python之正则表达式以及网络爬虫
2017-12-22 17:29
447 查看
正则表达式
正则表达式 (Regular Expression) 又称 RegEx, 是用来匹配字符的一种工具. 在一大串字符中寻找你需要的内容. 它常被用在很多方面, 比如网页爬虫, 文稿整理, 数据筛选等等. 最简单的一个例子, 比如我需要爬取网页中每一页的标题. 而网页中的标题常常是这种形式.<title>我是标题</ title>
而且每个网页的标题各不相同, 我就能使用正则表达式, 用一种简单的匹配方法, 一次性选取出成千上万网页的标题信息. 正则表达式绝对不是一天就能学会和记住的, 因为表达式里面的内容非常多, 强烈建议, 现在这个阶段, 你只需要了解正则里都有些什么, 不用记住, 等到你真正需要用到它的时候, 再反过头来, 好好琢磨琢磨, 那个时候才是你需要训练自己记住这些表达式的时候.
简单的匹配
正则表达式无非就是在做这么一回事. 在文字中找到特定的内容, 比如下面的内容. 我们在 “dog runs to cat” 这句话中寻找是否存在 “cat” 或者 “bird”.# matching string pattern1 = "cat" pattern2 = "bird" string = "dog runs to cat" print(pattern1 in string) # True print(pattern2 in string) # False
但是正则表达式绝非不止这样简单的匹配, 它还能做更加高级的内容. 要使用正则表达式, 首先需要调用一个 python 的内置模块
re.
然后我们重复上面的步骤, 不过这次使用正则. 可以看出, 如果
re.search()找到了结果, 它会返回一个
match 的 object. 如果没有匹配到, 它会返回 None. 这个
re.search()只是
re中的一个功能,
之后会介绍其它的功能.
import re # regular expression pattern1 = "cat" pattern2 = "bird" string = "dog runs to cat" print(re.search(pattern1, string)) # <_sre.SRE_Match object; span=(12, 15), match='cat'> print(re.search(pattern2, string)) # None
灵活匹配
除了上面的简单匹配, 下面的内容才是正则的核心内容, 使用特殊的 pattern 来灵活匹配需要找的文字.如果需要找到潜在的多个可能性文字, 我们可以使用
[]将可能的字符囊括进来. 比如
[ab]就说明我想要找的字符可以是
a也可以是
b.
这里我们还需要注意的是, 建立一个正则的规则, 我们在 pattern 的 “” 前面需要加上一个
r用来表示这是正则表达式,
而不是普通字符串. 通过下面这种形式, 如果字符串中出现 “run” 或者是 “ran”, 它都能找到.
# multiple patterns ("run" or "ran")
ptn = r"r[au]n" # start with "r" means regular expression
print(re.search(ptn, "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>同样, 中括号
[]中还可以是以下这些或者是这些的组合. 比如
[A-Z]表示的就是所有大写的英文字母.
[0-9a-z]表示可以是数字也可以是任何小写字母.
print(re.search(r"r[A-Z]n", "dog runs to cat")) # None print(re.search(r"r[a-z]n", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'> print(re.search(r"r[0-9]n", "dog r2ns to cat")) # <_sre.SRE_Match object; span=(4, 7), match='r2n'> print(re.search(r"r[0-9a-z]n", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
按类型匹配
除了自己定义规则, 还有很多匹配的规则时提前就给你定义好了的. 下面有一些特殊的匹配类型给大家先总结一下, 然后再上一些例子.\d : 任何数字
\D : 不是数字
\s : 任何 white space, 如 [\t\n\r\f\v]
\S : 不是 white space
\w : 任何大小写字母, 数字和 “” [a-zA-Z0-9]
\W : 不是 \w
\b : 空白字符 (只在某个字的开头或结尾)
\B : 空白字符 (不在某个字的开头或结尾)
\\ : 匹配 \
. : 匹配任何字符 (除了 \n)
^ : 匹配开头
$ : 匹配结尾
? : 前面的字符可有可无
下面就是具体的举例说明啦.
# \d : decimal digit print(re.search(r"r\dn", "run r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'> # \D : any non-decimal digit print(re.search(r"r\Dn", "run r4n")) # <_sre.SRE_Match object; span=(0, 3), match='run'> # \s : any white space [\t\n\r\f\v] print(re.search(r"r\sn", "r\nn r4n")) # <_sre.SRE_Match object; span=(0, 3), match='r\nn'> # \S : opposite to \s, any non-white space print(re.search(r"r\Sn", "r\nn r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'> # \w : [a-zA-Z0-9_] print(re.search(r"r\wn", "r\nn r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'> # \W : opposite to \w print(re.search(r"r\Wn", "r\nn r4n")) # <_sre.SRE_Match object; span=(0, 3), match='r\nn'> # \b : empty string (only at the start or end of the word) print(re.search(r"\bruns\b", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 8), match='runs'> # \B : empty string (but not at the start or end of a word) print(re.search(r"\B runs \B", "dog runs to cat")) # <_sre.SRE_Match object; span=(8, 14), match=' runs '> # \\ : match \ print(re.search(r"runs\\", "runs\ to me")) # <_sre.SRE_Match object; span=(0, 5), match='runs\\'> # . : match anything (except \n) print(re.search(r"r.n", "r[ns to me")) # <_sre.SRE_Match object; span=(0, 3), match='r[n'> # ^ : match line beginning print(re.search(r"^dog", "dog runs to cat")) # <_sre.SRE_Match object; span=(0, 3), match='dog'> # $ : match line ending print(re.search(r"cat$", "dog runs to cat")) # <_sre.SRE_Match object; span=(12, 15), match='cat'> # ? : may or may not occur print(re.search(r"Mon(day)?", "Monday")) # <_sre.SRE_Match object; span=(0, 6), match='Monday'> print(re.search(r"Mon(day)?", "Mon")) # <_sre.SRE_Match object; span=(0, 3), match='Mon'>
如果一个字符串有很多行, 我们想使用
^形式来匹配行开头的字符, 如果用通常的形式是不成功的. 比如下面的
“I” 出现在第二行开头, 但是使用
r"^I"却匹配不到第二行, 这时候, 我们要使用 另外一个参数,
让
re.search()可以对每一行单独处理. 这个参数就是
flags=re.M,
或者这样写也行
flags=re.MULTILINE.
string = """ dog runs to cat. I run to dog. """ print(re.search(r"^I", string)) # None print(re.search(r"^I", string, flags=re.M)) # <_sre.SRE_Match object; span=(18, 19), match='I'>
重复匹配
如果我们想让某个规律被重复使用, 在正则里面也是可以实现的, 而且实现的方式还有很多. 具体可以分为这三种:*: 重复零次或多次
+: 重复一次或多次
{n, m} : 重复 n 至 m 次{n} : 重复 n 次举例如下:
# * : occur 0 or more times
print(re.search(r"ab*", "a")) # <_sre.SRE_Match object; span=(0, 1), match='a'>
print(re.search(r"ab*", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
# + : occur 1 or more times
print(re.search(r"ab+", "a")) # None
print(re.search(r"ab+", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
# {n, m} : occur n to m times
print(re.search(r"ab{2,10}", "a")) # None
print(re.search(r"ab{2,10}", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
分组
我们甚至可以为找到的内容分组, 使用 ()能轻松实现这件事. 通过分组, 我们能轻松定位所找到的内容. 比如在这个
(\d+)组里,
需要找到的是一些数字, 在
(.+)这个组里, 我们会找到 “Date: “ 后面的所有内容. 当使用
match.group()时,
他会返回所有组里的内容, 而如果给
.group(2)里加一个数, 它就能定位你需要返回哪个组里的信息.
match = re.search(r"(\d+), Date: (.+)", "ID: 021523, Date: Feb/12/2017") print(match.group()) # 021523, Date: Feb/12/2017 print(match.group(1)) # 021523 print(match.group(2)) # Date: Feb/12/2017
有时候, 组会很多, 光用数字可能比较难找到自己想要的组, 这时候, 如果有一个名字当做索引, 会是一件很容易的事. 我们字需要在括号的开头写上这样的形式
?P<名字>就给这个组定义了一个名字.
然后就能用这个名字找到这个组的内容.
match = re.search(r"(?P<id>\d+), Date: (?P<date>.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group('id')) # 021523
print(match.group('date')) # Date: Feb/12/2017
findall
前面我们说的都是只找到了最开始匹配上的一项而已, 如果需要找到全部的匹配项, 我们可以使用 findall功能.
然后返回一个列表. 注意下面还有一个新的知识点,
|是 or 的意思, 要不是前者要不是后者.
# findall print(re.findall(r"r[ua]n", "run ran ren")) # ['run', 'ran'] # | : or print(re.findall(r"(run|ran)", "run ran ren")) # ['run', 'ran']
replace
我们还能通过正则表达式匹配上一些形式的字符串然后再替代掉这些字符串. 使用这种匹配 re.sub(), 将会比
python 自带的
string.replace()要灵活多变.
print(re.sub(r"r[au]ns", "catches", "dog runs to cat")) # dog catches to cat
split
再来我们 Python 中有个字符串的分割功能, 比如想获取一句话中所有的单词. 比如 "a is b".split(" "),这样它就会产生一个列表来保存所有单词. 但是在正则中, 这种普通的分割也可以做的淋漓精致.
print(re.split(r"[,;\.]", "a;b,c.d;e")) # ['a', 'b', 'c', 'd', 'e']
compile
最后, 我们还能使用 compile 过后的正则, 来对这个正则重复使用. 先将正则 compile 进一个变量, 比如 compiled_re,
然后直接使用这个
compiled_re来搜索.
compiled_re = re.compile(r"r[ua]n")
print(compiled_re.search("dog ran to cat")) # <_sre.SRE_Match object; span=(4, 7), match='ran'>
小抄
为了大家方便记忆, 我很久以前在网上找到了一份小抄, 这个小抄的原出处应该是这里. 小抄很有用, 不记得的时候回头方便看.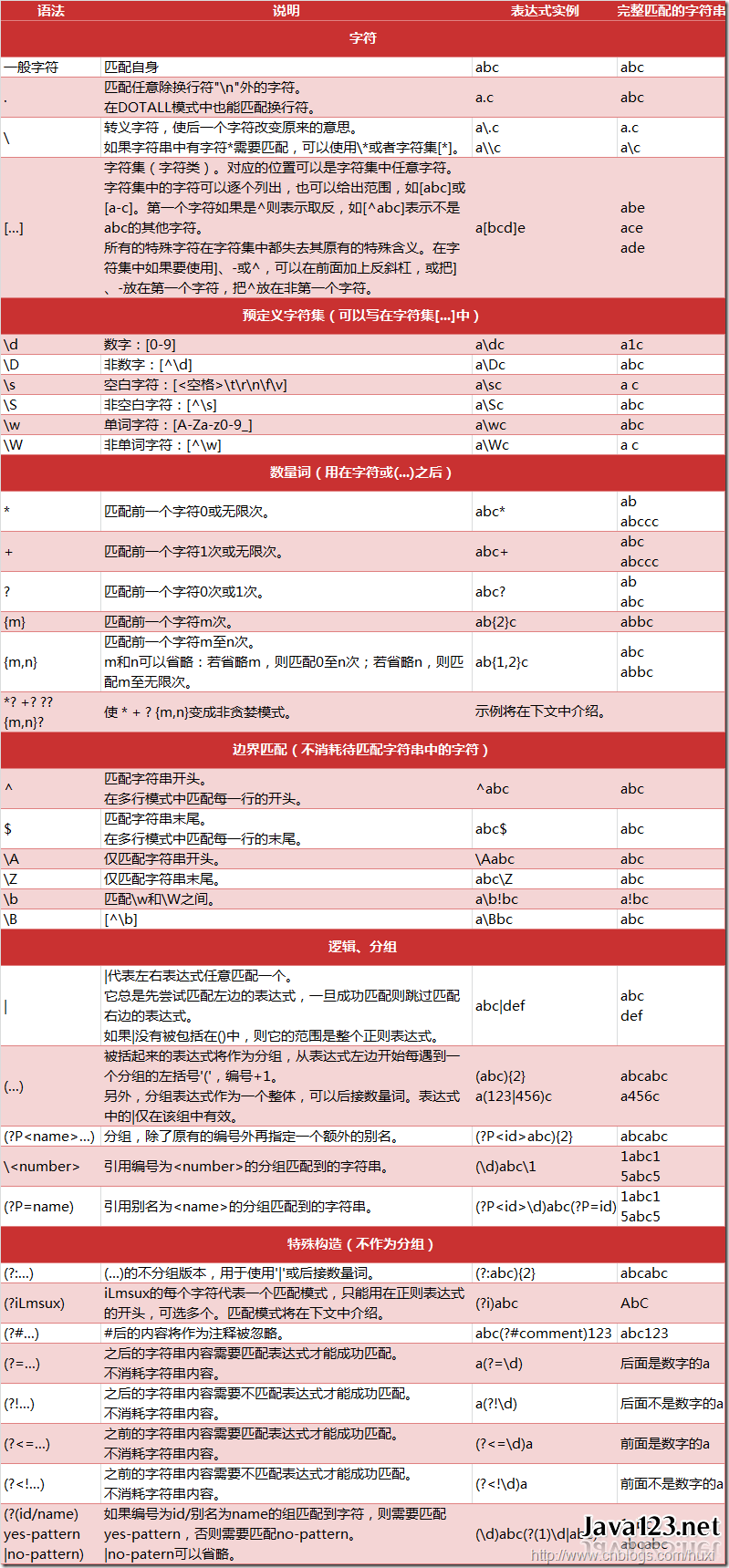
了解网页结构
学习爬虫, 首先要懂的是网页. 支撑起各种光鲜亮丽的网页的不是别的, 全都是一些代码. 这种代码我们称之为 HTML, HTML 是一种浏览器(Chrome, Safari, IE, Firefox等)看得懂的语言, 浏览器能将这种语言转换成我们用肉眼看到的网页.所以 HTML 里面必定存在着很多规律, 我们的爬虫就能按照这样的规律来爬取你需要的信息.
其实除了 HTML, 一同构建多彩/多功能网页的组件还有 CSS 和 JavaScript.
但是这个简单的爬虫教程, 大部分时间会将会使用 HTML. CSS 和 JavaScript 会在后期简单介绍一下. 因为爬网页的时候多多少少还是要和 CSS JavaScript 打交道的.
虽然莫烦Python主打的是机器学习的教程. 但是这个爬虫教程适用于任何想学爬虫的朋友们. 从机器学习的角度看, 机器学习中的大量数据, 也是可以从这些网页中来, 使用爬虫来爬取各种网页上面的信息, 然后再放入各种机器学习的方法, 这样的应用途径正在越来越多被采用. 所以如果你的数据也是分散在各个网页中, 爬虫是你减少人力劳动的必修课.
网络基本组成部分
在真正进入爬虫之前, 我们先来做一下热身运动, 弄明白网页的基础, HTML 有哪些组成部分, 是怎么样运作的. 如果你已经非常熟悉网页的构造了, 欢迎直接跳过这一节, 进入下面的学习.我制作了一个非常简易的网页, 给大家呈现以下最骨感的 HTML 结构. 如果你点开它, 呈现在你眼前的, 就是下面这张图的上半部分. 而下半部分就是我们网页背后的 HTML code.
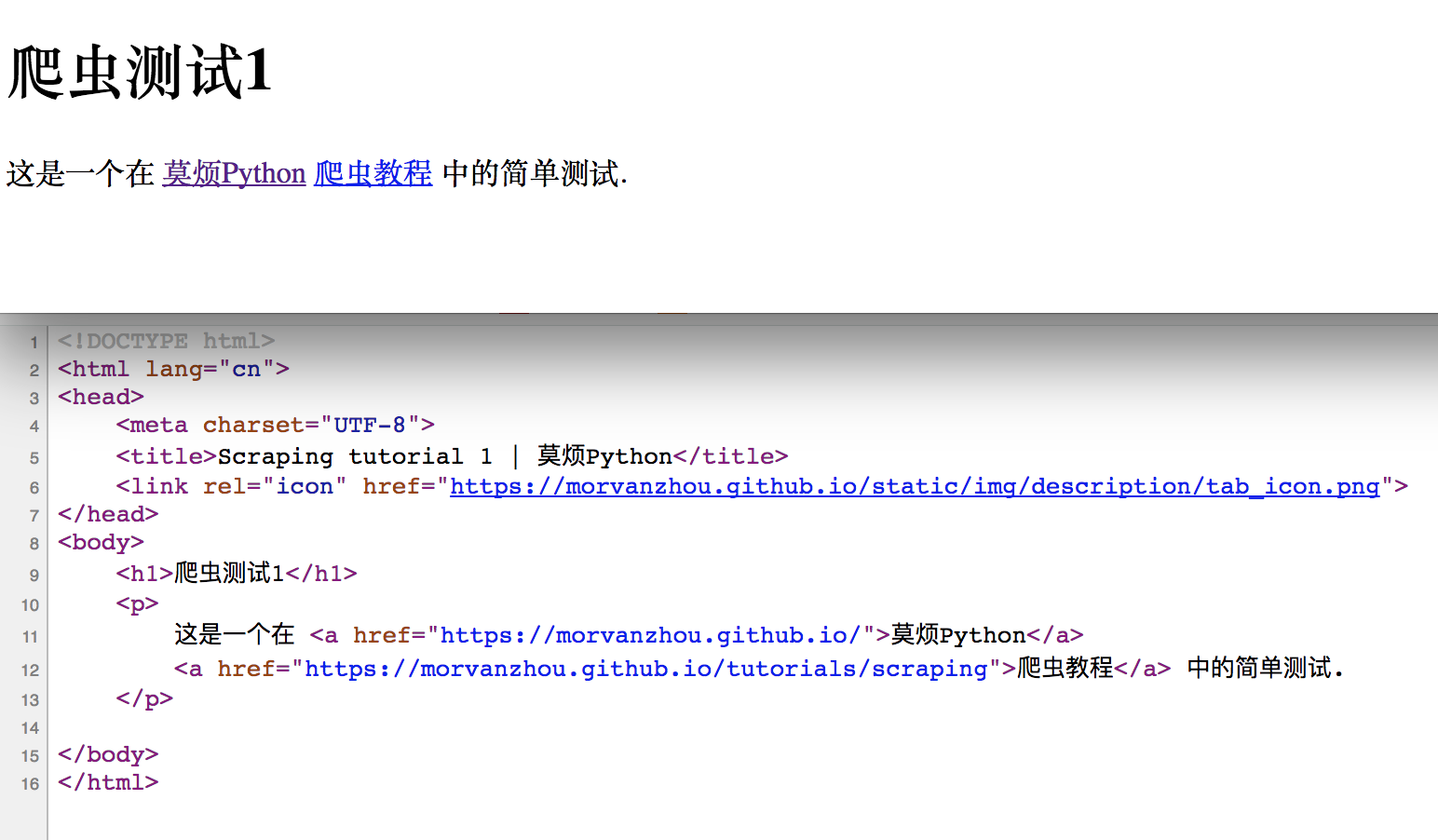
想问我是如何看到 HTML 的 source code 的? 其实很简单, 在你的浏览器中, 显示网页的地方, 点击鼠标右键, 大多数浏览器都会有类似这样一个选项 “View Page Source”. 点击它就能看到页面的源码了.
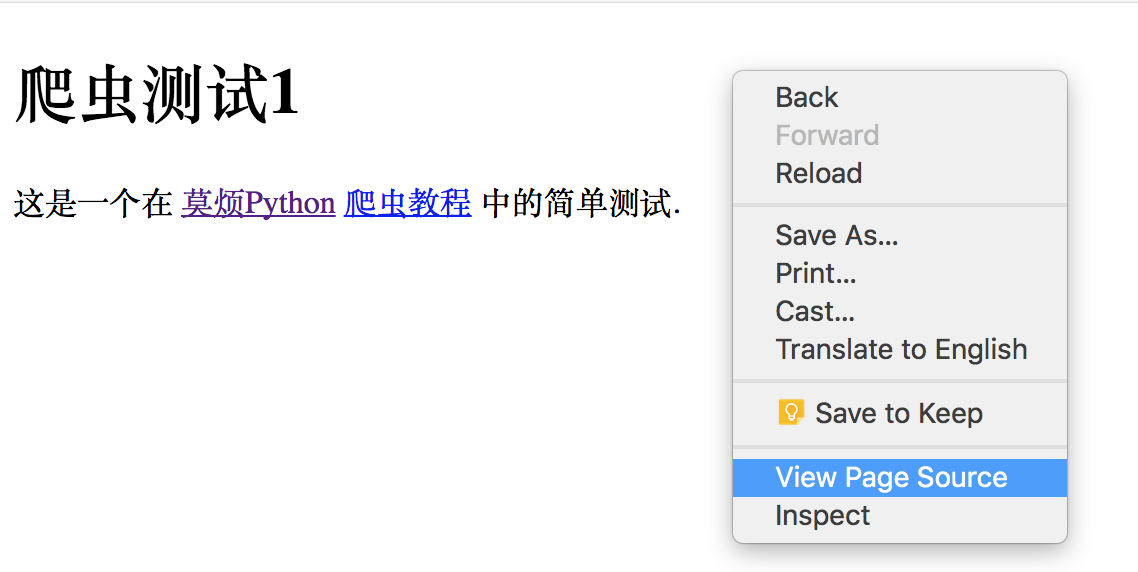
在 HTML 中, 基本上所有的实体内容, 都会有个 tag 来框住它. 而这个被 tag 住的内容, 就可以被展示成不同的形式, 或有不同的功能. 主体的 tag 分成两部分,
header和
body.
在
header中, 存放这一些网页的网页的元信息, 比如说
title,
这些信息是不会被显示到你看到的网页中的. 这些信息大多数时候是给浏览器看, 或者是给搜索引擎的爬虫看.
<head> <meta charset="UTF-8"> <title>Scraping tutorial 1 | 莫烦Python</title> <link rel="icon" href="https://morvanzhou.github.io/static/img/description/tab_icon.png"> </head>
HTML 的第二大块是
body, 这个部分才是你看到的网页信息. 网页中的
heading,
视频, 图片和文字等都存放在这里. 这里的
<h1></h1>tag 就是主标题, 我们看到呈现出来的效果就是大一号的文字.
<p></p>里面的文字就是一个段落.
<a></a>里面都是一些链接.
所以很多情况, 东西都是放在这些 tag 中的.
<body> <h1>爬虫测试1</h1> <p> 这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a> <a href="https://morvanzhou.github.io/tutorials/scraping">爬虫教程</a> 中的简单测试. </p> </body>
爬虫想要做的就是根据这些 tag 来找到合适的信息.
用 Python 登录网页
好了, 对网页结构和 HTML 有了一些基本认识以后, 我们就能用 Python 来爬取这个网页的一些基本信息. 首先要做的, 是使用 Python 来登录这个网页, 并打印出这个网页 HTML 的 source code. 注意, 因为网页中存在中文, 为了正常显示中文, read()完以后,
我们要对读出来的文字进行转换,
decode()成可以正常显示中文的形式.
from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen(
"https://morvanzhou.github.io/static/scraping/basic-structure.html"
).read().decode('utf-8')
print(html)print 出来就是下面这样啦. 这就证明了我们能够成功读取这个网页的所有信息了. 但我们还没有对网页的信息进行汇总和利用. 我们发现, 想要提取一些形式的信息, 合理的利用 tag 的名字十分重要.
<!DOCTYPE html>
<html lang="cn">
<head> <meta charset="UTF-8"> <title>Scraping tutorial 1 | 莫烦Python</title> <link rel="icon" href="https://morvanzhou.github.io/static/img/description/tab_icon.png"> </head><body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/tutorials/scraping">爬虫教程</a> 中的简单测试.
</p>
</body>
</html>
匹配网页内容
所以这里我们使用 Python 的正则表达式 RegEx 进行匹配文字, 筛选信息的工作. 我有一个很不错的正则表达式的教程, 如果是初级的网页匹配, 我们使用正则完全就可以了, 高级一点或者比较繁琐的匹配, 我还是推荐使用 BeautifulSoup.不急不急, 我知道你想偷懒, 我之后马上就会教 beautiful soup 了. 但是现在我们还是使用正则来做几个简单的例子, 让你熟悉一下套路.
如果我们想用代码找到这个网页的 title, 我们就能这样写. 选好要使用的 tag 名称
<title>.
使用正则匹配.
import re
res = re.findall(r"<title>(.+?)</title>", html)
print("\nPage title is: ", res[0])
# Page title is: Scraping tutorial 1 | 莫烦Python如果想要找到中间的那个段落
<p>, 我们使用下面方法, 因为这个段落在 HTML 中还夹杂着 tab, new
line, 所以我们给一个
flags=re.DOTALL来对这些 tab, new line 不敏感.
res = re.findall(r"<p>(.*?)</p>", html, flags=re.DOTALL) # re.DOTALL if multi line
print("\nPage paragraph is: ", res[0])
# Page paragraph is:
# 这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
# <a href="https://morvanzhou.github.io/tutorials/scraping">爬虫教程</a> 中的简单测试.最后一个练习是找一找所有的链接, 这个比较有用, 有时候你想找到网页里的链接, 然后下载一些内容到电脑里, 就靠这样的途径了.
res = re.findall(r'href="(.*?)"', html)
print("\nAll links: ", res)
# All links: ['https://morvanzhou.github.io/static/img/description/tab_icon.png', 'https://morvanzhou.github.io/', 'https://morvanzhou.github.io/tutorials/scraping']下次我们就来看看为了图方面, 我们如何使用 BeautifulSoup.

相关文章推荐
- Python 网络爬虫-正则表达式、BeautifulSoup、lxml三种提取方法
- 在学习python网络爬虫时用到的正则表达式
- Python 网络爬虫 009 (编程) 通过正则表达式来获取一个网页中的所有的URL链接,并下载这些URL链接的源代码
- python实现简单爬虫以及正则表达式简述
- python3实现网络爬虫(6)--正则表达式和BeautifulSoup配合使用
- Python 网络爬虫 009 (编程) 通过正则表达式来获取一个网页中的所有的URL链接,并下载这些URL链接的源代码
- 分享录制的正则表达式入门、高阶以及使用 .NET 实现网络爬虫视频教程
- Python:入门到实现网络爬虫 Day4 --正则表达式
- 05精通Python网络爬虫——正则表达式的运用
- [Python] 网络爬虫和正则表达式学习总结
- python爬虫正则表达式之处理换行符以及其他
- Python--正则表达式/单线程网络爬虫
- 用python写网络爬虫-使用xpath代替正则表达式
- 网络爬虫(六):Python中的正则表达式教程
- Python正则表达式以及爬虫
- python网络爬虫之正则表达式(续)
- Python 爬虫学习笔记之正则表达式
- Python 爬虫小程序(正则表达式的应用)
- python-网络爬虫初学一:获取网页源码以及发送POST和GET请求
- 【python爬虫学习2.正则表达式】