[Java]“语法糖”系列(三)之集合流操作(Stream)[笔记]
2017-11-25 17:49
806 查看
>集合流操作
这里的这个流和IO流不一样,是JDK8中对Collection对象功能的加强。
个人认为作为基础,IBM上的>这篇文章<写得已经很好了,已然再无他文可出其右。这里只做一个要点笔记。
>流操作
流操作分为两类:
Intermediate(转换操作):一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
Terminal(终点操作):一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。
所有的转换操作都是lazy的,lazy是指多次转换操作只会在遇到终点操作之后,才会依次执行。在终点操作之后,流截止,不再允许更多操作。比如:
>流操作分类
【数据集合】 ->【数据源】 - > 若干次(包括0)【转换操作】 ->【终点操作】。
>这篇文章<把常用操作都用图表示出来了,值得记录一下。
转换操作:map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel...
终点操作:forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny...
其实还有一种短路操作,下面再说。
>终点操作:Collect方法
看下面这段代码:
最终由StreamPipe送入每一个数据,通过累加器 accumulator 叠加到集合中。
<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner);接受的三个函数参数都有具体的要求,第一个参数要求返回一个产生数据容器result的实例;第二个函数参数要求是一个无状态、无打断(异常)的累加函数,用于把数据流中的每个数据装入result容器中;第三个函数参数要求传入一个与累加函数兼容的结合函数,用于叠加并行流的多个数据容器。
在经过方法引用简写后,上文的例子可简化为:
>函数接口
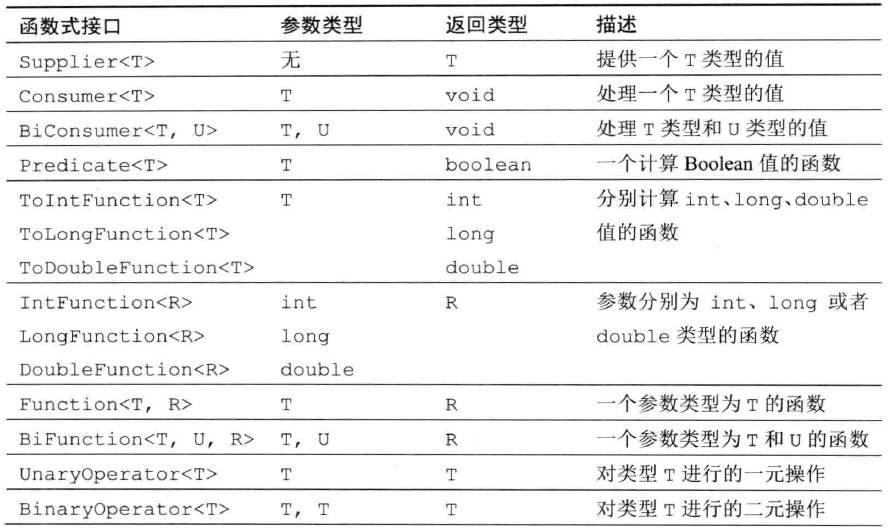
上面那个例子里提到了函数接口,我找到了一张描述常用函数接口的图:
>短路操作Short-circuiting()
其实不难发现,所有的转换操作最终返回的都是一个流,而终点操作不再返回一个流,而是直接触发了Pipe中取出数据的操作,给所有激活所有沿途lazy的转换操作。
短路操作其实和终点操作也是一样的,可能不再返回一个流,或是返回一个被截取过的流。比如anyMatch方法,通过Predicate<T>接口返回了一个真值。
由于流Stream在理论上是无限大的,短路操作被用以对流进行截取,把无限的变成有限的流,比如limit方法,可以限制获取数据源的数量。
短路操作:anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit...
下面这个例子是就是一个短路操作,用于检测数据流中是否含有"aa"字符串。相比于迭代的方式,这钟写法更偏向自然语言。
>海纳百川的流:flatMap
Stream是无限的,并且流也接受不同的数据类型。这就带来一个问题,Steam是Collection类的功能加强,但Collcetion显然不能一次性接受所有的数据类型。
Steam中提供了一个接口方法flatMap,用于把不同的数据集拍平,无论你是List还是Set,统一还原成数据源Source。
例如我现在有个学校,学校下有若干个班级,班级里有若干个学生。我要把这个学校直接拍平并转化成学生的数据流:
如果需要拍平二层以上的流,如现在有一个List<List>region.add(school),对于拍平、并获取整个地区所有学校所有班级的学生名字的流,需要做一个转型,这么写:
region.stream()
.flatMap(Collection::stream)// 用了"方法引用"的语法糖,详见:http://blog.csdn.net/shenpibaipao/article/details/78614280
.flatMap(e->((List<String>) e).stream())// 转型成Collection形式
.forEach(System.out::println);
这里的这个流和IO流不一样,是JDK8中对Collection对象功能的加强。
个人认为作为基础,IBM上的>这篇文章<写得已经很好了,已然再无他文可出其右。这里只做一个要点笔记。
>流操作
流操作分为两类:
Intermediate(转换操作):一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
Terminal(终点操作):一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。
所有的转换操作都是lazy的,lazy是指多次转换操作只会在遇到终点操作之后,才会依次执行。在终点操作之后,流截止,不再允许更多操作。比如:
List<Integer> nums = Arrays.asList(1, 2, 3); nums.stream().peek(System.out::println).map(x->x*-1).forEach(System.out::println);输出为: 1 -1 2 -2 3 -3。
>流操作分类
【数据集合】 ->【数据源】 - > 若干次(包括0)【转换操作】 ->【终点操作】。
>这篇文章<把常用操作都用图表示出来了,值得记录一下。
转换操作:map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel...
终点操作:forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny...
其实还有一种短路操作,下面再说。
>终点操作:Collect方法
看下面这段代码:
Set<String> result = Stream.of("aa", "bb", "cc", "aa").collect(
() -> new HashSet<String>(),
(set, item) -> set.add(item),
(set, subSet) -> set.addAll(subSet)); 其中collect方法源码为:<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner);Supplier是一个函数式接口:
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
} 其功能为直接返回一个传入的实例。() -> new HashSet<String>()等价于:new Supplier<Set<String>>() {
@Override
public Set<String> get() {
return new HashSet<>();
}
} BiConsumer也是一个函数式接口,接受两个传入的参数,无返回值。(set, item) -> set.add(item)等价于:new BiConsumer<Set<String>, String>() {
@Override
public void accept(Set<String> set, String item) {
set.add(item);
}
} 同理(set, subSet) -> set.addAll(subSet))等价于:new BiConsumer<Set<String>, Set<String>>() {
@Override
public void accept(Set<String> set, Set<String> subSet) {
set.addAll(subSet);
}
} collect方法在ReferencePipeLine.java -> ReduceOps.java中被实现:public static <T, R> TerminalOp<T, R>
makeRef(Supplier<R> seedFactory,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R,R> reducer) {
Objects.requireNonNull(seedFactory);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(reducer);
class ReducingSink extends Box<R>
implements AccumulatingSink<T, R, ReducingSink> {
@Override
public void begin(long size) {
state = seedFactory.get();
}
@Override
public void accept(T t) {
accumulator.accept(state, t);
}
@Override
public void combine(ReducingSink other) {
reducer.accept(state, other.state);
}
}
return new ReduceOp<T, R, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
};
}最终由StreamPipe送入每一个数据,通过累加器 accumulator 叠加到集合中。
<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner);接受的三个函数参数都有具体的要求,第一个参数要求返回一个产生数据容器result的实例;第二个函数参数要求是一个无状态、无打断(异常)的累加函数,用于把数据流中的每个数据装入result容器中;第三个函数参数要求传入一个与累加函数兼容的结合函数,用于叠加并行流的多个数据容器。
在经过方法引用简写后,上文的例子可简化为:
Set<String> result = Stream.of("aa", "bb", "cc", "aa").collect(
HashSet::new,
HashSet::add,
HashSet::addAll); 事实上对于Java提供的集合对象,已有封装好的方法:Set<String> result = Stream.of("aa", "bb", "cc", "aa").collect(Collectors.toSet());>函数接口
上面那个例子里提到了函数接口,我找到了一张描述常用函数接口的图:
>短路操作Short-circuiting()
其实不难发现,所有的转换操作最终返回的都是一个流,而终点操作不再返回一个流,而是直接触发了Pipe中取出数据的操作,给所有激活所有沿途lazy的转换操作。
短路操作其实和终点操作也是一样的,可能不再返回一个流,或是返回一个被截取过的流。比如anyMatch方法,通过Predicate<T>接口返回了一个真值。
由于流Stream在理论上是无限大的,短路操作被用以对流进行截取,把无限的变成有限的流,比如limit方法,可以限制获取数据源的数量。
短路操作:anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit...
下面这个例子是就是一个短路操作,用于检测数据流中是否含有"aa"字符串。相比于迭代的方式,这钟写法更偏向自然语言。
boolean string = Stream.of("aa", "bb", "cc", "dd").anyMatch("aa"::equals);
System.out.println(string); 再举一个关于短路操作的例子。findFirst方法用于获取数据流中的第一个数据,返回一个Optional对象。Optional对象是Java仿Scala语言设计的一种可空对象,在>这篇文章<里有详尽解释。Stream.of("aa", "bb", "cc", "dd").findFirst().ifPresent(System.out::println);// 打印 aa>海纳百川的流:flatMap
Stream是无限的,并且流也接受不同的数据类型。这就带来一个问题,Steam是Collection类的功能加强,但Collcetion显然不能一次性接受所有的数据类型。
Steam中提供了一个接口方法flatMap,用于把不同的数据集拍平,无论你是List还是Set,统一还原成数据源Source。
例如我现在有个学校,学校下有若干个班级,班级里有若干个学生。我要把这个学校直接拍平并转化成学生的数据流:
List<List> school = new LinkedList<>();
List<String> class1 = new LinkedList<>();
List<String> class2 = new LinkedList<>();
class1.add("小明");class1.add("小王");
class2.add("小李");
school.add(class1);school.add(class2);
school.stream().flatMap(e->e.stream()).forEach(System.out::println);// 打印: 小明 小王 小李如果需要拍平二层以上的流,如现在有一个List<List>region.add(school),对于拍平、并获取整个地区所有学校所有班级的学生名字的流,需要做一个转型,这么写:
region.stream()
.flatMap(Collection::stream)// 用了"方法引用"的语法糖,详见:http://blog.csdn.net/shenpibaipao/article/details/78614280
.flatMap(e->((List<String>) e).stream())// 转型成Collection形式
.forEach(System.out::println);

相关文章推荐
- 自学Java系列 笔记2 Java集合2
- Java基础知识强化之集合框架笔记77:ConcurrentHashMap之 ConcurrentHashMap的基本操作
- 学习笔记之javaweb基础:jsp基本语法,内置对象,对JavaBean的操作语法
- Java 8系列之Stream的基本语法详解
- 很久很久前初学Java时的笔记--集合操作1
- Java8集合及Stream操作
- 自学Java系列 笔记2 Java集合3
- 自学Java系列 笔记1 java的基本语法2
- Java8 系列之Stream的基本语法详解
- Java8系列--Java Stream入门篇(流的操作)
- JAVA笔记:集合系列3—fast-fail
- collections集合操作排序,Java8 stream集合操作
- Java 8系列之Stream的基本语法详解
- java8新特性Predicate和Stream操作集合
- Java 8函数式编程笔记(二)- 集合和流(stream)
- 自学Java系列 笔记1 java的基本语法3
- Java高级语法笔记-文件及目录操作
- 自学Java系列 笔记2 Java集合1
- 很久很久前初学Java时的笔记--集合操作2
- Java高级语法笔记-文件操作-链表的存储