深度学习界明星:生成对抗网络与Improving GAN
2017-11-15 00:00
459 查看
2014年,深度学习三巨头之一IanGoodfellow提出了生成对抗网络(Generative Adversarial Networks, GANs)这一概念,刚开始并没有引起轰动,直到2016年,学界、业界对它的兴趣如“井喷”一样爆发,多篇重磅文章陆续发表。2016年12月NIPS大会上,Goodfellow做了关于GANs的专题报告,使得GANs成为了当今最热门的研究领域之一,本文将介绍如今深度学习界的明星——生成对抗网络。
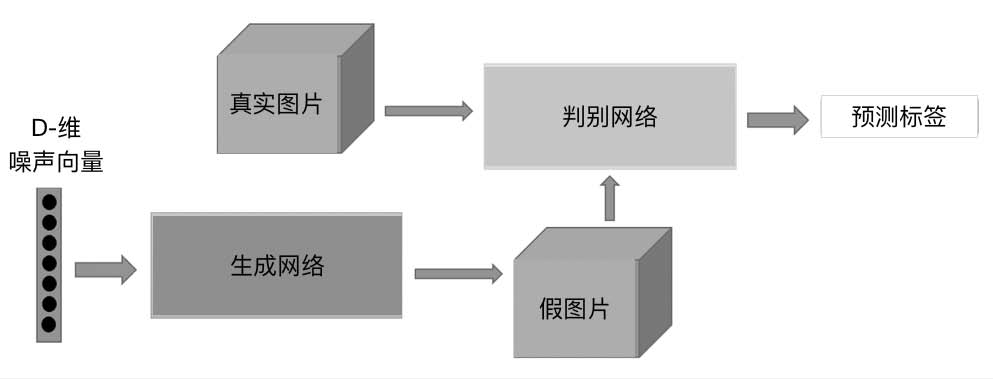
图1 生成对抗网络生成数据过程
下面依次介绍生成模型和对抗模型。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
在生成对抗网络中,不再是将图片输入编码器得到隐含向量然后生成图片,而是随机初始化一个隐含向量,根据变分自动编码器的特点,初始化一个正态分布的隐含向量,通过类似解码的过程,将它映射到一个更高的维度,最后生成一个与输入数据相似的数据,这就是假的图片。这时自动编码器是通过对比两张图片之间每个像素点的差异计算损失函数的,而生成对抗网络会通过对抗过程来计算出这个损失函数,如图2所示。
图2 生成模型
对抗过程简单来说就是一个判断真假的判别器,相当于一个二分类问题,输入一张真的图片希望判别器输出的结果是1,输入一张假的图片希望判别器输出的结果是0。
这跟原图片的label 没有关系,不管原图片到底是一个多少类别的图片,它们都统一称为真的图片,输出的label 是1,则表示是真实的;而生成图片的label 是0,则表示是假的。
在训练的时候,先训练判别器,将假的数据和真的数据都输入给判别模型,这个时候优化这个判别模型,希望它能够正确地判断出真的数据和假的数据,这样就能够得到一个比较好的判别器。
然后开始训练生成器,希望它生成的假的数据能够骗过现在这个比较好的判别器。
具体做法就是将判别器的参数固定,通过反向传播优化生成器的参数,希望生成器得到的数据在经过判别器之后得到的结果能尽可能地接近1,这时只需要调整一下损失函数就可以了,之前在优化判别器的时候损失函数是让假的数据尽可能接近0,而现在训练生成器的损失函数是让假的数据尽可能接近1。
这其实就是一个简单的二分类问题,这个问题可以用前面介绍过的很多方法去处理,比如Logistic 回归、多层感知器、卷积神经网络、循环神经网络等。
上面是生成对抗网络的简单解释,可以通过代码更清晰地展示整个过程。
跟自动编码器一样,先使用简单的多层感知器来实现:
上面是判别器的结构,中间使用了斜率设为0.2 的LeakyReLU 激活函数,最后需要使用nn.Sigmoid() 将结果映射到0 s 1 之间概率进行真假的二分类。这里之所以用LeakyReLU 激活函数而不使用ReLU 激活函数,是因为经过实验,LeakyReLU 的表现更好。
这就是生成器的结构,跟自动编码器中的解码器是类似的,最后需要使用nn.Tanh(),将数据分布到-1 ~1 之间,这是因为输入的图片会规范化到-1 ~1之间。
接着需要定义损失函数和优化函数:
这里使用二分类的损失函数nn.BCELoss(),使用Adam 优化函数,学习率设置为0.0003。
接着是最为重要的训练过程,这个过程分为两个部分:一个是判别器的训练,一个是生成器的训练。
首先来看看判别器的训练。
开始需要自己创建label,真实的数据是1,生成的假的数据是0,然后将真实的数据输入判别器得到loss,将假的数据输入判别器得到loss,将这两个loss 加起来得到总的loss,然后反向传播去更新参数就能够得到一个优化好的判别器。
接下来是生成模型的训练:
一个随机隐含向量通过生成网络得到了一个假的数据,然后希望假的数据经过判别模型后尽可能和真实label 接近,通过g_loss = criterion(output, real_label)实现,然后反向传播去优化生成器的参数,在这个过程中,判别器的参数不再发生变化,否则生成器永远无法骗过优化的判别器。
除了使用简单的多层感知器外,也可以在生成模型和对抗模型中使用更加复杂的卷积神经网络,定义十分简单。
图3 左边是多层感知器的生成对抗网络,右边是卷积生成对抗网络,右边的图片比左边的图片噪声明显更少。在卷积神经网络里引入了批标准化(Batchnormalization)来稳定训练,同时使用了LeakyReLU 和平均池化来进行训练。生成对抗网络的训练其实是很困难的,因为这是两个对偶网络在相互学习,所以需要增加一些训练技巧才能使训练更加稳定。

图3生成对抗网络对比结果
以上介绍了生成对抗网络的简单原理和训练流程,但是对生成对抗网络而言,它其实并没有真正地学习到它要表示的物体,通过对抗的过程,它只是生成了一张尽可能真的图片,这就意味着没办法决定用哪种噪声能够生成想要的图片,除非把初始分布都试一遍。所以在生成对抗网络提出之后,有很多基于标准生成对抗网络的变式来解决各种各样的问题。
原文链接
1何为生成对抗网络
生成对抗网络,根据它的名字,可以推断这个网络由两部分组成:第一部分是生成,第二部分是对抗。这个网络的第一部分是生成模型,就像之前介绍的自动编码器的解码部分;第二部分是对抗模型,严格来说它是一个判断真假图片的判别器。生成对抗网络最大的创新在此,这也是生成对抗网络与自动编码器最大的区别。简单来说,生成对抗网络就是让两个网络相互竞争,通过生成网络来生成假的数据,对抗网络通过判别器判别真伪,最后希望生成网络生成的数据能够以假乱真骗过判别器。过程如图1所示。图1 生成对抗网络生成数据过程
下面依次介绍生成模型和对抗模型。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
1. 生成模型
首先看看生成模型,前一节自动编码器其实已经给出了一般的生成模型。在生成对抗网络中,不再是将图片输入编码器得到隐含向量然后生成图片,而是随机初始化一个隐含向量,根据变分自动编码器的特点,初始化一个正态分布的隐含向量,通过类似解码的过程,将它映射到一个更高的维度,最后生成一个与输入数据相似的数据,这就是假的图片。这时自动编码器是通过对比两张图片之间每个像素点的差异计算损失函数的,而生成对抗网络会通过对抗过程来计算出这个损失函数,如图2所示。
图2 生成模型
2. 对抗模型
重点来介绍对抗过程,这个过程是生成对抗网络相对于之前的生成模型如自动编码器等最大的创新。对抗过程简单来说就是一个判断真假的判别器,相当于一个二分类问题,输入一张真的图片希望判别器输出的结果是1,输入一张假的图片希望判别器输出的结果是0。
这跟原图片的label 没有关系,不管原图片到底是一个多少类别的图片,它们都统一称为真的图片,输出的label 是1,则表示是真实的;而生成图片的label 是0,则表示是假的。
在训练的时候,先训练判别器,将假的数据和真的数据都输入给判别模型,这个时候优化这个判别模型,希望它能够正确地判断出真的数据和假的数据,这样就能够得到一个比较好的判别器。
然后开始训练生成器,希望它生成的假的数据能够骗过现在这个比较好的判别器。
具体做法就是将判别器的参数固定,通过反向传播优化生成器的参数,希望生成器得到的数据在经过判别器之后得到的结果能尽可能地接近1,这时只需要调整一下损失函数就可以了,之前在优化判别器的时候损失函数是让假的数据尽可能接近0,而现在训练生成器的损失函数是让假的数据尽可能接近1。
这其实就是一个简单的二分类问题,这个问题可以用前面介绍过的很多方法去处理,比如Logistic 回归、多层感知器、卷积神经网络、循环神经网络等。
上面是生成对抗网络的简单解释,可以通过代码更清晰地展示整个过程。
跟自动编码器一样,先使用简单的多层感知器来实现:
class discriminator(nn.Module): def __init__(self): super(discriminator, self).__init__() self.dis = nn.Sequential( nn.Linear(784, 256), nn.LeakyReLU(0.2), nn.Linear(256, 256), nn.LeakyReLU(0.2), nn.Linear(256, 1), nn.Sigmoid() ) def forward(self, x): x = self.dis(x) return x
上面是判别器的结构,中间使用了斜率设为0.2 的LeakyReLU 激活函数,最后需要使用nn.Sigmoid() 将结果映射到0 s 1 之间概率进行真假的二分类。这里之所以用LeakyReLU 激活函数而不使用ReLU 激活函数,是因为经过实验,LeakyReLU 的表现更好。
class generator(nn.Module): def __init__(self, input_size): super(generator, self).__init__() self.gen = nn.Sequential( nn.Linear(input_size, 256), nn.ReLU(True), nn.Linear(256, 256), nn.ReLU(True), nn.Linear(256, 784), nn.Tanh() ) def forward(self, x): x = self.gen(x) return x
这就是生成器的结构,跟自动编码器中的解码器是类似的,最后需要使用nn.Tanh(),将数据分布到-1 ~1 之间,这是因为输入的图片会规范化到-1 ~1之间。
接着需要定义损失函数和优化函数:
criterion = nn.BCELoss() # Binary Cross Entropy d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003) g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
这里使用二分类的损失函数nn.BCELoss(),使用Adam 优化函数,学习率设置为0.0003。
接着是最为重要的训练过程,这个过程分为两个部分:一个是判别器的训练,一个是生成器的训练。
首先来看看判别器的训练。
img = img.view(num_img, -1) real_img = Variable(img).cuda() real_label = Variable(torch.ones(num_img)).cuda() fake_label = Variable(torch.zeros(num_img)).cuda() # compute loss of real_img real_out = D(real_img) d_loss_real = criterion(real_out, real_label) real_scores = real_out # compute loss of fake_img z = Variable(torch.randn(num_img, z_dimension)).cuda() fake_img = G(z) fake_out = D(fake_img) d_loss_fake = criterion(fake_out, fake_label) fake_scores = fake_out # bp and optimize d_loss = d_loss_real + d_loss_fake d_optimizer.zero_grad() d_loss.backward() d_optimizer.step()
开始需要自己创建label,真实的数据是1,生成的假的数据是0,然后将真实的数据输入判别器得到loss,将假的数据输入判别器得到loss,将这两个loss 加起来得到总的loss,然后反向传播去更新参数就能够得到一个优化好的判别器。
接下来是生成模型的训练:
# compute loss of fake_img z = Variable(torch.randn(num_img, z_dimension)).cuda() # 得到随机噪声 fake_img = G(z) # 生成假的图片 output = D(fake_img) # 经过判别器得到结果 g_loss = criterion(output, real_label) # 得到假的图片与真实图片label的loss # bp and optimize g_optimizer.zero_grad() # 归0梯度 g_loss.backward() # 反向传播 g_optimizer.step() # 更新生成网络的参数
一个随机隐含向量通过生成网络得到了一个假的数据,然后希望假的数据经过判别模型后尽可能和真实label 接近,通过g_loss = criterion(output, real_label)实现,然后反向传播去优化生成器的参数,在这个过程中,判别器的参数不再发生变化,否则生成器永远无法骗过优化的判别器。
除了使用简单的多层感知器外,也可以在生成模型和对抗模型中使用更加复杂的卷积神经网络,定义十分简单。
class discriminator(nn.Module): def __init__(self): super(discriminator, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(1, 32, 5, padding=2), # batch, 32, 28, 28 nn.LeakyReLU(0.2, True), nn.AvgPool2d(2, stride=2), # batch, 32, 14, 14 ) self.conv2 = nn.Sequential( nn.Conv2d(32, 64, 5, padding=2), # batch, 64, 14, 14 nn.LeakyReLU(0.2, True), nn.AvgPool2d(2, stride=2) # batch, 64, 7, 7 ) self.fc = nn.Sequential( nn.Linear(6477, 1024), nn.LeakyReLU(0.2, True), nn.Linear(1024, 1), nn.Sigmoid() ) def forward(self, x): ''' x: batch, width, height, channel=1 ''' x = self.conv1(x) x = self.conv2(x) x = x.view(x.size(0), -1) x = self.fc(x) return x class generator(nn.Module): def __init__(self, input_size, num_feature): super(generator, self).__init__() self.fc = nn.Linear(input_size, num_feature) # batch, 3136=1x56x56 self.br = nn.Sequential( nn.BatchNorm2d(1), nn.ReLU(True) ) self.downsample1 = nn.Sequential( nn.Conv2d(1, 50, 3, stride=1, padding=1), # batch, 50, 56, 56 nn.BatchNorm2d(50), nn.ReLU(True) ) self.downsample2 = nn.Sequential( nn.Conv2d(50, 25, 3, stride=1, padding=1), # batch, 25, 56, 56 nn.BatchNorm2d(25), nn.ReLU(True) ) self.downsample3 = nn.Sequential( nn.Conv2d(25, 1, 2, stride=2), # batch, 1, 28, 28 nn.Tanh() ) def forward(self, x): x = self.fc(x) x = x.view(x.size(0), 1, 56, 56) x = self.br(x) x = self.downsample1(x) x = self.downsample2(x) x = self.downsample3(x) return x
图3 左边是多层感知器的生成对抗网络,右边是卷积生成对抗网络,右边的图片比左边的图片噪声明显更少。在卷积神经网络里引入了批标准化(Batchnormalization)来稳定训练,同时使用了LeakyReLU 和平均池化来进行训练。生成对抗网络的训练其实是很困难的,因为这是两个对偶网络在相互学习,所以需要增加一些训练技巧才能使训练更加稳定。
图3生成对抗网络对比结果
以上介绍了生成对抗网络的简单原理和训练流程,但是对生成对抗网络而言,它其实并没有真正地学习到它要表示的物体,通过对抗的过程,它只是生成了一张尽可能真的图片,这就意味着没办法决定用哪种噪声能够生成想要的图片,除非把初始分布都试一遍。所以在生成对抗网络提出之后,有很多基于标准生成对抗网络的变式来解决各种各样的问题。
原文链接

相关文章推荐
- 深度学习界明星:生成对抗网络与Improving GAN
- 【深度学习理论】通俗理解生成对抗网络GAN
- Nikolai Yakovenko大佬:深度学习的下一个热点:生成对抗网络(GANs)将改变世界
- 【备忘】2017年深度学习项目实战之对抗生成网络视频课程
- 深度学习笔记九:生成对抗网络GAN(基本理论)
- 【深度学习】生成对抗网络Generative Adversarial Nets
- 深度学习笔记一:生成对抗网络(Generative Adversarial Nets)
- 深度学习之生成对抗网络GAN
- 生成对抗网络入门详解及TensorFlow源码实现--深度学习笔记
- 对生成对抗网络GANs原理、实现过程、应用场景的理解(附代码),另附:深度学习大神文章列表
- 对抗的深度卷积生成网络来学习无监督表示
- 七月算法深度学习 第三期 学习笔记-第五节 生成对抗网络GAN
- 深度卷积对抗生成网络(DCGAN)
- GANs-生成对抗网络 (生成明星脸)
- 【深度学习:CNN】利用随机前馈神经网络生成图像观察网络复杂度
- 深度 | 生成对抗网络初学入门:一文读懂GAN的基本原理(附资源)
- 【学习资料】生成对抗网络(GAN,Generative Adversarial Networks)
- 生成对抗网络学习笔记2----GANs(Generative Adversarial Nets)总结
- 生成对抗网络学习笔记3----论文unsupervised representation learning with deep convolutional generative adversarial
- 一文读懂生成对抗网络GANs(附学习资源)