xpath入门教程
2017-11-15 14:29
211 查看
大部分程序开发者应该都有过爬取网页的经历,每个人爬取的方法也不太相同,有的用强大的正则表达式,有的用selector,有的也会用第三方提供的插件等等。每种方法都有各自的优缺点,比如正则的抓取效率问题但是通用性强,selector上手难度,插件类比如simple_dom_php抓取不到直接error退出进程问题等等。这里不做过多评价,只介绍一个好用的、强大的、易上手的抓取工具xpath。
什么是xpath
一句话,XPath 是一门在 XML 文档中查找信息的语言。简单来说,html类似于xml结构,但是没有xml格式那么严格。
十分钟入门xpath
入门用法,如何抓取百度首页图片链接
使用谷歌浏览器获取需要抓取元素的xpath路径
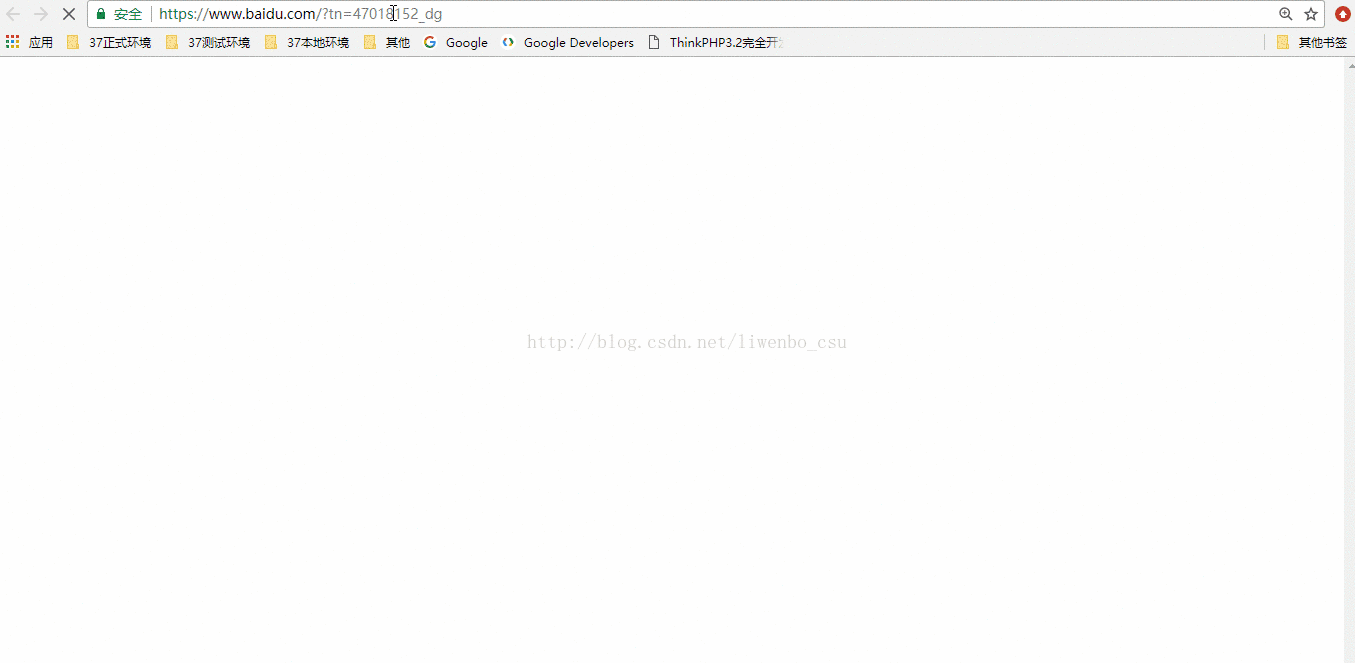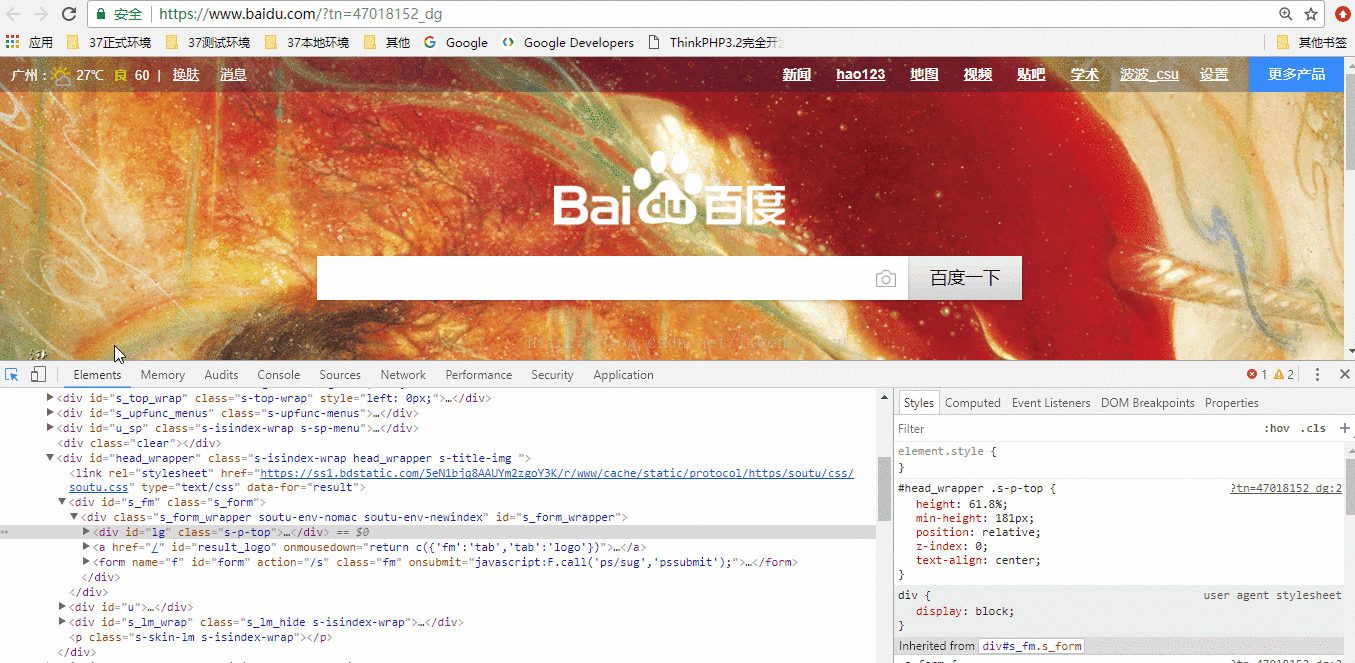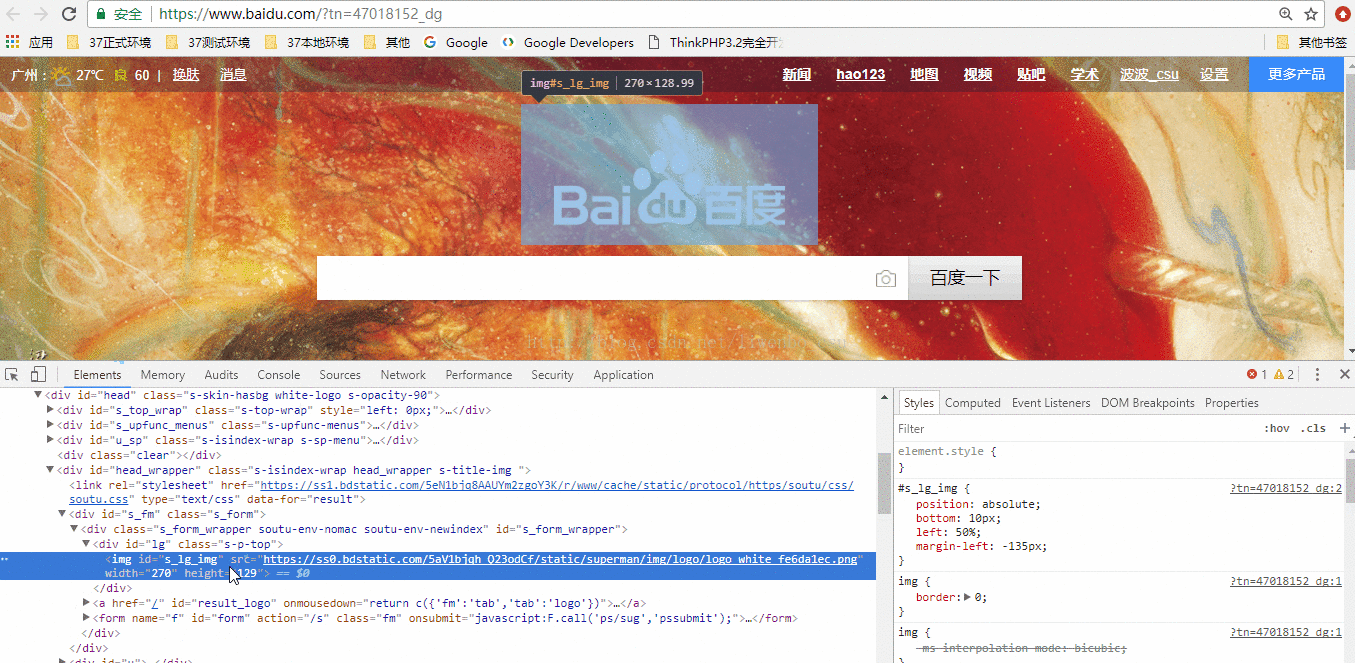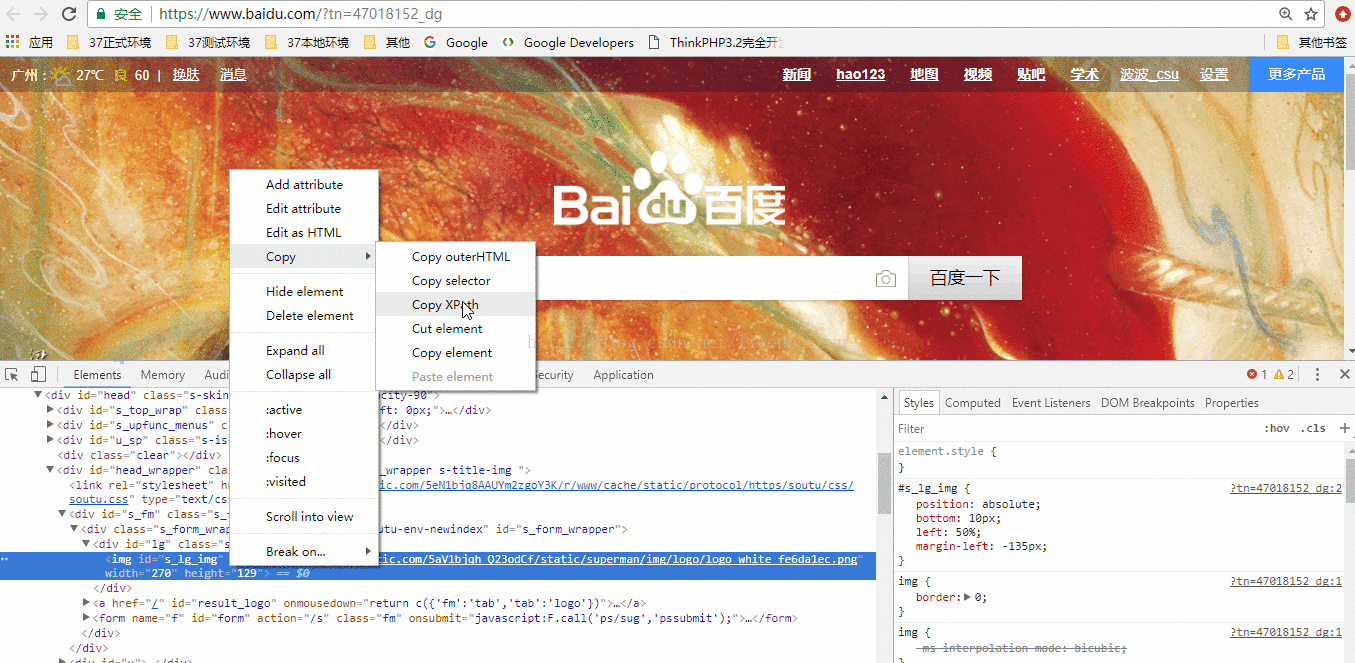
把自动生成的路径拷贝到代码中(ps:这里把网页代码保存在了本地!)
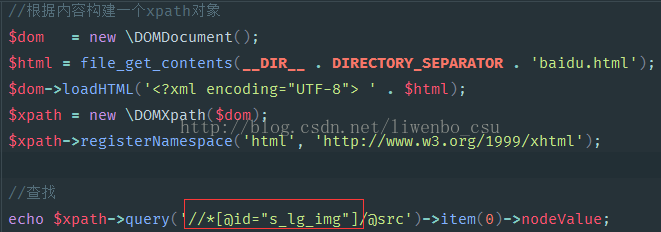
运行查看结果

第二步:掌握基本语法,xpath语法类似于路径选择,非常容易上手
以下图html举例如何获取不同的节点:
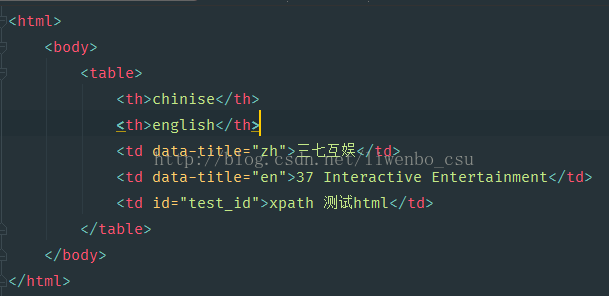
方法一:根据路径获取节点信息
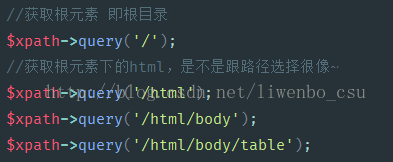
方法二:根据属性值快速选取节点

掌握以上几种常用法,基本上就可以快速开发一个页面的抓取功能了,是不是非常简单,赶紧自己动手试试吧。更深入的用法无非是在上面基础上加了一些函数操作,具体可以搜索xpath教程,这里只做入门,不再深入介绍。
性能如何?
这里我使用上述html建立了以下基准进行测试:
1、使用PHP语言 (php版本5.4.41)
2、选取相同网页,约20W字符 (www.baidu.com)
3、各抓取一千次 (循环一千次,抓取所有img标签的图片地址)
分别用正则和xpath进行抓取,比较处理时间。
首先定义两个抓取方法:
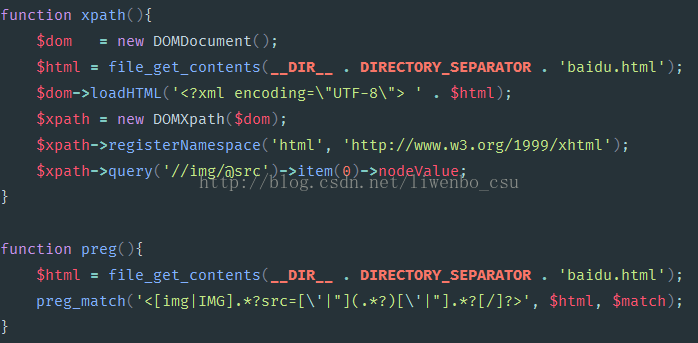
循环调用一千次,得出结论:本次测试,xpath爬取可以做到秒级;正则是分钟级别
说明:上述测试基准可能不太明确,但是差异较大已经足够得到我们需要的对比结果。
总结一下:
XPath的优势在于它的速度,这是因为它把html以树形的结构进行存储,在你通过层级关系查找节点的时候,并不需要对所有字符串进行遍历,它的底层是通过libxml构建一棵DOM树实现的查找。
XPath其实并不容易掌握(ps:我的意思是要深入掌握),它的语法和函数都非常多,学习起来成本也比较高,但是在普通的抓取业务中,只需要掌握一些基本的就足够了。
XPath的语法和规则跟语言是无关的。
这里只讨论了xpath对单个网页的爬取新的基本方法,帮助开发人员快速抓取网页中的信息。因为简单快速,适用范围必然比不上强大的正则表达式,可以根据各自的应用场景选择。
什么是xpath
一句话,XPath 是一门在 XML 文档中查找信息的语言。简单来说,html类似于xml结构,但是没有xml格式那么严格。
十分钟入门xpath
入门用法,如何抓取百度首页图片链接
使用谷歌浏览器获取需要抓取元素的xpath路径
把自动生成的路径拷贝到代码中(ps:这里把网页代码保存在了本地!)
运行查看结果
第二步:掌握基本语法,xpath语法类似于路径选择,非常容易上手
以下图html举例如何获取不同的节点:
方法一:根据路径获取节点信息
方法二:根据属性值快速选取节点
掌握以上几种常用法,基本上就可以快速开发一个页面的抓取功能了,是不是非常简单,赶紧自己动手试试吧。更深入的用法无非是在上面基础上加了一些函数操作,具体可以搜索xpath教程,这里只做入门,不再深入介绍。
性能如何?
这里我使用上述html建立了以下基准进行测试:
1、使用PHP语言 (php版本5.4.41)
2、选取相同网页,约20W字符 (www.baidu.com)
3、各抓取一千次 (循环一千次,抓取所有img标签的图片地址)
分别用正则和xpath进行抓取,比较处理时间。
首先定义两个抓取方法:
循环调用一千次,得出结论:本次测试,xpath爬取可以做到秒级;正则是分钟级别
说明:上述测试基准可能不太明确,但是差异较大已经足够得到我们需要的对比结果。
总结一下:
XPath的优势在于它的速度,这是因为它把html以树形的结构进行存储,在你通过层级关系查找节点的时候,并不需要对所有字符串进行遍历,它的底层是通过libxml构建一棵DOM树实现的查找。
XPath其实并不容易掌握(ps:我的意思是要深入掌握),它的语法和函数都非常多,学习起来成本也比较高,但是在普通的抓取业务中,只需要掌握一些基本的就足够了。
XPath的语法和规则跟语言是无关的。
这里只讨论了xpath对单个网页的爬取新的基本方法,帮助开发人员快速抓取网页中的信息。因为简单快速,适用范围必然比不上强大的正则表达式,可以根据各自的应用场景选择。

相关文章推荐
- python爬虫入门(4)-补充知识:XPath 教程(转自w3school)
- XPath 初学者入门教程:XPath 语法
- XPath入门 - XSL教程 - 3
- XPath入门教程
- XPath入门教程
- Ant入门教程
- Systemd 入门教程:实战篇
- 无废话ExtJs 入门教程十三[上传图片:File]
- [译] THREE.JS入门教程-3.着色器-下
- Zend Framework开发入门经典教程
- 快速学习MySQL索引的入门超级教程
- ExtJs 入门教程二[Hello World]
- [Umbraco] 入门教程(转)
- SpringMVC入门示例教程(一)
- iBATIS SQL Maps入门教程
- JMS(Java消息服务)入门教程
- SQLite 入门教程(四)增删改查,有讲究
- Velocity快速入门教程
- ionic入门教程第三课-在项目中使用requirejs分离controller文件和server文件
- ExtJs 入门教程二十[数据交互:AJAX]