A Survey on Techniques in NLP--阅读笔记
2017-11-12 17:23
267 查看
论文链接
ABSTRACT
INTRODUCTION
OVERVIEW OF PHASES
Language modelling
POS tagging
Parsing
METHODOLOGIES ANALYSIS
Language Modelling
POS tagging
Parsing
本文描述了自然语言处理的三个阶段,即语言建模,词类标注和解析,概述了可以使用的方法。
多年来开发的语音识别,语言翻译,信息检索,文本摘要等自然语言处理的很多应用。
NLP有几个阶段取决于应用程序,但在这里,我们将讨论限制在三个阶段,即语言建模,词类标注和解析。
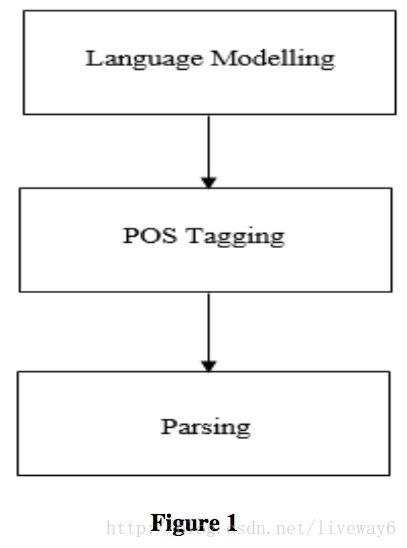
请注意,该图特定于本调查中指定的方法,即统计语言建模,POS(parts-of-speech,词类)标记和解析。像神经网络这样的某些方法可能不能确认这个时间顺序。
在NLP中多次提出自己的头脑的固有问题之一是模棱两可的问题。研究人员在处理几乎每一个阶段都必须处理模棱两可的问题。例如,在POS标签中,考虑“可以”这个词:
它可以被分类为一个模态动词,因为它是一种能够做某事的能力,
也可以被归类为一个名词,因为它可以是一个容器来容纳某物。
历史上,语言处理应用程序通过创建基于规则的软件来检查句子的结构,以查看它是否符合指定的结构。一旦规则变多之前的相互作用就变得复杂,对大规模数据无用。
最近的方法采用的方法利用了可用于训练语言模型的海量数据。换句话说,最近的语言处理方法利用数据驱动的方法来达到理解语言的目的。这些数据驱动的策略组成了NLP的统计革命。
有许多方法可以模拟语言,如:
n-gram模型;
决策树模型;
语言激励模型;
指数模型;
自适应模型。
在这里介绍如何在语言建模工作中的n-gram模型。 N-gram模型是语言建模过程的主要部分,也是语音识别系统中使用最广泛的模型。
N-gram模型基于隐藏的马尔可夫链顺序。 马尔可夫链与条件概率相似,但其假设值根据马尔科夫链的顺序变化。
考虑可以取值x1,x2和x3的随机变量X1,X2,X3。 X1,X2,X3取x1,x2和x3的概率由下式给出:
P(X1=x1,X2=x3,X2=x3)=P(X1=x1∣X2=x2,X3=x3).P(X2=x2∣X3=x3).P(X3=x3)
随着一级马尔可夫假设,它成为一元模型,马氏假设为二级,它成为二元模型。 n-gram模型以前面的条件为条件。
一个二元模型如下
P(Xi=xi)=∑i=2nP(Xi=xi∣Xi−1=xi−1)
具体而言,无论何时对一种语言进行建模,在一个二元模型中,都会调整一个特定词语出现在前一个词所在位置的概率。 因此,要确定最大可能的单词发生,例如前一个单词是“the”。
使用训练数据建立表格,并记录所有的单词与前一个单词具有相关联的概率。 可以通过查找这个表来推断出跟随的最可能的单词是X。
但当测试集没有出现训练集的一个单词,就会出现问题,某些类别的平滑技术因此被应用。
语言模型用一种称为“困惑(perplexity)”的度量来评估。 困惑的表达由下式给出:
H=−∑DP(D).logPM(D)
其中H表示模型的熵(语言样本D的概率的组合)。
这里,表示语言样本D新句子样本的概率,表示D表示模型中语言的概率。
分配给每个单词的词汇类是名词,代词,形容词,动词等类型。
广义上有两种方法,即基于规则和随机的:
基于规则的方法使用手写消歧规则的大数据库,考虑语素排序和上下文信息。基于规则的标记器使用语言规则将正确的标签分配给句子或文件中的单词,例如。动词识别规则,名词识别规则,代词识别规则,形容词识别规则。由于手动编写的规则,基于规则的标记器是复杂和耗时的,因此随机方法优于基于规则。
统计方法主要分为三个部分,即HMM(生成模型),最大熵和条件随机场。
对于词性标注,最常用的算法是维特比算法,同时考虑HMM。维特比算法建立在动态规划和语言概率模型的原理上。
解析不是那么简单,因为我们使用的语言有一个固有的模糊的语法。这会导致不同的分析树,可能意味着不同的事情。举个例子,考虑一个句子,“Happy cats and dogs live on the farm.”。如图所示,我们可以有两个有着鲜明含义的解析树:
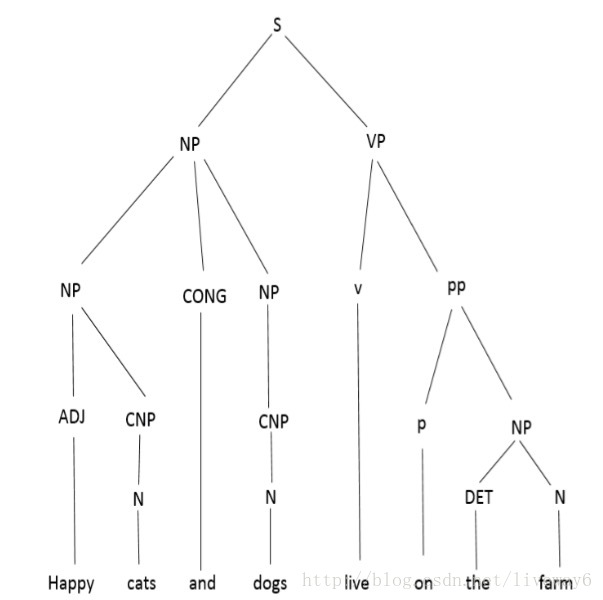
表示:快乐的猫和普通的狗都住在农场里。
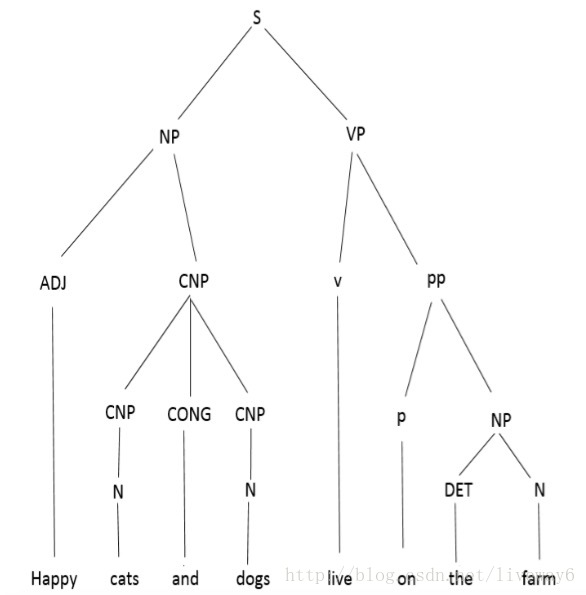
表示:快乐的猫和快乐的狗都住在农场里。
由于这种含糊不清,意义的变化,因此解析旨在消除或至少减少模糊语法造成的歧义。
解析有各种方法可供使用,这里深入研究Michael Collins提出的最新方法之一。
词汇化的解析器由一组具有与每个语法规则相关的概率的上下文无关语法规则给出。 这是它与概率上下文无关语法模型的相似之处。 除了这些语法概率规则之外,词汇化的PCFG也具有与每个规则相关的头部,这些规则对上(父)节点具有词汇化的含义。
这个扩展的主要优点是在解析一个句子时保留了词汇化的信息,因此短语的附加比PCFG更容易执行。 更正式地说,一个词汇化的PCFG由一个由非终端,终端,生产规则,起始状态组成的语法给出。
每条规则都有一个与其相关的概率,并且是由父节点提供的。
ABSTRACT
INTRODUCTION
OVERVIEW OF PHASES
Language modelling
POS tagging
Parsing
METHODOLOGIES ANALYSIS
Language Modelling
POS tagging
Parsing
ABSTRACT
自然语言处理领域(NLP)是语言学,计算和统计学研究的交汇点。 NLP的主要目标是自动理解人类使用的半结构化语言。本研究主要应用于语义分析,摘要,文本分类等多个领域。本文描述了自然语言处理的三个阶段,即语言建模,词类标注和解析,概述了可以使用的方法。
INTRODUCTION
自然语言处理的思想是设计和开发一个可以分析,理解和综合自然人类语言的计算机系统。自然语言属于人工智能领域,目标是理解和创造人类语言中的有意义的表达。多年来开发的语音识别,语言翻译,信息检索,文本摘要等自然语言处理的很多应用。
NLP有几个阶段取决于应用程序,但在这里,我们将讨论限制在三个阶段,即语言建模,词类标注和解析。
OVERVIEW OF PHASES
任何NLP应用程序的初步目标是为属于该语言集的句子生成一个解析树。为了创建一个解析树,需要知道句子中所有单词所属的类,即一个单词是形容词还是动词或其他。为了正确识别特定单词所属的类别,我们依靠语言模型。如下图:请注意,该图特定于本调查中指定的方法,即统计语言建模,POS(parts-of-speech,词类)标记和解析。像神经网络这样的某些方法可能不能确认这个时间顺序。
在NLP中多次提出自己的头脑的固有问题之一是模棱两可的问题。研究人员在处理几乎每一个阶段都必须处理模棱两可的问题。例如,在POS标签中,考虑“可以”这个词:
它可以被分类为一个模态动词,因为它是一种能够做某事的能力,
也可以被归类为一个名词,因为它可以是一个容器来容纳某物。
历史上,语言处理应用程序通过创建基于规则的软件来检查句子的结构,以查看它是否符合指定的结构。一旦规则变多之前的相互作用就变得复杂,对大规模数据无用。
最近的方法采用的方法利用了可用于训练语言模型的海量数据。换句话说,最近的语言处理方法利用数据驱动的方法来达到理解语言的目的。这些数据驱动的策略组成了NLP的统计革命。
Language modelling
语言建模是制作语言后期阶段使用的语言的概率模型的艺术。 这个模型在统计上是严格统计的,它忽略了句子的基本含义,并着重于发展特定语言的概率分布。POS tagging
词性标注是词语在其上下文中分类的过程。 它使用前一节中构建的概率模型以及其他参数将单词分类到其类中。Parsing
解析涉及到构造分析树来理解句子不同组成部分之间的关系。 这在解决歧义方面尤为重要。 解析模型使用上下文无关文法以及与每个规则相关的概率来导出句子的解析树。METHODOLOGIES’ ANALYSIS
Language Modelling
统计语言模型就是语言中所有可能的句子S的概率分布,即统计语言建模只计算句子的概率分布,而不考虑句子的语义。有许多方法可以模拟语言,如:
n-gram模型;
决策树模型;
语言激励模型;
指数模型;
自适应模型。
在这里介绍如何在语言建模工作中的n-gram模型。 N-gram模型是语言建模过程的主要部分,也是语音识别系统中使用最广泛的模型。
N-gram模型基于隐藏的马尔可夫链顺序。 马尔可夫链与条件概率相似,但其假设值根据马尔科夫链的顺序变化。
考虑可以取值x1,x2和x3的随机变量X1,X2,X3。 X1,X2,X3取x1,x2和x3的概率由下式给出:
P(X1=x1,X2=x3,X2=x3)=P(X1=x1∣X2=x2,X3=x3).P(X2=x2∣X3=x3).P(X3=x3)
随着一级马尔可夫假设,它成为一元模型,马氏假设为二级,它成为二元模型。 n-gram模型以前面的条件为条件。
一个二元模型如下
P(Xi=xi)=∑i=2nP(Xi=xi∣Xi−1=xi−1)
具体而言,无论何时对一种语言进行建模,在一个二元模型中,都会调整一个特定词语出现在前一个词所在位置的概率。 因此,要确定最大可能的单词发生,例如前一个单词是“the”。
使用训练数据建立表格,并记录所有的单词与前一个单词具有相关联的概率。 可以通过查找这个表来推断出跟随的最可能的单词是X。
但当测试集没有出现训练集的一个单词,就会出现问题,某些类别的平滑技术因此被应用。
语言模型用一种称为“困惑(perplexity)”的度量来评估。 困惑的表达由下式给出:
H=−∑DP(D).logPM(D)
其中H表示模型的熵(语言样本D的概率的组合)。
这里,表示语言样本D新句子样本的概率,表示D表示模型中语言的概率。
POS tagging
词性标注是解析任务的先导任务。这个短语的含义是句子中的一个单词被标记或标注了一个词性。更具体地说,POS是根据上下文为句子中的每个词分配词汇类标记的过程。分配给每个单词的词汇类是名词,代词,形容词,动词等类型。
广义上有两种方法,即基于规则和随机的:
基于规则的方法使用手写消歧规则的大数据库,考虑语素排序和上下文信息。基于规则的标记器使用语言规则将正确的标签分配给句子或文件中的单词,例如。动词识别规则,名词识别规则,代词识别规则,形容词识别规则。由于手动编写的规则,基于规则的标记器是复杂和耗时的,因此随机方法优于基于规则。
统计方法主要分为三个部分,即HMM(生成模型),最大熵和条件随机场。
对于词性标注,最常用的算法是维特比算法,同时考虑HMM。维特比算法建立在动态规划和语言概率模型的原理上。
Parsing
解析的一个例子是分析树的生成,显示了句子不同组成部分之间的关系。作为一个例子,考虑这个句子,约翰击球。在这里,为了建立不同单词之间的关系,我们需要一个解析树来为我们做这个。一个解析树就是这样做的,如下图所示。解析不是那么简单,因为我们使用的语言有一个固有的模糊的语法。这会导致不同的分析树,可能意味着不同的事情。举个例子,考虑一个句子,“Happy cats and dogs live on the farm.”。如图所示,我们可以有两个有着鲜明含义的解析树:
表示:快乐的猫和普通的狗都住在农场里。
表示:快乐的猫和快乐的狗都住在农场里。
由于这种含糊不清,意义的变化,因此解析旨在消除或至少减少模糊语法造成的歧义。
解析有各种方法可供使用,这里深入研究Michael Collins提出的最新方法之一。
词汇化的解析器由一组具有与每个语法规则相关的概率的上下文无关语法规则给出。 这是它与概率上下文无关语法模型的相似之处。 除了这些语法概率规则之外,词汇化的PCFG也具有与每个规则相关的头部,这些规则对上(父)节点具有词汇化的含义。
这个扩展的主要优点是在解析一个句子时保留了词汇化的信息,因此短语的附加比PCFG更容易执行。 更正式地说,一个词汇化的PCFG由一个由非终端,终端,生产规则,起始状态组成的语法给出。
每条规则都有一个与其相关的概率,并且是由父节点提供的。

相关文章推荐
- 论文阅读笔记:Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
- Attention and Memory in Deep Learning and NLP(深度学习和NLP中的注意和记忆机制) 阅读笔记
- 【点击模型学习笔记】A survey on click modeling in web search_Lianghao Li_ppt
- A survey of task allocation and load balance in distributed system阅读笔记
- Exception Management in .NET阅读笔记
- Tensor Representation in High-Frequency Finanical Data for Price Change Prediction(阅读笔记 待更新)
- Thinking in C++ 阅读笔记(第三章)
- 论文阅读笔记:DeepRadiologyNet: Radiologist Level Pathology Detection in CT Head Images
- Exception Management in .NET阅读笔记
- Java Concurrency In Practice 阅读笔记(第一、二部分)
- Thinking in c++ 阅读笔记 2014.5.26
- A survey on the communication architectures in smart grid(2)
- 【论文阅读笔记】Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique
- LEARNING TO NAVIGATE IN COMPLEX ENVIRONMENTS 阅读笔记
- 论文笔记:A Survey on Tag Recommendation Methods 上
- [NLP论文阅读] Word Embedding based on Fixed-Size Ordinally Forgetting Encoding
- Hibernate in action阅读笔记-吵吵冷饭-持久化对象
- DARLA: Improving Zero-Shot Transfer in Reinforcement Learning 阅读笔记
- 【Android安全研究笔记】A Survey of Mobile Malware in the Wild
- Solr in Action阅读笔记