【代码分享】一种异常值检测方法、原理 (基于箱线图)
2017-12-11 13:52
721 查看
先介绍使用到的方法原理,也就是一种异常检测的方法。
首先要先了解箱线图。
先看一下什么是箱线图,下面这个是常见的箱线图样子。
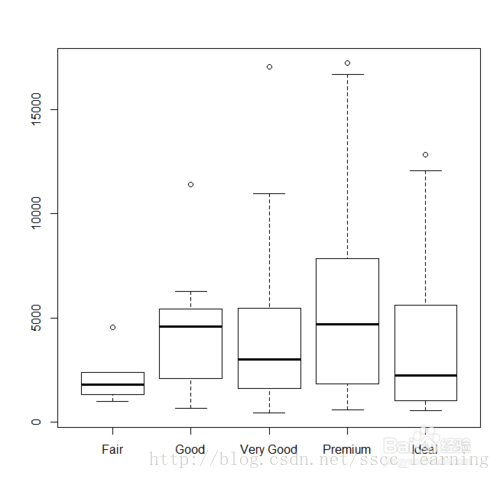
具体含义如下,首先计算出第一四分位数(Q1)、中位数、第三四分位数(Q3)。
中位数我们都知道,就是将一组数字按从小到大的顺序排序后,处于中间位置(也就是50%位置)的数字。
同理,第一四分位数、第三四分位数是按从小到大的顺序排序后,处于25%、75%的数字。
令 IQR=Q3−Q1 ,那么 Q3+1.5(IQR) 和 Q1−1.5(IQR) 之间的值就是可接受范围内的数值,这两个值之外的数认为是异常值。
在Q3+1.5IQR(四分位距)和Q1-1.5IQR处画两条与中位线一样的线段,这两条线段为异常值截断点,称其为内限;在Q3+3IQR和Q1-3IQR处画两条线段,称其为外限。
处于内限以外位置的点表示的数据都是异常值,其中在内限与外限之间的异常值为温和的异常值(mild outliers),在外限以外的为极端的异常值(li)的异常值extreme outliers。这种异常值的检测方法叫做Tukey’s method。
从矩形盒两端边向外各画一条线段直到不是异常值的最远点 表示该批数据正常值的分布区间点,示该批数据正常值的分布区间。
一般用“〇”标出温和的异常值,用“*”标出极端的异常值。

代码原地址:https://www.kaggle.com/yassineghouzam/titanic-top-4-with-ensemble-modeling/notebook
通过上面对箱线图的介绍,相信同时也清楚了异常值检测的方法。
假设我们现在已经有了一份pandas.DataFrame读取后的数据df,其中需要进行检测的列保存在features列表中,每个样本能忍受的最大异常值数量为n。
首先要先了解箱线图。
箱线图
箱线图(Boxplot)也称箱须图(Box-whisker Plot),是利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法,它也可以粗略地看出数据是否具有有对称性,分布的分散程度等信息,特别可以用于对几个样本的比较。 ——MBAlib 箱线图先看一下什么是箱线图,下面这个是常见的箱线图样子。
具体含义如下,首先计算出第一四分位数(Q1)、中位数、第三四分位数(Q3)。
中位数我们都知道,就是将一组数字按从小到大的顺序排序后,处于中间位置(也就是50%位置)的数字。
同理,第一四分位数、第三四分位数是按从小到大的顺序排序后,处于25%、75%的数字。
令 IQR=Q3−Q1 ,那么 Q3+1.5(IQR) 和 Q1−1.5(IQR) 之间的值就是可接受范围内的数值,这两个值之外的数认为是异常值。
在Q3+1.5IQR(四分位距)和Q1-1.5IQR处画两条与中位线一样的线段,这两条线段为异常值截断点,称其为内限;在Q3+3IQR和Q1-3IQR处画两条线段,称其为外限。
处于内限以外位置的点表示的数据都是异常值,其中在内限与外限之间的异常值为温和的异常值(mild outliers),在外限以外的为极端的异常值(li)的异常值extreme outliers。这种异常值的检测方法叫做Tukey’s method。
从矩形盒两端边向外各画一条线段直到不是异常值的最远点 表示该批数据正常值的分布区间点,示该批数据正常值的分布区间。
一般用“〇”标出温和的异常值,用“*”标出极端的异常值。
python 代码分享
这段检测异常值的代码是从kaggle上看到的,很简单也很有用。代码原地址:https://www.kaggle.com/yassineghouzam/titanic-top-4-with-ensemble-modeling/notebook
通过上面对箱线图的介绍,相信同时也清楚了异常值检测的方法。
假设我们现在已经有了一份pandas.DataFrame读取后的数据df,其中需要进行检测的列保存在features列表中,每个样本能忍受的最大异常值数量为n。
# Outlier detection import pandas as pd import numpy as np from collections import Counter def detect_outliers(df,n,features): outlier_indices = [] # iterate over features(columns) for col in features: # 1st quartile (25%) Q1 = np.percentile(df[col], 25) # 3rd quartile (75%) Q3 = np.percentile(df[col],75) # Interquartile range (IQR) IQR = Q3 - Q1 # outlier step outlier_step = 1.5 * IQR # Determine a list of indices of outliers for feature col outlier_list_col = df[(df[col] < Q1 - outlier_step) | (df[col] > Q3 + outlier_step )].index # append the found outlier indices for col to the list of outlier indices outlier_indices.extend(outlier_list_col) # select observations containing more than 2 outliers outlier_indices = Counter(outlier_indices) multiple_outliers = list( k for k, v in outlier_indices.items() if v > n ) return multiple_outliers
# detect outliers from "Col1","Col2","Col3","Col4"
df = pd.read_csv("data.csv")
Outliers_to_drop = detect_outliers(df,2,["Col1","Col2","Col3","Col4"])
# Drop outliers
df = df.drop(Outliers_to_drop, axis = 0).reset_index(drop=True)

相关文章推荐
- 一种利用异常机制基于MVC过滤器的防止重复提交的机制分享
- 一种基于自定义代码记录用户访问日志在Sharepoint网站的应用方法!
- 【分享】基于Gabor特征提取和人工智能神经网络的人脸检测matlab代码
- 基于大数据分析的异常检测方法及其思路实例
- 一种基于自定义代码的asp.net网站首页根据IP自动跳转指定页面的方法!
- 一种基于自定义代码记录用户访问日志在Sharepoint网站的应用方法!
- 一种基于实时日志的网站威胁检测的方法及系统
- 一种基于java的web动态安全漏洞检测方法
- 一种基于DirectX 9.0 API的G代码逆向渲染方法
- [经验] 一种基于FreeRTOS的CPU使用率测算方法及原理介绍
- 吉首大学_编译原理实验题_基于预測方法的语法分析程序的设计【通过代码】
- 基于生长的棋盘格角点检测方法--(2)代码详解(上)
- 一种基于网格点来检测网格线的方法(可用于Camera Calibration)
- 一种基于Java的异常处理装置及其异常处理方法
- 一种基于libgds的简单内存泄露的检测方法
- 吉首大学_编译原理实验题_基于预测方法的语法分析程序的设计【通过代码】
- 基于生长的棋盘格角点检测方法--(3)代码详解(下)
- 一种基于自定义代码的asp.net网站访问IP过滤方法!
- 一种基于Redis的10行代码实现IP频率控制方法
- 基于模糊集理论的一种图像二值化算法的原理、实现效果及代码