python3多进程,单线程,网络请求密集型操作速度对比
2017-12-02 17:08
495 查看
from multiprocessing import Pool
import requests
from requests.exceptions import ConnectionError
import time
def scrape(url):
try:
print(requests.get(url))
except ConnectionError:
print('Error Occured ', url)
finally:
print('URL ', url, ' Scraped')
if __name__ == '__main__':
start = time.time()
pool = Pool(3)
urls = [
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/'
]
pool.map(scrape, urls)
print(time.time()-start)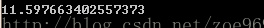
import requests
from requests.exceptions import ConnectionError
import time
def scrape(url):
try:
print(requests.get(url))
except ConnectionError:
print('Error Occured ', url)
finally:
print('URL ', url, ' Scraped')
if __name__ == '__main__':
start = time.time()
urls = [
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/'
]
for url in urls:
scrape(url)
print(time.time()-start)
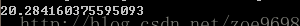

相关文章推荐
- python3 urllib.request 网络请求操作
- python3 urllib.request 网络请求操作
- python3 urllib.request 网络请求操作
- Python中单线程、多线程与多进程的效率对比实验
- 没有任何关闭socket的日志,客户端和服务端进程都在, 网络连接完好, 为什么进行某操作后好好的tcp连接莫名其妙地断了呢?
- python中几个网络请求库的区别
- python读取串口、网络编程、文本处理与文件操作
- python构造icmp echo请求和实现网络探测器功能代码分享
- python中数据类型操作对比总结
- Android常用网络请求框架xUtils、OkHttp、Volley、Retorfit对比
- C# 第一次网络请求速度慢的原因
- python编写简单的网络爬虫——爬取内涵段子(请求头header反爬,适用瀑布流试网站,淘宝、知乎等)
- 在子线程中 执行相关操作 请求网络
- [Python网络编程]浅析守护进程后台任务的设计与实现
- python构造icmp echo请求和实现网络探测器功能代码分享
- python 中的赋值操作,与c/c++的对比
- python网络请求报urllib2.HTTPError: HTTP Error 405: Not Allowed
- Volley与XUtils网络请求使用对比,心得,两者基本使用
- Python串行运算、并行运算、多线程、多进程对比实验
- Android主流网络请求开源库的对比(Android-Async-Http、Volley、OkHttp、Retrofit)