BP神经网络的数学原理及其算法实现
2017-11-21 21:18
585 查看
什么是BP网络
BP网络的数学原理
BP网络算法实现
转载请声明出处http://blog.csdn.net/zhongkejingwang/article/details/44514073
上一篇文章介绍了KNN分类器,当时说了其分类效果不是很出色但是比较稳定,本文后面将利用BP网络同样对Iris数据进行分类。
BP神经网络,BP即Back Propagation的缩写,也就是反向传播的意思,顾名思义,将什么反向传播?文中将会解答。不仅如此,关于隐层的含义文中也会给出个人的理解。最后会用Java实现的BP分类器作为其应用以加深印象。
很多初学者刚接触神经网络的时候都会到网上找相关的介绍,看了很多数学原理之后还是云里雾里,然后会琢磨到底这个有什么用?怎么用?于是又到网上找别人写的代码,下下来之后看一眼发现代码写的很糟糕,根本就理不清,怎么看也看不懂,于是就放弃了。作为过来人,本人之前在网上也看过很多关于BP网络的介绍,也下载了别人实现的代码下来研究,原理都一样,但是至今为止没有看到过能令人满意的代码实现。于是就有了这篇文章,不仅有原理也有代码,对节点的高度抽象会让代码更有可读性。
CSDN博客编辑器终于可以编写数学公式了!第一次使用Markdown编辑器,感觉爽歪歪,latex数学公式虽然写起来麻烦,不过很灵活,排版也漂亮~在这里贴一个Markdown输入数学公式的教程http://ttang.name/2014/05/04/markdown-and-mathjax/很全的说!
下面将介绍BP网络的数学原理,相比起SVD的算法推导,这个简直就是小菜一碟,不就是梯度吗求个导就完事了。首先来看看BP网络长什么样,这就是它的样子:
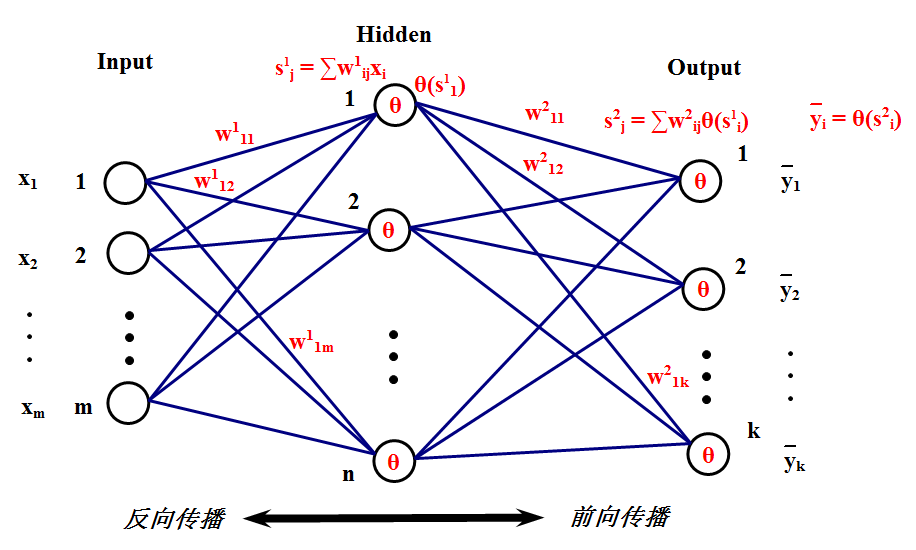
为了简单起见,这里只介绍只有一个隐层的BP网络,多个隐层的也是一样的原理。这个网络的工作原理应该很清楚了,首先,一组输入x1、x2、…、xm来到输入层,然后通过与隐层的连接权重产生一组数据s1、s2、…、sn作为隐层的输入,然后通过隐层节点的θ(⋅)激活函数后变为θ(sj)其中sj表示隐层的第j个节点产生的输出,这些输出将通过隐层与输出层的连接权重产生输出层的输入,这里输出层的处理过程和隐层是一样的,最后会在输出层产生输出y¯j,这里j是指输出层第j个节点的输出。这只是前向传播的过程,很简单吧?在这里,先解释一下隐层的含义,可以看到,隐层连接着输入和输出层,它到底是什么?它就是特征空间,隐层节点的个数就是特征空间的维数,或者说这组数据有多少个特征。而输入层到隐层的连接权重则将输入的原始数据投影到特征空间,比如sj就表示这组数据在特征空间中第j个特征方向的投影大小,或者说这组数据有多少份量的j特征。而隐层到输出层的连接权重表示这些特征是如何影响输出结果的,比如某一特征对某个输出影响比较大,那么连接它们的权重就会比较大。关于隐层的含义就解释这么多,至于多个隐层的,可以理解为特征的特征。
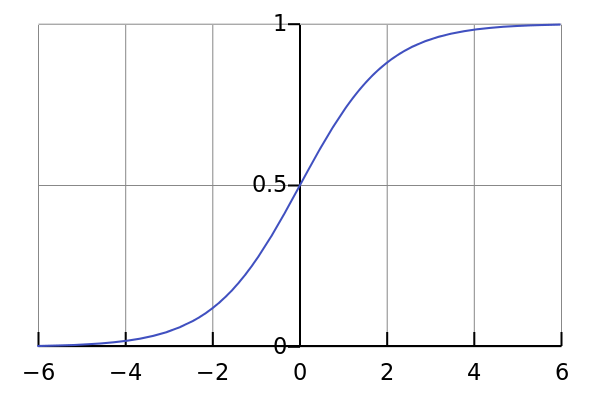
前面提到激活函数θ(⋅),一般使用S形函数(即sigmoid函数),比如可以使用log-sigmoid:θ(s)=11+e−s
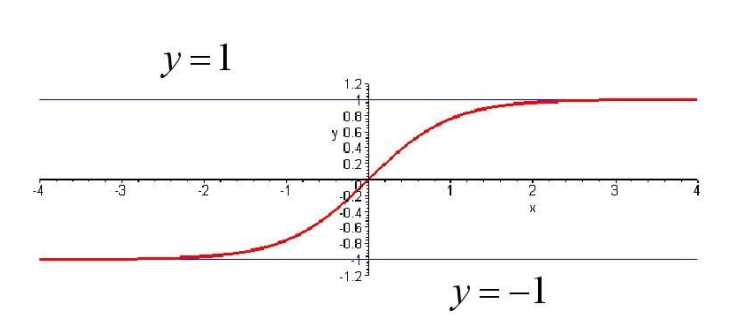
或者tan-sigmoid:θ(s)=es−e−ses+e−s
前面说了,既然在输出层产生输出了,那总得看下输出结果对不对吧或者距离预期的结果有多大出入吧?现在就来分析一下什么东西在影响输出。显然,输入的数据是已知的,变量只有那些个连接权重了,那这些连接权重如何影响输出呢?现在假设输入层第i个节点到隐层第j个节点的连接权重发生了一个很小的变化Δwij,那么这个Δwij将会对sj产生影响,导致sj也出现一个变化Δsj,然后产生Δθ(sj),然后传到各个输出层,最后在所有输出层都产生一个误差Δe。所以说,权重的调整将会使得输出结果产生变化,那么如何使这些输出结果往正确方向变化呢?这就是接下来的任务:如何调整权重。对于给定的训练样本,其正确的结果已经知道,那么由输入经过网络的输出和正确的结果比较将会有一个误差,如果能把这个误差将到最小,那么就是输出结果靠近了正确结果,就可以说网络可以对样本进行正确分类了。怎样使得误差最小呢?首先,把误差表达式写出来,为了使函数连续可导,这里最小化均方根差,定义损失函数如下:
L(e)=12SSE=12∑j=0ke2j=12∑j=0k(y¯j−yj)2
用什么方法最小化L?跟SVD算法一样,用随机梯度下降。也就是对每个训练样本都使权重往其负梯度方向变化。现在的任务就是求L对连接权重w的梯度。
用w1ij表示输入层第i个节点到隐层第j个节点的连接权重,w2ij表示隐层第i个节点到输出层第j个节点的连接权重,s1j表示隐层第j个节点的输入,s2j表示输出层第j个几点的输入,区别在右上角标,1表示第一层连接权重,2表示第二层连接权重。那么有
∂L∂w1ij=∂L∂s1j⋅∂s1j∂w1ij
由于
s1j=∑i=1mxi⋅w1ij
所以
∂s1j∂w1ij=xi
代入前面式子可得
∂L∂w1ij=xi⋅∂L∂s1j
接下来只需求出∂L∂s1j即可。
由于s1j对所有输出层都有影响,所以
∂L∂s1j=∑i=1k∂L∂s2i⋅∂s2i∂s1j
由于
s2i=∑j=0nθ(s1j)⋅w2ji
所以
∂s2i∂s1j=∂s2i∂θ(s1j)⋅∂θ(s1j)∂s1j=w2ji⋅θ′(s1j)
代入前面的式子可得
∂L∂s1j=∑i=1k∂L∂s2i⋅w2ji⋅θ′(s1j)=θ′(s1j)⋅∑i=1k∂L∂s2i⋅w2ji
现在记
δli=∂L∂sli
则隐层δ为
δ1j=θ′(s1j)⋅∑i=1kδ2i⋅w2ji
输出层δ为
δ2i=∂L∂s2i=∂∑kj=012(y¯j−yj)2∂s2i=(y¯i−yi)⋅∂y¯i∂s2i=ei⋅∂y¯i∂s2i=ei⋅θ′(s2i)
到这一步,可以看到是什么反向传播了吧?没错,就是误差e!
反向传播过程是这样的:输出层每个节点都会得到一个误差e,把e作为输出层反向输入,这时候就像是输出层当输入层一样把误差往回传播,先得到输出层δ,然后将输出层δ根据连接权重往隐层传输,即前面的式子:
δ1j=θ′(s1j)⋅∑i=1kδ2i⋅w2ji
现在再来看第一层权重的梯度:
∂L∂w1ij=xi⋅δ1j
第二层权重梯度:
∂L∂w2ij=∂L∂s2j⋅∂s2j∂w2ij=δ2j⋅θ(s1i)
可以看到一个规律:每个权重的梯度都等于与其相连的前一层节点的输出(即xi和θ(s1i))乘以与其相连的后一层的反向传播的输出(即δ1j和δ2j)
xi和θ(s1i))乘以与其相连的后一层的反向传播的输出(即δ1j和δ2j)。如果看不明白原理的话记住这句话即可!
这样反向传播得到所有的δ以后,就可以更新权重了。更直观的BP神经网络的工作过程总结如下:
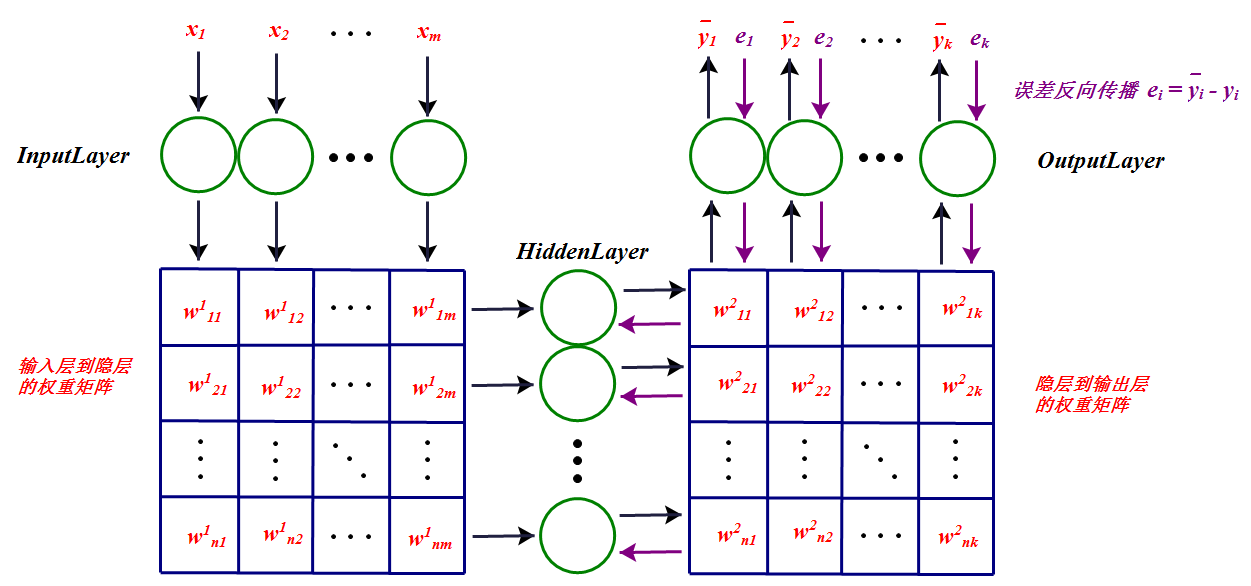
上图中每一个节点的输出都和权重矩阵中同一列(行)的元素相乘,然后同一行(列)累加作为下一层对应节点的输入。
为了代码实现的可读性,对节点进行抽象如下:
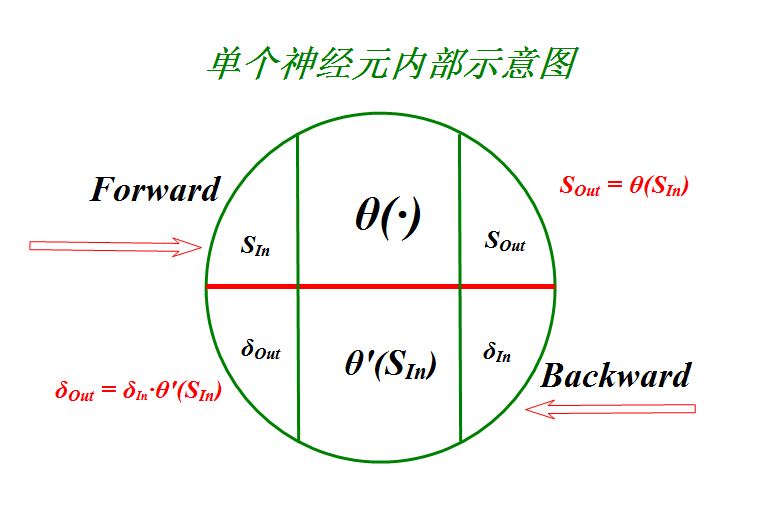
这样的话,很多步骤都在节点内部进行了。
当θ(s)=11+e−s时,
θ′(s)=θ(s)⋅(1−θ(s))=SOut⋅(1−SOut)
当θ(s)=es−e−ses+e−s时,
θ′(s)=1−θ(s)2=1−S2Out
BP网络原理部分就到这,接下来要根据上图中的神经元模型用代码实现BP网络,然后对Iris数据集进行分类。完整的代码见github:https://github.com/jingchenUSTC/ANN
首先,单个神经元封装代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
[/code]
然后就是整个神经网络类:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
[/code]
Iris数据有三种类别,所以输出层会有三个节点,每个节点代表一种类别,节点输出1(具体根据所用激活函数的上界)则表示属于该类,输出-1(具体根据所用激活函数的下界)则表示不属于该类。
完整的代码已共享到github,地址:https://github.com/jingchenUSTC/ANN。用BP网络对Iris数据进行分类的准确率接近100%!
BP网络的数学原理
BP网络算法实现
转载请声明出处http://blog.csdn.net/zhongkejingwang/article/details/44514073
上一篇文章介绍了KNN分类器,当时说了其分类效果不是很出色但是比较稳定,本文后面将利用BP网络同样对Iris数据进行分类。
什么是BP网络
BP神经网络,BP即Back Propagation的缩写,也就是反向传播的意思,顾名思义,将什么反向传播?文中将会解答。不仅如此,关于隐层的含义文中也会给出个人的理解。最后会用Java实现的BP分类器作为其应用以加深印象。很多初学者刚接触神经网络的时候都会到网上找相关的介绍,看了很多数学原理之后还是云里雾里,然后会琢磨到底这个有什么用?怎么用?于是又到网上找别人写的代码,下下来之后看一眼发现代码写的很糟糕,根本就理不清,怎么看也看不懂,于是就放弃了。作为过来人,本人之前在网上也看过很多关于BP网络的介绍,也下载了别人实现的代码下来研究,原理都一样,但是至今为止没有看到过能令人满意的代码实现。于是就有了这篇文章,不仅有原理也有代码,对节点的高度抽象会让代码更有可读性。
CSDN博客编辑器终于可以编写数学公式了!第一次使用Markdown编辑器,感觉爽歪歪,latex数学公式虽然写起来麻烦,不过很灵活,排版也漂亮~在这里贴一个Markdown输入数学公式的教程http://ttang.name/2014/05/04/markdown-and-mathjax/很全的说!
BP网络的数学原理
下面将介绍BP网络的数学原理,相比起SVD的算法推导,这个简直就是小菜一碟,不就是梯度吗求个导就完事了。首先来看看BP网络长什么样,这就是它的样子:为了简单起见,这里只介绍只有一个隐层的BP网络,多个隐层的也是一样的原理。这个网络的工作原理应该很清楚了,首先,一组输入x1、x2、…、xm来到输入层,然后通过与隐层的连接权重产生一组数据s1、s2、…、sn作为隐层的输入,然后通过隐层节点的θ(⋅)激活函数后变为θ(sj)其中sj表示隐层的第j个节点产生的输出,这些输出将通过隐层与输出层的连接权重产生输出层的输入,这里输出层的处理过程和隐层是一样的,最后会在输出层产生输出y¯j,这里j是指输出层第j个节点的输出。这只是前向传播的过程,很简单吧?在这里,先解释一下隐层的含义,可以看到,隐层连接着输入和输出层,它到底是什么?它就是特征空间,隐层节点的个数就是特征空间的维数,或者说这组数据有多少个特征。而输入层到隐层的连接权重则将输入的原始数据投影到特征空间,比如sj就表示这组数据在特征空间中第j个特征方向的投影大小,或者说这组数据有多少份量的j特征。而隐层到输出层的连接权重表示这些特征是如何影响输出结果的,比如某一特征对某个输出影响比较大,那么连接它们的权重就会比较大。关于隐层的含义就解释这么多,至于多个隐层的,可以理解为特征的特征。
前面提到激活函数θ(⋅),一般使用S形函数(即sigmoid函数),比如可以使用log-sigmoid:θ(s)=11+e−s
或者tan-sigmoid:θ(s)=es−e−ses+e−s
前面说了,既然在输出层产生输出了,那总得看下输出结果对不对吧或者距离预期的结果有多大出入吧?现在就来分析一下什么东西在影响输出。显然,输入的数据是已知的,变量只有那些个连接权重了,那这些连接权重如何影响输出呢?现在假设输入层第i个节点到隐层第j个节点的连接权重发生了一个很小的变化Δwij,那么这个Δwij将会对sj产生影响,导致sj也出现一个变化Δsj,然后产生Δθ(sj),然后传到各个输出层,最后在所有输出层都产生一个误差Δe。所以说,权重的调整将会使得输出结果产生变化,那么如何使这些输出结果往正确方向变化呢?这就是接下来的任务:如何调整权重。对于给定的训练样本,其正确的结果已经知道,那么由输入经过网络的输出和正确的结果比较将会有一个误差,如果能把这个误差将到最小,那么就是输出结果靠近了正确结果,就可以说网络可以对样本进行正确分类了。怎样使得误差最小呢?首先,把误差表达式写出来,为了使函数连续可导,这里最小化均方根差,定义损失函数如下:
L(e)=12SSE=12∑j=0ke2j=12∑j=0k(y¯j−yj)2
用什么方法最小化L?跟SVD算法一样,用随机梯度下降。也就是对每个训练样本都使权重往其负梯度方向变化。现在的任务就是求L对连接权重w的梯度。
用w1ij表示输入层第i个节点到隐层第j个节点的连接权重,w2ij表示隐层第i个节点到输出层第j个节点的连接权重,s1j表示隐层第j个节点的输入,s2j表示输出层第j个几点的输入,区别在右上角标,1表示第一层连接权重,2表示第二层连接权重。那么有
∂L∂w1ij=∂L∂s1j⋅∂s1j∂w1ij
由于
s1j=∑i=1mxi⋅w1ij
所以
∂s1j∂w1ij=xi
代入前面式子可得
∂L∂w1ij=xi⋅∂L∂s1j
接下来只需求出∂L∂s1j即可。
由于s1j对所有输出层都有影响,所以
∂L∂s1j=∑i=1k∂L∂s2i⋅∂s2i∂s1j
由于
s2i=∑j=0nθ(s1j)⋅w2ji
所以
∂s2i∂s1j=∂s2i∂θ(s1j)⋅∂θ(s1j)∂s1j=w2ji⋅θ′(s1j)
代入前面的式子可得
∂L∂s1j=∑i=1k∂L∂s2i⋅w2ji⋅θ′(s1j)=θ′(s1j)⋅∑i=1k∂L∂s2i⋅w2ji
现在记
δli=∂L∂sli
则隐层δ为
δ1j=θ′(s1j)⋅∑i=1kδ2i⋅w2ji
输出层δ为
δ2i=∂L∂s2i=∂∑kj=012(y¯j−yj)2∂s2i=(y¯i−yi)⋅∂y¯i∂s2i=ei⋅∂y¯i∂s2i=ei⋅θ′(s2i)
到这一步,可以看到是什么反向传播了吧?没错,就是误差e!
反向传播过程是这样的:输出层每个节点都会得到一个误差e,把e作为输出层反向输入,这时候就像是输出层当输入层一样把误差往回传播,先得到输出层δ,然后将输出层δ根据连接权重往隐层传输,即前面的式子:
δ1j=θ′(s1j)⋅∑i=1kδ2i⋅w2ji
现在再来看第一层权重的梯度:
∂L∂w1ij=xi⋅δ1j
第二层权重梯度:
∂L∂w2ij=∂L∂s2j⋅∂s2j∂w2ij=δ2j⋅θ(s1i)
可以看到一个规律:每个权重的梯度都等于与其相连的前一层节点的输出(即xi和θ(s1i))乘以与其相连的后一层的反向传播的输出(即δ1j和δ2j)
xi和θ(s1i))乘以与其相连的后一层的反向传播的输出(即δ1j和δ2j)。如果看不明白原理的话记住这句话即可!
这样反向传播得到所有的δ以后,就可以更新权重了。更直观的BP神经网络的工作过程总结如下:
上图中每一个节点的输出都和权重矩阵中同一列(行)的元素相乘,然后同一行(列)累加作为下一层对应节点的输入。
为了代码实现的可读性,对节点进行抽象如下:
这样的话,很多步骤都在节点内部进行了。
当θ(s)=11+e−s时,
θ′(s)=θ(s)⋅(1−θ(s))=SOut⋅(1−SOut)
当θ(s)=es−e−ses+e−s时,
θ′(s)=1−θ(s)2=1−S2Out
BP网络原理部分就到这,接下来要根据上图中的神经元模型用代码实现BP网络,然后对Iris数据集进行分类。完整的代码见github:https://github.com/jingchenUSTC/ANN
BP网络算法实现
首先,单个神经元封装代码如下://NetworkNode.java
package com.jingchen.ann;
public class NetworkNode
{
public static final int TYPE_INPUT = 0;
public static final int TYPE_HIDDEN = 1;
public static final int TYPE_OUTPUT = 2;
private int type;
public void setType(int type)
{
this.type = type;
}
// 节点前向输入输出值
private float mForwardInputValue;
private float mForwardOutputValue;
// 节点反向输入输出值
private float mBackwardInputValue;
private float mBackwardOutputValue;
public NetworkNode()
{
}
public NetworkNode(int type)
{
this.type = type;
}
/**
* sigmoid函数,这里用tan-sigmoid,经测试其效果比log-sigmoid好!
*
* @param in
* @return
*/
private float forwardSigmoid(float in)
{
switch (type)
{
case TYPE_INPUT:
return in;
case TYPE_HIDDEN:
case TYPE_OUTPUT:
return tanhS(in);
}
return 0;
}
/**
* log-sigmoid函数
*
* @param in
* @return
*/
private float logS(float in)
{
return (float) (1 / (1 + Math.exp(-in)));
}
/**
* log-sigmoid函数的导数
*
* @param in
* @return
*/
private float logSDerivative(float in)
{
return mForwardOutputValue * (1 - mForwardOutputValue) * in;
}
/**
* tan-sigmoid函数
*
* @param in
* @return
*/
private float tanhS(float in)
{
return (float) ((Math.exp(in) - Math.exp(-in)) / (Math.exp(in) + Math
.exp(-in)));
}
/**
* tan-sigmoid函数的导数
*
* @param in
* @return
*/
private float tanhSDerivative(float in)
{
return (float) ((1 - Math.pow(mForwardOutputValue, 2)) * in);
}
/**
* 误差反向传播时,激活函数的导数
*
* @param in
* @return
*/
private float backwardPropagate(float in)
{
switch (type)
{
case TYPE_INPUT:
return in;
case TYPE_HIDDEN:
case TYPE_OUTPUT:
return tanhSDerivative(in);
}
return 0;
}
public float getForwardInputValue()
{
return mForwardInputValue;
}
public void setForwardInputValue(float mInputValue)
{
this.mForwardInputValue = mInputValue;
setForwardOutputValue(mInputValue);
}
public float getForwardOutputValue()
{
return mForwardOutputValue;
}
private void setForwardOutputValue(float mInputValue)
{
this.mForwardOutputValue = forwardSigmoid(mInputValue);
}
public float getBackwardInputValue()
{
return mBackwardInputValue;
}
public void setBackwardInputValue(float mBackwardInputValue)
{
this.mBackwardInputValue = mBackwardInputValue;
setBackwardOutputValue(mBackwardInputValue);
}
public float getBackwardOutputValue()
{
return mBackwardOutputValue;
}
private void setBackwardOutputValue(float input)
{
this.mBackwardOutputValue = backwardPropagate(input);
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
[/code]
然后就是整个神经网络类:
//AnnClassifier.java
package com.jingchen.ann;
import java.util.ArrayList;
import java.util.List;
/**
* 人工神经网络分类器
*
* @author chenjing
*
*/
public class AnnClassifier
{
private int mInputCount;
private int mHiddenCount;
private int mOutputCount;
private List<NetworkNode> mInputNodes;
private List<NetworkNode> mHiddenNodes;
private List<NetworkNode> mOutputNodes;
private float[][] mInputHiddenWeight;
private float[][] mHiddenOutputWeight;
private List<DataNode> trainNodes;
public void setTrainNodes(List<DataNode> trainNodes)
{
this.trainNodes = trainNodes;
}
public AnnClassifier(int inputCount, int hiddenCount, int outputCount)
{
trainNodes = new ArrayList<DataNode>();
mInputCount = inputCount;
mHiddenCount = hiddenCount;
mOutputCount = outputCount;
mInputNodes = new ArrayList<NetworkNode>();
mHiddenNodes = new ArrayList<NetworkNode>();
mOutputNodes = new ArrayList<NetworkNode>();
mInputHiddenWeight = new float[inputCount][hiddenCount];
mHiddenOutputWeight = new float[mHiddenCount][mOutputCount];
}
/**
* 更新权重,每个权重的梯度都等于与其相连的前一层节点的输出乘以与其相连的后一层的反向传播的输出
*/
private void updateWeights(float eta)
{
//更新输入层到隐层的权重矩阵
for (int i = 0; i < mInputCount; i++)
for (int j = 0; j < mHiddenCount; j++)
mInputHiddenWeight[i][j] -= eta
* mInputNodes.get(i).getForwardOutputValue()
* mHiddenNodes.get(j).getBackwardOutputValue();
//更新隐层到输出层的权重矩阵
for (int i = 0; i < mHiddenCount; i++)
for (int j = 0; j < mOutputCount; j++)
mHiddenOutputWeight[i][j] -= eta
* mHiddenNodes.get(i).getForwardOutputValue()
* mOutputNodes.get(j).getBackwardOutputValue();
}
/**
* 前向传播
*/
private void forward(List<Float> list)
{
// 输入层
for (int k = 0; k < list.size(); k++)
mInputNodes.get(k).setForwardInputValue(list.get(k));
// 隐层
for (int j = 0; j < mHiddenCount; j++)
{
float temp = 0;
for (int k = 0; k < mInputCount; k++)
temp += mInputHiddenWeight[k][j]
* mInputNodes.get(k).getForwardOutputValue();
mHiddenNodes.get(j).setForwardInputValue(temp);
}
// 输出层
for (int j = 0; j < mOutputCount; j++)
{
float temp = 0;
for (int k = 0; k < mHiddenCount; k++)
temp += mHiddenOutputWeight[k][j]
* mHiddenNodes.get(k).getForwardOutputValue();
mOutputNodes.get(j).setForwardInputValue(temp);
}
}
/**
* 反向传播
*/
private void backward(int type)
{
// 输出层
for (int j = 0; j < mOutputCount; j++)
{
//输出层计算误差把误差反向传播,这里-1代表不属于,1代表属于
float result = -1;
if (j == type)
result = 1;
mOutputNodes.get(j).setBackwardInputValue(
mOutputNodes.get(j).getForwardOutputValue() - result);
}
// 隐层
for (int j = 0; j < mHiddenCount; j++)
{
float temp = 0;
for (int k = 0; k < mOutputCount; k++)
temp += mHiddenOutputWeight[j][k]
* mOutputNodes.get(k).getBackwardOutputValue();
}
}
public void train(float eta, int n)
{
reset();
for (int i = 0; i < n; i++)
{
for (int j = 0; j < trainNodes.size(); j++)
{
forward(trainNodes.get(j).getAttribList());
backward(trainNodes.get(j).getType());
updateWeights(eta);
}
}
}
/**
* 初始化
*/
private void reset()
{
mInputNodes.clear();
mHiddenNodes.clear();
mOutputNodes.clear();
for (int i = 0; i < mInputCount; i++)
mInputNodes.add(new NetworkNode(NetworkNode.TYPE_INPUT));
for (int i = 0; i < mHiddenCount; i++)
mHiddenNodes.add(new NetworkNode(NetworkNode.TYPE_HIDDEN));
for (int i = 0; i < mOutputCount; i++)
mOutputNodes.add(new NetworkNode(NetworkNode.TYPE_OUTPUT));
for (int i = 0; i < mInputCount; i++)
for (int j = 0; j < mHiddenCount; j++)
mInputHiddenWeight[i][j] = (float) (Math.random() * 0.1);
for (int i = 0; i < mHiddenCount; i++)
for (int j = 0; j < mOutputCount; j++)
mHiddenOutputWeight[i][j] = (float) (Math.random() * 0.1);
}
public int test(DataNode dn)
{
forward(dn.getAttribList());
float result = 2;
int type = 0;
//取最接近1的
for (int i = 0; i < mOutputCount; i++)
if ((1 - mOutputNodes.get(i).getForwardOutputValue()) < result)
{
result = 1 - mOutputNodes.get(i).getForwardOutputValue();
type = i;
}
return type;
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
[/code]
Iris数据有三种类别,所以输出层会有三个节点,每个节点代表一种类别,节点输出1(具体根据所用激活函数的上界)则表示属于该类,输出-1(具体根据所用激活函数的下界)则表示不属于该类。
完整的代码已共享到github,地址:https://github.com/jingchenUSTC/ANN。用BP网络对Iris数据进行分类的准确率接近100%!

相关文章推荐
- BP神经网络的数学原理及其算法实现
- BP神经网络的数学原理及其算法实现
- BP神经网络的数学原理及其算法实现
- BP神经网络的数学原理及其算法实现
- BP神经网络的数学原理及其算法实现
- BP神经网络的数学原理及其算法实现
- BP神经网络的数学原理及其算法实现
- BP神经网络的数学原理及其算法实现
- BP神经网络的数学原理及其算法实现
- Camshift算法原理及其Opencv实现
- OpenCV: Canny边缘检测算法原理及其VC实现详解
- Round-Robin负载均衡算法及其实现原理(转)
- Canny边缘检测算法原理及其VC实现详解(二)
- Canny边缘检测算法原理及其VC实现详解(二)
- Canny边缘检测算法原理及其VC实现详解(一)
- 算法基础:堆排序原理及其实现
- Canny边缘检测算法原理及其VC实现详解(二)
- Canny边缘检测算法原理及其VC实现详解(一)
- Canny边缘检测算法原理及其VC实现详解(二)
- 【密码学】RC4加解密原理及其Java和C实现算法