java8函数式编程数据并行化<三>
2017-11-18 00:00
267 查看
摘要: java8函数式编程数据并行化
数据并行化是指将数据分成块,为每块数据分配单独的处理单元。《java8函数式编程》书中拿马拉车那个例子打比方,就像从车里取出一些货物,放到另一辆车上,两辆马车都沿着同样的路径到达目的地,书中画的图也是很容易理解,后面也copy了不少原句。
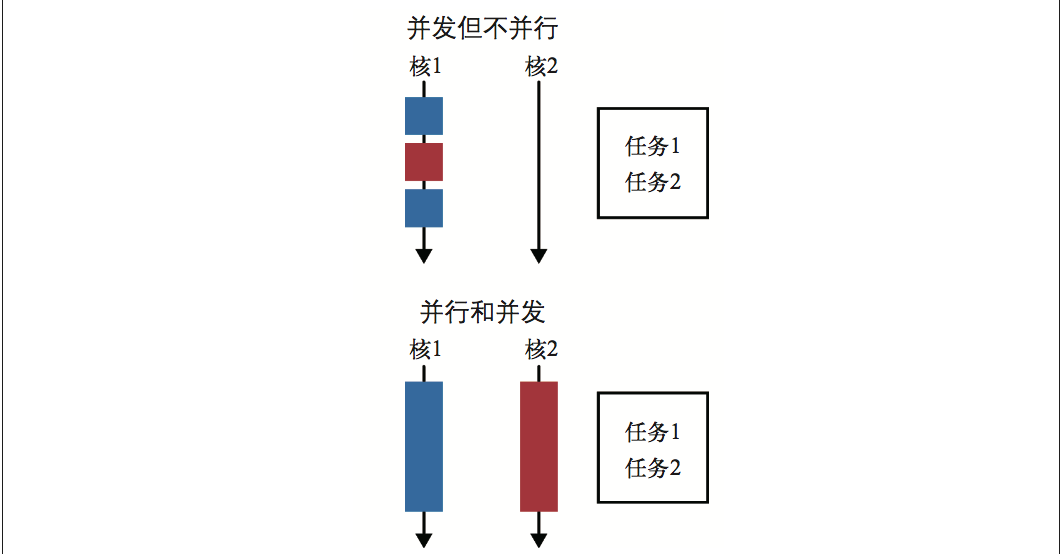
当需要在大量数据上执行同样的操作时,数据并行化很管用。它将问题分解为可在多块数 据上求解的形式,然后对每块数据执行运算,最后将各数据块上得到的结果汇总,从而获 得最终答案。这个描述还有点像分治法,或者归并排序。
如果已经有一个 Stream 对象,调用它的 parallel 方法就能让其拥有并行操作的能力。如果想从一个集合类创建一个流,调用 parallelStream 就能立即获得一个拥有并行能力的流,使用起来很简单,只要改动一个方法,其他都是一样的,不必理会串行还是并行,只要告诉程序怎么做就行了,毕竟告诉计算机做什么和怎么做是两回事。
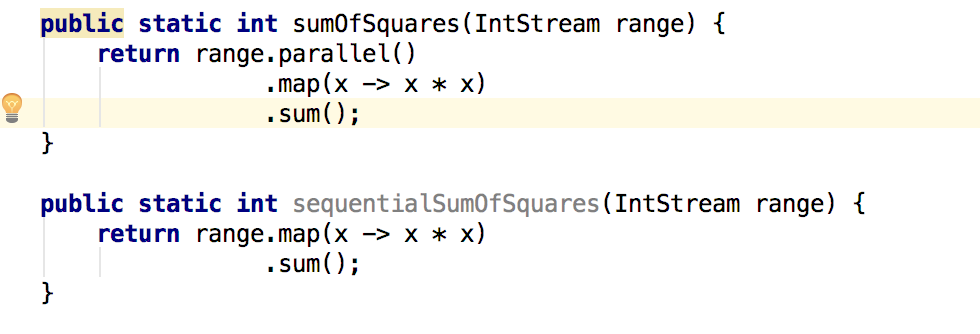
并发化数组操作

但是有人会问串行和并行哪一个快?这就要看具体的环境要求了,主要影响因素如下:
数据大小:只有数据足够大、每个数据处理管道花费的时间足够多 时,并行化处理才有意义。
源数据结构:每个管道的操作都基于一些初始数据源,通常是集合。
装箱 处理基本类型比处理装箱类型要快。
核的数量:在实践中,核的数量不单指你的机器上有多少核,更是指运行时 你的机器能使用多少核。这也就是说同时运行的其他进程,或者线程关联性(强制线程 在某些核或 CPU 上运行)会影响性能。
单元处理开销:花在流中 每个元素身上的时间越长,并行操作带来的性能提升越明显。
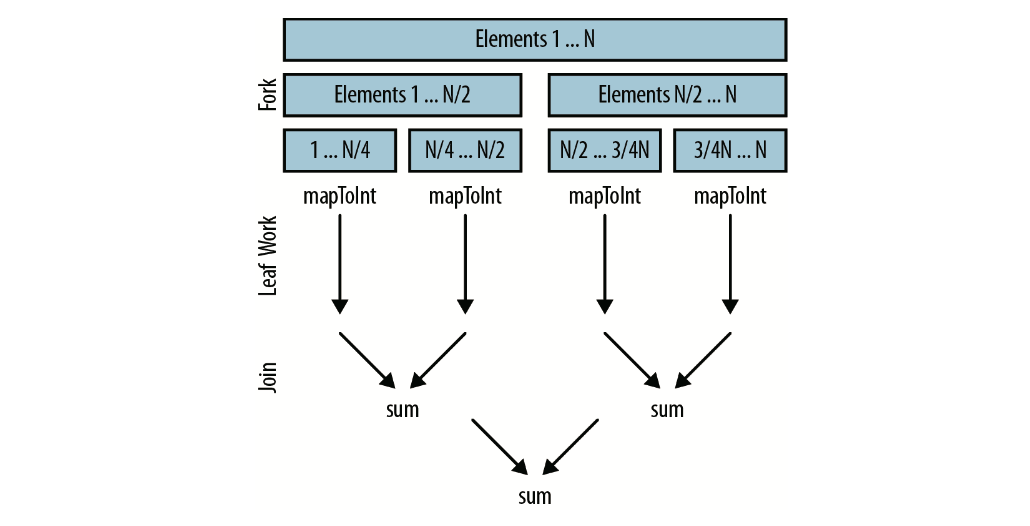
书中描述了在底层,并行流沿用了fork/join框架(其实我理解不了)。fork递归式地分解问题,然后每段并行执行,最终由join合并结果,返回最后的值(书中画了一个图)。
将核心类库提供的通用数据结构分成以下三组:
性能好:ArrayList、数组或 IntStream.range,这些数据结构支持随机读取,也就是说它们能轻 而易举地被任意分解。
性能一般:HashSet、TreeSet,这些数据结构不易公平地被分解,但是大多数时候分解是可能的。
性能差:有些数据结构难于分解,比如,可能要花 O(N) 的时间复杂度来分解问题。其中包括 LinkedList,对半分解太难了。还有 Streams.iterate 和 BufferedReader.lines,它们 长度未知,因此很难预测该在哪里分解。
一入Stream有点迷惘,具体这个性能怎么样,还要继续摸索。
数据并行化是指将数据分成块,为每块数据分配单独的处理单元。《java8函数式编程》书中拿马拉车那个例子打比方,就像从车里取出一些货物,放到另一辆车上,两辆马车都沿着同样的路径到达目的地,书中画的图也是很容易理解,后面也copy了不少原句。
当需要在大量数据上执行同样的操作时,数据并行化很管用。它将问题分解为可在多块数 据上求解的形式,然后对每块数据执行运算,最后将各数据块上得到的结果汇总,从而获 得最终答案。这个描述还有点像分治法,或者归并排序。
如果已经有一个 Stream 对象,调用它的 parallel 方法就能让其拥有并行操作的能力。如果想从一个集合类创建一个流,调用 parallelStream 就能立即获得一个拥有并行能力的流,使用起来很简单,只要改动一个方法,其他都是一样的,不必理会串行还是并行,只要告诉程序怎么做就行了,毕竟告诉计算机做什么和怎么做是两回事。
并发化数组操作
但是有人会问串行和并行哪一个快?这就要看具体的环境要求了,主要影响因素如下:
数据大小:只有数据足够大、每个数据处理管道花费的时间足够多 时,并行化处理才有意义。
源数据结构:每个管道的操作都基于一些初始数据源,通常是集合。
装箱 处理基本类型比处理装箱类型要快。
核的数量:在实践中,核的数量不单指你的机器上有多少核,更是指运行时 你的机器能使用多少核。这也就是说同时运行的其他进程,或者线程关联性(强制线程 在某些核或 CPU 上运行)会影响性能。
单元处理开销:花在流中 每个元素身上的时间越长,并行操作带来的性能提升越明显。
书中描述了在底层,并行流沿用了fork/join框架(其实我理解不了)。fork递归式地分解问题,然后每段并行执行,最终由join合并结果,返回最后的值(书中画了一个图)。
将核心类库提供的通用数据结构分成以下三组:
性能好:ArrayList、数组或 IntStream.range,这些数据结构支持随机读取,也就是说它们能轻 而易举地被任意分解。
性能一般:HashSet、TreeSet,这些数据结构不易公平地被分解,但是大多数时候分解是可能的。
性能差:有些数据结构难于分解,比如,可能要花 O(N) 的时间复杂度来分解问题。其中包括 LinkedList,对半分解太难了。还有 Streams.iterate 和 BufferedReader.lines,它们 长度未知,因此很难预测该在哪里分解。
一入Stream有点迷惘,具体这个性能怎么样,还要继续摸索。

相关文章推荐
- <JavaScript语言精粹>--<读书笔记三>之replace()与正则
- 动态规划入门<三>
- C语言程序设计<三>
- django框架<三>
- UnityEditor<三>自定义窗口 案例1
- springMVC+mybatis+spring security<三>:使用数据库管理资源
- 【Android自定义控件】Android自定义虚线<三>
- git使用<三>:新建空白分支
- 好记性不如烂笔杆-android学习笔记<三> RadioGroup 和 CheckBox的使用
- Ulua热更新提高 <三> 网络通信和ProtocolBuffer
- 工作总结日志<三> 数控系统RTLinux内核上几个系统类型和函数在RTAI内核上的对应
- silverlight学习<三> 记录今天silverlight调用WCF服务出现的各种状况
- Linux的使用<三> ubuntu16.04LTS安装Wine
- java8函数式编程常用收集器<二>
- Java 嵌套类和内部类示例<三>
- 在阿里云centOs上部署项目环境<三>
- dex2jar源码解析----解析dex文件<三>
- Python入门<三>
- Linq学习<三> linq to entity
- elasticsearch 学习博客系列<三> ES 中 index-doc 的 添加(java)