5分钟入门网络爬虫 - 原来可以这么简单易懂
2017-11-16 04:55
816 查看
爬虫在大数据时代占据了重要的位置,在网上有大量的公开数据可以轻松获取。
爬虫入门其实非常简单,就算你是编程小白,也可以轻松爬下一些网站。下面就以爬取笔者的个人博客网站(大数据分析@唐松)为例,教大家学会一个简单的爬虫。。一方面,由于这个网站的设计和框架不会更改,因此本书的网络爬虫代码可以一直使用; 另一方面,由于这个网站由笔者拥有,因此避免了一些法律上的风险。
如果你有已经安装了python3,pip,可以跳过下面对python,pip安装的介绍。
第二步:安装pip,pip是按照python各种包的工具,有了它安装python的各种包都很方便。如果你安装了 Anaconda,那么恭喜你,它已经自带了 pip 不用单独安装了。
如果不使用 Anaconda 安装 Python,需要单独装 pip,可以借鉴这篇文章:https://www.tuicool.com/articles/eiM3Er3/
第三步:有了pip,就可以安装beautifulsoup了。这个包可以很好地从网页代码中提取想要的数据。安装方法: 在 terminal (MacOS) 或是 cmd (Windows)中键入
第四步:选一个python编译器来跑程序。为了代码的调试方便,可以直接用 Anaconda 中的 jupyter。使用方法:在 terminal (MacOS) 或是 cmd (Windows)中键入
上述代码获取了博客首页的网页HTML代码。首先import requests,使用requests.get(link, headers=headers)获取了网页。值得注意的是:
用requests的headers可以伪装成浏览器访问
r是requests的Response回复对象,我们从中可以获取我们想要的信息。r.text是获取的网页内容代码。
运行完上述代码后,我们得到的结果是:

在获取到整个页面的HTML代码后,我们需要从整个网页中提取第一篇文章的标题。
这里用到beautifulsoup这个库了对爬下来的页面进行解析,首先我们需要导入这个库,from bs4 import BeautifulSoup。然后,把HTML代码转化为soup对象,接下来就是用soup.find(“h1”,class_=”post-title”).a.text.strip(),得到第一篇文章的标题,并且打印出来。
对初学者来说,beautifulsoup从网页中提取需要的数据,更加简单易用。
那么,我们是怎么从那么长的代码中准确找到标题的位置呢?
这里就要隆重介绍Chrome浏览器的“检查(审查元素)”功能了。下面介绍一下找到需要元素的步骤:
步骤一:使用Chrome浏览器,打开博客首页http://www.santostang.com。右键网页页面,在弹出的对话框中,点击“检查”选项。
步骤二:出现如下图所示的审查元素功能。点击左上角的鼠标键,然后在页面上点击想要的数据,下面的Elements就会出现相应的code所在的地方,就定位到你想要的元素了。
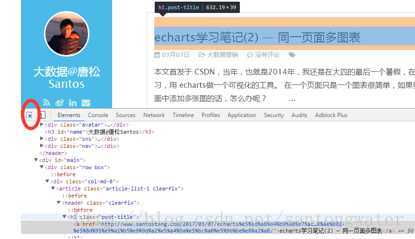
步骤三:在代码中找到标蓝色的地方,为”h1 class=”post-title”> a>echarts学习笔记(2) – 同一页面多图表/a>”。于是,我们可以用soup.find(“h1”,class_=”post-title”).a.text.strip()提取出该博文的标题了。
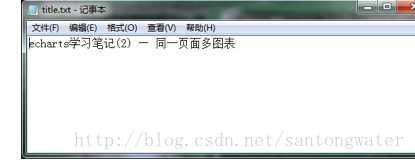
储存到本地的txt文件也非常简单,在第二步的基础上,加上三行代码,就可以把这个字符串,保存在text里,并存到本地。txt文件地址应该和你的python文件在同一文件夹。
返回文件夹中,打开’
4000
title.txt’文件,可以看到里面的内容,如下图所示:
本书主要分为三部分:基础部分(第1~6章)、进阶部分(第7~12章)和项目实践部分(第13~16章),以此来针对不同类型的读者。如果你是Python爬虫的初学者,那么可以先学习基础部分,这部分每一章的最后都有自我实践题,读者可以通过实践题熟悉编写Python爬虫代码。如果你已经对Python爬虫有所了解,但是在实践中遇到了各种问题,那么可以直接学习进阶部分,这部分为你在爬虫实践中遇到的问题提供了解决方案。本书最后的项目实践部分是让你在学习Python爬虫后,可以通过在真实网站中练习来消化和吸收Python爬虫的知识。
这本书相对网络上的学习比较系统化,希望大家能支持!
京东链接:《Python网络爬虫从入门到实践》(唐松,陈智铨)【摘要 书评 试读】- 京东图书
当当链接:《Python网络爬虫从入门到实践》(唐松 陈智铨)【简介书评在线阅读】 - 当当图书
爬虫入门其实非常简单,就算你是编程小白,也可以轻松爬下一些网站。下面就以爬取笔者的个人博客网站(大数据分析@唐松)为例,教大家学会一个简单的爬虫。。一方面,由于这个网站的设计和框架不会更改,因此本书的网络爬虫代码可以一直使用; 另一方面,由于这个网站由笔者拥有,因此避免了一些法律上的风险。
如果你有已经安装了python3,pip,可以跳过下面对python,pip安装的介绍。
安装python3, pip, beautifulsoup
第一步:Python3安装,请自行百度 Anaconda。这里推荐使用 Anaconda 的 Python 科学计算环境。只需像普通软件一样安装好 Anaconda,就可以把 Python 的环境变量、解释器、开发环境等安装在计算机中。第二步:安装pip,pip是按照python各种包的工具,有了它安装python的各种包都很方便。如果你安装了 Anaconda,那么恭喜你,它已经自带了 pip 不用单独安装了。
如果不使用 Anaconda 安装 Python,需要单独装 pip,可以借鉴这篇文章:https://www.tuicool.com/articles/eiM3Er3/
第三步:有了pip,就可以安装beautifulsoup了。这个包可以很好地从网页代码中提取想要的数据。安装方法: 在 terminal (MacOS) 或是 cmd (Windows)中键入
pip install bs4
第四步:选一个python编译器来跑程序。为了代码的调试方便,可以直接用 Anaconda 中的 jupyter。使用方法:在 terminal (MacOS) 或是 cmd (Windows)中键入
jupyter notebook
第一步:获取页面
#!/usr/bin/python
# coding: utf-8
import requests
link = "http://www.santostang.com/"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers
print (r.text)上述代码获取了博客首页的网页HTML代码。首先import requests,使用requests.get(link, headers=headers)获取了网页。值得注意的是:
用requests的headers可以伪装成浏览器访问
r是requests的Response回复对象,我们从中可以获取我们想要的信息。r.text是获取的网页内容代码。
运行完上述代码后,我们得到的结果是:
第二步:提取需要的数据
#!/usr/bin/python
# coding: utf-8
import requests
from bs4 import BeautifulSoup #从bs4这个库中导入BeautifulSoup
link = "http://www.santostang.com/"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
soup = BeautifulSoup(r.text, "lxml") #使用BeautifulSoup解析这段代码
title = soup.find("h1", class_="post-title").a.text.strip()
print (title)在获取到整个页面的HTML代码后,我们需要从整个网页中提取第一篇文章的标题。
这里用到beautifulsoup这个库了对爬下来的页面进行解析,首先我们需要导入这个库,from bs4 import BeautifulSoup。然后,把HTML代码转化为soup对象,接下来就是用soup.find(“h1”,class_=”post-title”).a.text.strip(),得到第一篇文章的标题,并且打印出来。
对初学者来说,beautifulsoup从网页中提取需要的数据,更加简单易用。
那么,我们是怎么从那么长的代码中准确找到标题的位置呢?
这里就要隆重介绍Chrome浏览器的“检查(审查元素)”功能了。下面介绍一下找到需要元素的步骤:
步骤一:使用Chrome浏览器,打开博客首页http://www.santostang.com。右键网页页面,在弹出的对话框中,点击“检查”选项。
步骤二:出现如下图所示的审查元素功能。点击左上角的鼠标键,然后在页面上点击想要的数据,下面的Elements就会出现相应的code所在的地方,就定位到你想要的元素了。
步骤三:在代码中找到标蓝色的地方,为”h1 class=”post-title”> a>echarts学习笔记(2) – 同一页面多图表/a>”。于是,我们可以用soup.find(“h1”,class_=”post-title”).a.text.strip()提取出该博文的标题了。
第三步:储存数据
import requests
from bs4 import BeautifulSoup #从bs4这个库中导入BeautifulSoup
link = "http://www.santostang.com/"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
soup = BeautifulSoup(r.text, "lxml") #使用BeautifulSoup解析这段代码
title = soup.find("h1", class_="post-title").a.text.strip()
print (title)
with open('title.txt', "a+") as f:
f.write(title)
f.close()储存到本地的txt文件也非常简单,在第二步的基础上,加上三行代码,就可以把这个字符串,保存在text里,并存到本地。txt文件地址应该和你的python文件在同一文件夹。
返回文件夹中,打开’
4000
title.txt’文件,可以看到里面的内容,如下图所示:
一波硬广:
本文节选自图书《Python 网络爬虫:从入门到实践》第二章:编写你的第一个爬虫,由机械工业出版社出版。本书主要分为三部分:基础部分(第1~6章)、进阶部分(第7~12章)和项目实践部分(第13~16章),以此来针对不同类型的读者。如果你是Python爬虫的初学者,那么可以先学习基础部分,这部分每一章的最后都有自我实践题,读者可以通过实践题熟悉编写Python爬虫代码。如果你已经对Python爬虫有所了解,但是在实践中遇到了各种问题,那么可以直接学习进阶部分,这部分为你在爬虫实践中遇到的问题提供了解决方案。本书最后的项目实践部分是让你在学习Python爬虫后,可以通过在真实网站中练习来消化和吸收Python爬虫的知识。
这本书相对网络上的学习比较系统化,希望大家能支持!
京东链接:《Python网络爬虫从入门到实践》(唐松,陈智铨)【摘要 书评 试读】- 京东图书
当当链接:《Python网络爬虫从入门到实践》(唐松 陈智铨)【简介书评在线阅读】 - 当当图书

相关文章推荐
- JAVA中BCD码的转化问题:原来可以这么简单
- JSON解析的成长史——原来还可以这么简单
- 实体类的枚举属性--原来支持枚举类型这么简单,没有EF5.0也可以
- ASP.NET MVC3 + Ninject.Mvc3 依赖注入原来可以这么简单
- JSON解析的成长史——原来还可以这么简单
- TaskHosting - 开发桌面工具原来还可以这么简单
- 厉害了黑科技,动态安全下的防拖库原来可以这么简单!
- 动态安全下的防***原来可以这么简单!
- JPA + SpringData 操作数据库原来可以这么简单 ---- 深入了解 JPA - 1
- (原来可以这么简单)实现变色TextView及ViewPager指示器(二)
- 原来这么简单就可以申请Blog了,害我还自己做了一个~
- xmake入门,构建项目原来可以如此简单
- 最新开源DBLayer,原来数据库操作可以这么简单
- ASP.NET MVC3 + Ninject.Mvc3 依赖注入原来可以这么简单
- 深度寻路算法,原来算法可以这么简单的理解学习?!
- 原来幸福可以这么简单
- Java实现的网络爬虫程序,简单易懂无框架(我的网络大作业)
- 实现变色TextView及ViewPager指示器(原来可以这么简单)
- JPA + SpringData 操作数据库原来可以这么简单 ---- 深入了解 JPA - 3
- 利用.NET做“电子书阅读器”原来这么简单(其实你也可以做出金山词霸)