28 14:58
288 查看
原文链接:点击打开链接
摘要: FAIR研究科学家田渊栋今天在知乎发表他的2017年工作总结。今年的主要研究方向是两个:一是强化学习及其在游戏上的应用,二是深度学习理论分析的探索,文章介绍了这两个方向的研究,在ICML、NIPS等发表的工作。
今年的主要研究方向是两个:一是强化学习及其在游戏上的应用,二是深度学习理论分析的探索。
今年理论方向我们做了一些文章,主要内容是分析浅层网络梯度下降非凸优化的收敛性质。首先是上半年我自己 ICML 的这篇[1],分析了带一层隐层的网络,且输入为高斯分布时的收敛性情况。这篇文章,尤其是去年在 ICLR 17 workshop 上发表的不完全版,可以算是此方向的头一篇,给分析神经网络的非凸问题提供了一个思路。之后 CMU 的杜少雷过来实习,又出了两篇拓展性的文章。两篇都在浅层卷积网络上做了分析,一篇[2]去掉了高斯假设,在一般的输入分布下可以证明梯度下降收敛;另一篇[3]则在高斯假设下分析同时优化两层权重时的情况,证明了并非所有局部极小都是全局最小,这个就推翻了之前很多论文力图推动的方向。
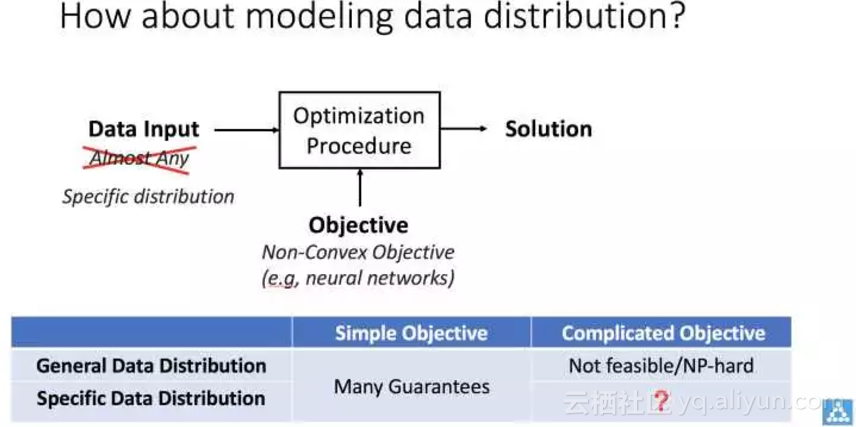
这整个方向背后是对于深度学习原理的探讨和严格化定量化的努力。很容易证明一般的非凸优化要得到最优解至少得要进行地毯式轰炸,做指数级的穷举;而神经网络的效果如此之好,一定有它超出一般非凸优化的特殊原因。我的猜想是因为数据集的 “自然” 分布和特定的网络结构(如卷积)联合起来导致的结果。这种思路同时也将 “最优化得到的解” 和机器学习中提的 “泛化能力” 结合了起来——如果解是因为数据分布而收敛得到的,那当然也能适应于服从同样分布的测试样本,这样泛化能力就有了保证。这样的想法也和我在博士阶段的工作一脉相承:即利用输入数据分布的特殊结构(如图像扭曲操作的群结构),构造新的算法,使得在同样保证恢复未知参数的条件下,样本复杂度更低。
接下来,如何将 “自然” 分布严格化定量化,如何证明在实际系统中用的多层非线性网络结构能抓住这个自然分布并且收敛,就是最大的问题。希望我们在 2018 年继续能做出有意思的工作来。
附带说一句,就算是较为理论的方向,今年的竞争也比较激烈,我在投完 ICML 之后一周,就看到 Arxiv 上有一篇相似的工作出现,第一部分和我推导出的结论完全一样,只是方法不同,可见人工智能领域竞争的激烈程度。
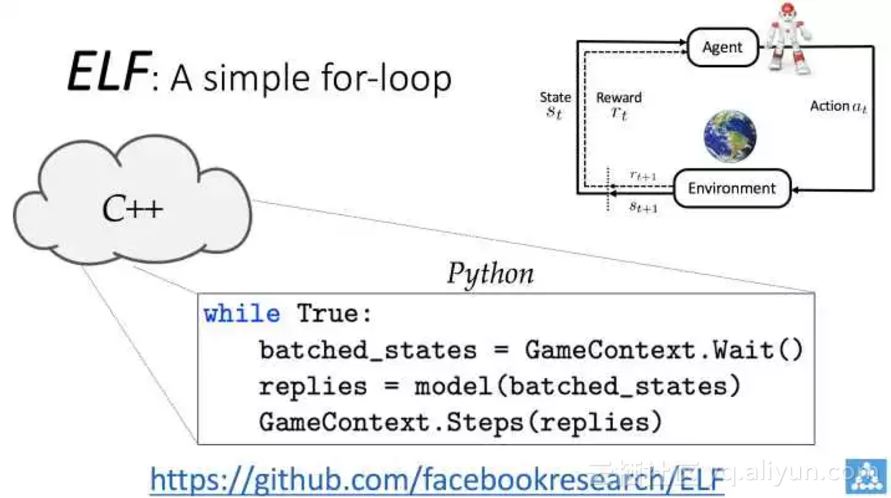
另一个方向是强化学习和游戏。今年我们主要做了系统方面的工作,一个是快速轻量灵活的 ELF 强化学习训练平台(见《黑暗森林中的光之精灵》一文,代码在这里),这个工作已经被今年的 NIPS 接收为 Oral 并且演讲过了[4]。ELF 用多线程代替多进程进行强化学习的训练,并且简化 Python 的接口设计,让只看过教科书的强化学习新人们都能有效率地训练模型。之后我们在 ELF 上面搭建了一个微缩版的即时战略游戏
MiniRTS。MiniRTS 可以以极快的速度模拟(单核 4 万帧每秒,在服务器上运行 1 万局游戏评估模型性能只需 2 分钟),有利于在有限资源限制下的即时战略游戏 AI 研究。在 MiniRTS 上我们用 Actor-Critic 模型训练出一些有意思的人工智能。在这个基础上,我们继续试验了各种参数组合,分析了训练所得智能的一些行为,并且尝试基于模型的强化学习 (model-based RL),获得了一些结果,这篇是放在今年的 NIPS Deep RL Symposium 上,见这里[5]。

还有一个平台是利用现存四万多人工设计的三维房屋(SUNCG 数据集)构造出的 House3D 平台(代码已经开源),在这个平台中我们可以让智能体看到当前视野中的各种物体,获取深度信息和物体类别标注,还可以四处行走探索并遵循基本物理规律。我们挑选了 200 间房屋进行寻路训练,并且在 50 间新房屋中确认了寻路智能的泛化能力。这篇也在 NIPS Deep RL Symposium 上亮相。
明年我们会尝试各种强化学习的已有算法,诸如层次式强化学习(Hierarchical RL),基于模型的强化学习(model-based RL)等等,并且设计新算法,一方面让我们的智能体变得更聪明,另一方面也希望构建一个公开标准的强化学习算法平台库,让大家都能重复(深度)强化学习这个方向的工作,从而推动整个领域的发展。
参考链接:
[1]An Analytical Formula of Population Gradient for two-layered ReLU network and its Applications in Convergence and Critical Point Analysis, arXiv:1703.00560
[2]When is a Convolutional Filter Easy To Learn? arXiv:1709.06129
[3]Gradient Descent Learns One-hidden-layer CNN: Don't be Afraid of Spurious Local Minima arXiv:1712.00779
[4]ELF: Extensive, Lightweight and Flexible Framework for Game Research http://yuandong-tian.com/nips17_oral_final.pdf
[5]https://drive.google.com/file/d/1LMyidobtWabKmQysyhEnWwriI7X2rgQ3/view
==============
我这次回来很多人询问我们组(Facebook AI Research,FAIR)的情况。我们组目前有一百人出头一点,分散在四个不同的地方(加州硅谷,纽约,法国巴黎,及加拿大蒙特利尔),硅谷和纽约人多一些,各约 40 多人。总的来说,我们组还是不错的,研究方向较为自由,计算资源比较丰富,注重文章发表和开源共享,全年招实习生和全职。我现在作为研究经理(Research Manager)负责加州硅谷的强化学习研究,欢迎大家踊跃投送简历,我的邮箱是 yuandong@fb.com.
摘要: FAIR研究科学家田渊栋今天在知乎发表他的2017年工作总结。今年的主要研究方向是两个:一是强化学习及其在游戏上的应用,二是深度学习理论分析的探索,文章介绍了这两个方向的研究,在ICML、NIPS等发表的工作。
今年的主要研究方向是两个:一是强化学习及其在游戏上的应用,二是深度学习理论分析的探索。
今年理论方向我们做了一些文章,主要内容是分析浅层网络梯度下降非凸优化的收敛性质。首先是上半年我自己 ICML 的这篇[1],分析了带一层隐层的网络,且输入为高斯分布时的收敛性情况。这篇文章,尤其是去年在 ICLR 17 workshop 上发表的不完全版,可以算是此方向的头一篇,给分析神经网络的非凸问题提供了一个思路。之后 CMU 的杜少雷过来实习,又出了两篇拓展性的文章。两篇都在浅层卷积网络上做了分析,一篇[2]去掉了高斯假设,在一般的输入分布下可以证明梯度下降收敛;另一篇[3]则在高斯假设下分析同时优化两层权重时的情况,证明了并非所有局部极小都是全局最小,这个就推翻了之前很多论文力图推动的方向。
这整个方向背后是对于深度学习原理的探讨和严格化定量化的努力。很容易证明一般的非凸优化要得到最优解至少得要进行地毯式轰炸,做指数级的穷举;而神经网络的效果如此之好,一定有它超出一般非凸优化的特殊原因。我的猜想是因为数据集的 “自然” 分布和特定的网络结构(如卷积)联合起来导致的结果。这种思路同时也将 “最优化得到的解” 和机器学习中提的 “泛化能力” 结合了起来——如果解是因为数据分布而收敛得到的,那当然也能适应于服从同样分布的测试样本,这样泛化能力就有了保证。这样的想法也和我在博士阶段的工作一脉相承:即利用输入数据分布的特殊结构(如图像扭曲操作的群结构),构造新的算法,使得在同样保证恢复未知参数的条件下,样本复杂度更低。
接下来,如何将 “自然” 分布严格化定量化,如何证明在实际系统中用的多层非线性网络结构能抓住这个自然分布并且收敛,就是最大的问题。希望我们在 2018 年继续能做出有意思的工作来。
附带说一句,就算是较为理论的方向,今年的竞争也比较激烈,我在投完 ICML 之后一周,就看到 Arxiv 上有一篇相似的工作出现,第一部分和我推导出的结论完全一样,只是方法不同,可见人工智能领域竞争的激烈程度。
另一个方向是强化学习和游戏。今年我们主要做了系统方面的工作,一个是快速轻量灵活的 ELF 强化学习训练平台(见《黑暗森林中的光之精灵》一文,代码在这里),这个工作已经被今年的 NIPS 接收为 Oral 并且演讲过了[4]。ELF 用多线程代替多进程进行强化学习的训练,并且简化 Python 的接口设计,让只看过教科书的强化学习新人们都能有效率地训练模型。之后我们在 ELF 上面搭建了一个微缩版的即时战略游戏
MiniRTS。MiniRTS 可以以极快的速度模拟(单核 4 万帧每秒,在服务器上运行 1 万局游戏评估模型性能只需 2 分钟),有利于在有限资源限制下的即时战略游戏 AI 研究。在 MiniRTS 上我们用 Actor-Critic 模型训练出一些有意思的人工智能。在这个基础上,我们继续试验了各种参数组合,分析了训练所得智能的一些行为,并且尝试基于模型的强化学习 (model-based RL),获得了一些结果,这篇是放在今年的 NIPS Deep RL Symposium 上,见这里[5]。
还有一个平台是利用现存四万多人工设计的三维房屋(SUNCG 数据集)构造出的 House3D 平台(代码已经开源),在这个平台中我们可以让智能体看到当前视野中的各种物体,获取深度信息和物体类别标注,还可以四处行走探索并遵循基本物理规律。我们挑选了 200 间房屋进行寻路训练,并且在 50 间新房屋中确认了寻路智能的泛化能力。这篇也在 NIPS Deep RL Symposium 上亮相。
明年我们会尝试各种强化学习的已有算法,诸如层次式强化学习(Hierarchical RL),基于模型的强化学习(model-based RL)等等,并且设计新算法,一方面让我们的智能体变得更聪明,另一方面也希望构建一个公开标准的强化学习算法平台库,让大家都能重复(深度)强化学习这个方向的工作,从而推动整个领域的发展。
参考链接:
[1]An Analytical Formula of Population Gradient for two-layered ReLU network and its Applications in Convergence and Critical Point Analysis, arXiv:1703.00560
[2]When is a Convolutional Filter Easy To Learn? arXiv:1709.06129
[3]Gradient Descent Learns One-hidden-layer CNN: Don't be Afraid of Spurious Local Minima arXiv:1712.00779
[4]ELF: Extensive, Lightweight and Flexible Framework for Game Research http://yuandong-tian.com/nips17_oral_final.pdf
[5]https://drive.google.com/file/d/1LMyidobtWabKmQysyhEnWwriI7X2rgQ3/view
==============
我这次回来很多人询问我们组(Facebook AI Research,FAIR)的情况。我们组目前有一百人出头一点,分散在四个不同的地方(加州硅谷,纽约,法国巴黎,及加拿大蒙特利尔),硅谷和纽约人多一些,各约 40 多人。总的来说,我们组还是不错的,研究方向较为自由,计算资源比较丰富,注重文章发表和开源共享,全年招实习生和全职。我现在作为研究经理(Research Manager)负责加州硅谷的强化学习研究,欢迎大家踊跃投送简历,我的邮箱是 yuandong@fb.com.

相关文章推荐
- 伯克利吴翼&FAIR田渊栋等人提出强化学习环境House3D
- 深度学习在图像识别中的研究进展与展望
- 周志华 《机器学习》之 第十二章(计算学习理论)概念总结
- 深度学习在图像识别中的研究进展与展望----王晓刚
- 深度学习在图像识别中的研究进展与展望
- 深度学习的最新进展及诺亚方舟实验室的研究
- Yoshua Bengio团队最新强化学习研究:智能体通过与环境交互,「分离」变化的独立可控因素
- 知识表示学习研究进展
- 十五个经典算法研究与总结学习笔记之A*搜索算法2
- servlet研究学习总结--OutputStream和PrintWriter的区别
- 从修正Adam到理解泛化:概览2017年深度学习优化算法的最新研究进展
- 从修正Adam到理解泛化:概览2017年深度学习优化算法的最新研究进展
- 软件工程理论学习总结
- 十五个经典算法研究与总结学习笔记之A*搜索算法1
- 深度学习的最新进展及诺亚方舟实验室的研究
- Annual summary(年度总结)--学习计划篇
- 伯克利强化学习新研究:机器人只用几分钟随机数据就能学会轨迹跟踪
- 研究领域总结(一):稀疏——字典学习
- 中科院自动化所介绍深度强化学习进展:从AlphaGo到AlphaGo Zero
- 深度学习研究和进展