改善深度神经网络(理论)—超参数调试、Batch正则化和程序框架(2-3)
2017-11-11 12:09
549 查看
1.调试处理
关于训练神经网络,要处理的参数的数量,从学习速率αα 到momentum ββ 同时还有Adam优化算法的参数 ββ ,ββ and εε,也p许还需要选择层数 layer_size, 不同层中隐藏单元的数量 layer_units ,有可能还需要选择学习率衰减 learning_rate_decay,还有需要选择mini_batch 的大小。但是,虽然有这么多的超参数,但是在神经网络中的调试是有优先级的,优先级如下:
αα > ββ (momentum,0.9) > mini_batch_size = hidden_units_size >layer_size = learning_rate_decay > ββ (0.9), ββ (0.999) ,εε(10^(-8))
1.在机器学习领域,超参数比较少的情况下,我们之前利用设置网格点的方式来调试超参数。
2.但在深度学习领域,超参数较多的情况下,不是设置规则的网格点,而是随机选择点进行调试。这样做是因为在我们处理问题的时候,是无法知道哪个超参数是更重要的,所以随机的方式去测试超参数点的性能,更为合理,这样可以探究更超参数的潜在价值。
如果在某一区域找到一个效果好的点,将关注点放到点附近的小区域内继续寻找。
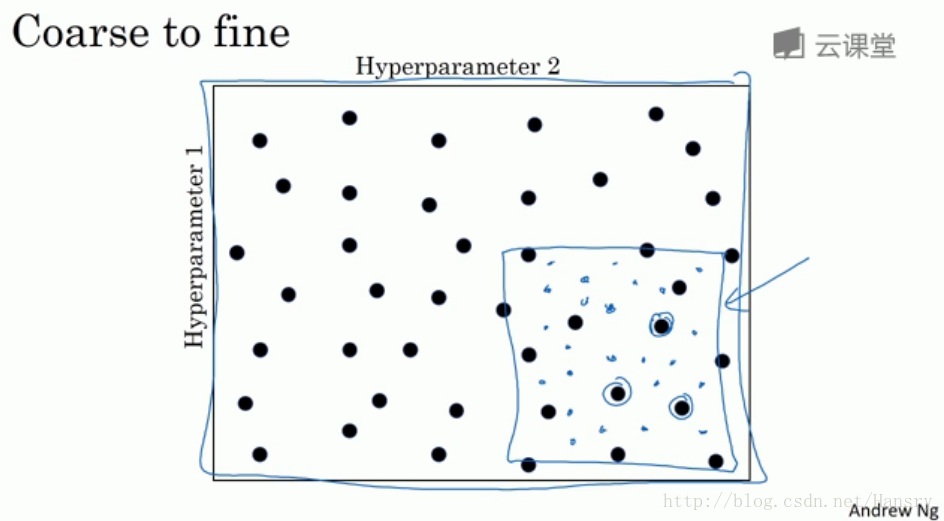
2.为超参数选择合适的范围
Scale 均匀随机
在上一节中,随机取值并不是在有效值范围内的随机均匀取值,而是选择合适的scale(标尺)用于探究这些超参数。在超参数选择的过程中,一些超参数是在一个范围内进行均匀随机取值的,如神经元结点的个数,隐藏层的层数等。但是有一些超参数的选择做均匀随机取值是不合适的,如学习率 αα ,这里需要按照一定的比例在不同的小范围内进行均匀随机取值,假如 αα 在[0.0001,1]之间取值,那么我们如果使用普通的均匀随机取值,αα 在[0.0001,0.001]之间的取值只有0.1*0.1*0.1=0.1%的概率才会选在这个区间中,这明显是不合理的!

所以,为保证在[0.0001,0.001] , [0.001,0.01] , [0.01,0.1] , [0.1,1] 这几个范围内均匀取值,则我们需要使用scale均匀随机。
可以构造一个指数型函数,则我们有:
r=np.random.rand() learning_rate=10**r
这里我们通过对数求得 r 属于 [-4,0] 这个区间,α=10rα=10r。因此当根据学习率的范围可以求出r的范围 [a,b],从而学习率 α=10rα=10r, α∈[10a,10b]α∈[10a,10b]
对于momentum中的指数加平均中的 ββ,若我们需要它的取值在[0.9,0.999]之间,我们也需要对其进行scale调整,我们需要对其划分为[0.9,0.99] [0.99,0.999] , 其中0.9,0.99,0.999分别对应了其平均10,100,1000个平均数(如果忘记了指数加权平均,请跳转自改善深层神经网络:超参数调试、正则化以及优化——优化算法(2-2) )。则 1- ββ 分别为 0.1,0.01,0.001,这样子我们可以利用对数,得到 β=1−10r,r∈[−3,−1]β=1−10r,r∈[−3,−1] ,对r进行均匀取值。
为什么需要对越小的区间给予相同的权重?
对于学习率 α=10rα=10r而言,学习率越小,虽然迭代速度慢,但是优于找到最小值。对于Momentum 的 ββ 来说,如果 ββ=0.999,是平均了前1000个数,而 ββ=0.9995则平均了前2000个数,ββ越靠近1,灵敏度越大,所以必须对其保持一定的警惕性,才能得到较好的值。
3.超参数调试实践——Pandasvs vs. Caviar
在超参数调试的实际操作中,我们需要根据我们的计算资源来决定以什么样的方式去调试超参数,进而对模型进行改进。以下是不同情况下的俩种方式: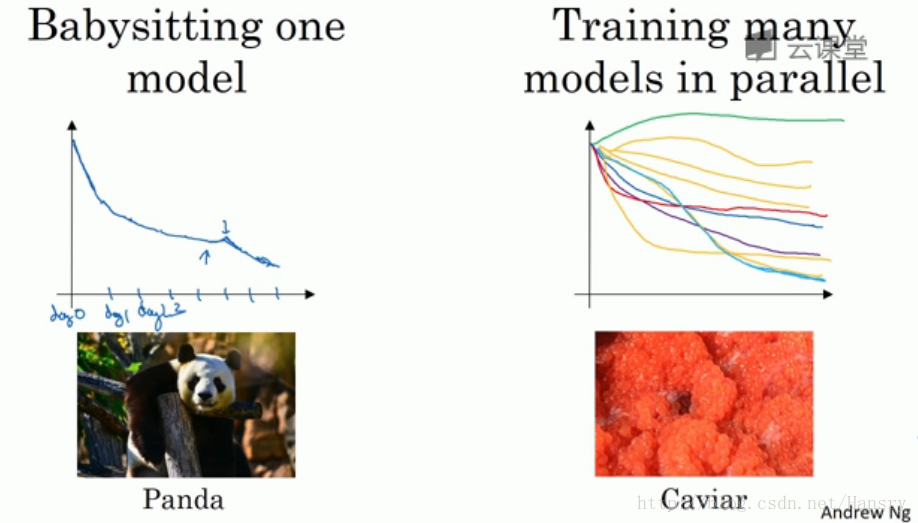
1.在计算机资源有限的情况下,选择第一种,仅调试一个模型,并且不断的对其进行优化。
2.在计算机资源充足的情况下,选择第二种,同时并行调试多个模型,选择其中最好的模型。
4. 网络中激活值的归一化
在Logistic Regression 中,将输入特征进行归一化,可以加速模型的训练。那么对于更深层次的神经网络,我们是否可以归一化隐藏层的输出 a[l]a[l] 或者 激活函数之前的 z[l]z[l] 值,从而加速对神经网络的训练。在这里我们将隐藏层的激活函数前的 z[l]z[l]进行归一化。Batch norm的实现
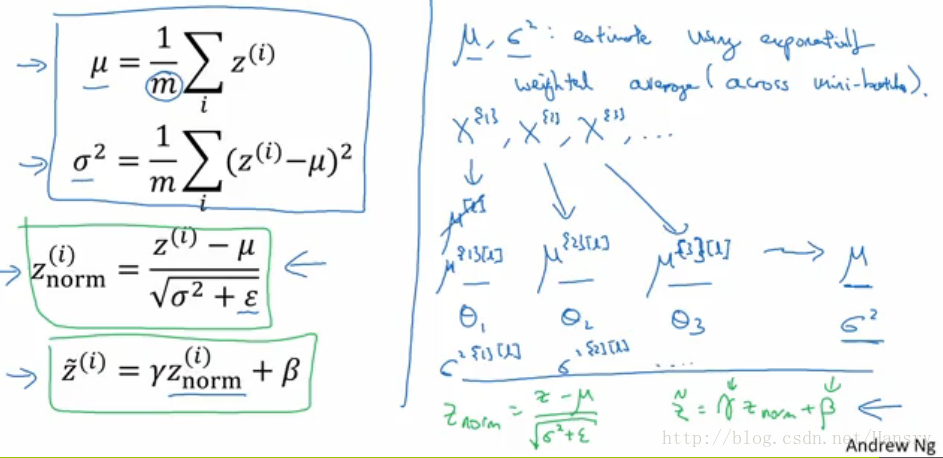
这里我们以神经网络的其中一层为例,有 z(1),z(2),⋯,z(n)z(1),z(2),⋯,z(n),则有以下公式:u=1m∗∑ni=1z(i)u=1m∗∑i=1nz(i)
σ2=1m∗∑ni=1(z(i)−u)σ2=1m∗∑i=1n(z(i)−u)
znorm=z(i)−uσ2+ε√znorm=z(i)−uσ2+ε
这里加上epsilon是为了保证数值的稳定。
到这里为止,z的数据为均值为0,方差为1的分布,但是当我们使用的激活函数为sigmoid的时候,如果数据都集中在均值为0,方差为1之间的时候,可能会失去sigmoid其他范围的性质,这时候我们会使用参数 γ,βγ,β,如下所示:
z˜=γ∗znorm+βz~=γ∗znorm+β
这里的 γ,βγ,β 是可以学习的超参数,可以使用gd 或者 Momentum 或者 adam 来得到俩个参数的值来确定其分布。
5.将Batch Norm拟合进神经网络
在深度神经网络中应用Batch Norm,前向传播的计算流程如下图所示: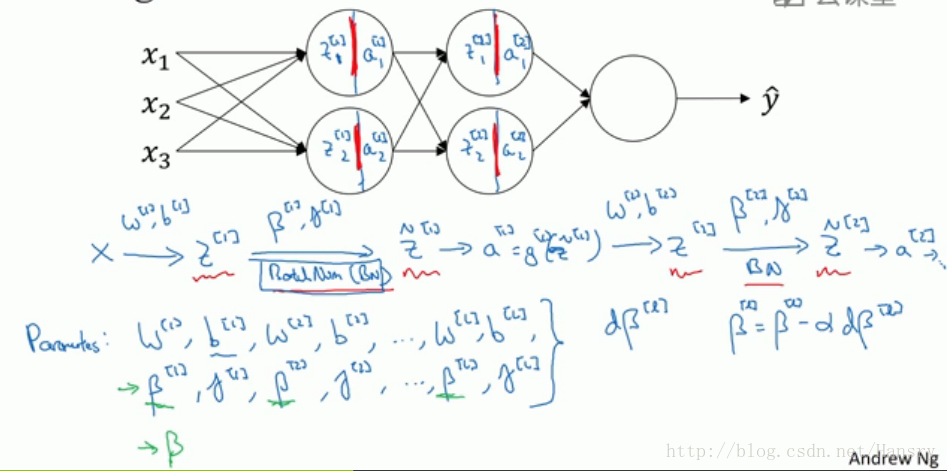
其中,我们将一个神经元看作是俩种运算,一种线性正向传播,另一种非线性正向传播,当加入Batch_Norm后,其正向传播和反向传播分别如下所示:
for mini_batch in minibatches: (这里的mini_batch指每一个划分的小集合):
1. 对 l 层的X(第一层是X,后面都是 A[l−1]A[l−1])求正向传播(forward_propagation),从而得到 Z[l]Z[l] (正向传播)
2. 在每一层中都将 Z˜[l]Z~[l] (正向传播)
3. 计算完正向传播后,开始进行反向传播,需要计算的各个参数有 dW,dβ,dγdW,dβ,dγ(反向传播)
4. 进行参数的更新(反向传播):
W[l]=W[l]−α∗dW(l)W[l]=W[l]−α∗dW(l)
γ[l]=γ[l]−γ∗dW(l)γ[l]=γ[l]−γ∗dW(l)
β[l]=β[l]−β∗dW(l)β[l]=β[l]−β∗dW(l)
对于Mini_batch的梯度下降法,Batch 同样适用于 Momentum,RMSprop ,Adam 等方法来进行参数的更新。
在第三步中,我们没有给出 dW,dβ,dγdW,dβ,dγ,主要是因为在Batch_norm的时候,我们是先计算 Z[l]Z[l] 的平均值,对每个Z[l]Z[l] 值减去其平均值u,再除以其方差,在这个过程中,其实有加上 b 和跟没有加上 b其实是一样的,所以在这里我们将偏置参数 Z[l]Z[l] 舍去,或者直接置0.
6.Batch Norm 为什么奏效?
原因1:使数据更加集中,加速收敛过程
类似于对输入层的输入特征进行归一化,Batch Norm 可以加速神经网络训练的原因在于可以使得Cost function的形状更为集中,使得每次梯度下降都可以更快的接近函数的最小值点,从而加速模型训练过程。与输入特征归一化不同的是,Batch_norm 是将各个隐藏层的激活函数的激活值进行归一化(归一化后呈现均值为0,方差为1的分布),并通过参数调整到各个层的分布。
原因2:使权重比网络更滞后或者更深层
下面是一个判别是否是猫的分类问题,假设第一训练样本的集合中的猫均是黑猫,而第二个训练样本集合中的猫是各种颜色的猫。如果我们将第二个训练样本直接输入到用第一个训练样本集合训练出的模型进行分类判别,那么我们在很大程度上是无法保证能够得到很好的判别结果。这是因为第一个训练集合中均是黑猫,而第二个训练集合中各色猫均有,虽然都是猫,但是很大程度上样本的分布情况是不同的,所以我们无法保证模型可以仅仅通过黑色猫的样本就可以完美的找到完整的决策边界。第二个样本集合相当于第一个样本的分布的改变(这句话很重要),称为:Covariate shift。如下图所示:
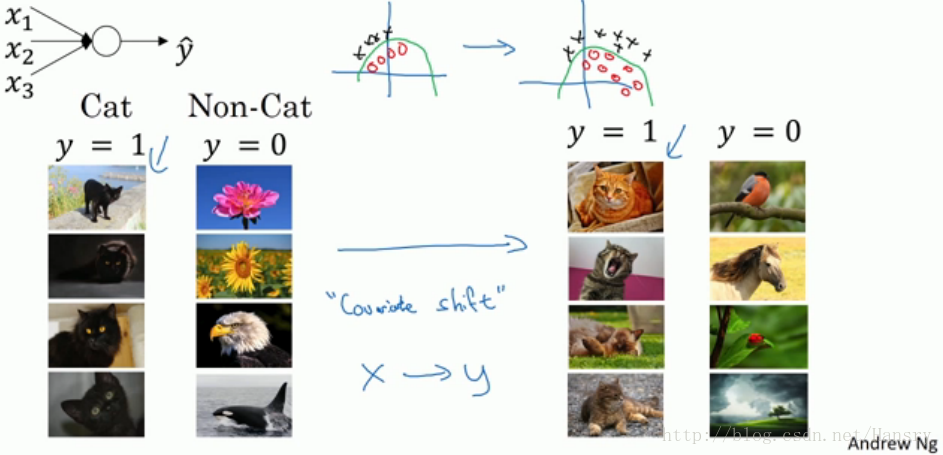
那么存在Covariate shift的问题如何应用在神经网络中?就是利用Batch Norm来实现。如下面的网络结构:
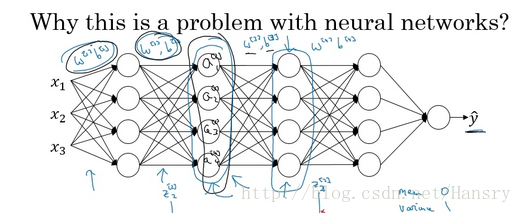
网络的目的是不断的训练,最后训练出一个更加接近于真实值的 yˆy^,现在以第2个隐藏层为输入来看:
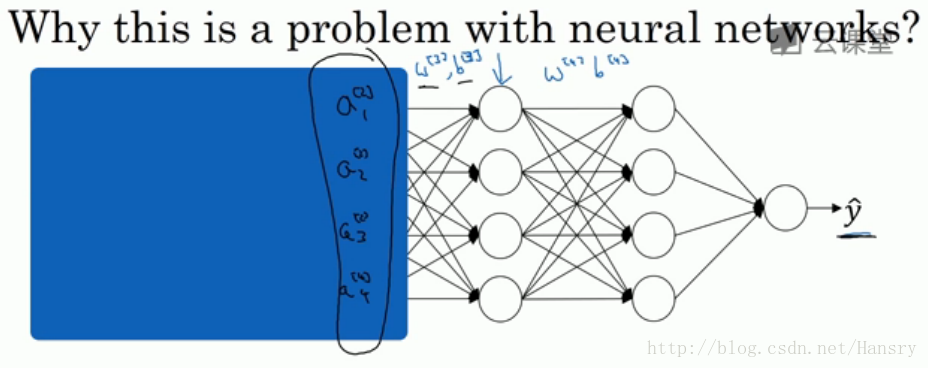
对于后面的神经网络,是以第二层隐层的输出值a[2]作为输入特征的,通过前向传播得到最终的y^,但是因为我们的网络还有前面两层,由于训练过程,参数w[1],w[2]是不断变化的,那么也就是说对于后面的网络,a[2]的值也是处于不断变化之中,所以就有了Covariate shift的问题。
那么如果对z[2]使用了Batch Norm,那么即使其值不断的变化,但是其均值和方差却会保持。那么Batch Norm的作用便是其限制了前层的参数更新导致对后面网络数值分布程度的影响,使得输入后层的数值变得更加稳定。另一个角度就是可以看作,Batch Norm 削弱了前层参数与后层参数之间的联系,使得网络的每层都可以自己进行学习,相对其他层有一定的独立性,这会有助于加速整个网络的学习。
Batch Norm 正则化效果
这是因为在使用Mini_batch的时候,由于是对部分的数据集进行的计算,这样子均值和方差就会带来噪声(这里可以理解为对整个数据集而言有些不准),则计算得到的 Z˜[l]Z~[l] 则会带来一定的噪声。所以和Dropout相似,其在每个隐藏层的激活值上加入了一些噪声,(这里因为Dropout以一定的概率给神经元乘上0或者1)。所以和Dropout相似,Batch Norm 也有轻微的正则化效果。
这里引入一个小的细节就是,如果使用Batch Norm ,那么使用大的Mini-batch如256,相比使用小的Mini-batch如64,会引入跟少的噪声,那么就会减少正则化的效果。
7.测试时的 Batch Norm
训练过程中,我们是在每一个Mini-batch 使用 Batch Norm,来计算所需要的均值和方差,从而归一化,但是在测试的时候,我们需要对每一个样本进行预测,无法进行均值和方差的计算。同样的道理,就像我们在训练的时候,可以得到权重W和偏置b,但是我们在测试的时候,则是通过这些参数来进行预测,而无法求出测试样本所对应的W和b。
实际上,为了将神经网络用于预测,那么我们需要单独进行估算均值和方差。通常的方法是利用指数加权平均来进行估算,然后这个平均数涵盖了所有mini-batch。
假如我们选择 L 层,然后有mini_batch : X[1],X[2]X[1],X[2] , …
那么在为L层训练 X[1],X[2]X[1],X[2](第一个mini_batch) 的时候,我们得到了均值 u[1]u[1], 训练 X[1],X[2]X[1],X[2](第二个 mini_batch) 的时候,我们得到了均值 u[1]u[1], 训练 X[1],X[2]X[1],X[2](第三个mini_batch) 的时候, 我们得到了均值 u[1]u[1], …. , 以此类推
对于以上的得出的 u[1]u[1], u[1]u[1] , u[1]u[1] , … , 我们可以通过指数加权平均的方法得到在这个L层的 u ,同样的也可以得出在这个L层的方差 σ2σ2 ,因此在用不同的mini_batch 进行训练的时候,其实得到的均值和方差都是不一样的。
总之,均值 u 和方差 σ2σ2 是在整个mini_batch 上计算出来的,即整个数据集,然后得到均值和方差后,再用到Batch Norm 公式的计算中,用以对样本的测试。
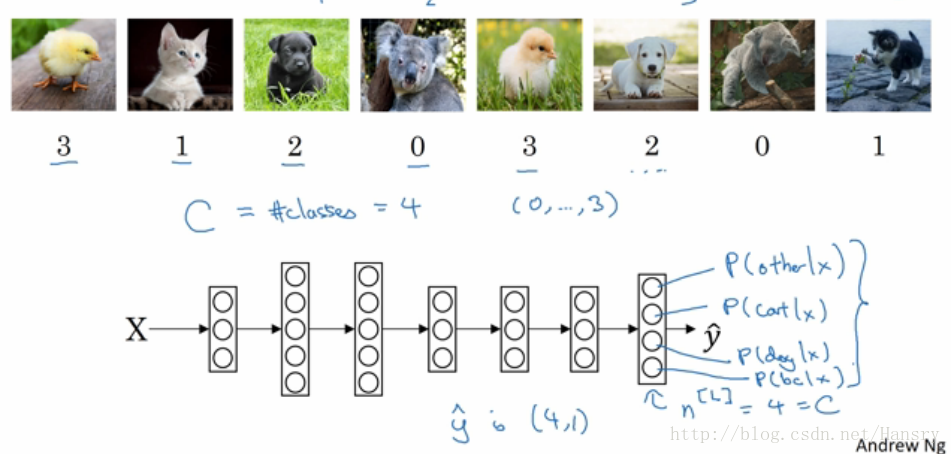
8.Soft 回归
在前面内容中,我们使用的都是二分类的,例如我们用来判断图片中是否存在有猫的情形,但是当我们的输入有很多分类,输出也希望是有多个分类,我们需要用到Softmax 回归。在以下图片中,我们把猫归为0类,把狗归为1类,把小鸟归为2类,其他为0类,用C来表示classification的个数,这里我们C=4,则我们在末端输出是一个 (4,1)的向量,当然这是在一个样本的情况下。 P(cat|x),P(other|x),P(dog|x),P(bird|x) 分别代表的是这些分类的概率。
Softmax 回归的步骤如下:
1.跟之前一样,我们求出线性回归, Z[L]=W[L]∗A[L−1]+b[L]Z[L]=W[L]∗A[L−1]+b[L] ,激活函数为 A[L]=eZ[L]A[L]=eZ[L](这里之所以用t,是因为我们需要归一化,得到(4,1)向量)
2.归一化处理t,得到 A[L]=eZ[L]∑ni=1eZ[L]iA[L]=eZ[L]∑i=1neiZ[L] (归一化目的是使得输出的元素之和为1)
4.从 A[L]=eZ[L]A[L]=eZ[L] 开始到输出 A^[L]为止,这一过程成为 Softmax 函数
Softmax 分类器还可以代表其他的什么东西呢?
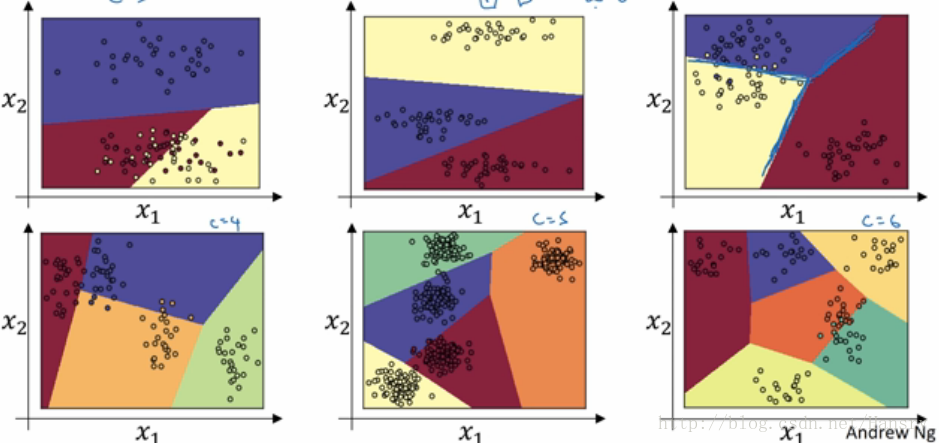
假如现在有俩个变量,x1,x2,我们将其直接输出到Softmax函数中,过程为:Z=W∗X+b,A=g(Z)Z=W∗X+b,A=g(Z) ,即没有中间的隐含层,所以决策边界是线性的,以下是不同C值(输出分类)决策边界。如果在中间增加更多隐含层,那么我们可以得到非线性决策边界。
9.训练一个 Softmax 分类器
对于Softmax 函数,其实是相对于 hardmax 而言的,Softmax 在向量中的值是用概率来表示的,而hardmax则是用0,1来表示的,如下图所示,对于hardmax 而言,概率大的则置1,概率较小的则置0,softmax 所做的从z 到这些概率的映射更为温和。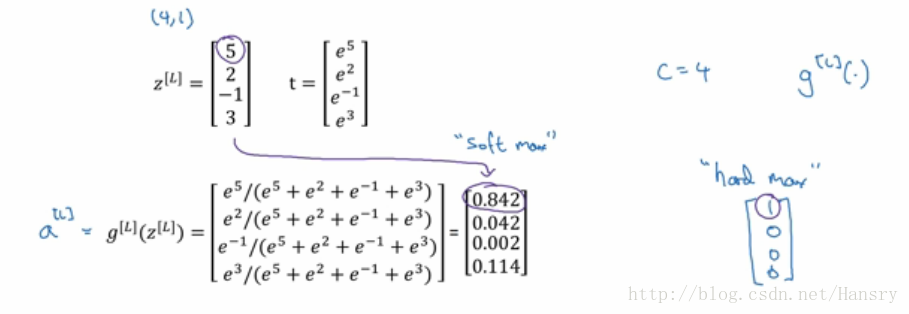
我们知道,Softmax 回归其实就是逻辑回归的一般式,当Softmax 回归的C 值变为 2的时候,其实就是Logistic 回归。虽然当Softmax 回归的C值为2 时,输入为俩个值,但是和为1,这跟计算一个值没有什么区别。
对于Softmax 而言,我们将使用什么样子的损失函数呢?
同样的,我们使用了最大似然的方法,对于一个样本而言,我们定义损失函数为:L(yˆ,y)=∑nxi=1(−ylog(yˆ))L(y^,y)=∑i=1nx(−ylog(y^)) ,对于多个样本而言,我们直接求出其和为: L(yˆ,y)whole=1m∗L(yˆ,y)L(y^,y)whole=1m∗L(y^,y)
如果要理解其意义,我们可以有 : 假设一个标签y为 (4,1)的一个向量, y=⎡⎣⎢⎢⎢0100⎤⎦⎥⎥⎥y=[0100] ,则我们实际上预测出来的是:yˆ=⎡⎣⎢⎢⎢0.30.20.10.4⎤⎦⎥⎥⎥y^=[0.30.20.10.4]
对于代价函数来说,在 y 为 0 的函数,loss function的那项其实都为0 ,我们需要的是计算的只有:−y2log(yˆ2)−y2log(y^2) ,由于 y2=1y2=1 ,那么我们可以得出,需要这个代价函数越小,则 yˆ2=1y^2=1 需要越大,符合逻辑。

相关文章推荐
- 第2次课改善深层神经网络:超参数优化、正则化以及优化 - week3 超参数调试、Batch正则化和程序框架
- 2.改善深层神经网络-第三周 超参数调试,batch正则化和程序框架
- Part 2 (三)超参数调试、batch正则化、程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达神经网络和深度学习课程自学笔记(七)之超参数调试,Batch正则化和程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 《深度学习Ng》课程学习笔记02week3——超参数调试、Batch正则化和程序框架
- 吴恩达《深度学习工程师》Part2.Week3 超参数调试、Batch正则化及程序框架
- 改善深度神经网络:超参数调试、正则化以及优化——实践方面(2-1)
- Coursera吴恩达《优化深度神经网络》课程笔记(3)-- 超参数调试、Batch正则化和编程框架
- DeepLearning.ai学习笔记(二)改善深层神经网络:超参数调试、正则化以及优化--week3 超参数调试、Batch正则化和程序框架