1.1 Redis数据类型
Redis数据类型:Redis使用key/value格式存储数据,其中key的类型永远是string,而value的类型非常丰富;
常用的数据类型:
string:存储字符串(最基础的数据类型,二进制的文件(图片、视频)512M)
list:是一个集合,可以在头部或者尾部操作数据
hash(Map):采用键值对存储
set:无序不可重复的集合
SortedSet:使用score来排序的集合
HyperLogLog结构(redis2.8.9版本之后才有,用来做基数统计的算法。)
1.2 string类型
最为基础的数据存储类型。在Redis中字符串类型的Value最多可以容纳的数据长度是512M。
redis中没有使用C语言的字符串表示,而是自定义一个数据结构叫SDS(simple dynamic string)即简单动态字符串。
打开下载的redis源码包,找到src下的sds.h文件查看sds源码:
struct sdshdr {//字符串长度
unsignedint len;
//buf数组中未使用的字节数量
unsignedint free;
//用于保存字符串
char buf[];
};
c语言对字符串的存储是使用字符数组,遇到'\0'字符则认为字符串结束,
redis的字符串可以存储任何类型的数据,因为任何类型数据都可以表示成二进制,sds结构中的char buf[]就是存储了二进制数据。
redis的字符串是二进制安全的,什么是二进制安全?简单理解就是存入什么数据取出的还是什么数据。
redis中的sds不像c语言处理字符串那样遇到'\0'字符则认证字符串结束,
它不会对存储进去的二进制数据进行处理,存入什么数据取出还是什么数据。
| 命令 | 描述 | 例子 |
| Set | 赋值 | SET key value |
| Get | 获取值 | GET key |
| APPEND | 追加字符串 | APPEND key value |
| DECR | 减少值 | DECR key |
| INCR | 增加值 | INCR key |
| DECRBY | 设置减少数值的步长 | DECRBY key decrement |
| INCRBY | 设置增加数值的步长 | INCRBY key increment |
| GETSET | 先获取值再赋值 | GETSET key value |
| STRLEN | 返回key的长度 | STRLEN key |
| SETEX | 设置key在服务器中存在的时间 | SETEX key seconds value |
| SETNX | Key不存在设置值,否则不做操作 | SETNX key value |
| SETRANGE | 字符串替换 | SETRANGE key start "value" |
| GETRANGE | 截取字符串 | GETRANGE key start end |
| SETBIT | 设置二进制的值 | SETBIT key offset value |
| GETBIT | 获取二进制的值 | GETBIT key offset |
| MGET | 返回多个key的值 | MGET key [key ...] |
| MSET | 设置多个key、value | MSET key value [key value ...] |
| MSETNX | Key不存在设置多个key、value值,否则不做操作 | MSETNX key value [key value ...] |
String应用:自增主键
商品编号、订单号采用string的递增数字特性生成。
定义商品编号key:items:id
192.168.101.3:7003> INCR items:id
(integer)2
192.168.101.3:7003> INCR items:id
(integer)3
1.3 list类型
List类型是按照插入顺序排序的字符串链表。可以在链表的两头插入或删除元素,List中可以包含的最大元素数量是4294967295。
列表类型(list)可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。
列表类型内部是使用双向链表(double linked list)实现的,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。
这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。
1.3.1 ArrayList与LinkedList的区别
ArrayList使用数组方式存储数据,所以根据索引查询数据速度快,而新增或者删除元素时需要设计到位移操作,所以比较慢。 LinkedList使用双向链接方式存储数据,每个元素都记录前后元素的指针,所以插入、删除数据时只是更改前后元素的指针指向即可,速度非常快,然后通过下标查询元素时需要从头开始索引,所以比较慢,但是如果查询前几个元素或后几个元素速度比较快。
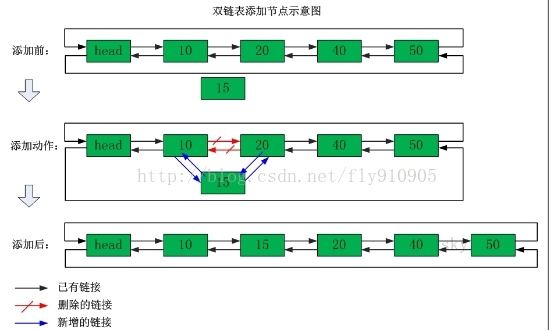
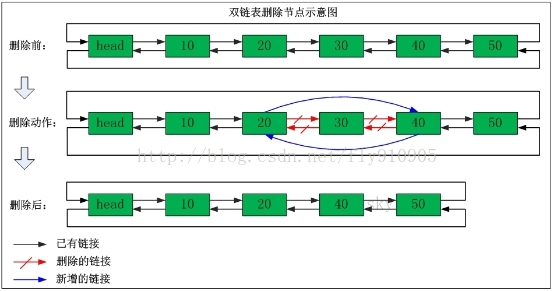
| 命令 | 描述 | 例子 |
| LPUSH | 在list头部添加多个值 | LPUSH key value [value ...] |
| LPUSHX | Key存在则添加值,否则不做操作 | LPUSHX key value |
| LRANGE | 遍历list中key数据 | LRANGE key start stop |
| LPOP | 从头部弹出key中的值 | LPOP key |
| LLEN | 返回key的长度 | LLEN key |
| LREM | 删除前面几个值等于某值得元素 | LREM key count value |
| LSET | 给下标赋值 | LSET key index value |
| LINDEX | 返回下标中的值 | LINDEX key index |
| LTRIM | 截取list中的值 | LTRIM key start stop |
| LINSERT | 在某个值的前面或者后面插入值 | LINSERT key BEFORE|AFTER pivot value |
| RPUSH | 在list尾部添加多个值 | RPUSH key value [value ...] |
| RPUSHX | 在list尾部添加单个值 | RPUSHX key value |
| RPOP key | 从尾部弹出值 | RPOP key |
| RPOPLPUSH | 从一个集合尾部弹出值插入到里一个集合的头部 | RPOPLPUSH source destination |
list应用:在redis中创建商品评论列表
用户发布商品评论,将评论信息转成json存储到list中。
用户在页面查询评论列表,从redis中取出json数据展示到页面。
定义商品评论列表key:
商品编号为1001的商品评论key:items: comment:1001
192.168.101.3:7001> LPUSH items:comment:1001'{"id":1,"name":"商品不错,很好!!","date":1430295077289}'1.4 hash类型
使用string的问题
假设有User对象以JSON序列化的形式存储到Redis中,User对象有id,username、password、age、name等属性,存储的过程如下:
保存、更新:
User对象 --->json(string) ---> redis
如果在业务上只是更新age属性,其他的属性并不做更新我应该怎么做呢?
如果仍然采用上边的方法在传输、处理时会造成资源浪费,下边讲的hash可以很好的解决这个问题。
hash叫散列类型,它提供了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、集合类型等其它类型。如下:
Hash类型可以看成具有StringKey和StringValue的map容器。非常适合于存储值对象的信息。如Username、Password和Age等。
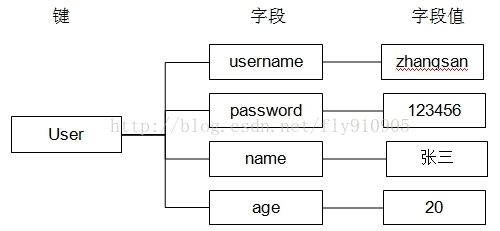
| 命令 | 描述 | 例子 |
| HSET | 给key中filed字段赋值[HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0.] | HSET key field value |
| HGET | 获取key中filed的值 | HGET key field |
| HEXISTS | 判断filed是否存在 | HEXISTS key field |
| HLEN | 获取key 的长度 | HLEN key |
| HDEL | 删除file字段[可以删除一个或多个字段,返回值是被删除的字段个数 ] | HDEL key field [field ...] |
| HSETNX | 如果filed不存在时赋值否则不做操作 | HSETNX key field value |
| HINCRBY | 给filed增加步长 | HINCRBY key field increment |
| HGETALL | 获取所有的filed和value | HGETALL key |
| HKEYS | 获取key | HKEYS key |
| HVALS | 获取value | HVALS key |
| HMGET | 获取所有filed字段的值 | HMGET key field [field ...] |
| HMSET | 设置多个filed字段value | HMSET key field value [field value ...] |
hash应用商品信息
商品id、商品名称、商品描述、商品库存、商品好评
定义商品信息的key:
商品1001的信息在 redis中的key为:items:1001
存储商品信息
192.168.101.3:7003> HMSET items:1001 id 3 name apple price 999.9
OK
获取商品信息
192.168.101.3:7003> HGET items:1001 id
"3"
192.168.101.3:7003> HGETALL items:1001
1)"id"
2)"3"
3)"name"
4)"apple"
5)"price"
6)"999.9"
1.5 set类型
集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在等,
由于集合类型的Redis内部是使用值为空的散列表实现,所有这些操作的时间复杂度都为0(1)。
Set类型看作为没有排序的字符集合,Set集合中不允许出现重复的元素,redis可以在服务器端完成多个Sets之间的计算操作,
如unions、intersections和differences。
这些操作均在服务端完成,因此效率极高,而且也节省了大量的网络IO开销
| 命令 | 描述 | 例子 |
| SADD | 添加值 | SADD key member [member ...] |
| SMEMBERS | 遍历集合 | SMEMBERS key |
| SCARD | 获取key的成员数量 | SCARD key |
| SISMEMBER | 判断成员是否存在 | SISMEMBER key member |
| Spop | 随机弹出值 | Spop key |
| SREM | 删除指定的成员 | SREM key member [member ...] |
| SRANDMEMBER | 随机返回成员,不删除原值 | SRANDMEMBER key |
| SMOVE | 移动一个集合的成员到另一个集合 | SMOVE source destination member |
| SDIFF | 求集合差集 | SDIFF key [key ...] 【属于A并且不属于B的元素构成的集合】SDIFF key [key ...]127.0.0.1:6379> sadd setA 1 2 3(integer) 3127.0.0.1:6379> sadd setB 2 3 4(integer) 3127.0.0.1:6379> sdiff setA setB 1) "1"127.0.0.1:6379> sdiff setB setA 1) "4" |
| SDIFFSTORE | 集合中的差集存储到新集合中 | SDIFFSTORE destination key [key ...] |
| SINTER | 求集合交集 | SINTER key [key ...]【属于A且属于B的元素构成的集合】SINTER key [key ...]127.0.0.1:6379> sinter setA setB 1) "2"2) "3" |
| SINTERSTORE | 将集合交集存储到新集合 | SINTERSTORE destination key [key ...] |
| SUNION | 求集合并集 | SUNION key [key ...]【属于A或者属于B的元素构成的集合(去重)】SUNION key [key ...]127.0.0.1:6379> sunion setA setB1) "1"2) "2"3) "3"4) "4" |
| SUNIONSTORE | 将集合的并集存储到新集合 | SUNIONSTORE destination key [key ...] |
1.6 sortedset类型
不允许出现重复的元素,每一个成员都会有一个分数(score)与之关联,用分数来进行排序,分数是可以重复的
在集合类型的基础上有序集合类型为集合中的每个元素都关联一个分数,
这使得我们不仅可以完成插入、删除和判断元素是否存在在集合中,
还能够获得分数最高或最低的前N个元素、获取指定分数范围内的元素等与分数有关的操作。
在某些方面有序集合和列表类型有些相似。
1、二者都是有序的。
2、二者都可以获得某一范围的元素。
但是,二者有着很大区别:
1、列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会变慢。
2、有序集合类型使用散列表实现,所有即使读取位于中间部分的数据也很快。
3、列表中不能简单的调整某个元素的位置,但是有序集合可以(通过更改分数实现)
4、有序集合要比列表类型更耗内存。
| 命令 | 描述 | 例子 |
| ZADD | 添加排序成员 | ZADD key score member [score] [member] |
| ZCARD | 获取成员数量 | ZCARD key |
| ZCOUNT | 获取分数在min和max之间成员有多少个 | ZCOUNT key min max |
| ZINCRBY | 增加指定成员的分数 | ZINCRBY key increment member【增加某个元素的分数,返回值是更改后的分数】 |
| ZRANGE | 遍历成员以及分数 | ZRANGE key start stop [WITHSCORES]【获得排名在某个范围的元素列表 ZRANGE key start stop [WITHSCORES]照元素分数从小到大的顺序返回索引从start到stop之间的所有元素(包含两端的元素)】【ZREVRANGE key start stop [WITHSCORES]照元素分数从大到小的顺序返回索引从start到stop之间的所有元素(包含两端的元素)】如果需要获得元素的分数的可以在命令尾部加上WITHSCORES参数 |
| ZRANGEBYSCORE | 返回分数在min和max之间的成员和分数 | ZRANGEBYSCORE key min max [WITHSCORES] |
| ZRANK | 返回成员的下标 | ZRANK key member |
| ZREM | 删除指定成员 | ZREM key member [member ...] |
| ZREVRANGE | 遍历成员以及分数从大到小 | ZREVRANGE key start stop [WITHSCORES] |
| ZREVRANK | 返回成员下标顺序从大到小 | ZREVRANK key member |
| ZSCORE | 获取指定成员的分数 | ZSCORE key member |
| ZREVRANGEBYSCORE | 获取成员以及分数按照从高到低 | ZREVRANGEBYSCORE key max min [WITHSCORES] |
| ZREMRANGEBYRANK | 删除下标之间的数据 | ZREMRANGEBYRANK key start stop |
| ZREMRANGEBYSCORE | 删除分数在min和max中的成员 | ZREMRANGEBYSCORE key min max |
sortedset应用
商品销售排行榜
根据商品销售量对商品进行排行显示,定义sorted set集合,商品销售量为元素的分数。
定义商品销售排行榜key:items:sellsort
写入商品销售量:
商品编号1001的销量是9,商品编号1002的销量是10
192.168.101.3:7007> ZADD items:sellsort 91001101002
商品编号1001的销量加1
192.168.101.3:7001> ZINCRBY items:sellsort 11001
商品销量前10名:
192.168.101.3:7001> ZRANGE items:sellsort 09 withscores
1.7 redis对于key的应用。
使用对key的操作,通常可以用来维护数据
| 命令 | 描述 | 例子 |
| KEYS | 获取所有的key | KEYS pattern [如:Keys * ] |
| Del | 删除指定的key | DEL key [key ...] |
| EXISTS | 判断key是否存在 | EXISTS key |
| MOVE | 移动一个key到另一个库中 | MOVE key db |
| RENAME | 给key从新命名 | RENAME key newkey |
| RENAMENX | 修改key的名字 | RENAMENX key newkey |
| PERSIST | 持久化key | PERSIST key |
| EXPIRE | 设置key存活时间 | EXPIRE key seconds |
| EXPIREAT | 设置key存活时间(年月日) | EXPIREAT key timestamp |
| TTL | 实时查看key存活时间 | TTL key |
| RANDOMKEY | 随机返回一个key | RANDOMKEY |
| TYPE | 查看key的中value数据类型 | TYPE key |
| SELECT | 进入指定库 | SELECT NUM |
1.8服务器命令
| 命令 | 描述 | 例子 |
| ping | 测试连接是否存活 | //执行下面命令之前,我们停止redis 服务器redis 127.0.0.1:6379> pingCould not connect to Redis at 127.0.0.1:6379: Connection refused//执行下面命令之前,我们启动redis 服务器not connected> pingPONGredis 127.0.0.1:6379>第一个ping 时,说明此连接正常第二个ping 之前,我们将redis 服务器停止,那么ping 是失败的第三个ping 之前,我们将redis 服务器启动,那么ping 是成功的 |
| echo | 在命令行打印一些内容 | 在命令行打印一些内容redis 127.0.0.1:6379> echo HongWan"HongWan" |
| select | 选择数据库。Redis 数据库编号从0~15,我们可以选择任意一个数据库来进行数据的存取。 | 选择数据库。Redis 数据库编号从0~15,我们可以选择任意一个数据库来进行数据的存取。redis 127.0.0.1:6379> select 1OKredis 127.0.0.1:6379[1]> select 16(error) ERR invalid DB indexredis 127.0.0.1:6379[16]>当选择16 时,报错,说明没有编号为16 的这个数据库 |
| quit | 退出连接。 | redis 127.0.0.1:6379> quit |
| dbsize | 返回当前数据库中key 的数目。 | redis 127.0.0.1:6379> dbsize(integer) 18redis 127.0.0.1:6379>结果说明此库中有18 个key |
| info | 获取服务器的信息和统计。 | redis 127.0.0.1:6379> inforedis_version:2.2.12redis_git_sha1:00000000redis_git_dirty:0arch_bits:32multiplexing_api:epollprocess_id:28480uptime_in_seconds:2515uptime_in_days:0。。。。。。。。 |
| flushdb | 删除当前选择数据库中的所有key。 | redis 127.0.0.1:6379> dbsize(integer) 18redis 127.0.0.1:6379> flushdbOKredis 127.0.0.1:6379> dbsize(integer) 0redis 127.0.0.1:6379>在本例中我们将0 号数据库中的key 都清除了。 |
| flushall | 删除所有数据库中的所有key | redis 127.0.0.1:6379[1]> dbsize(integer) 1redis 127.0.0.1:6379[1]> select 0OKredis 127.0.0.1:6379> flushallOKredis 127.0.0.1:6379> select 1OKredis 127.0.0.1:6379[1]> dbsize(integer) 0redis 127.0.0.1:6379[1]>在本例中我们先查看了一个1 号数据库中有一个key,然后我切换到0 号库执行flushall 命令,结果1 号库中的key 也被清除了,说是此命令工作正常。 |
