浅谈Redis的特点与应用场景
2017-12-06 18:29
423 查看
参考文档::Redis实战《红丸出品》
一:概述
1:数据类型
1:redis是一个Key-Value存储系统
2:支持的value类型:
字符串
list链表
set接口的集合实现
zset有序集合
3:数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
2:持久化
Redis 将数据存储于内存中,或被配置为使用虚拟内存。通过两种方式可以实现数据
1:使用截图的方式,将内存中的数据不断写入磁盘;
2:或使用类似 MySQL 的日志方式,
记录每次更新的日志。前者性能较高,但是可能会引起一定程度的数据丢失;后者相反
3:主从同步
数据都是缓存在内存中。区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave(主从)同步.

二:应用背景
1:对于 google, ebay 这样的互联网企业,每时每刻都有无数的用户在使用它们提供的互联网
服务,这些服务带来的就是大量的数据吞吐量,在同一时间,会并发的有成千上万的连接对
数据库进行操作。在这种情况下,单台服务器或者几台服务器远远不能满足这些数据处理的
需求
2:简单的升级服务器性能这样的@ scale up
的方式也不行,所以唯一可以采用的办法就是
scale out 了。
@scale out 的方法有很多种,但大致分为两类:一类仍然采用 RDBMS,然后通过
对数据库的垂直和水平切割将整个数据库部署到一个集群上,这种方法的优点在于可以采用
RDBMS 这种熟悉的技术,但缺点在于它是针对特定应用的,就是说,由于应用的不同,切
割的方法是不一样的。
3:还有一类就是 google 所采用的方法,抛弃 RDBMS,采用 key-value 形式的存储,这样可以
极大的增强系统的可扩展性(scalability),如果要处理的数据持续增大,多加机器就 可
以了。事实上, key-value 的存储就是由于 BigTable 等相关论文的发表慢慢进入人们的 视
野的
三:Key-Value Store
1:概述:
最大的特点就是它的可扩展性,这也就是它最大的优势。所谓的可扩展性,
在我看来这里包括了两方面内容。一方面,是指 Key-Value Store 可以支持极大的数据的存储,
它的分布式的架构决定了只要有更多的机器,就能够保证存储更多的数据。另一方面,是指
它可以支持数量很多的并发的查询。对于 RDBMS,一般几百个并发的查询就可以让它很吃
力了,而一个 Key-Value Store,可以很轻松的支持上千的并发查询
2:主要特点
1:Key-value store:一个 key-value 数据存储系统,只支持一些基本操作,如: SET(key, value)和 GET(key) 等;
2: 分布式:多台机器(nodes)同时存储数据和状态,彼此交换消息来保持数据一致,可
视为一个完整的存储系统。
3: 数据一致:所有机器上的数据都是同步更新的、不用担心得到不一致的结果;
4: 冗余:所有机器(nodes)保存相同的数据,整个系统的存储能力取决于单台机器(node)
的能力;
5: 容错:如果有少数 nodes 出错,比如重启、当机、断网、网络丢包等各种 fault/fail 都
不影响整个系统的运行;
:6:高可靠性:容错、冗余等保证了数据库系统的可靠性
7:存取性能
Key-Value Store 更加注重对海量数据存取的性能、分布式、扩展性支持上,并不需要传统
关系数据库的一些特征,例如: Schema、事务、完整 SQL 查询支持等等,因此在分布式环
境下的性能相对于传统的关系数据库有较大的提升
四:应用举例
目前全球最大的 Redis 用户是新浪微博,在新浪有 200 多台物理机, 400 多
c460
个端口正在运行着 Redis, 有+4G 的数据跑在 Redis 上来为微博用户提供服务。
1:访问方式
1:应用程序直接访问数据库redis
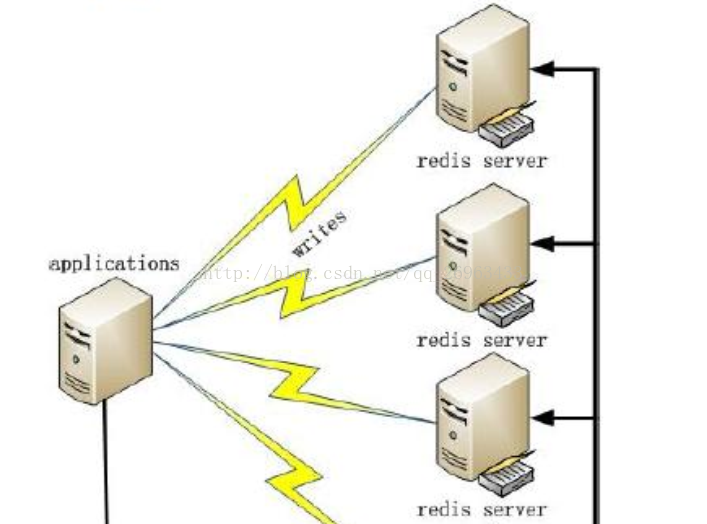
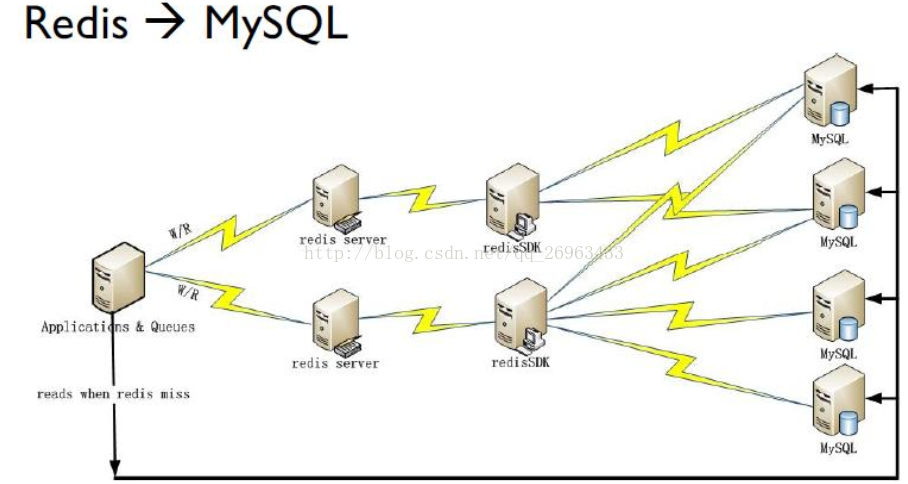
2:应用程序直接访问 Redis,只有当 Redis 访问失败时才访问 MySQL
一:概述
1:数据类型
1:redis是一个Key-Value存储系统
2:支持的value类型:
字符串
list链表
set接口的集合实现
zset有序集合
3:数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
2:持久化
Redis 将数据存储于内存中,或被配置为使用虚拟内存。通过两种方式可以实现数据
1:使用截图的方式,将内存中的数据不断写入磁盘;
2:或使用类似 MySQL 的日志方式,
记录每次更新的日志。前者性能较高,但是可能会引起一定程度的数据丢失;后者相反
3:主从同步
数据都是缓存在内存中。区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave(主从)同步.
二:应用背景
1:对于 google, ebay 这样的互联网企业,每时每刻都有无数的用户在使用它们提供的互联网
服务,这些服务带来的就是大量的数据吞吐量,在同一时间,会并发的有成千上万的连接对
数据库进行操作。在这种情况下,单台服务器或者几台服务器远远不能满足这些数据处理的
需求
2:简单的升级服务器性能这样的@ scale up
的方式也不行,所以唯一可以采用的办法就是
scale out 了。
@scale out 的方法有很多种,但大致分为两类:一类仍然采用 RDBMS,然后通过
对数据库的垂直和水平切割将整个数据库部署到一个集群上,这种方法的优点在于可以采用
RDBMS 这种熟悉的技术,但缺点在于它是针对特定应用的,就是说,由于应用的不同,切
割的方法是不一样的。
3:还有一类就是 google 所采用的方法,抛弃 RDBMS,采用 key-value 形式的存储,这样可以
极大的增强系统的可扩展性(scalability),如果要处理的数据持续增大,多加机器就 可
以了。事实上, key-value 的存储就是由于 BigTable 等相关论文的发表慢慢进入人们的 视
野的
三:Key-Value Store
1:概述:
最大的特点就是它的可扩展性,这也就是它最大的优势。所谓的可扩展性,
在我看来这里包括了两方面内容。一方面,是指 Key-Value Store 可以支持极大的数据的存储,
它的分布式的架构决定了只要有更多的机器,就能够保证存储更多的数据。另一方面,是指
它可以支持数量很多的并发的查询。对于 RDBMS,一般几百个并发的查询就可以让它很吃
力了,而一个 Key-Value Store,可以很轻松的支持上千的并发查询
2:主要特点
1:Key-value store:一个 key-value 数据存储系统,只支持一些基本操作,如: SET(key, value)和 GET(key) 等;
2: 分布式:多台机器(nodes)同时存储数据和状态,彼此交换消息来保持数据一致,可
视为一个完整的存储系统。
3: 数据一致:所有机器上的数据都是同步更新的、不用担心得到不一致的结果;
4: 冗余:所有机器(nodes)保存相同的数据,整个系统的存储能力取决于单台机器(node)
的能力;
5: 容错:如果有少数 nodes 出错,比如重启、当机、断网、网络丢包等各种 fault/fail 都
不影响整个系统的运行;
:6:高可靠性:容错、冗余等保证了数据库系统的可靠性
7:存取性能
Key-Value Store 更加注重对海量数据存取的性能、分布式、扩展性支持上,并不需要传统
关系数据库的一些特征,例如: Schema、事务、完整 SQL 查询支持等等,因此在分布式环
境下的性能相对于传统的关系数据库有较大的提升
四:应用举例
目前全球最大的 Redis 用户是新浪微博,在新浪有 200 多台物理机, 400 多
c460
个端口正在运行着 Redis, 有+4G 的数据跑在 Redis 上来为微博用户提供服务。
1:访问方式
1:应用程序直接访问数据库redis
2:应用程序直接访问 Redis,只有当 Redis 访问失败时才访问 MySQL

相关文章推荐
- Redis作者浅谈Redis应用场景
- Redis特点及应用场景
- NoSQL | Redis、Memcache、MongoDB特点、区别以及应用场景
- 【NoSQL】——了解Redis 以及应用场景
- Redis几种数据结构的应用场景
- zookeeper应用场景浅谈
- Redis作者谈Redis应用场景
- Redis各类型应用场景
- Redis的五种存储类型和其应用场景
- Redis应用场景 及其数据对象 string hash list set sortedset
- Redis应用场景
- Redis应用场景(转)
- 浅谈Java内部类的四个应用场景
- Redis应用场景
- Redis的11种Web应用场景简介
- REDIS 在电商中的实际应用场景(转)
- Redis作者谈Redis应用场景(转)
- Redis 和 Memcached 各有什么优缺点,主要的应用场景是什么样的?
- Redis发布订阅和应用场景
- Redis能干啥?细看11种Web应用场景