基于Java、Kafka、ElasticSearch的搜索框架的设计与实现
2017-11-22 00:00
776 查看
Jkes是一个基于Java、Kafka、ElasticSearch的搜索框架。Jkes提供了注解驱动的JPA风格的对象/文档映射,使用rest api用于文档搜索。
安装
可以参考
安装
安装 Smart Chinese Analysis Plugin
添加配置
提供JkesProperties Bean
这里可以很灵活,如果使用Spring Boot,可以使用
增加索引管理端点 因为我们不知道客户端使用的哪种web技术,所以索引端点需要在客户端添加。比如在
当更新实体时,文档会被自动索引到ElasticSearch;删除实体时,文档会自动从ElasticSearch删除。
URI query
Nested query
match query
bool query
Source filtering
prefix
wildcard
regexp
应用启动时,Jkes扫描所有标注
基于构建的元数据,创建
为每个文档创建/更新
为整个项目启动/更新
拦截数据操作方法。将
拦截事务。在事务提交后使用
与
与
查询工作原理:
查询服务通过rest api提供
我们没有直接使用ElasticSearch进行查询,因为我们需要在后续版本使用机器学习进行搜索排序,而直接与ElasticSearch进行耦合,会增加搜索排序API的接入难度
查询服务是一个Spring Boot Application,使用docker打包为镜像
查询服务提供多版本API,用于API进化和兼容
查询服务解析
为了便于客户端人员开发,查询服务提供了一个查询UI界面,开发人员可以在这个页面得到预期结果后再把json请求体复制到程序中。
如果你在学习Java的过程中或者在工作中遇到什么问题都可以来群里提问,阿里Java高级大牛直播讲解知识点,分享知识,多年工作经验的梳理和总结,带着大家全面、科学地建立自己的技术体系和技术认知!可以加群找我要课堂链接 注意:是免费的 没有开发经验误入哦! 非喜勿入 .学习交流QQ群:478052716
当前,我们通过
在后续版本,我们会提供与更多框架的集成。
借助于Kafka Connect的rest admin api,我们轻松地实现了多租户平台上的文档删除功能。只要为每个项目启动一个
我们没有直接使用ElasticSearch进行查询,因为我们需要在后续版本使用机器学习进行搜索排序,而直接与ElasticSearch进行耦合,会增加搜索排序的接入难度
查询服务是一个Spring Boot Application,使用docker打包为镜像
查询服务解析
为了便于客户端人员开发,查询服务提供了一个查询UI界面,开发人员可以在这个页面得到预期结果后再把json请求体复制到程序中。
后续,我们将会基于
Issue Tracker: https://github.com/chaokunyang/jkes/issues
安装
可以参考
jkes-integration-test项目快速掌握jkes框架的使用方法。
jkes-integration-test是我们用来测试功能完整性的一个Spring Boot Application。
安装
jkes-index-connector和
jkes-delete-connector到Kafka Connect类路径
安装 Smart Chinese Analysis Plugin
sudo bin/elasticsearch-plugin install analysis-smartcn
配置
引入jkes-spring-data-jpa依赖添加配置
@EnableAspectJAutoProxy
@EnableJkes
@Configuration
public class JkesConfig {
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory factory, EventSupport eventSupport) {
return new SearchPlatformTransactionManager(new JpaTransactionManager(factory), eventSupport);
}
}提供JkesProperties Bean
@Component
@Configuration
public class JkesConf extends DefaultJkesPropertiesImpl {
@PostConstruct
public void setUp() {
Config.setJkesProperties(this);
}
@Override
public String getKafkaBootstrapServers() {
return "k1-test.com:9292,k2-test.com:9292,k3-test.com:9292";
}
@Override
public String getKafkaConnectServers() {
return "http://k1-test.com:8084,http://k2-test.com:8084,http://k3-test.com:8084";
}
@Override
public String getEsBootstrapServers() {
return "http://es1-test.com:9200,http://es2-test.com:9200,http://es3-test.com:9200";
}
@Override
public String getDocumentBasePackage() {
return "com.timeyang.jkes.integration_test.domain";
}
@Override
public String getClientId() {
return "integration_test";
}
}这里可以很灵活,如果使用Spring Boot,可以使用
@ConfigurationProperties提供配置
增加索引管理端点 因为我们不知道客户端使用的哪种web技术,所以索引端点需要在客户端添加。比如在
Spring MVC中,可以按照如下方式添加索引端点
@RestController
@RequestMapping("/api/search")
public class SearchEndpoint {
private Indexer indexer;
@Autowired
public SearchEndpoint(Indexer indexer) {
this.indexer = indexer;
}
@RequestMapping(value = "/start_all", method = RequestMethod.POST)
public void startAll() {
indexer.startAll();
}
@RequestMapping(value = "/start/{entityClassName:.+}", method = RequestMethod.POST)
public void start(@PathVariable("entityClassName") String entityClassName) {
indexer.start(entityClassName);
}
@RequestMapping(value = "/stop_all", method = RequestMethod.PUT)
public Map<String, Boolean> stopAll() {
return indexer.stopAll();
}
@RequestMapping(value = "/stop/{entityClassName:.+}", method = RequestMethod.PUT)
public Boolean stop(@PathVariable("entityClassName") String entityClassName) {
return indexer.stop(entityClassName);
}
@RequestMapping(value = "/progress", method = RequestMethod.GET)
public Map<String, IndexProgress> getProgress() {
return indexer.getProgress();
}
}快速开始
索引API
使用com.timeyang.jkes.core.annotation包下相关注解标记实体
@lombok.Data
@Entity
@Document
public class Person extends AuditedEntity {
// @Id will be identified automatically
// @Field(type = FieldType.Long)
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@MultiFields(
mainField = @Field(type = FieldType.Text),
otherFields = {
@InnerField(suffix = "raw", type = FieldType.Keyword),
@InnerField(suffix = "english", type = FieldType.Text, analyzer = "english")
}
)
private String name;
@Field(type = FieldType.Keyword)
private String gender;
@Field(type = FieldType.Integer)
private Integer age;
// don't add @Field to test whether ignored
// @Field(type = FieldType.Text)
private String description;
@Field(type = FieldType.Object)
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "group_id")
private PersonGroup personGroup;
}@lombok.Data
@Entity
@Document(type = "person_group", alias = "person_group_alias")
public class PersonGroup extends AuditedEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String interests;
@OneToMany(fetch = FetchType.EAGER, cascade = CascadeType.ALL, mappedBy = "personGroup", orphanRemoval = true)
private List<Person> persons;
private String description;
@DocumentId
@Field(type = FieldType.Long)
public Long getId() {
return id;
}
@MultiFields(
mainField = @Field(type = FieldType.Text),
otherFields = {
@InnerField(suffix = "raw", type = FieldType.Keyword),
@InnerField(suffix = "english", type = FieldType.Text, analyzer = "english")
}
)
public String getName() {
return name;
}
@Field(type = FieldType.Text)
public String getInterests() {
return interests;
}
@Field(type = FieldType.Nested)
public List<Person> getPersons() {
return persons;
}
/**
* 不加Field注解,测试序列化时是否忽略
*/
public String getDescription() {
return description;
}
}当更新实体时,文档会被自动索引到ElasticSearch;删除实体时,文档会自动从ElasticSearch删除。
搜索API
启动搜索服务jkes-search-service,搜索服务是一个Spring Boot Application,提供rest搜索api,默认运行在9000端口。URI query
curl -XPOST localhost:9000/api/v1/integration_test_person_group/person_group/_search?from=3&size=10
Nested query
integration_test_person_group/person_group/_search?from=0&size=10
{
"query": {
"nested": {
"path": "persons",
"score_mode": "avg",
"query": {
"bool": {
"must": [
{
"range": {
"persons.age": {
"gt": 5
}
}
}
]
}
}
}
}
}match query
integration_test_person_group/person_group/_search?from=0&size=10
{
"query": {
"match": {
"interests": "Hadoop"
}
}
}bool query
{
"query": {
"bool" : {
"must" : {
"match" : { "interests" : "Hadoop" }
},
"filter": {
"term" : { "name.raw" : "name0" }
},
"should" : [
{ "match" : { "interests" : "Flink" } },
{
"nested" : {
"path" : "persons",
"score_mode" : "avg",
"query" : {
"bool" : {
"must" : [
{ "match" : {"persons.name" : "name40"} },
{ "match" : {"persons.interests" : "interests"} }
],
"must_not" : {
"range" : {
"age" : { "gte" : 50, "lte" : 60 }
}
}
}
}
}
}
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}Source filtering
integration_test_person_group/person_group/_search
{
"_source": false,
"query" : {
"match" : { "name" : "name17" }
}
}integration_test_person_group/person_group/_search
{
"_source": {
"includes": [ "name", "persons.*" ],
"excludes": [ "date*", "version", "persons.age" ]
},
"query" : {
"match" : { "name" : "name17" }
}
}prefix
integration_test_person_group/person_group/_search
{
"query": {
"prefix" : { "name" : "name" }
}
}wildcard
integration_test_person_group/person_group/_search
{
"query": {
"wildcard" : { "name" : "name*" }
}
}regexp
integration_test_person_group/person_group/_search
{
"query": {
"regexp":{
"name": "na.*17"
}
}
}Jkes工作原理
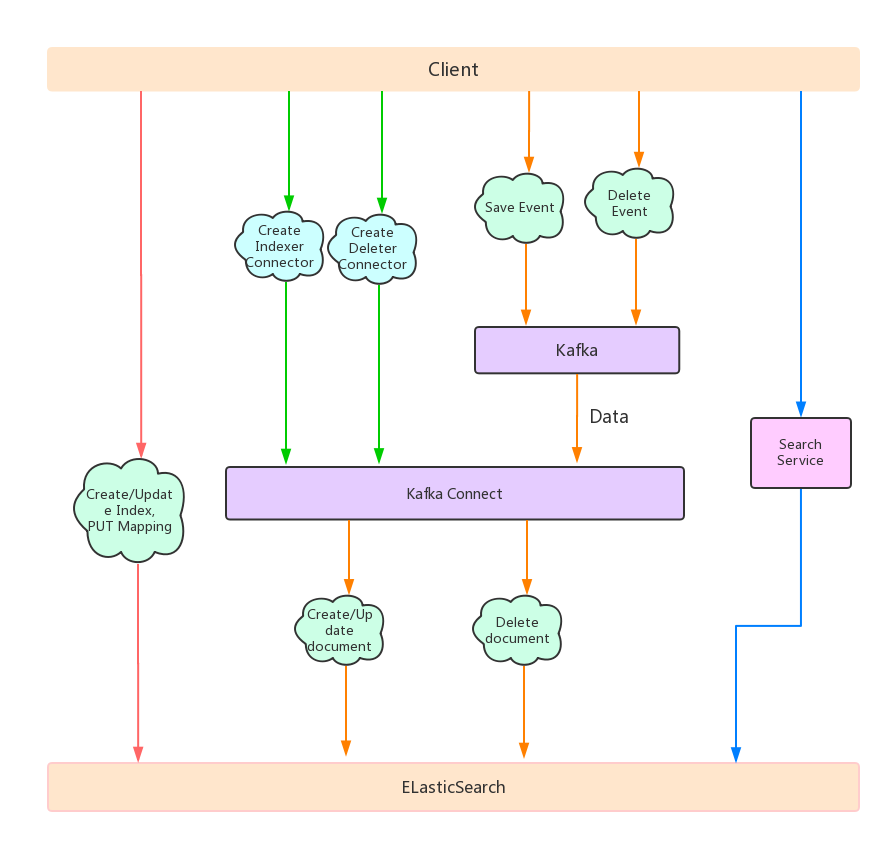
索引工作原理:应用启动时,Jkes扫描所有标注
@Document注解的实体,为它们构建元数据。
基于构建的元数据,创建
index和
mappingJson格式的配置,然后通过
ElasticSearch Java Rest Client将创建/更新
index配置。
为每个文档创建/更新
Kafka ElasticSearch Connector,用于创建/更新文档
为整个项目启动/更新
Jkes Deleter Connector,用于删除文档
拦截数据操作方法。将
* save(*)方法返回的数据包装为
SaveEvent保存到
EventContainer;使用
(* delete*(..)方法的参数,生成一个
DeleteEvent/DeleteAllEvent保存到
EventContainer。
拦截事务。在事务提交后使用
JkesKafkaProducer发送
SaveEvent中的实体到Kafka,Kafka会使用我们提供的
JkesJsonSerializer序列化指定的数据,然后发送到Kafka。
与
SaveEvent不同,
DeleteEvent会直接被序列化,然后发送到Kafka,而不是只发送一份数据
与
SaveEvent和
DeleteEvent不同,
DeleteAllEvent不会发送数据到Kafka,而是直接通过
ElasticSearch Java Rest Client删除相应的
index,然后重建该索引,重启
Kafka ElasticSearch Connector
查询工作原理:
查询服务通过rest api提供
我们没有直接使用ElasticSearch进行查询,因为我们需要在后续版本使用机器学习进行搜索排序,而直接与ElasticSearch进行耦合,会增加搜索排序API的接入难度
查询服务是一个Spring Boot Application,使用docker打包为镜像
查询服务提供多版本API,用于API进化和兼容
查询服务解析
json请求,进行一些预处理后,使用
ElasticSearch Java Rest Client转发到ElasticSearch,将得到的响应进行解析,进一步处理后返回到客户端。
为了便于客户端人员开发,查询服务提供了一个查询UI界面,开发人员可以在这个页面得到预期结果后再把json请求体复制到程序中。
如果你在学习Java的过程中或者在工作中遇到什么问题都可以来群里提问,阿里Java高级大牛直播讲解知识点,分享知识,多年工作经验的梳理和总结,带着大家全面、科学地建立自己的技术体系和技术认知!可以加群找我要课堂链接 注意:是免费的 没有开发经验误入哦! 非喜勿入 .学习交流QQ群:478052716
流程图
模块介绍
jkes-core
jkes-core是整个
jkes的核心部分。主要包括以下功能:
annotation包提供了jkes的核心注解
elasticsearch包封装了
elasticsearch相关的操作,如为所有的文档创建/更新索引,更新mapping
kafka包提供了Kafka 生产者,Kafka Json Serializer,Kafka Connect Client
metadata包提供了核心的注解元数据的构建与结构化模型
event包提供了事件模型与容器
exception包提供了常见的Jkes异常
http包基于
Apache Http Client封装了常见的http json请求
support包暴露了Jkes核心配置支持
util包提供了一些工具类,便于开发。如:Asserts, ClassUtils, DocumentUtils, IOUtils, JsonUtils, ReflectionUtils, StringUtils
jkes-boot
jkes-boot用于与一些第三方开源框架进行集成。
当前,我们通过
jkes-spring-data-jpa,提供了与
spring data jpa的集成。通过使用Spring的AOP机制,对
Repository方法进行拦截,生成
SaveEvent/DeleteEvent/DeleteAllEvent保存到
EventContainer。通过使用我们提供的
SearchPlatformTransactionManager,对常用的事务管理器(如
JpaTransactionManager)进行包装,提供事务拦截功能。
在后续版本,我们会提供与更多框架的集成。
jkes-spring-data-jpa说明:
ContextSupport类用于从bean工厂获取
Repository Bean
@EnableJkes让客户端能够轻松开启Jkes的功能,提供了与Spring一致的配置模型
EventSupport处理事件的细节,在保存和删除数据时生成相应事件存放到
EventContainer,在事务提交和回滚时处理相应的事件
SearchPlatformTransactionManager包装了客户端的事务管理器,在事务提交和回滚时加入了
回调hook
audit包提供了一个简单的
AuditedEntity父类,方便添加审计功能,版本信息可用于结合
ElasticSearch的版本机制保证不会索引过期文档数据
exception包封装了常见异常
intercept包提供了AOP切点和切面
index包提供了
全量索引功能。当前,我们提供了基于
线程池的索引机制和基于
ForkJoin的索引机制。在后续版本,我们会重构代码,增加基于
阻塞队列的
生产者-消费者模式,提供并发性能
jkes-services
jkes-services主要用来提供一些服务。 目前,
jkes-services提供了以下服务:
jkes-delete-connector
jkes-delete-connector是一个
Kafka Connector,用于从kafka集群获取索引删除事件(
DeleteEvent),然后使用
Jest Client删除ElasticSearch中相应的文档。
借助于Kafka Connect的rest admin api,我们轻松地实现了多租户平台上的文档删除功能。只要为每个项目启动一个
jkes-delete-connector,就可以自动处理该项目的文档删除工作。避免了每启动一个新的项目,我们都得手动启动一个Kafka Consumer来处理该项目的文档删除工作。尽管可以通过正则订阅来减少这样的工作,但是还是非常不灵活
jkes-search-service
jkes-search-service是一个restful的搜索服务,提供了多版本的rest query api。查询服务提供多版本API,用于API进化和兼容
jkes-search-service目前支持URI风格的搜索和JSON请求体风格的搜索。
我们没有直接使用ElasticSearch进行查询,因为我们需要在后续版本使用机器学习进行搜索排序,而直接与ElasticSearch进行耦合,会增加搜索排序的接入难度
查询服务是一个Spring Boot Application,使用docker打包为镜像
查询服务解析
json请求,进行一些预处理后,使用
ElasticSearch Java Rest Client转发到ElasticSearch,将得到的响应进行解析,进一步处理后返回到客户端。
为了便于客户端人员开发,查询服务提供了一个查询UI界面,开发人员可以在这个页面得到预期结果后再把json请求体复制到程序中。
后续,我们将会基于
zookeeper构建索引集群,提供集群索引管理功能
jkes-integration-test
jkes-integration-test是一个基于Spring Boot集成测试项目,用于进行
功能测试。同时测量一些常见操作的
吞吐率
开发
To build a development version you'll need a recent version of Kafka. You can build jkes with Maven using the standard lifecycle phases.Contribute
Source Code: https://github.com/chaokunyang/jkesIssue Tracker: https://github.com/chaokunyang/jkes/issues
LICENSE
This project is licensed under Apache License 2.0.
相关文章推荐
- 基于Java、Kafka、ElasticSearch的搜索框架的设计与实现
- 基于Java、Kafka、ElasticSearch的搜索框架的设计与实现
- 基于Java、Kafka、ElasticSearch的搜索框架的设计与实现
- 基于Java、Kafka、ElasticSearch的搜索框架的设计与实现
- 基于IOC的Java事件框架的设计与实现 Ⅲ
- 基于IOC的Java事件框架的设计与实现 Ⅱ
- 【Yom框架】漫谈个人框架的设计之二:新的IRepository接口+搜索和排序解耦(+基于Castle实现)
- 基于IOC的Java事件框架的设计与实现Ⅰ
- Java客户端连接elasticsearch5.5.3实现数据搜索(基于xpack安全管理)
- Java客户端连接elasticsearch5.5.3实现数据搜索(基于xpack安全管理)
- 基于java 的框架设计入门。
- 基于.Net(C#开发)平台的三层框架架构软件的设计与实现
- 一种Java日志系统框架的设计与实现
- 基于C/S的网盘设计(JAVA) - 网盘源码-实现部分功能
- 分布式搜索elasticsearch java API 之(八)------使用More like this实现基于内容的推荐
- 设计自己的基于Selenium 的自动化测试框架-Java版(1) - 为什么selenium还需要测试框架?
- 基于元数据配置的asp.net数据库应用快速开发框架设计及实现
- 0/7 基于ASP.NET的Web应用程序框架Nello的设计与实现
- 基于 Java 的界面布局 DSL 的设计与实现
- Java.NET --一个基于Java的Microsoft.NET框架的实现