MyBatis缓存机制原理
2017-11-14 10:45
351 查看
本文参考:http://blog.csdn.net/luanlouis/article/details/41390801
Mybatis为了方式用户频繁的进行数据库查询操作。导致性能的下降,内部封装了缓存对象,通过缓存的机制,来提高查询的速度和效率。
Mybatis缓存分为两级:一级缓存和二级缓存
一级缓存是怎样实现的呢?
当用户创建sqlsession时会创建一个Executor对象,Executor创建一个cache对象,执行一个sql查询时,首先会根据查询的唯一标识到缓存中查找,如果找到结果集,则直接返回给用户,否则到数据库当中进行查找,将查询到的结果缓存到Cache中然后返回。

那么从用户操作,缓存存储,缓存查询,返回结果集,这一部分到底是如何来完成的呢?
前面说到,通过mybatis的一系列操作,都是从创建一个sqlsession会话开始的。
我们只需要通过sqlsession调用select,insert等操作就能获取到信息。
其实在mybatis中,sqlsession只是一个调用的接口,sqlSession创建时会创建一个Executor执行器,由这个执行器来执行操作。
而缓存的信息就存在这个执行器里,并且把对缓存的添加删除操作封装到了Cache对象当中。他们之间的关系如下图所示。
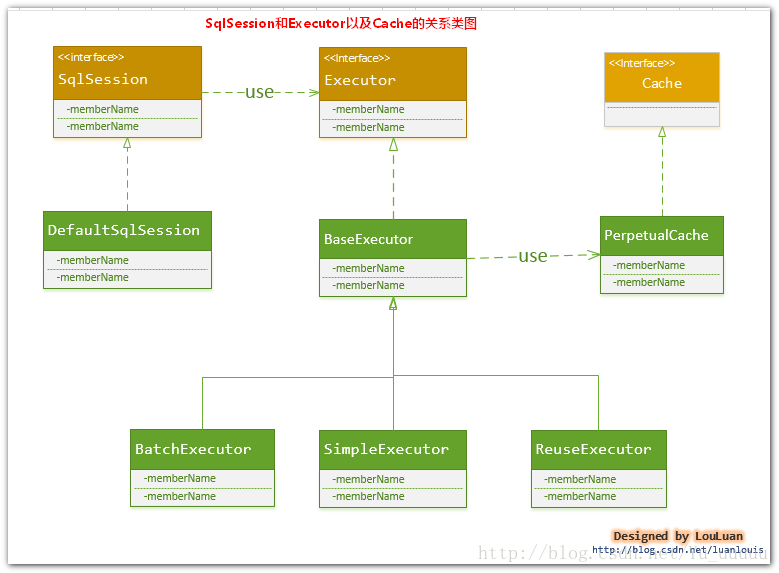
Executor接口的实现类BashExector拥有PerpetualCache对象,通过这个对象来对缓存进行维护。而PerpetualCache又实现了Cache接口
PerpetualCache代码实现其实非常简单。底层的结构就是通过一个HashMap来完成的,通过Key来存储查询操作的唯一标识,通过Value存储查询的结果集
实际上一级缓存就是通过PerpetualCache这个实现类来维护的。
缓存的生存周期从sqlsession会话创建直到销毁结束。
用户也可以手动的来调用sqlsession.close()来释放并关闭一级缓存。一级缓存将不可用。
如果调用sqlsession.clearCahce();方法,将会释放掉当前存储的所有缓存内容。但是一级缓存还是可用的。
由于对数据库进行update操作时,会改变数据内容,所以会清空掉缓存内容。一级缓存依然可用。
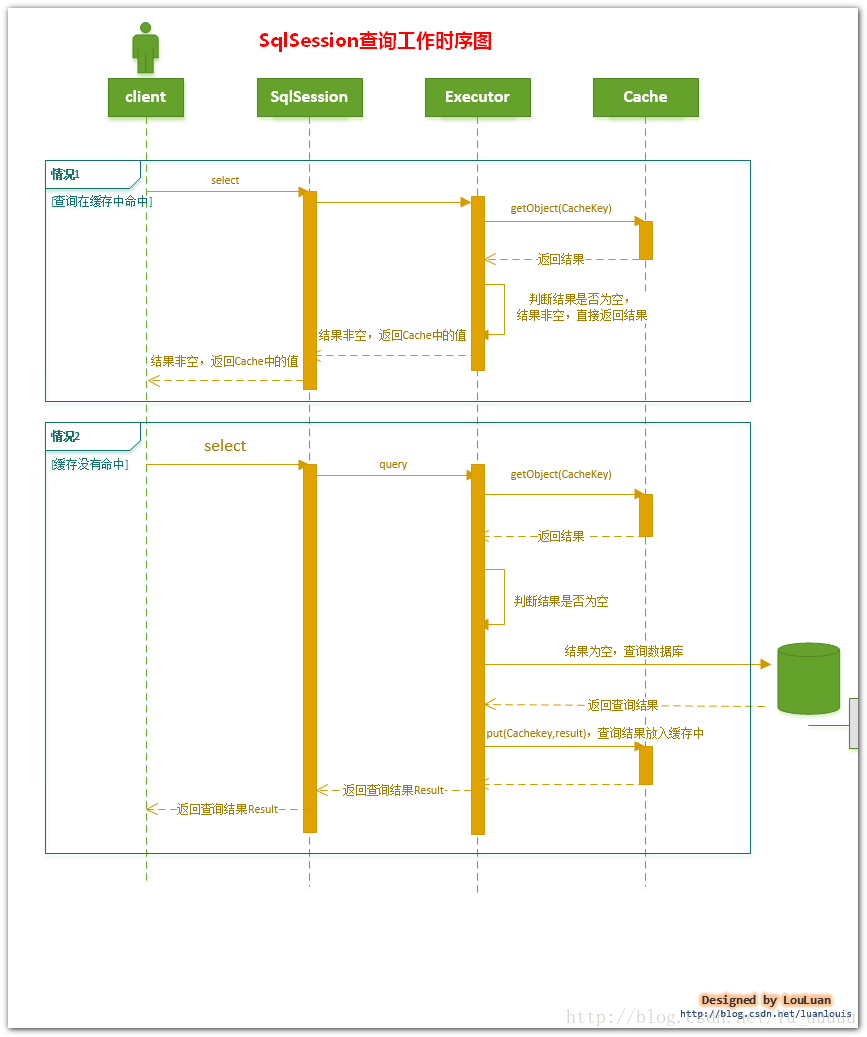
整个一级缓存的工作流程前面已经说过了
根据查询条件获得唯一查询标识key。
通过key到Cache中获取结果集。
如果查询到直接返回给用户。
如果未查询到则到数据库中获取,存入缓存中,返回给用户。
接下来就是最重点的内容。cache既然通过一个HashMap来维护缓存,那么缓存的key值,也就是唯一的查询条件是如何确定的呢?为何cache能够匹配到两次相同的查询。
缓存的key值,其实是由四部分来组成的:
1、statementID:也就是在mybatis中你要执行的sql语句唯一标识。(XML文件中配置的sql语句id )
2、rowBounds:查询时返回的结果集的范围。Mybatis自带的分页功能就是由rowBounds来实现的,通过rowBounds.offset和rowBounds.limit来过滤查询的结果集。
3、boundSql:就是最终通过xml映射参数之后生成的sql查询语句。 boundSql.getSql()。
4、preparedStatement:传递给JDBC的参数值。(并不是Dao方法所传递的参数值,而是在实际映射sql时的参数值,例如XML中 id = #{id} )
CacheKey由上述四部分来进行生成,这样在下次的查询中,如果判断这四个条件一样,则认为两次的查询是一致的。
由于preparedStatement参数值并不是接口中传入的,而是在JDBC 通过sql映射时的参数,所以如果多几个无效的参数并不影响缓存的key值判断。
CacheKey的生成源码在Executor的实现类BaseExecutor中
由于Cache的数据结构只是通过一个HashMap来进行存储的,所以不存在是否过期的判断和更新缓存的实现。
由于一级缓存生存周期是根据sqlsession来确定的。一般sqlSession生存周期比较端,所以一般不会发生内存溢出等问题。
用户当执行对表的update操作时,会清空一级缓存。
用户也可以通过clearCache()方法来清空一级缓存。
优先级:二级缓存 > 一级缓存 > DB 。
整个缓存的工作模式如图所示:
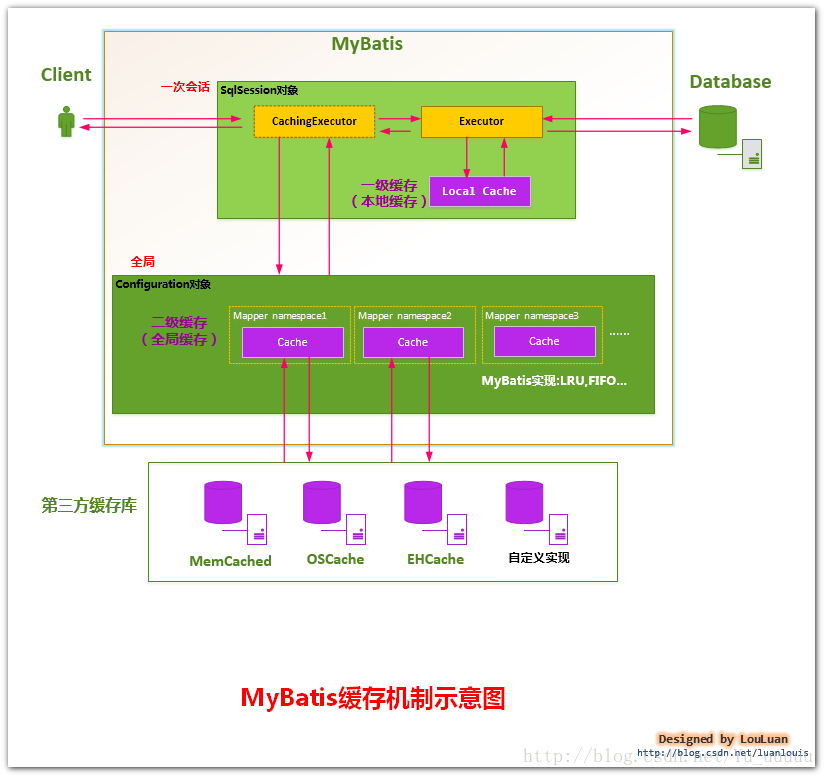
如上图所示,用户在执行一个操作时,首先会创建一个sqlSession会话,然后sqlSession会创建一个Executor对象来进行具体的执行操作。
但是,如果用户在配置文件中通过 cacheEnable = true 的开关开启了二级缓存,这时会创建一个CachingExecutor对象来进行具体的执行操作,而CachingExecutor实现了Executor,是Executor的装饰者。这里采用了设计模式中的装饰者模式。CachingExecutor首先会根据查询的标识到二级缓存中查询结果,如果查询直接返回,否则交给Executor去查询( 一级缓存查询流程 )。
二级缓存的划分流程更加细致,mybatis可以对Mapper级别进行缓存的开启。也就是每个Mapper一个缓存,通过节点配置。(这个Mapper在实际中就是对一个表的curd操作,这样可以对每个表都进行单独的缓存操作)也可以多个mapper共用一个缓存,通过节点配置。
这样可以总结,如果想要对一个mapper使用二级缓存必须要的几个配置:
1、配置myBatis二级缓存开关。cacheEnable = true
2、在Mapper中配置 或节点。
3、在select语句上,开启参数useCache = true。
解释一下第三点,如果不开启useCache = true,mybatis不会对所有的查询进行缓存。
Mybatis允许用户自定义实现二级缓存,只要实现org.apache.ibatis.cache.Cache接口,然后在节点的type上配置即可。
Mybatis也允许集成第三方缓存库。
Mybatis自身提供了多种缓存的刷新策略。
1、LRU ,最少使用算法,当cache容量满的时候,将最少使用的删除。
2、FIFO,先进先出算法,容量满时,最先添加的最先删除。
3、Scheduled,指定时间算法,指定一个时间间隔来将cache数据删除。
在实际的工作中,一般会使用第三方的缓存库。例如持久化的redis等。
Mybatis为了方式用户频繁的进行数据库查询操作。导致性能的下降,内部封装了缓存对象,通过缓存的机制,来提高查询的速度和效率。
Mybatis缓存分为两级:一级缓存和二级缓存
一级缓存
一级缓存是会话级别的缓存,通过Cache对象来进行封装查询标识与查询结果。由于在数据库操作时,是通过创建sqlSession会话来实现的。所以一级缓存的生命周期从创建SqlSesion开始到销毁SqlSession结束,并且不允许用户自己进行配置。一级缓存是怎样实现的呢?
当用户创建sqlsession时会创建一个Executor对象,Executor创建一个cache对象,执行一个sql查询时,首先会根据查询的唯一标识到缓存中查找,如果找到结果集,则直接返回给用户,否则到数据库当中进行查找,将查询到的结果缓存到Cache中然后返回。
那么从用户操作,缓存存储,缓存查询,返回结果集,这一部分到底是如何来完成的呢?
前面说到,通过mybatis的一系列操作,都是从创建一个sqlsession会话开始的。
我们只需要通过sqlsession调用select,insert等操作就能获取到信息。
其实在mybatis中,sqlsession只是一个调用的接口,sqlSession创建时会创建一个Executor执行器,由这个执行器来执行操作。
而缓存的信息就存在这个执行器里,并且把对缓存的添加删除操作封装到了Cache对象当中。他们之间的关系如下图所示。
Executor接口的实现类BashExector拥有PerpetualCache对象,通过这个对象来对缓存进行维护。而PerpetualCache又实现了Cache接口
PerpetualCache代码实现其实非常简单。底层的结构就是通过一个HashMap来完成的,通过Key来存储查询操作的唯一标识,通过Value存储查询的结果集
实际上一级缓存就是通过PerpetualCache这个实现类来维护的。
package org.apache.ibatis.cache.impl;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.ReadWriteLock;
import org.apache.ibatis.cache.Cache;
import org.apache.ibatis.cache.CacheException;
public class PerpetualCache implements Cache {
private String id;
private Map<Object, Object> cache = new HashMap<Object, Object>();
public PerpetualCache(String id) {
this.id = id;
}
public String getId() {
return id;
}
public int getSize() {
return cache.size();
}
public void putObject(Object key, Object value) {
cache.put(key, value);
}
public Object getObject(Object key) {
return cache.get(key);
}
public Object removeObject(Object key) {
return cache.remove(key);
}
public void clear() {
cache.clear();
}
public ReadWriteLock getReadWriteLock() {
return null;
}
public boolean equals(Object o) {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
if (this == o) return true;
if (!(o instanceof Cache)) return false;
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
public int hashCode() {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
return getId().hashCode();
}
}缓存的生存周期从sqlsession会话创建直到销毁结束。
用户也可以手动的来调用sqlsession.close()来释放并关闭一级缓存。一级缓存将不可用。
如果调用sqlsession.clearCahce();方法,将会释放掉当前存储的所有缓存内容。但是一级缓存还是可用的。
由于对数据库进行update操作时,会改变数据内容,所以会清空掉缓存内容。一级缓存依然可用。
整个一级缓存的工作流程前面已经说过了
根据查询条件获得唯一查询标识key。
通过key到Cache中获取结果集。
如果查询到直接返回给用户。
如果未查询到则到数据库中获取,存入缓存中,返回给用户。
接下来就是最重点的内容。cache既然通过一个HashMap来维护缓存,那么缓存的key值,也就是唯一的查询条件是如何确定的呢?为何cache能够匹配到两次相同的查询。
缓存的key值,其实是由四部分来组成的:
1、statementID:也就是在mybatis中你要执行的sql语句唯一标识。(XML文件中配置的sql语句id )
2、rowBounds:查询时返回的结果集的范围。Mybatis自带的分页功能就是由rowBounds来实现的,通过rowBounds.offset和rowBounds.limit来过滤查询的结果集。
3、boundSql:就是最终通过xml映射参数之后生成的sql查询语句。 boundSql.getSql()。
4、preparedStatement:传递给JDBC的参数值。(并不是Dao方法所传递的参数值,而是在实际映射sql时的参数值,例如XML中 id = #{id} )
CacheKey由上述四部分来进行生成,这样在下次的查询中,如果判断这四个条件一样,则认为两次的查询是一致的。
由于preparedStatement参数值并不是接口中传入的,而是在JDBC 通过sql映射时的参数,所以如果多几个无效的参数并不影响缓存的key值判断。
CacheKey的生成源码在Executor的实现类BaseExecutor中
/**
* 所属类: org.apache.ibatis.executor.BaseExecutor
* 功能 : 根据传入信息构建CacheKey
*/
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) throw new ExecutorException("Executor was closed.");
CacheKey cacheKey = new CacheKey();
//1.statementId
cacheKey.update(ms.getId());
//2. rowBounds.offset
cacheKey.update(rowBounds.getOffset());
//3. rowBounds.limit
cacheKey.update(rowBounds.getLimit());
//4. SQL语句
cacheKey.update(boundSql.getSql());
//5. 将每一个要传递给JDBC的参数值也更新到CacheKey中
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
for (int i = 0; i < parameterMappings.size(); i++) { // mimic DefaultParameterHandler logic
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
//将每一个要传递给JDBC的参数值也更新到CacheKey中
cacheKey.update(value);
}
}
return cacheKey;
}
//而cacheKey的HashCode生成源码:
public void update(Object object) {
if (object != null && object.getClass().isArray()) {
int length = Array.getLength(object);
for (int i = 0; i < length; i++) {
Object element = Array.get(object, i);
doUpdate(element);
}
} else {
doUpdate(object);
}
}
private void doUpdate(Object object) {
//1. 得到对象的hashcode;
int baseHashCode = object == null ? 1 : object.hashCode();
//对象计数递增
count++;
checksum += baseHashCode;
//2. 对象的hashcode 扩大count倍
baseHashCode *= count;
//3. hashCode * 拓展因子(默认37)+拓展扩大后的对象hashCode值
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}由于Cache的数据结构只是通过一个HashMap来进行存储的,所以不存在是否过期的判断和更新缓存的实现。
由于一级缓存生存周期是根据sqlsession来确定的。一般sqlSession生存周期比较端,所以一般不会发生内存溢出等问题。
用户当执行对表的update操作时,会清空一级缓存。
用户也可以通过clearCache()方法来清空一级缓存。
二级缓存:
一级缓存是会话级别的,而二级缓存是存在整个应用级别的。优先级:二级缓存 > 一级缓存 > DB 。
整个缓存的工作模式如图所示:
如上图所示,用户在执行一个操作时,首先会创建一个sqlSession会话,然后sqlSession会创建一个Executor对象来进行具体的执行操作。
但是,如果用户在配置文件中通过 cacheEnable = true 的开关开启了二级缓存,这时会创建一个CachingExecutor对象来进行具体的执行操作,而CachingExecutor实现了Executor,是Executor的装饰者。这里采用了设计模式中的装饰者模式。CachingExecutor首先会根据查询的标识到二级缓存中查询结果,如果查询直接返回,否则交给Executor去查询( 一级缓存查询流程 )。
二级缓存的划分流程更加细致,mybatis可以对Mapper级别进行缓存的开启。也就是每个Mapper一个缓存,通过节点配置。(这个Mapper在实际中就是对一个表的curd操作,这样可以对每个表都进行单独的缓存操作)也可以多个mapper共用一个缓存,通过节点配置。
这样可以总结,如果想要对一个mapper使用二级缓存必须要的几个配置:
1、配置myBatis二级缓存开关。cacheEnable = true
2、在Mapper中配置 或节点。
3、在select语句上,开启参数useCache = true。
解释一下第三点,如果不开启useCache = true,mybatis不会对所有的查询进行缓存。
Mybatis允许用户自定义实现二级缓存,只要实现org.apache.ibatis.cache.Cache接口,然后在节点的type上配置即可。
Mybatis也允许集成第三方缓存库。
Mybatis自身提供了多种缓存的刷新策略。
1、LRU ,最少使用算法,当cache容量满的时候,将最少使用的删除。
2、FIFO,先进先出算法,容量满时,最先添加的最先删除。
3、Scheduled,指定时间算法,指定一个时间间隔来将cache数据删除。
在实际的工作中,一般会使用第三方的缓存库。例如持久化的redis等。

相关文章推荐
- 《深入理解mybatis原理(六)》 MyBatis缓存机制的设计与实现如何细粒度地控制你的MyBatis二级缓存
- 深入理解mybatis原理(五) MyBatis缓存机制的设计与实现
- 深入理解mybatis原理(六) MyBatis缓存机制的设计与实现如何细粒度地控制你的MyBatis二级缓存
- 《深入理解mybatis原理(五)》 MyBatis缓存机制的设计与实现
- 《深入理解mybatis原理(五)》 MyBatis缓存机制的设计与实现
- 《深入理解mybatis原理(六)》 MyBatis缓存机制的设计与实现如何细粒度地控制你的MyBatis二级缓存
- mybatis缓存机制
- 【mybatis】【延迟加载】【mybatis的缓存机制】
- 《深入理解mybatis原理》 MyBatis缓存机制的设计与实现
- MyBatis缓存机制学习笔记
- 彻底弄懂HTTP缓存机制及原理
- 《深入理解mybatis原理》 MyBatis缓存机制的设计与实现
- MyBatis概述(1) 缓存机制
- MyBatis学习(五)-缓存机制
- Mybatis的缓存机制(一)
- 《深入理解mybatis原理》 MyBatis缓存机制的设计与实现
- MyBatis缓存机制
- Mybatis缓存机制
- MyBatis 源码分析 - 缓存原理
- 【MyBatis】mybatis执行流程与缓存机制分析