Python 爬虫APP URL
2017-12-25 16:36
225 查看
1、安装环境 python 2.7
2、安装scrapy
Pip2.7 install scrapy; 如果不是这么安装,则windows下scrapy命令用不了;先pip2.7 uninstall scrapy再install;3、输入scrapy
有命令提示则安装正确;
4、Windows
下进入爬虫项目里,cd D:\PythonWorkspace\spider; 执行命令:scrapystartprojecttutorial
5、执行以后会出现很多脚本
tutorial/ scrapy.cfg # deploy configuration file tutorial/ # project's Python module, you'll import your code from here __init__.py items.py # project items definition file pipelines.py # project pipelines file settings.py # project settings file spiders/ # a directory where you'll later put your spiders __init__.py
6、编写爬虫脚本
# -*- coding:utf-8 -*-
import sys
import scrapy
reload(sys)
sys.setdefaultencoding('utf-8')class WanDouJia_browser_Spider(scrapy.Spider):
name ="Spider-appLabel_URL"
def start_requests(self):
#app应用大类入口
#url="http://www.wandoujia.com/category/app"
for line in open("D:\\PythonWorkspace\\spider\\Resources\\appLabels.csv".decode('utf-8'),'r'):
keyWord= line.split(",")[0].strip()
url = "http://www.wandoujia.com/search?key="+keyWord.decode('utf-8')
yield scrapy.Request(url=url,meta={'appname':keyWord.decode('utf-8')},callback=self.parse_big_class)
#解析出app的入口url
def parse_big_class(self,response):
appName = response.xpath('//h2[@class="app-title-h2"]/a/text()').extract_first()
url = response.xpath('//h2[@class="app-title-h2"]/a/@href').extract_first()
print appName+" "+url
f=open("appListURLs.csv", 'a')
f.write(str(appName)+","+str(url)+"\n")7、设置调试设置。
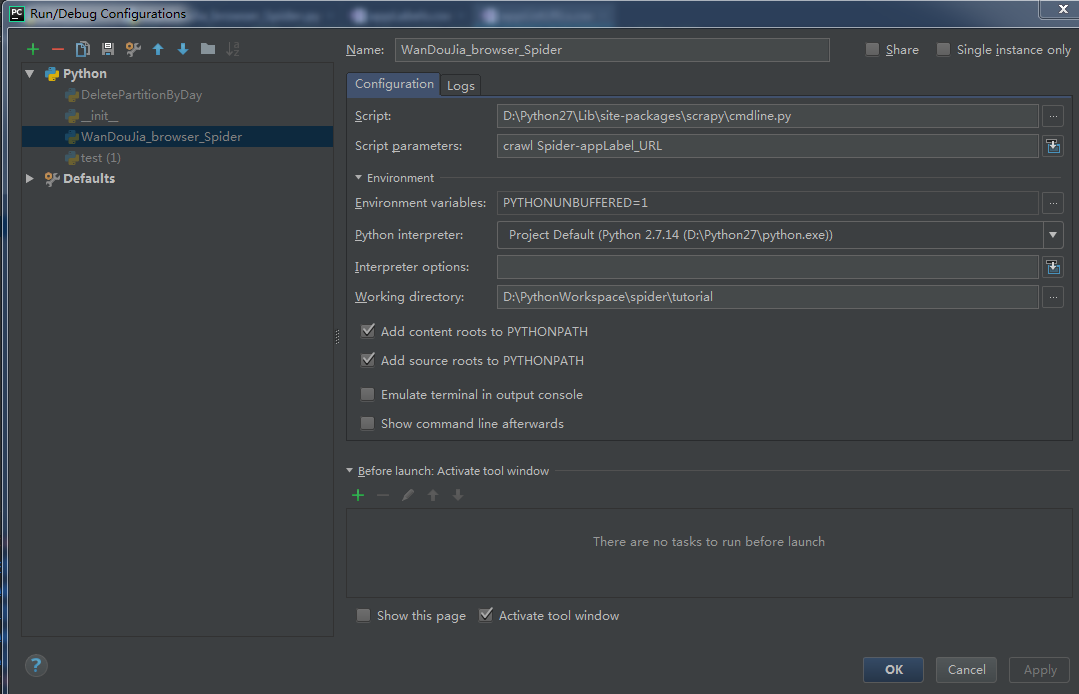
打开pycharm工程调试配置界面(Run -> Edit Configurations)。选择工程。选择调试工程
Spider。
设置执行脚本(Script)。设置为
D:\Python27\Lib\site-packages\scrapy\cmdline.py,
cmdline.py是
scrapy提供的命令行调用脚本,此处将启动脚本设置为
cmdline.py,将需要调试的工程作为参数传递给此脚本。
设置执行脚本参数(Script parameters)。设置为
crawl Spider-appLabel_URL,参数命令参照官方文档提供的爬虫执行命;
设置工作目录(Work Directory)。设置为工程根目录 D:\PythonWorkspace\spider\tutorial,根目录下包含爬虫配置文件
scrapy.cfg。
配置如下图:
配置完成后,可设置断点,调试运行配置好的工程,断点命中,并在控制台输出调试信息。
8、调试会报错,ImportError:
No module named win32api
安装win32api:pip install win32api;9、有可能报错 Unknown
command: crawl
设置工作目录aae2
有误,造成无法识别 scrapy 命令,按照上文所说,将工作目录设置为包含 scrapy.cfg,重新运行,OK。

相关文章推荐
- python爬虫URL重试机制实现(python2.7以及python3.5)
- Python 爬虫之超链接 url中含有中文出错及解决办法
- 【Python学习】Python写爬虫时用到的相对路径和绝对路径--urljoin
- 使用python爬虫爬取百度手机助手网站中app的数据
- Python爬虫关于urlretrieve()函数的使用笔记
- 用爬虫来爬取廖老师的python教程的url
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
- Images, Users, URL Fetch Python API——Google App Engine Services简介
- 【Python3 爬虫】04_urllib.request.urlretrieve
- Python爬虫判断url链接的是下载文件还是html文件
- python爬虫模块之URL管理器模块
- Python爬虫:抓取手机APP的传输数据
- 零基础写python爬虫之爬虫的定义及URL构成
- python 爬虫入门(5) url异常处理 ; cookie使用 ;cookielib
- Python 爬虫 URL中存在中文或特殊符号无法请求的解决方法
- Python爬虫基础(一)--简单的url请求
- python爬虫url带中文解决方案之一
- 零基础写python爬虫之爬虫的定义及URL构成
- python爬虫:传递URL参数学习笔记
- Python爬虫:抓取手机APP的传输数据