对于unicode的个人理解2:emoji表情
2017-12-14 23:07
369 查看
emoji(a磨叽)
Emoji (絵文字,词义来自日语えもじ,e-moji,moji在日语中的含义是字符)是一套起源于日本的12x12像素表情符号,由栗田穣崇(Shigetaka Kurit)创作,最早在日本网络及手机用户中流行,自苹果公司发布的iOS 5输入法中加入了emoji后,这种表情符号开始席卷全球,目前emoji已被大多数现代计算机系统所兼容的Unicode编码采纳,普遍应用于各种手机短信和社交网络中。近期,更是有不少网友用emoji图案
可能对于emoji的了解,大家都是这一点进来的:“emoji如何在数据库中保存?”可是,弱弱的说一句,这是你们后台的,(emoji在unicode中是4个字节的,所以你数据库设置三个字节是没用的,最好是设置成为utf8md4的编译)
举个简单的例子:
但是,usc-2的范围就那么大。他到底包括哪些呢?
1.中文的unicode位置:<a>360doc</a>
2.unicode的第1个panel的分布区域:“<a>unicode平面映射</a>”
有些时候,太阳公公不止是出现在天上,有时候也会出现在我们的电脑上,那么,他是怎么出来的?其实,太阳公公在unicode中也是有一个位置的,他的位置是2600,什么意思?来段简单的代码

就这样,太阳公公出现了,查询下刚刚发的,我们可以发现,太阳公公的u+2600代表的是杂项符号,所以也不算是emoji的
真正的emoji,是不会存放在第一panel的,通常是放在我们称之为辅助平面的panel里面
辅助平面:鉴于 Unicode 原有的16位元空间不足以应用,从
Unicode 3.1 版本开始,设立了16个辅助平面,使 Unicode 的可使用空间由六万多字增至约一百万字。原有的 Unicode 空间称为基本平面或基本多文种平面 (Basic
Multilingual Plane, 简称 BMP)。辅助平面字符要用上4字节来储存。-------------------百度百科
这时候要注意下,辅助平面的是4个字节,但是,我们使用的js是2个字节的这个时候就衍生出了一个问题:
js如何表示辅助平面的unicode?
现在,我们以一个emoji来做例子
emoji-unicode查询:<a >表情的unicode查询</a>
u+1f602:笑哭的表情,表示应该很多人喜欢这个吧
现在,直接编辑上我们的代码:
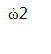
这是什么?1个什么表情加上一个2????
那么他是怎么产生的?
首先,1f602,由于js在识别的时候,是这样的:由于是4位数,所以js是将其才分为1f60,还有一个单独的2,然后我们在写的时候,实际上就变成了:\u1f60外加一个2.而1f60是一个希腊符号(好像!!!不及得了)
那么这就是我们今天的问题,怎么正确的书写一个表情?
<A>https://mathiasbynens.be/notes/javascript-unicode</a>
上方作者的博客写的很棒,强力推荐
作者向我们讲述了有两种方法
1.使用一个{}

??????乱码是什么?这是因为电脑没有这个表情。当然, 用手机也许会有不一样的天地
嗯,看样子我魅族也没那么惨,至少还不砸我面子
2.使用两个unicode来拆分。
回到刚刚的unicode的最最最重要的那个panel,我们看到了这么一句话:

我们可以使用d800-dbff来代表utf-16的高半区,以及使用dc00-dfff来表示底半区
怎么用????当然,是有换算公式的
先来段文字帮助理解下:
C.1 UTF-16的规定UTF-16的规定如下:
1) 高半区应当是BMP的D8到DB共4行,即,S区之中码位从D800到DBFF的1024个字位。
2) 低半区应当是BMP的DC到DF共4行,即,S区之中码位从DC00到DFFF的1024个字位。
3) 高半区和低半区的所有字位应当永远保留给UTF-16编码表示形式使用。
5) 在UTF-16中,UCS-4编码表示在到0010FFFF范围中的任何UCS字符都应当用由S区的两个RC元素组成的一个序列来表示,第一个RC元素取自S区的高半区,而第二个RC元素取自S区的低半区。
这些字符在UCS-4和UTF-16之间的映射如C.3所示

---------------------------------------
GB 13000—2010/ISO/IEC 10646:2003《信息技术 通用多八位编码字符集(UCS)》我想应该还是有人嫌上面的公式太麻烦吧。。。那就来个简单的:
最后。我们算出来的程序是这样的:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<!-- cry-joy -->
<div class="s0"><span></span></div>
<script>
var s0="\ud83d\ude02"
console.log(Math.floor((0x1F6A2-0x10000)/0x400)+0xD800);//55357
console.log((0x1F602-0x10000) % 0x400+0xDC00);//56834
document.querySelector(".s0 span").innerText = s0;
</script>
</body>
</html>运行起来是这样的:

就这样,希望能记住这个公式,但是更绝得知道怎么计算,以及长度的问题更好
Emoji (絵文字,词义来自日语えもじ,e-moji,moji在日语中的含义是字符)是一套起源于日本的12x12像素表情符号,由栗田穣崇(Shigetaka Kurit)创作,最早在日本网络及手机用户中流行,自苹果公司发布的iOS 5输入法中加入了emoji后,这种表情符号开始席卷全球,目前emoji已被大多数现代计算机系统所兼容的Unicode编码采纳,普遍应用于各种手机短信和社交网络中。近期,更是有不少网友用emoji图案
可能对于emoji的了解,大家都是这一点进来的:“emoji如何在数据库中保存?”可是,弱弱的说一句,这是你们后台的,(emoji在unicode中是4个字节的,所以你数据库设置三个字节是没用的,最好是设置成为utf8md4的编译)
举个简单的例子:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<!-- a -->
<div class="s0"><span></span></div>
<script>
var s0 = "\u0061";
console.log(s0);
document.querySelector(".s0 span").innerText = s0;
</script>
</body>
</html> 上回说到,js使用的是usc-2的编码,所以对于2个字节的unicode,js是解析起来66的但是,usc-2的范围就那么大。他到底包括哪些呢?
1.中文的unicode位置:<a>360doc</a>
2.unicode的第1个panel的分布区域:“<a>unicode平面映射</a>”
有些时候,太阳公公不止是出现在天上,有时候也会出现在我们的电脑上,那么,他是怎么出来的?其实,太阳公公在unicode中也是有一个位置的,他的位置是2600,什么意思?来段简单的代码
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<!-- sun -->
<div class="s0"><span></span></div>
<script>
var s0 = "\u2600";
console.log(s0);
document.querySelector(".s0 span").innerText = s0;
</script>
</body>
</html>注意哦,上面的不再是0061,而是2600,那么浏览器的是什么呢?就这样,太阳公公出现了,查询下刚刚发的,我们可以发现,太阳公公的u+2600代表的是杂项符号,所以也不算是emoji的
真正的emoji,是不会存放在第一panel的,通常是放在我们称之为辅助平面的panel里面
辅助平面:鉴于 Unicode 原有的16位元空间不足以应用,从
Unicode 3.1 版本开始,设立了16个辅助平面,使 Unicode 的可使用空间由六万多字增至约一百万字。原有的 Unicode 空间称为基本平面或基本多文种平面 (Basic
Multilingual Plane, 简称 BMP)。辅助平面字符要用上4字节来储存。-------------------百度百科
这时候要注意下,辅助平面的是4个字节,但是,我们使用的js是2个字节的这个时候就衍生出了一个问题:
js如何表示辅助平面的unicode?
现在,我们以一个emoji来做例子
emoji-unicode查询:<a >表情的unicode查询</a>
u+1f602:笑哭的表情,表示应该很多人喜欢这个吧
现在,直接编辑上我们的代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<!-- cry-joy -->
<div class="s0"><span></span></div>
<script>
var s0 = "\u1f602";
console.log(s0);
document.querySelector(".s0 span").innerText = s0;
</script>
</body>
</html>猜猜结果是什么?笑哭的表情?很抱歉错误哦,答案是:这是什么?1个什么表情加上一个2????
那么他是怎么产生的?
首先,1f602,由于js在识别的时候,是这样的:由于是4位数,所以js是将其才分为1f60,还有一个单独的2,然后我们在写的时候,实际上就变成了:\u1f60外加一个2.而1f60是一个希腊符号(好像!!!不及得了)
那么这就是我们今天的问题,怎么正确的书写一个表情?
<A>https://mathiasbynens.be/notes/javascript-unicode</a>
上方作者的博客写的很棒,强力推荐
作者向我们讲述了有两种方法
1.使用一个{}
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<!-- cry-joy -->
<div class="s0"><span></span></div>
<script>
var s0 = "\u{1f602}";
console.log(s0);
document.querySelector(".s0 span").innerText = s0;
</script>
</body>
</html>最后界面的效果是这样的:??????乱码是什么?这是因为电脑没有这个表情。当然, 用手机也许会有不一样的天地
嗯,看样子我魅族也没那么惨,至少还不砸我面子
2.使用两个unicode来拆分。
回到刚刚的unicode的最最最重要的那个panel,我们看到了这么一句话:
我们可以使用d800-dbff来代表utf-16的高半区,以及使用dc00-dfff来表示底半区
怎么用????当然,是有换算公式的
先来段文字帮助理解下:
C.1 UTF-16的规定UTF-16的规定如下:
1) 高半区应当是BMP的D8到DB共4行,即,S区之中码位从D800到DBFF的1024个字位。
2) 低半区应当是BMP的DC到DF共4行,即,S区之中码位从DC00到DFFF的1024个字位。
3) 高半区和低半区的所有字位应当永远保留给UTF-16编码表示形式使用。
5) 在UTF-16中,UCS-4编码表示在到0010FFFF范围中的任何UCS字符都应当用由S区的两个RC元素组成的一个序列来表示,第一个RC元素取自S区的高半区,而第二个RC元素取自S区的低半区。
这些字符在UCS-4和UTF-16之间的映射如C.3所示
---------------------------------------
GB 13000—2010/ISO/IEC 10646:2003《信息技术 通用多八位编码字符集(UCS)》我想应该还是有人嫌上面的公式太麻烦吧。。。那就来个简单的:
y = Math.floor((0x1F6A2-0x10000)/0x400)+0xD800; z = (0x1F602-0x10000) % 0x400+0xDC00 ;
最后。我们算出来的程序是这样的:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<!-- cry-joy -->
<div class="s0"><span></span></div>
<script>
var s0="\ud83d\ude02"
console.log(Math.floor((0x1F6A2-0x10000)/0x400)+0xD800);//55357
console.log((0x1F602-0x10000) % 0x400+0xDC00);//56834
document.querySelector(".s0 span").innerText = s0;
</script>
</body>
</html>运行起来是这样的:
就这样,希望能记住这个公式,但是更绝得知道怎么计算,以及长度的问题更好

相关文章推荐
- 对于unicode的个人理解1:历史
- UCOS2:对于信号量,互斥信号量,事件标志组的个人理解
- 个人对于冒泡排序和选择排序的理解
- 对于oauth2.0的个人理解-客户端篇
- Java关于个人对于Socket的理解,Socket多线程批量上传文件,适合新手
- 对于":nth-child"前面加空格造成区别个人理解
- 个人对于lower_bound的理解
- 对于this和$(this)的个人理解
- 个人对码表的理解(ASCII,GBK,Unicode,UTF-8等)。
- UCOS-II:对于信号量,互斥信号量,事件标志组的个人理解-转
- 已有打开的与此命令相关联的DataReader,必须首先将它关闭。对于此异常的个人的理解!
- 个人对于项目成功失败的理解
- 个人对于三层架构解决项目问题的理解
- 个人对于spring依赖注入和控制反转概念的理解
- 对于AOP切面编程的一些个人理解
- 对于形参和实参的个人理解
- 个人对于PHP设计模式之工厂模式的理解
- 对于dequeueReusableCellWithIdentifier:的个人理解
- 对于S3C2440的看门狗定时器的个人理解
- 对于rpc遇到的疑问以及个人理解