基于CBO的SQL优化和Oracle实例优化
2017-12-08 22:21
375 查看
[版权申明:本文系作者原创,转载请注明出处]
文章出处:http://blog.csdn.net/sdksdk0/article/details/78745507
作者:朱培 ID:sdksdk0
SQL优化是数据优化的重要方面,本文将分析Oracle自身的CBO优化,即基于成本的优化方法。Oracle为了自动的优化sql语句需要各种统计数据作为优化基础。外面会通过sql的追踪来分析sql的执行过程,消耗的资源信息。对于数据库的性能问题往往是在系统部署一段时间之后出现的,即大量用户开始使用该系统,系统的数据处理量和各种计算复杂性增加的时候,这个时候往往会追溯到系统的初始设计阶段,所以我们还是要在编码阶段就编写高效的sql语句。我在网上看到了很多关于sql优化的文章,但是不尽人意,有的很笼统的描述有的根本还是错误的方法,所以我重新将我的学习过程分享出来。
查询处理与查询优化是两个相关联的概念,查询处理时执行SQL语句获取数据的过程,而查询优化是通过分析SQL语句以及其他资源获得最佳执行计划的过程。在这里最佳的执行计划。我指的是消耗资源最少的计划,例如包含有数据库服务器的CPU和系统I/O。一条SQL 的执行分为3个阶段:语法分析阶段、语句优化阶段、查询执行阶段。
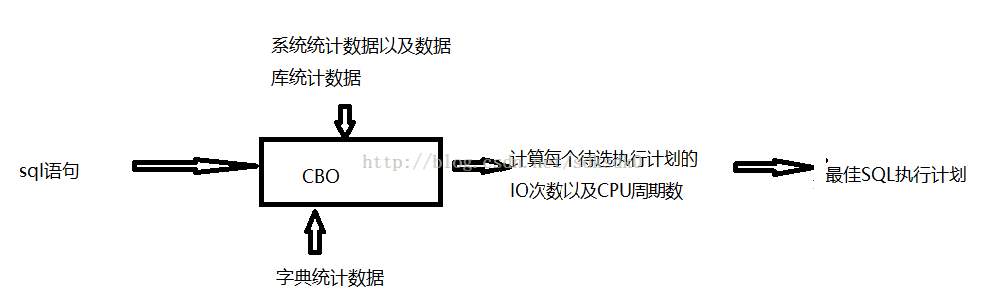
1.2 语句优化阶段这是这3个步骤中最关键的一个地方了,oracle默认使用的是基于CBO来选择最好的执行计划,你可能会问,啥是CBO?,好吧!CBO其实就是基于成本的优化程序,也就是会将对成本消耗评估,将消耗的cpu执行周期、内存、I/O速率等资源转换为时间成本。时间最少的当然就是最好的了。例如Oracle的解析也分为硬解析和软解析, 对于不同的oracle版本,硬解析的次数也不同,在oracle12中,硬解析的次数为19次,在oracle11g中硬解析的次数为59次。在做这个阶段,Oracle会将语法分析树转换为一个逻辑查询,然后将逻辑查询转换为物理查询计划。而且这个物理查询计划还不止一种,因为优化器往往会生成好几个有效的查询计划,然后会根据这些计划来做出成本消耗评估。注意,这里只是做义工评估,并没有把每一种计划都去执行一遍。那么oracle是依据什么来评估的呢?一般会按照如下因素进行评估:a、查询中涉及的连接操作以及连接顺序 b、操作执行的算法 c、数据读取的方式,例如读内存还是磁盘 d、查询各操作之间的数据传递方式。一条sql语句进来,到最终对sql语句生成执行计划之前,需要经历一个过程,如下图所示(嗨呀,随手画的图, 画得比较丑呀!)
下面提供三种优化方式来满足不同的查询需求:
1、All_Rows:默认方式,优化的目标是实现查询的最大吞吐量
2、FIRST_ROWS_n:优化输出查询的前n行数据,目标是满足快速的响应需求
3、FIRST_ROWS:使用CBO的成本优化尽快输出查询的前几行数据,满足最小响应时间的需求
oracle提供了三种级别上的优化:实例级、会话级、语句级。
查询当前数据库的CBO优化方式:
SQL> show parameter optimizer_mode;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_mode string ALL_ROWS
可以看出我当前的数据库的优化方式是实现查询的最大吞吐量。
--查询用户scott拥有表的统计分析情况:sample_size表示采样行数
select last_analyzed,table_name,owner,num_rows,sample_size from dba_tables where owner='SCOTT';
--为模式scott的所有表统计数据(手工收集)
execute dbms_stats.gather_schema_stats(ownname => 'scott');
2,优化数据库结构,将字段很多的表分解为多个表,增加中间表,增加冗余字段,优化插入速度,禁用唯一性检查,使用批量插入,禁止外键检查,禁止自动提交,优化表optimize
3,优化数据库的服务器,硬件:内存,io, 优化参数。
4、使用绑定变量:我们都知道,在Oracle中是分为了硬解析和软解析的,在SGA中,共享池就是存放解析后的SQL语句,此时的共享池包含SQL语句的最终执行计划。如果有相同的是SQL查询语句,就不需要再次解析SQL语句了,而是直接从共享池中执行SQL语句的执行计划。使用共享池就是为了避免硬解析的发生,因为每次去进行硬解析的时候都需要重新去分析语句的语法语义,然后通过CBO优化生成的最终执行计划,这样就很消耗CPU的资源。使用绑定变量,也就是我们在java开发中常见的给一个sql语句加一个?来执行,然后再传入参数。例如: select ename,job,sal from scott.emp where deptno=? 然后我们再把参数传入,这样不仅可以防止SQL注入,而且可以对SQL进行优化。
5、消除子查询:对于一些嵌套的子查询,将嵌套的sql语句,例如:
select * from scott.emp e1 where e1.sal>(select avg(sal) from scott.emp e2 where e2.deptno=e1.deptno);
这样的一条sql语句每次需要执行N*M次操作,具体数值你可以使用下文中是sql跟踪进行性能分析。
优化后的语句为:
select *from scott.emp e1,(select e2.deptno ,avg(e2.sal) avg_sal from scott.emp e2 group by deptno) dwhere e1.deptno=d.deptno and e1.sal >d.avg_sal
优化后的这条sql只需要进行N+M此操作即可,其伸缩性更强,计算结果也不会呈指数增长。虽然初步看起来优化后的sql语句似乎更长一点,如果你在质疑到底对不对,你可以使用我们接下来讲到的SQL语句分析工具来进行对比,大家可以通过其执行计划来验证。
使用explain plan for 指令来获得SQL语句的执行计划,所以我们先来创建一个执行这个指令所需要的表,在oracle的安装目录中,我们需要找到utlxplan.sql这个文件,然后执行。我这里的这个文件的路径位于E:\oracle\app\product\11.2.0\dbhome_1\RDBMS\ADMIN\utlxplan.sql,执行命令如下:
表已创建
查看这个表结构:
SQL> desc plan_table;SQL> desc plan_tableName Type Nullable Default Comments----------------- -------------- -------- ------- --------STATEMENT_ID VARCHAR2(30) YPLAN_ID NUMBER YTIMESTAMP DATE YREMARKS VARCHAR2(4000) YOPERATION VARCHAR2(30) YOPTIONS VARCHAR2(255) YOBJECT_NODE VARCHAR2(128) YOBJECT_OWNER VARCHAR2(30) YOBJECT_NAME VARCHAR2(30) YOBJECT_ALIAS VARCHAR2(65) YOBJECT_INSTANCE INTEGER YOBJECT_TYPE VARCHAR2(30) YOPTIMIZER VARCHAR2(255) YSEARCH_COLUMNS NUMBER YID INTEGER YPARENT_ID INTEGER YDEPTH INTEGER YPOSITION INTEGER YCOST INTEGER YCARDINALITY INTEGER YBYTES INTEGER YOTHER_TAG VARCHAR2(255) YPARTITION_START VARCHAR2(255) YPARTITION_STOP VARCHAR2(255) YPARTITION_ID INTEGER YOTHER LONG YDISTRIBUTION VARCHAR2(30) YCPU_COST INTEGER YIO_COST INTEGER YTEMP_SPACE INTEGER YACCESS_PREDICATES VARCHAR2(4000) YFILTER_PREDICATES VARCHAR2(4000) YPROJECTION VARCHAR2(4000) YTIME INTEGER YQBLOCK_NAME VARCHAR2(30) YOTHER_XML CLOB Y 然后我们通过这个命令来分析SQL语句的执行:
SQL> explain plan for
2 select count(*) from scott.emp;
Explained
我们来查看一下plan_table表中的sql语句执行计划信息:
SQL> col id for 999
SQL> col operation for a20
SQL> col options for a20
SQL> col object_name for a20
SQL> select id,operation,options,object_name,options from plan_table;
ID OPERATION OPTIONS OBJECT_NAME OPTIONS
--- -------------------- -------------------- -------------------- --------------------
0 SELECT STATEMENT
1 SORT AGGREGATE AGGREGATE
2 INDEX FULL SCAN PK_EMP FULL SCAN
我们可以看到,这是一个全表扫描的,表明是emp。
如果我们想要更深入的对这条sql进行分析怎么办,例如想要知道这个的访问对象、消耗的CPU等信息。那么我们可以启用SQL追踪。
1、使用autotrace指令
使用该指令可以跟踪SQL语句并分析其执行步骤,统计信息如物理读数据量、磁盘和内存排序数据量。
具体的操作命令如下:
SQL> show user; SQL> select sid,serial# from v$session where username='SYS' 2 ; SID SERIAL#---------- ---------- 7 1056 67 875 68 660
--开启追踪 SQL> exec dbms_system.set_sql_trace_in_session(68,660,true); PL/SQL procedure successfully completed --执行语句SQL> select * from scott.emp where sal>2000; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO----- ---------- --------- ----- ----------- --------- --------- ------ 7566 JONES MANAGER 7839 1981/4/2 2975.00 20 7698 BLAKE MANAGER 7839 1981/5/1 2850.00 30 7782 CLARK MANAGER 7839 1981/6/9 2450.00 10 7788 SCOTT ANALYST 7566 1987/4/19 3000.00 20 7839 KING PRESIDENT 1981/11/17 5000.00 10 7902 FORD ANALYST 7566 1981/12/3 3000.00 20 6 rows selected --关闭追踪SQL> exec dbms_system.set_sql_trace_in_session(68,660,false); PL/SQL procedure successfully completed --查询trace文件存放在那个目录
SQL> show parameter dump_dest; NAME TYPE VALUE------------------------------------ ----------- ------------------------------background_dump_dest string e:\app\thinkive\diag\rdbms\orcl\orcl\tracecore_dump_dest string e:\app\thinkive\diag\rdbms\orcl\orcl\cdumpuser_dump_dest string e:\app\thinkive\diag\rdbms\orcl\orcl\trace SQL>分析语句:使用tkprof命令
PS E:\app\thinkive\product\11.2.0\dbhome_1\BIN> tkprof E:\app\thinkive\diag\rdbms\orcl\orcl\trace\orcl_ora_14816.trcD:\arc148.txtTKPROF: Release 11.2.0.1.0 - Development on Tue Dec 5 16:14:58 2017Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.PS E:\app\thinkive\product\11.2.0\dbhome_1\BIN>
SQL> @E:\oracle\app\product\11.2.0\dbhome_1\RDBMS\ADMIN\utlxplan.sql
来看一下这个生成好的文件(部分内容,因为生成的内容比较多,所以这里不完全贴上来,需要查看的朋友可以自己去执行一个sql追踪然后查看):
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows------- ------ -------- ---------- ---------- ---------- ---------- ----------Parse 38 0.00 0.01 0 0 0 0Execute 48 0.07 0.17 0 0 0 2Fetch 70 0.01 0.09 9 171 0 48------- ------ -------- ---------- ---------- ---------- ---------- ----------total 156 0.09 0.28 9 171 0 50
Misses in library cache during parse: 22Misses in library cache during execute: 21
Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ db file sequential read 5 0.04 0.05
47 user SQL statements in session. 42 internal SQL statements in session. 89 SQL statements in session.********************************************************************************
在这段输出中,可以看出,SQL语句被执行了38次,总共耗时0.01秒,语句被执行了48次,话费时间是0.17秒,在解析和执行期间没有磁盘I/O和缓冲区读取操作,fetch操作执行了70次,耗时0.09秒,涉及了9次磁盘读取以及171次缓冲区读取操作,总共读取了0个数据库块,涉及50行数据。
在库缓存中丢失的命中次数是22次,说明有22次硬解析出现。最后说明是47个用户SQL语句,42个内部SQL语句总共涉及89个SQL语句。
Trace file: E:\app\thinkive\diag\rdbms\orcl\orcl\trace\orcl_ora_14816.trcTrace file compatibility: 11.1.0.7Sort options: default
1 session in tracefile. 47 user SQL statements in trace file. 42 internal SQL statements in trace file. 89 SQL statements in trace file. 33 unique SQL statements in trace file. 1345 lines in trace file. 749 elapsed seconds in trace file.
四、被动优化SQL在程序打包后,或者系统运行后如何来优化SQL语句,一般就是建立或删除索引、建立分区表等操作,下面指给出一些思路,具体的实现还是需要在实际工作中才能领会。
1、使用分区表
2、创建压缩表:原理就是,将表中重复的数据去掉,采用算法来替换这些重复的值,在需要的时候,用算法去重建这些重复的数据,从而实现对表的压缩。
语句为;
create table compress_empcompresstablespace usersasselect * from scott.emp;
3、创建压缩索引:原理同压缩表,主要就是去掉索引中的重复值,尤其对于大表,可以减少存储空间并增强查询性能。语句为:
create index compress_emp_ename_idxon compress_emp(ename)compress;
4、保持CBO的稳定性,创建存储大纲,分为三种; 数据库级别的存储大纲、会话级别的存储大纲、SQL语句级别的存储大纲
5、使用V$SQL视图
例如可以查询消耗磁盘I/O最多的语句,缓冲区读取次数最多的SQL语句等。
--查询自实例启动以来磁盘IO最多的sql语句
SQL> select sql_text,executions,disk_reads from v$sql where disk_reads>&number order by disk_reads desc;SQL_TEXT EXECUTIONS DISK_READS-------------------------------------------------------------------------------- ---------- ----------call dbms_stats.gather_database_stats_job_proc ( ) 1 8883call dbms_space.auto_space_advisor_job_proc ( ) 1 4214delete from sys.wri$_optstat_histgrm_history whe 1 3688select substrb(dump(val,16,0,32),1,120) ep, cnt from (select /*+ no_parallel(t) 1 2898select o.name, o.owner# from obj$ o, type$ t where o.oid$ = t.tvoid and bitand 1 2810SELECT space_usage_kbytes FROM v$sysaux_occupants WHERE occupant_name = 'SQL_ 1 2328DECLARE job BINARY_INTEGER := :job; next_date DATE := :mydate; broken BOOLEAN : 211 1862begin dbms_feature_usage_internal.exec_db_usage_sampling(:bind1); end; 1 1739DECLARE job BINARY_INTEGER := :job; next_date TIMESTAMP WITH TIME ZONE := :myda 2 1603select owner, segment_name, blocks from dba_segments where tablespace_name = :ts 1 1589select /*+ index(idl_ub1$ i_idl_ub11) +*/ piece#,length,piece from idl_ub1$ wher 458 1502 create table "SH".DBMS_TABCOMP_TEMP_UNCMP tablespace "EXAMPLE" nologging as sel 1 1472select count(*) cnt from "SH".DBMS_TABCOMP_TEMP_UNCMP 1 1438delete from WRH$_SYSMETRIC_HISTORY tab where (:beg_snap <= tab.snap_id and 1 1412delete from sys.wri$_optstat_histhead_history whe 1 1349select substrb(dump(val,16,0,32),1,120) ep, cnt from (select /*+ no_parallel(t) 1 1270BEGIN prvt_advisor.delete_expired_tasks; END; 2 1179/* SQL Analyze(1) */ select /*+ full(t) no_parallel(t) no_parallel_index(t) dbms 1 989select count(*) cnt from "SH".DBMS_TABCOMP_TEMP_CMP 1 755BEGIN DBMS_FEATURE_XDB(:feature_boolean, :aux_cnt, :feature_info); END; 1 738SQL_TEXT EXECUTIONS DISK_READS-------------------------------------------------------------------------------- ---------- ---------- select s.synonym_name as object_name, o.object_type from sys.all_synonyms s, 1 730select count(*) from xdb.xdb$resource e, sys.user$ u where to_number(utl 1 727SELECT count(*), sum(blocks) FROM dba_segments where OWNER = 'SYS' and TABLES 1 724/* SQL Analyze(1) */ select /*+ full(t) no_parallel(t) no_parallel_index(t) dbms 1 722select OBJOID, CLSOID, RUNTIME, PRI, JOBTYPE, SCHLIM, WT, INST, RUNNOW, ENQ_ 3 697SELECT /* DS_SVC */ /*+ cursor_sharing_exact dynamic_sampling(0) no_sql_tune no_ 11 686select count(1), count(1), null from sys.view$ v where bitand(v.property, 32) = 1 683delete from WRH$_SQL_PLAN tab where (:beg_snap <= tab.snap_id and tab.sn 1 659select /*+ rule */ bucket, endpoint, col#, epvalue from histgrm$ where obj#=:1 a 2743 608begin dbms_stats.gather_schema_stats(ownname => 'scott'); end; 1 415SELECT /* OPT_DYN_SAMP */ /*+ ALL_ROWS IGNORE_WHERE_CLAUSE NO_PARALLEL(SAMPLESUB 2 40131 rows selected
SQL>
五、索引类型及使用时机
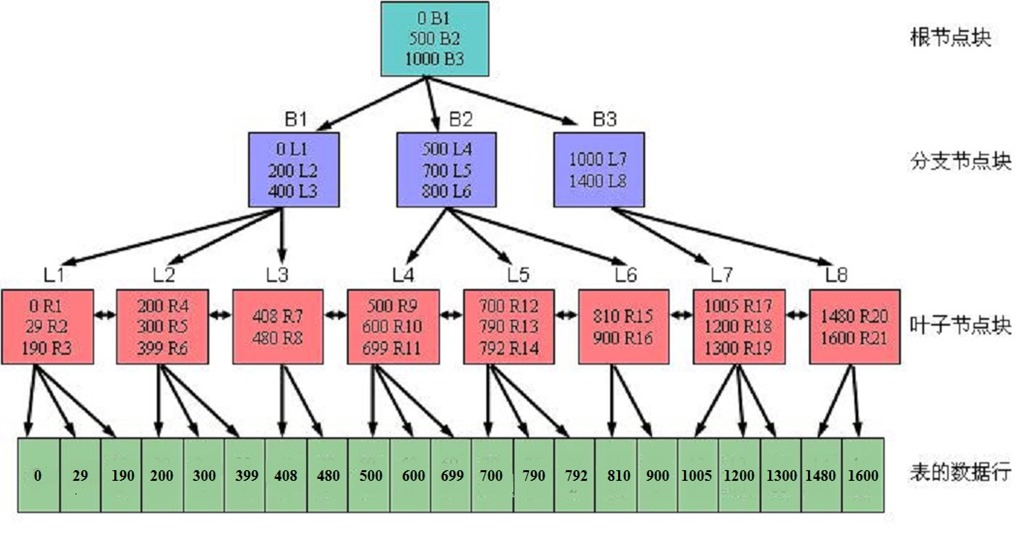
说到数据库的优化,不得不提的就是索引了,下面详细来讲解一下oracle的索引类型及其使用时机。1、B-树索引B-树索引是Oracle默认的索引类型。叶子节点包含索引的实际值和该索引条目的行ID。分为根节点、分支节点、叶子节点3个部分,其中根节点位于索引的最顶端。在叶子节点中存储了实际的索引列的值和该列对应的记录的行ID,它是唯一的Oracle指针,指向该行的物理位置,叶子节点其实就是一个双向链表,每个叶子节点包含一个指向下一个和上一个叶子节点的指针,这样在一定范围内便利用索引以搜索需要的记录。
2、位图索引位图索引使用位图标识索引的列值,它适用于没有大量数据更新、删除和插入操作的数据仓库。因为使用位图索引时,每个位图索引项与表中大量的行有关联,当表中有大量的增删改操作的时候,位图索引页需要相应的改变,而且索引会占用一定的磁盘空间,并且索引在更新的时候受影响的索引行需要锁定。例如我们执行如下语句:[align=left]SELECT EMPNO,ENAME,job,SAL FROM scott.emp WHERE JOB='SALESMAN';[/align]
目的就是在emp中查出职位为salesman的员工信息,这里我们为其建立位图索引,结构如下图所示(纯手工绘图):

创建位图索引的语句为:create bitmap index emp_job_bitmap_idx on emp(job);
3、反向键索引是值在创建索引过程中对索引列创建的索引键值的字节反向,使用反向键索引的好处是将值连续插入到索引中时反向键能避免争用。使用反向键索引使得每个键值被颠倒了顺序,将索引的键值分散开。
例如: 46892 ----> 29864Horoscope ---> eposcoroH
创建反向键索引需要使用reverse关键字。
create index emp_sal_reverse_idx on emp(sal) reverse;
4、基于函数的索引
用户查询时,如果查询语句的where子句中有函数存在,oracle将使用函数索引加快查询速度。create index dept_dname_idx on dept9UPPER(dname));
如上所示,我们创建了一个基于表dept中列dname的函数索引,创建该索引时首先将列dname中的值转换为大写,然后对大写的dname创建索引,放入索引表。资源当用户需要进行如下查询的时候就会极大的提高查询速度。[align=left]select UPPER(dname) from scott.dept where UPPER(dname) ='SALES';[/align]
六、SGA详解
Oracle的SGA是指系统全局区,它包括数据库缓冲区、重做日志缓冲区、共享池、java池、大池、流池。要优化SGA就是要调整这些数据库组件的参数 ,这些组件就是实例优化的操作对象,从而提高系统的运行效率,如提高用户查询的响应事件等。
数据库缓冲区:存放用户从库中读取的数据,用户查找数据会先在这里进行查找,如果没有才会去读数据库文件,所以该区域的设置不能过小。重做日志缓冲区:这里放置用户改变的数据,所有变化了的数据和需要回滚的数据都暂时保存在这里。共享池:包括数据字典高速缓存和库高速缓存,库高速缓存存放oracle解析的SQL语句、PL/SQL过程、包以及各种控制结构,如表、库缓冲句柄等。java池:执行java代码的区域,是为运行JVM分配的一段固定大小的内存。大池:该内存区提供大型的内存分配,在共享服务器连接模式下提供会话区,在使用RMAN备份是也使用该内存区作为磁盘IO的数据缓冲区。流池:流内存,为oracle流专用的内存池,流是指oracle数据库中的一个数据共享。
查看SGA的信息:[align=left]SQL> show parameter sga;[/align][align=left]NAME TYPE VALUE[/align][align=left]------------------------------------ ----------- ------------------------------[/align][align=left]lock_sga boolean FALSE[/align][align=left]pre_page_sga boolean FALSE[/align][align=left]sga_max_size big integer 3232M[/align][align=left]sga_target big integer 0[/align][align=left]
[/align]其中lock_sga表示:将SGA锁定在物理内存中, 这样就不会发生SGA使用虚拟内存的情况,这样可以提高数据的读取速度,该值默认是flase,我们需要将其修改为true.SQL> alter system set lock_sga=true scope=spfile;
这个参数是一个静态参数,需要重启数据库才能生效。
pre_page_sga 表示: 在启动数据库实例时,将整个SGA读入物理内存,对于内存充足的系统而言,这样显然可以提高那系统运行效率,默认为false,我们需要将其修改为true.SQL> alter system set pre_page_sga =true scope=spfile;sga_target: 在oracle10g及其以上的版本中,提供内存的自动管理功能,这样oracle可以根据业务需要和服务器自身的软硬件环境自动调整一些内存参数。当这个参数不为0的时候,就启动了SGA的自动管理了,我们也可以修改这个参数。例如alter system set sga_target=1000M;
对于数据库的优化是一个很深入的内容了,例如还有可以优化重做日志缓冲区、优化共享池优化PGA内存等方面的内容,日志缓冲区中将缓冲写入到日志文件中的方式有每隔3秒提交、数据大于1MB的时候、检验点发生时、当DBWR进程将数据库高速缓冲区中的数据写到数据文件前,日志缓冲区的优化就是调整log_buffer_pace或者将不同的文件放在不同的磁盘上以避免冲突。PGA是一个程序全局区,可以作为大规模的数据排序,而不需要去使用虚拟内存而占用操作系统的交换区。更为详细的内容在本文就不再说明,感兴趣的朋友可以自行查阅相关资料。学习一些SQL的底层,可以更好的修炼内功。
文章出处:http://blog.csdn.net/sdksdk0/article/details/78745507
作者:朱培 ID:sdksdk0
SQL优化是数据优化的重要方面,本文将分析Oracle自身的CBO优化,即基于成本的优化方法。Oracle为了自动的优化sql语句需要各种统计数据作为优化基础。外面会通过sql的追踪来分析sql的执行过程,消耗的资源信息。对于数据库的性能问题往往是在系统部署一段时间之后出现的,即大量用户开始使用该系统,系统的数据处理量和各种计算复杂性增加的时候,这个时候往往会追溯到系统的初始设计阶段,所以我们还是要在编码阶段就编写高效的sql语句。我在网上看到了很多关于sql优化的文章,但是不尽人意,有的很笼统的描述有的根本还是错误的方法,所以我重新将我的学习过程分享出来。
一、SQL查询处理过程详解
查询处理与查询优化是两个相关联的概念,查询处理时执行SQL语句获取数据的过程,而查询优化是通过分析SQL语句以及其他资源获得最佳执行计划的过程。在这里最佳的执行计划。我指的是消耗资源最少的计划,例如包含有数据库服务器的CPU和系统I/O。一条SQL 的执行分为3个阶段:语法分析阶段、语句优化阶段、查询执行阶段。1.1 语法分析阶段
语法分析是在SGA中完成的,(SGA是指系统全局区,包括数据库缓冲区、重做日志缓冲区、共享池、java池、大池、流池),在这里将sql语句分解为关系代数查询,也就是通过这些关系代数查询来验证这个sql的语法有没有写错,关键字是否正确等。1.2 语句优化阶段这是这3个步骤中最关键的一个地方了,oracle默认使用的是基于CBO来选择最好的执行计划,你可能会问,啥是CBO?,好吧!CBO其实就是基于成本的优化程序,也就是会将对成本消耗评估,将消耗的cpu执行周期、内存、I/O速率等资源转换为时间成本。时间最少的当然就是最好的了。例如Oracle的解析也分为硬解析和软解析, 对于不同的oracle版本,硬解析的次数也不同,在oracle12中,硬解析的次数为19次,在oracle11g中硬解析的次数为59次。在做这个阶段,Oracle会将语法分析树转换为一个逻辑查询,然后将逻辑查询转换为物理查询计划。而且这个物理查询计划还不止一种,因为优化器往往会生成好几个有效的查询计划,然后会根据这些计划来做出成本消耗评估。注意,这里只是做义工评估,并没有把每一种计划都去执行一遍。那么oracle是依据什么来评估的呢?一般会按照如下因素进行评估:a、查询中涉及的连接操作以及连接顺序 b、操作执行的算法 c、数据读取的方式,例如读内存还是磁盘 d、查询各操作之间的数据传递方式。一条sql语句进来,到最终对sql语句生成执行计划之前,需要经历一个过程,如下图所示(嗨呀,随手画的图, 画得比较丑呀!)
1.3 查询执行
查询执行时最简单的一个步骤了,只需要将刚才步骤2的物理查询计划进行执行即可,然后将处理的数据返回给用户。二、基于成本的优化
2.1 优化方式
优化方式的含义是为满足SQL优化的目标而选择的优化方式,在默认情况下,是以SQL语句的吞吐量作为优化的目标。下面提供三种优化方式来满足不同的查询需求:
1、All_Rows:默认方式,优化的目标是实现查询的最大吞吐量
2、FIRST_ROWS_n:优化输出查询的前n行数据,目标是满足快速的响应需求
3、FIRST_ROWS:使用CBO的成本优化尽快输出查询的前几行数据,满足最小响应时间的需求
oracle提供了三种级别上的优化:实例级、会话级、语句级。
查询当前数据库的CBO优化方式:
SQL> show parameter optimizer_mode;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_mode string ALL_ROWS
可以看出我当前的数据库的优化方式是实现查询的最大吞吐量。
2.2 优化器工作过程
CBO通过4个步骤步骤完成SQL的优化1、根据统计数据转换SQL语句 : 也就是指CBO认为转换后的语句查询会更高效,所以将你的sql语句转换为另外一种形式,例如你写的OR转换为 UNION ALL,将between转换为>=和<=等。2、根据资源情况选访问路径:指访问某个路径的数据所消耗的资源。3、根据统计数据选择连接方法: 如果涉及多个表,CBO会根据统计数据以及表的键的信息来选择连接的方法,在多个连接方法中选择计算成本最低的一个作为最佳连接方法。4、确定连接次序:指涉及的数据行的数目来确定最好的连接次序。2.3 统计数据
--查看gather_stats_job的当前运行状态select job_name,state,owner from dba_scheduler_jobs;
--查询用户scott拥有表的统计分析情况:sample_size表示采样行数
select last_analyzed,table_name,owner,num_rows,sample_size from dba_tables where owner='SCOTT';
--为模式scott的所有表统计数据(手工收集)
execute dbms_stats.gather_schema_stats(ownname => 'scott');
三、主动优化SQL语句
3.1 优化查询
1、优化查询:explain,对于使用索引查询,使用like的时候只有%不在第一个位置才会有效,使用多列查询的时候,只有查询条件中使用了这些字段中的第一个字段时,索引才会被引用,or查询条件时,前后两个条件中的列都是索引时,查询中才会使用索引。2,优化数据库结构,将字段很多的表分解为多个表,增加中间表,增加冗余字段,优化插入速度,禁用唯一性检查,使用批量插入,禁止外键检查,禁止自动提交,优化表optimize
3,优化数据库的服务器,硬件:内存,io, 优化参数。
4、使用绑定变量:我们都知道,在Oracle中是分为了硬解析和软解析的,在SGA中,共享池就是存放解析后的SQL语句,此时的共享池包含SQL语句的最终执行计划。如果有相同的是SQL查询语句,就不需要再次解析SQL语句了,而是直接从共享池中执行SQL语句的执行计划。使用共享池就是为了避免硬解析的发生,因为每次去进行硬解析的时候都需要重新去分析语句的语法语义,然后通过CBO优化生成的最终执行计划,这样就很消耗CPU的资源。使用绑定变量,也就是我们在java开发中常见的给一个sql语句加一个?来执行,然后再传入参数。例如: select ename,job,sal from scott.emp where deptno=? 然后我们再把参数传入,这样不仅可以防止SQL注入,而且可以对SQL进行优化。
5、消除子查询:对于一些嵌套的子查询,将嵌套的sql语句,例如:
select * from scott.emp e1 where e1.sal>(select avg(sal) from scott.emp e2 where e2.deptno=e1.deptno);
这样的一条sql语句每次需要执行N*M次操作,具体数值你可以使用下文中是sql跟踪进行性能分析。
优化后的语句为:
select *from scott.emp e1,(select e2.deptno ,avg(e2.sal) avg_sal from scott.emp e2 group by deptno) dwhere e1.deptno=d.deptno and e1.sal >d.avg_sal
优化后的这条sql只需要进行N+M此操作即可,其伸缩性更强,计算结果也不会呈指数增长。虽然初步看起来优化后的sql语句似乎更长一点,如果你在质疑到底对不对,你可以使用我们接下来讲到的SQL语句分析工具来进行对比,大家可以通过其执行计划来验证。
3.2 SQL语句优化工具
使用explain plan for 指令来获得SQL语句的执行计划,所以我们先来创建一个执行这个指令所需要的表,在oracle的安装目录中,我们需要找到utlxplan.sql这个文件,然后执行。我这里的这个文件的路径位于E:\oracle\app\product\11.2.0\dbhome_1\RDBMS\ADMIN\utlxplan.sql,执行命令如下:表已创建
查看这个表结构:
SQL> desc plan_table;SQL> desc plan_tableName Type Nullable Default Comments----------------- -------------- -------- ------- --------STATEMENT_ID VARCHAR2(30) YPLAN_ID NUMBER YTIMESTAMP DATE YREMARKS VARCHAR2(4000) YOPERATION VARCHAR2(30) YOPTIONS VARCHAR2(255) YOBJECT_NODE VARCHAR2(128) YOBJECT_OWNER VARCHAR2(30) YOBJECT_NAME VARCHAR2(30) YOBJECT_ALIAS VARCHAR2(65) YOBJECT_INSTANCE INTEGER YOBJECT_TYPE VARCHAR2(30) YOPTIMIZER VARCHAR2(255) YSEARCH_COLUMNS NUMBER YID INTEGER YPARENT_ID INTEGER YDEPTH INTEGER YPOSITION INTEGER YCOST INTEGER YCARDINALITY INTEGER YBYTES INTEGER YOTHER_TAG VARCHAR2(255) YPARTITION_START VARCHAR2(255) YPARTITION_STOP VARCHAR2(255) YPARTITION_ID INTEGER YOTHER LONG YDISTRIBUTION VARCHAR2(30) YCPU_COST INTEGER YIO_COST INTEGER YTEMP_SPACE INTEGER YACCESS_PREDICATES VARCHAR2(4000) YFILTER_PREDICATES VARCHAR2(4000) YPROJECTION VARCHAR2(4000) YTIME INTEGER YQBLOCK_NAME VARCHAR2(30) YOTHER_XML CLOB Y 然后我们通过这个命令来分析SQL语句的执行:
SQL> explain plan for
2 select count(*) from scott.emp;
Explained
我们来查看一下plan_table表中的sql语句执行计划信息:
SQL> col id for 999
SQL> col operation for a20
SQL> col options for a20
SQL> col object_name for a20
SQL> select id,operation,options,object_name,options from plan_table;
ID OPERATION OPTIONS OBJECT_NAME OPTIONS
--- -------------------- -------------------- -------------------- --------------------
0 SELECT STATEMENT
1 SORT AGGREGATE AGGREGATE
2 INDEX FULL SCAN PK_EMP FULL SCAN
我们可以看到,这是一个全表扫描的,表明是emp。
如果我们想要更深入的对这条sql进行分析怎么办,例如想要知道这个的访问对象、消耗的CPU等信息。那么我们可以启用SQL追踪。
1、使用autotrace指令
使用该指令可以跟踪SQL语句并分析其执行步骤,统计信息如物理读数据量、磁盘和内存排序数据量。
具体的操作命令如下:
SQL> show user; SQL> select sid,serial# from v$session where username='SYS' 2 ; SID SERIAL#---------- ---------- 7 1056 67 875 68 660
--开启追踪 SQL> exec dbms_system.set_sql_trace_in_session(68,660,true); PL/SQL procedure successfully completed --执行语句SQL> select * from scott.emp where sal>2000; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO----- ---------- --------- ----- ----------- --------- --------- ------ 7566 JONES MANAGER 7839 1981/4/2 2975.00 20 7698 BLAKE MANAGER 7839 1981/5/1 2850.00 30 7782 CLARK MANAGER 7839 1981/6/9 2450.00 10 7788 SCOTT ANALYST 7566 1987/4/19 3000.00 20 7839 KING PRESIDENT 1981/11/17 5000.00 10 7902 FORD ANALYST 7566 1981/12/3 3000.00 20 6 rows selected --关闭追踪SQL> exec dbms_system.set_sql_trace_in_session(68,660,false); PL/SQL procedure successfully completed --查询trace文件存放在那个目录
SQL> show parameter dump_dest; NAME TYPE VALUE------------------------------------ ----------- ------------------------------background_dump_dest string e:\app\thinkive\diag\rdbms\orcl\orcl\tracecore_dump_dest string e:\app\thinkive\diag\rdbms\orcl\orcl\cdumpuser_dump_dest string e:\app\thinkive\diag\rdbms\orcl\orcl\trace SQL>分析语句:使用tkprof命令
PS E:\app\thinkive\product\11.2.0\dbhome_1\BIN> tkprof E:\app\thinkive\diag\rdbms\orcl\orcl\trace\orcl_ora_14816.trcD:\arc148.txtTKPROF: Release 11.2.0.1.0 - Development on Tue Dec 5 16:14:58 2017Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.PS E:\app\thinkive\product\11.2.0\dbhome_1\BIN>
SQL> @E:\oracle\app\product\11.2.0\dbhome_1\RDBMS\ADMIN\utlxplan.sql
来看一下这个生成好的文件(部分内容,因为生成的内容比较多,所以这里不完全贴上来,需要查看的朋友可以自己去执行一个sql追踪然后查看):
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows------- ------ -------- ---------- ---------- ---------- ---------- ----------Parse 38 0.00 0.01 0 0 0 0Execute 48 0.07 0.17 0 0 0 2Fetch 70 0.01 0.09 9 171 0 48------- ------ -------- ---------- ---------- ---------- ---------- ----------total 156 0.09 0.28 9 171 0 50
Misses in library cache during parse: 22Misses in library cache during execute: 21
Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ db file sequential read 5 0.04 0.05
47 user SQL statements in session. 42 internal SQL statements in session. 89 SQL statements in session.********************************************************************************
在这段输出中,可以看出,SQL语句被执行了38次,总共耗时0.01秒,语句被执行了48次,话费时间是0.17秒,在解析和执行期间没有磁盘I/O和缓冲区读取操作,fetch操作执行了70次,耗时0.09秒,涉及了9次磁盘读取以及171次缓冲区读取操作,总共读取了0个数据库块,涉及50行数据。
在库缓存中丢失的命中次数是22次,说明有22次硬解析出现。最后说明是47个用户SQL语句,42个内部SQL语句总共涉及89个SQL语句。
Trace file: E:\app\thinkive\diag\rdbms\orcl\orcl\trace\orcl_ora_14816.trcTrace file compatibility: 11.1.0.7Sort options: default
1 session in tracefile. 47 user SQL statements in trace file. 42 internal SQL statements in trace file. 89 SQL statements in trace file. 33 unique SQL statements in trace file. 1345 lines in trace file. 749 elapsed seconds in trace file.
四、被动优化SQL在程序打包后,或者系统运行后如何来优化SQL语句,一般就是建立或删除索引、建立分区表等操作,下面指给出一些思路,具体的实现还是需要在实际工作中才能领会。
1、使用分区表
2、创建压缩表:原理就是,将表中重复的数据去掉,采用算法来替换这些重复的值,在需要的时候,用算法去重建这些重复的数据,从而实现对表的压缩。
语句为;
create table compress_empcompresstablespace usersasselect * from scott.emp;
3、创建压缩索引:原理同压缩表,主要就是去掉索引中的重复值,尤其对于大表,可以减少存储空间并增强查询性能。语句为:
create index compress_emp_ename_idxon compress_emp(ename)compress;
4、保持CBO的稳定性,创建存储大纲,分为三种; 数据库级别的存储大纲、会话级别的存储大纲、SQL语句级别的存储大纲
5、使用V$SQL视图
例如可以查询消耗磁盘I/O最多的语句,缓冲区读取次数最多的SQL语句等。
--查询自实例启动以来磁盘IO最多的sql语句
SQL> select sql_text,executions,disk_reads from v$sql where disk_reads>&number order by disk_reads desc;SQL_TEXT EXECUTIONS DISK_READS-------------------------------------------------------------------------------- ---------- ----------call dbms_stats.gather_database_stats_job_proc ( ) 1 8883call dbms_space.auto_space_advisor_job_proc ( ) 1 4214delete from sys.wri$_optstat_histgrm_history whe 1 3688select substrb(dump(val,16,0,32),1,120) ep, cnt from (select /*+ no_parallel(t) 1 2898select o.name, o.owner# from obj$ o, type$ t where o.oid$ = t.tvoid and bitand 1 2810SELECT space_usage_kbytes FROM v$sysaux_occupants WHERE occupant_name = 'SQL_ 1 2328DECLARE job BINARY_INTEGER := :job; next_date DATE := :mydate; broken BOOLEAN : 211 1862begin dbms_feature_usage_internal.exec_db_usage_sampling(:bind1); end; 1 1739DECLARE job BINARY_INTEGER := :job; next_date TIMESTAMP WITH TIME ZONE := :myda 2 1603select owner, segment_name, blocks from dba_segments where tablespace_name = :ts 1 1589select /*+ index(idl_ub1$ i_idl_ub11) +*/ piece#,length,piece from idl_ub1$ wher 458 1502 create table "SH".DBMS_TABCOMP_TEMP_UNCMP tablespace "EXAMPLE" nologging as sel 1 1472select count(*) cnt from "SH".DBMS_TABCOMP_TEMP_UNCMP 1 1438delete from WRH$_SYSMETRIC_HISTORY tab where (:beg_snap <= tab.snap_id and 1 1412delete from sys.wri$_optstat_histhead_history whe 1 1349select substrb(dump(val,16,0,32),1,120) ep, cnt from (select /*+ no_parallel(t) 1 1270BEGIN prvt_advisor.delete_expired_tasks; END; 2 1179/* SQL Analyze(1) */ select /*+ full(t) no_parallel(t) no_parallel_index(t) dbms 1 989select count(*) cnt from "SH".DBMS_TABCOMP_TEMP_CMP 1 755BEGIN DBMS_FEATURE_XDB(:feature_boolean, :aux_cnt, :feature_info); END; 1 738SQL_TEXT EXECUTIONS DISK_READS-------------------------------------------------------------------------------- ---------- ---------- select s.synonym_name as object_name, o.object_type from sys.all_synonyms s, 1 730select count(*) from xdb.xdb$resource e, sys.user$ u where to_number(utl 1 727SELECT count(*), sum(blocks) FROM dba_segments where OWNER = 'SYS' and TABLES 1 724/* SQL Analyze(1) */ select /*+ full(t) no_parallel(t) no_parallel_index(t) dbms 1 722select OBJOID, CLSOID, RUNTIME, PRI, JOBTYPE, SCHLIM, WT, INST, RUNNOW, ENQ_ 3 697SELECT /* DS_SVC */ /*+ cursor_sharing_exact dynamic_sampling(0) no_sql_tune no_ 11 686select count(1), count(1), null from sys.view$ v where bitand(v.property, 32) = 1 683delete from WRH$_SQL_PLAN tab where (:beg_snap <= tab.snap_id and tab.sn 1 659select /*+ rule */ bucket, endpoint, col#, epvalue from histgrm$ where obj#=:1 a 2743 608begin dbms_stats.gather_schema_stats(ownname => 'scott'); end; 1 415SELECT /* OPT_DYN_SAMP */ /*+ ALL_ROWS IGNORE_WHERE_CLAUSE NO_PARALLEL(SAMPLESUB 2 40131 rows selected
SQL>
五、索引类型及使用时机
说到数据库的优化,不得不提的就是索引了,下面详细来讲解一下oracle的索引类型及其使用时机。1、B-树索引B-树索引是Oracle默认的索引类型。叶子节点包含索引的实际值和该索引条目的行ID。分为根节点、分支节点、叶子节点3个部分,其中根节点位于索引的最顶端。在叶子节点中存储了实际的索引列的值和该列对应的记录的行ID,它是唯一的Oracle指针,指向该行的物理位置,叶子节点其实就是一个双向链表,每个叶子节点包含一个指向下一个和上一个叶子节点的指针,这样在一定范围内便利用索引以搜索需要的记录。
2、位图索引位图索引使用位图标识索引的列值,它适用于没有大量数据更新、删除和插入操作的数据仓库。因为使用位图索引时,每个位图索引项与表中大量的行有关联,当表中有大量的增删改操作的时候,位图索引页需要相应的改变,而且索引会占用一定的磁盘空间,并且索引在更新的时候受影响的索引行需要锁定。例如我们执行如下语句:[align=left]SELECT EMPNO,ENAME,job,SAL FROM scott.emp WHERE JOB='SALESMAN';[/align]
目的就是在emp中查出职位为salesman的员工信息,这里我们为其建立位图索引,结构如下图所示(纯手工绘图):
创建位图索引的语句为:create bitmap index emp_job_bitmap_idx on emp(job);
3、反向键索引是值在创建索引过程中对索引列创建的索引键值的字节反向,使用反向键索引的好处是将值连续插入到索引中时反向键能避免争用。使用反向键索引使得每个键值被颠倒了顺序,将索引的键值分散开。
例如: 46892 ----> 29864Horoscope ---> eposcoroH
创建反向键索引需要使用reverse关键字。
create index emp_sal_reverse_idx on emp(sal) reverse;
4、基于函数的索引
用户查询时,如果查询语句的where子句中有函数存在,oracle将使用函数索引加快查询速度。create index dept_dname_idx on dept9UPPER(dname));
如上所示,我们创建了一个基于表dept中列dname的函数索引,创建该索引时首先将列dname中的值转换为大写,然后对大写的dname创建索引,放入索引表。资源当用户需要进行如下查询的时候就会极大的提高查询速度。[align=left]select UPPER(dname) from scott.dept where UPPER(dname) ='SALES';[/align]
六、SGA详解
Oracle的SGA是指系统全局区,它包括数据库缓冲区、重做日志缓冲区、共享池、java池、大池、流池。要优化SGA就是要调整这些数据库组件的参数 ,这些组件就是实例优化的操作对象,从而提高系统的运行效率,如提高用户查询的响应事件等。
数据库缓冲区:存放用户从库中读取的数据,用户查找数据会先在这里进行查找,如果没有才会去读数据库文件,所以该区域的设置不能过小。重做日志缓冲区:这里放置用户改变的数据,所有变化了的数据和需要回滚的数据都暂时保存在这里。共享池:包括数据字典高速缓存和库高速缓存,库高速缓存存放oracle解析的SQL语句、PL/SQL过程、包以及各种控制结构,如表、库缓冲句柄等。java池:执行java代码的区域,是为运行JVM分配的一段固定大小的内存。大池:该内存区提供大型的内存分配,在共享服务器连接模式下提供会话区,在使用RMAN备份是也使用该内存区作为磁盘IO的数据缓冲区。流池:流内存,为oracle流专用的内存池,流是指oracle数据库中的一个数据共享。
查看SGA的信息:[align=left]SQL> show parameter sga;[/align][align=left]NAME TYPE VALUE[/align][align=left]------------------------------------ ----------- ------------------------------[/align][align=left]lock_sga boolean FALSE[/align][align=left]pre_page_sga boolean FALSE[/align][align=left]sga_max_size big integer 3232M[/align][align=left]sga_target big integer 0[/align][align=left]
[/align]其中lock_sga表示:将SGA锁定在物理内存中, 这样就不会发生SGA使用虚拟内存的情况,这样可以提高数据的读取速度,该值默认是flase,我们需要将其修改为true.SQL> alter system set lock_sga=true scope=spfile;
这个参数是一个静态参数,需要重启数据库才能生效。
pre_page_sga 表示: 在启动数据库实例时,将整个SGA读入物理内存,对于内存充足的系统而言,这样显然可以提高那系统运行效率,默认为false,我们需要将其修改为true.SQL> alter system set pre_page_sga =true scope=spfile;sga_target: 在oracle10g及其以上的版本中,提供内存的自动管理功能,这样oracle可以根据业务需要和服务器自身的软硬件环境自动调整一些内存参数。当这个参数不为0的时候,就启动了SGA的自动管理了,我们也可以修改这个参数。例如alter system set sga_target=1000M;
对于数据库的优化是一个很深入的内容了,例如还有可以优化重做日志缓冲区、优化共享池优化PGA内存等方面的内容,日志缓冲区中将缓冲写入到日志文件中的方式有每隔3秒提交、数据大于1MB的时候、检验点发生时、当DBWR进程将数据库高速缓冲区中的数据写到数据文件前,日志缓冲区的优化就是调整log_buffer_pace或者将不同的文件放在不同的磁盘上以避免冲突。PGA是一个程序全局区,可以作为大规模的数据排序,而不需要去使用虚拟内存而占用操作系统的交换区。更为详细的内容在本文就不再说明,感兴趣的朋友可以自行查阅相关资料。学习一些SQL的底层,可以更好的修炼内功。

相关文章推荐
- 基于CBO的SQL优化和Oracle实例优化
- SQL优化-基于数据访问路径的CBO成本计算模型
- 基于索引的SQL语句优化和导入导出Oracle表
- 基于Oracle,SQL语句优化方法30例(01)
- oracle SQL 优化( CBO下使用更具选择性的索引)
- Oracle SQL性能优化实例(1)
- 基于Oracle,SQL语句优化方法30例(02)
- Oracle SQL性能优化实例(2)
- 基于Oracle,SQL语句优化方法30例(03)
- 【Oracle】--11s到4s的SQL性能优化实例
- 基于实际开发的Oracle SQL优化建议
- oracle+SQL优化实例
- Oracle SQL 查询优化.Part6
- Oracle SQL优化规则
- oracle性能优化sql注意
- Oracle SQL 查询优化.Part4
- oracle的索引类型及sql优化总结(一)
- ORACLE SQL性能优化完结篇
- Oracle SQL查询优化3.优化原则
- Oracle SQL 性能优化技巧