Java 8 中的流--Stream
2017-11-18 00:00
281 查看
摘要: java 8 中的流,Stream, Lambda表达式
Java 8中的Stream API可以让你写出这样的代码:
声明性——更简洁,更易读
可复合——更灵活
可并行——性能更好
首先看一下使用流和不使用流的区别,需求: 把集合中年龄小于等于20的人的名字取出来并排序
不使用流:
使用流:
让我们一步步剖析这个定义:
1. 元素序列
就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元 素(如ArrayList 与 LinkedList)。但流的目的在于表达计算,集合讲的是数据,流讲的是计算。
2. 源
流会使用一个提供数据的源,如集合、数组或输入/输出资源。 请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
3. 数据处理操作
流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如filter、 map、 reduce、 find、 match、 sort等。流操作可以顺序执行,也可并行执行。
流操作有两个重要的特点。
1. 流水线
很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。流水线的操作可以 看作对数据源进行数据库式查询。
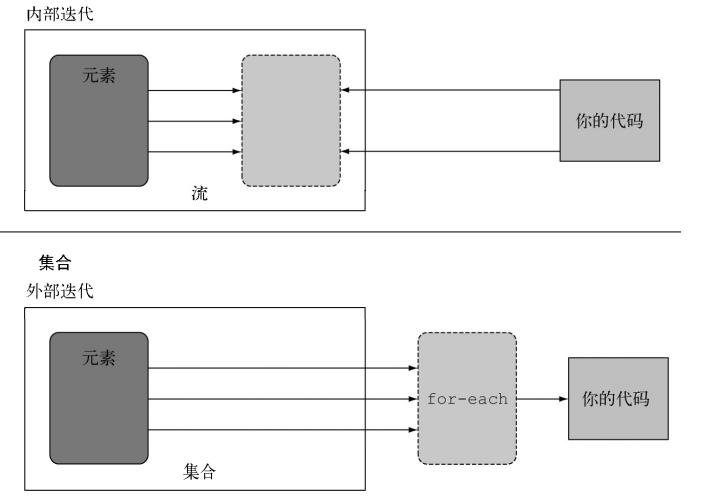
2. 内部迭代
与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
看一段能够显示这些概念的代码,需求是: 把集合中年龄小于等于20的人的名字取出来并排序
本例中,我们先是对users调用stream方法,由用户列表得到一个流。 数据源是用户列表,它给流提供一个元素序列。接下来,对流应用一系列数据处理操作: filter、 map、 sorted和collect。除了collect之外,所有这些操作都会返回另一个流,这样它们就可以接成一条流 水线,于是就可以看作对源的一个查询。最后, collect操作开始处理流水线,并返回结果(它 和别的操作不一样,因为它返回的不是流,在这里是一个List)。在调用collect之前,没有任 何结果产生,实际上根本就没有从users里选择元素。你可以这么理解:链中的方法调用都在排 队等待,直到调用collect。
相比之下,流则是在概念上固定的数据结构(你不能添加或删除元素),其元素则是按需计算的。 从另一个角度来说,流就像是一个延迟创建的集合:只有在消费者要求的时候才会计算值
以质数为例,要是想创建一个包含所有质数的集合,那这个程序算起来就没完没了了,因为总有新的质数要算,然后把它加到集合里面。
而流的话,仅仅从流中提取需要的值,而这些值——在用户看不见的地方,只会按需生成。
如下代码所示: 这段代码的意思是遍历 lists 集合
1. 中间操作
2. 终端操作
在上述例子中,filter,sorted,map 等都是中间操作,collect等是终端操作
中间操作可以连成一条流水线,终端触发流水线执行并关闭它。
总而言之,流的使用一般包括三件事:
1. 一个数据源(如集合)来执行一个查询;
2. 一个中间操作链,形成一条流的流水线;
3. 一个终端操作,执行流水线,并能生成结果
该方法接受一个 Predicate 作为参数。 如下代码所示,
注:map不是我们理解的集合Map,应该理解为映射,将一个值映射为另一个值
如下的例子为:取出集合中用户的名字,返回一个名字集合
anyMatch、 allMatch和noneMatch这三个操作都用到了我们所谓的短路,这就是大家熟悉的Java中&&和||运算符短路在流中的版本。
三个重载的方法:
提供一个初始值,后面是一个Lambda表达式,如计算两个值的最大值:
只是提供一个 Lambda表达式,返回一个Optional对象
第三个重载的方法的第三个参数的意思: Stream是支持并发操作的,为了避免竞争,对于reduce线程都会有独立的result,combiner的作用在于合并每个线程的result得到最终结果。
这段代码的问题是,它有一个暗含的装箱成本。每个Integer都必须拆箱成一个原始类型,再进行求和。
Java 8引入了三个原始类型特化流接口来解决这个问题: IntStream、 DoubleStream和 LongStream,分别将流中的元素特化为int、 long和double,从而避免了暗含的装箱成本。
每个接口都带来了进行常用数值归约的新方法,比如对数值流求和的sum,找到最大元素的max。 此外还有在必要时再把它们转换回对象流的方法。
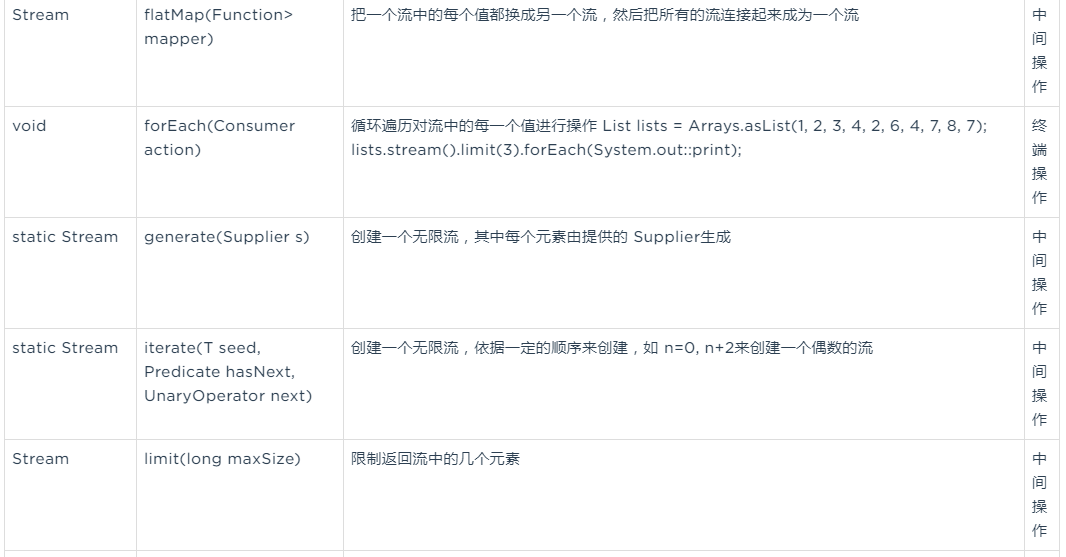
一般来说,在需要依次生成一系列值的时候应该使用iterate,比如一系列日期: 1月31日, 2月1日,依此类推。 与iterate方法类似, generate方法也可让你按需生成一个无限流。但generate不是依次 对每个新生成的值应用函数的。它接受一个Supplier<T>类型的Lambda提供新的值。


java 8中的流(Stream)
流是Java API的新成员,它允许你以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)Java 8中的Stream API可以让你写出这样的代码:
声明性——更简洁,更易读
可复合——更灵活
可并行——性能更好
首先看一下使用流和不使用流的区别,需求: 把集合中年龄小于等于20的人的名字取出来并排序
不使用流:
public List<String> beforeJava7(List<User> users){
// 取年龄 <= 20的用户
List<User> tmpList = new ArrayList<>();
for (User user : users) {
if (user.getAge() <= 20){
tmpList.add(user);
}
}
// 排序
Collections.sort(tmpList, new Comparator<User>() {
public int compare(User u1, User u2) {
return u1.getName().compareTo(u2.getName());
}
});
// 取名字
List<String> userNames = new ArrayList<>();
for(User user : tmpList){
userNames.add(user.getName());
}
return userNames;
}使用流:
public List<String> java8(List<User> users){
//为了利用多核架构并行执行这段代码,只需要把stream()换成parallelStream():
List<String> userNames = users.stream()
.filter(user -> user.getAge() <= 20)
.sorted(Comparator.comparing(User::getName))
.map(User::getName)
.collect(Collectors.toList());
return userNames;
}流的定义:
从支持数据处理操作的源生成的元素序列。让我们一步步剖析这个定义:
1. 元素序列
就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元 素(如ArrayList 与 LinkedList)。但流的目的在于表达计算,集合讲的是数据,流讲的是计算。
2. 源
流会使用一个提供数据的源,如集合、数组或输入/输出资源。 请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
3. 数据处理操作
流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如filter、 map、 reduce、 find、 match、 sort等。流操作可以顺序执行,也可并行执行。
流操作有两个重要的特点。
1. 流水线
很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。流水线的操作可以 看作对数据源进行数据库式查询。
2. 内部迭代
与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
看一段能够显示这些概念的代码,需求是: 把集合中年龄小于等于20的人的名字取出来并排序
public List<String> java8(List<User> users){
List<String> userNames = users.stream()
.filter(user -> user.getAge() <= 20)
.sorted(Comparator.comparing(User::getName))
.map(User::getName)
.collect(Collectors.toList());
return userNames;
}本例中,我们先是对users调用stream方法,由用户列表得到一个流。 数据源是用户列表,它给流提供一个元素序列。接下来,对流应用一系列数据处理操作: filter、 map、 sorted和collect。除了collect之外,所有这些操作都会返回另一个流,这样它们就可以接成一条流 水线,于是就可以看作对源的一个查询。最后, collect操作开始处理流水线,并返回结果(它 和别的操作不一样,因为它返回的不是流,在这里是一个List)。在调用collect之前,没有任 何结果产生,实际上根本就没有从users里选择元素。你可以这么理解:链中的方法调用都在排 队等待,直到调用collect。
流与集合的区别:
集合与流之间的差异就在于什么时候进行计算。集合是一个内存中的数据结构,它包含数据结构中目前所有的值——集合中的每个元素都得先算出来才能添加到集合中。(你可以往集合里加东西或者删东西,但是不管什么时候,集合中的每个元素都是放在内存里的,元素都得先算出来才能成为集合的一部分。)相比之下,流则是在概念上固定的数据结构(你不能添加或删除元素),其元素则是按需计算的。 从另一个角度来说,流就像是一个延迟创建的集合:只有在消费者要求的时候才会计算值
以质数为例,要是想创建一个包含所有质数的集合,那这个程序算起来就没完没了了,因为总有新的质数要算,然后把它加到集合里面。
而流的话,仅仅从流中提取需要的值,而这些值——在用户看不见的地方,只会按需生成。
流只能被消费一次,如果被消费多次,则会抛出异常:
java.lang.IllegalStateException: stream has already been operated upon or closed
如下代码所示: 这段代码的意思是遍历 lists 集合
List<String> lists = Arrays.asList("java8","lambda","stream");
Stream<String> stringStream = lists.stream();
Consumer<String> consumer = (x) -> System.out.println(x);
stringStream.forEach(consumer);
//stream has already been operated upon or closed
stringStream.forEach(consumer);外部迭代与内部迭代
使用Collection接口需要用户去做迭代(比如用for-each),这称为外部迭代。 相反,Streams库使用内部迭代——它帮你把迭代做了,还把得到的流值存在了某个地方,你只要给出 一个函数说要干什么就可以了。流操作
java.util.stream.Stream中的Stream接口定义了许多操作。它们可以分为两大类。1. 中间操作
2. 终端操作
在上述例子中,filter,sorted,map 等都是中间操作,collect等是终端操作
中间操作可以连成一条流水线,终端触发流水线执行并关闭它。
中间操作:
诸如filter或sorted等中间操作会返回另一个流。这让多个操作可以连接起来形成一个查询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理。这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理。终端操作:
终端操作会从流的流水线生成结果。其结果是任何不是流的值,比如List、 Integer,甚至void。总而言之,流的使用一般包括三件事:
1. 一个数据源(如集合)来执行一个查询;
2. 一个中间操作链,形成一条流的流水线;
3. 一个终端操作,执行流水线,并能生成结果
使用流:
筛选
filter()方法
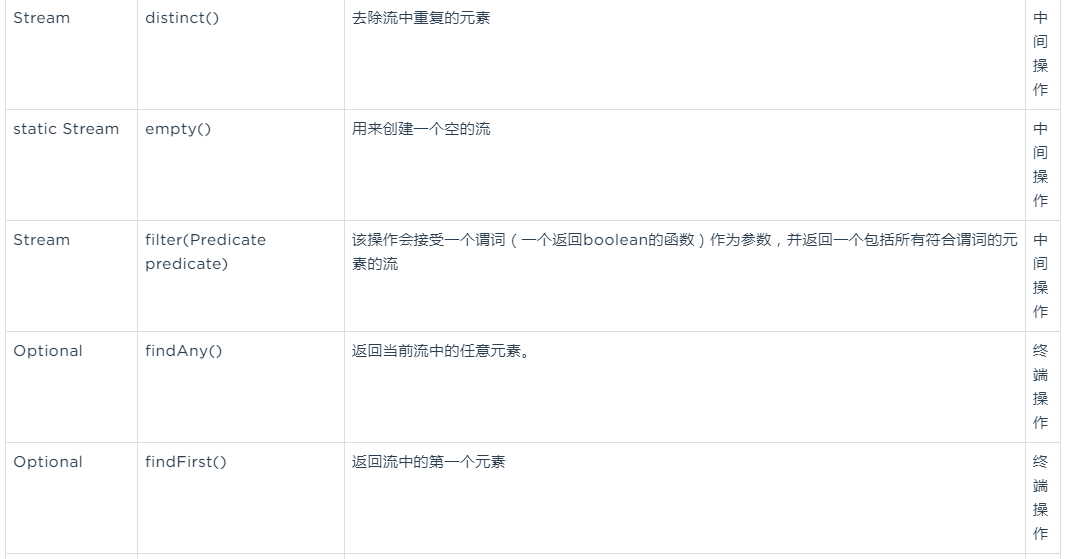
Streams接口的filter方法,该操作会接受一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流。filter(Predicate<? super T> predicate)
该方法接受一个 Predicate 作为参数。 如下代码所示,
/**
* 把用户集合中性别是男的用户选择出来
* user1, users2, users3是三种不同的写法,结果都一样
* @param users 原始用户集合
* @return 性别是男性的用户
*/
public List<User> filterOfStream(List<User> users){
List<User> users1 = users.stream().filter(User::isMen).collect(Collectors.toList());
List<User> users2 = users.stream().filter(u -> u.getGender().equals("男")).collect(Collectors.toList());
Predicate<User> predicate = (u) -> u.getGender().equals("男");
List<User> users3 = users.stream().filter(predicate).collect(Collectors.toList());
//return users1;
//return users2;
return users3;
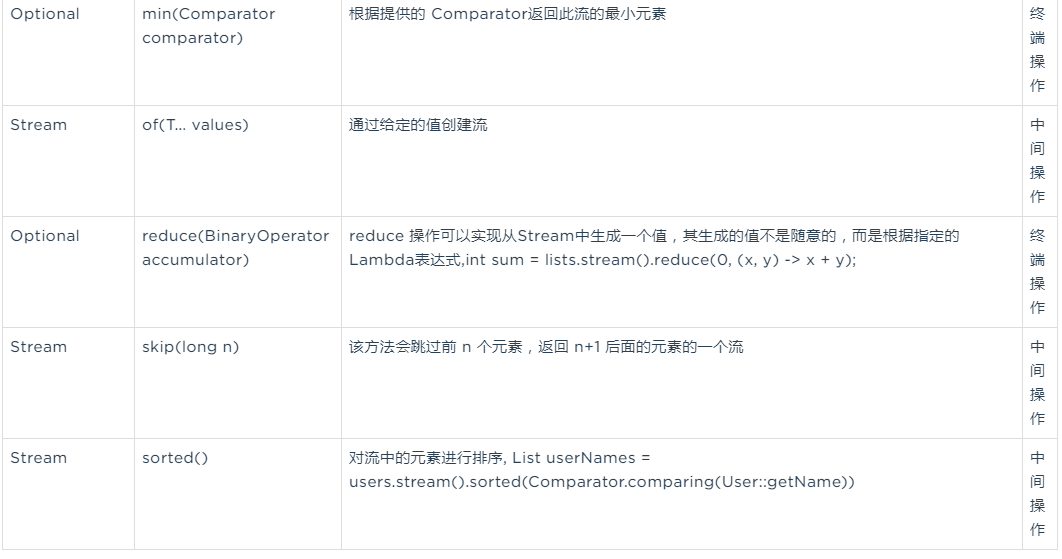
}distinct()方法:
该方法对流中重复的元素去重/**
* distinct(): 去除流中重复的元素
* 打印集合中的偶数,并且不能重复
*/
public void distinctOfStream(){
List<Integer> lists = Arrays.asList(1, 2, 3, 4, 2, 6, 4, 7, 8, 7);
//2468
lists.stream().filter(x -> x % 2 == 0).distinct().forEach(System.out::print);
// 另一种写法
Consumer<Integer> consumer = (x) -> System.out.print(x);
//2468
lists.stream().filter(x -> x % 2 == 0).distinct().forEach(consumer);
}limit()方法:
该方法会返回一个不超过给定长度的流。如果流是有序的,则最多会返回前n个元素。 如果是无序的,如set,limit的结果不会以任何顺序排列。/**
* limit():返回流中指定长度的流
*/
public void limitOfStream(){
List<Integer> lists = Arrays.asList(1, 2, 3, 4, 2, 6, 4, 7, 8, 7);
//获取 lists 中前三个元素, 有序
// 123
lists.stream().limit(3).forEach(System.out::print);
}skip(n)方法:
该方法会跳过前 n 个元素,返回 n+1 后面的元素的一个流/**
* skip(n):跳过前n个元素,返回n后面的元素
*/
public void skipOfStream(){
List<Integer> lists = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//跳过前5个元素,从第6个元素开始打印
//678910
lists.stream().skip(5).forEach(System.out::print);
}映射
一个非常常见的数据处理套路就是从某些对象中选择信息。比如在SQL里,你可以从表中选择一列。 Stream API也通过map和flatMap方法提供了类似的工具。map()方法:
它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素注:map不是我们理解的集合Map,应该理解为映射,将一个值映射为另一个值
如下的例子为:取出集合中用户的名字,返回一个名字集合
/**
* @param users 用户集合
* @return 用户名字集合
*/
public List<String> mapOfStream(List<User> users){
List<String> usersNames = users.stream().map(User::getName).collect(Collectors.toList());
// 另一种写法
Function<User, String> function = (user) -> user.getName();
List<String> usersNames2 = users.stream().map(function).collect(Collectors.toList());
//return usersNames2;
// 获取每个用户的名字的长度
// 写法一
List<Integer> userNameLength = users.stream()
.map(User::getName)// 获取用户名
.map(String::length) // 获取每个用户名的长度
.collect(Collectors.toList()); // 返回一个集合
// 写法二
Function<User, String> name = user -> user.getName();
Function<String, Integer> len = s -> s.length();
List<Integer> userNameLength2 = users.stream().map(name).map(len).collect(Collectors.toList());
// 写法三
List<Integer> userNameLength3 = users.stream().map(s -> s.getName()).map(s -> s.length()).collect(Collectors.toList());
return usersNames;
}flatmap()方法:
flatmap方法把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。查找和匹配
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性。 StreamAPI通过allMatch、 anyMatch、 noneMatch、 findFirst和findAny方法提供了这样的工具。anyMatch()方法:
该方法的意思是 流中是否有一个元素能匹配给定的谓词,只要有一个能够匹配,就返回 true/**
* anyMatch(): 流中是否有一个元素能匹配给定的谓词,只要有一个能够匹配,就返回 true
*/
public void anyMatchOfStream(){
List<Integer> lists = Arrays.asList(1, 2, 3, 3, 4, 5);
Stream<Integer> stream = lists.stream();
if (stream.anyMatch(i -> i == 3)){
System.out.println("包含 3");
}else{
System.out.println("不包含 3");
}
}allMatch()方法:
检查流中的元素是否都能匹配给定的谓词,只有所有的值和给定的谓词相等,才返回 true/**
* allMatch():检查流中的元素是否都能匹配给定的谓词
*/
public void allMatch(){
List<Integer> lists = Arrays.asList(3, 3);
if (lists.stream().allMatch(i -> i == 3)){
System.out.println("完全匹配");
}else{
System.out.println("不完全匹配");
}
}noneMatch()方法:
确保流中没有任何元素与给定的谓词匹配,没有匹配,返回 trueanyMatch、 allMatch和noneMatch这三个操作都用到了我们所谓的短路,这就是大家熟悉的Java中&&和||运算符短路在流中的版本。
findAny()方法:
findAny方法将返回当前流中的任意元素。它可以与其他流操作结合使用public void findAnyOfStream(List<User> users){
Optional<User> user =
users.stream().filter(u -> u.getName().equals("男")).findAny();
}findFirst()方法:
该方法返回流中的第一个元素归约
reduce()方法:
reduce 操作可以实现从Stream中生成一个值,其生成的值不是随意的,而是根据指定的Lambda表达式。/**
* reduce()
*/
public void reduceOfStream(){
List<Integer> lists = Arrays.asList(1, 2, 3, 3, 4, 5);
// 元素的总和
int sum = lists.stream().reduce(0, (x, y) -> x + y);
Optional<Integer> sum2 = lists.stream().reduce(Integer::sum);
System.out.println("sum = " + sum);
System.out.println("sum2 = " + sum2.get());
// 求最大值
int max = lists.stream().reduce(0, (x, y) -> x > y ? x : y);
Optional<Integer> max2 = lists.stream().reduce(Integer::max);
System.out.println("max = " + max);
System.out.println("max2 = " + max2.get());
// 最小值
int min = lists.stream().reduce(1, (x, y) -> x > y ? y : x);
Optional<Integer> min2 = lists.stream().reduce(Integer::min);
System.out.println("min = " + min);
System.out.println("min2 = " + min2.get());
}三个重载的方法:
reduce(T identity, BinaryOperator<T> accumulator)
提供一个初始值,后面是一个Lambda表达式,如计算两个值的最大值:
int max = lists.stream().reduce(0, (x, y) -> x > y ? x : y);
Optional<T> reduce(BinaryOperator<T> accumulator)
只是提供一个 Lambda表达式,返回一个Optional对象
Optional<Integer> max2 = lists.stream().reduce(Integer::max);
reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
第三个重载的方法的第三个参数的意思: Stream是支持并发操作的,为了避免竞争,对于reduce线程都会有独立的result,combiner的作用在于合并每个线程的result得到最终结果。
数值流
前面看到了可以使用reduce方法计算流中元素的总和int sum = lists.stream().reduce(0, Integer::sum);
这段代码的问题是,它有一个暗含的装箱成本。每个Integer都必须拆箱成一个原始类型,再进行求和。
Java 8引入了三个原始类型特化流接口来解决这个问题: IntStream、 DoubleStream和 LongStream,分别将流中的元素特化为int、 long和double,从而避免了暗含的装箱成本。
每个接口都带来了进行常用数值归约的新方法,比如对数值流求和的sum,找到最大元素的max。 此外还有在必要时再把它们转换回对象流的方法。
将流转换为特化版本的常用方法是mapToInt、 mapToDouble和mapToLong。
要把特型流转换成一般流(每个int都会装箱成一个Integer),可以使用boxed方法
Stream<Integer> stream = intStream.boxed();
数值的范围:
java 8引入了两个可以用于IntStream和LongStream的静态方法,帮助生成数值的范围: range和rangeClosed。这两个方法都是第一个参数接受起始值,第二个参数接受结束值。但 range是不包含结束值的,而rangeClosed则包含结束值。IntStream evenNumbers = IntStream.rangeClosed(1, 100) .filter(n -> n % 2 == 0); System.out.println(evenNumbers.count());
创建流的方式:
1. 由值创建流
可以使用静态方法Stream.of,通过显式值创建一个流。它可以接受任意数量的参数。 以下代码直接使用Stream.of创建了一个字符串流。然后,你可以将字符串转换为大写,再一个个打印出来:/**
* of() 方法创建流
*/
public void ofOfStream(){
Stream<String> stringStream = Stream.of("java", "lambda", "stream");
stringStream.map(s -> s.toUpperCase()).forEach(System.out::println);2. 由数组创建流
可以使用静态方法Arrays.stream从数组创建一个流。它接受一个数组作为参数。int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers)3. 由文件生成流
Java中用于处理文件等I/O操作的NIO API(非阻塞 I/O)已更新,以便利用Stream API。 java.nio.file.Files中的很多静态方法都会返回一个流。4. 由函数生成流:
创建无限流 Stream API提供了两个静态方法来从函数生成流: Stream.iterate和Stream.generate。 这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。由iterate 和generate产生的流会用给定的函数按需创建值,因此可以无穷无尽地计算下去!一般来说, 应该使用limit(n)来对这种流加以限制,以避免打印无穷多个值。一般来说,在需要依次生成一系列值的时候应该使用iterate,比如一系列日期: 1月31日, 2月1日,依此类推。 与iterate方法类似, generate方法也可让你按需生成一个无限流。但generate不是依次 对每个新生成的值应用函数的。它接受一个Supplier<T>类型的Lambda提供新的值。
常用的流操作:

相关文章推荐
- Java 流(Stream)、文件(File)和IO
- Java IO类库之PrintStreamWriter
- Java中getResourceAsStream的用法
- Java中getResourceAsStream的用法
- com.mysql.jdbc.ServerPreparedStatement.setCharacterStream(ILjava/io/Reader;J)V
- 黑马程序员—JAVA IO(Buffer和Stream)
- Java流(Stream)、文件(File)和IO
- java stream相关的类小记备忘
- spark createDirectStream保存kafka offset(JAVA实现)
- 深入理解 Java中的 流 (Stream)
- Java - getClass().getResourceAsStream()
- Java.io.StreamTokenizer的使用小结
- Java 流(Stream)简介:2、Reader 和 Writer
- Java中的getResourceAsStream
- java 的 Stream.
- Java中getResourceAsStream的用法
- Java Stream API进阶篇
- java.lang.IllegalStateException: Already using output stream分析及处理办法
- java ftp org.apache.commons.net.io.CopyStreamException
- Java8初体验-Stream语法详解