Redis-Scrapy分布式爬虫:当当网图书为例
2017-11-08 20:54
316 查看
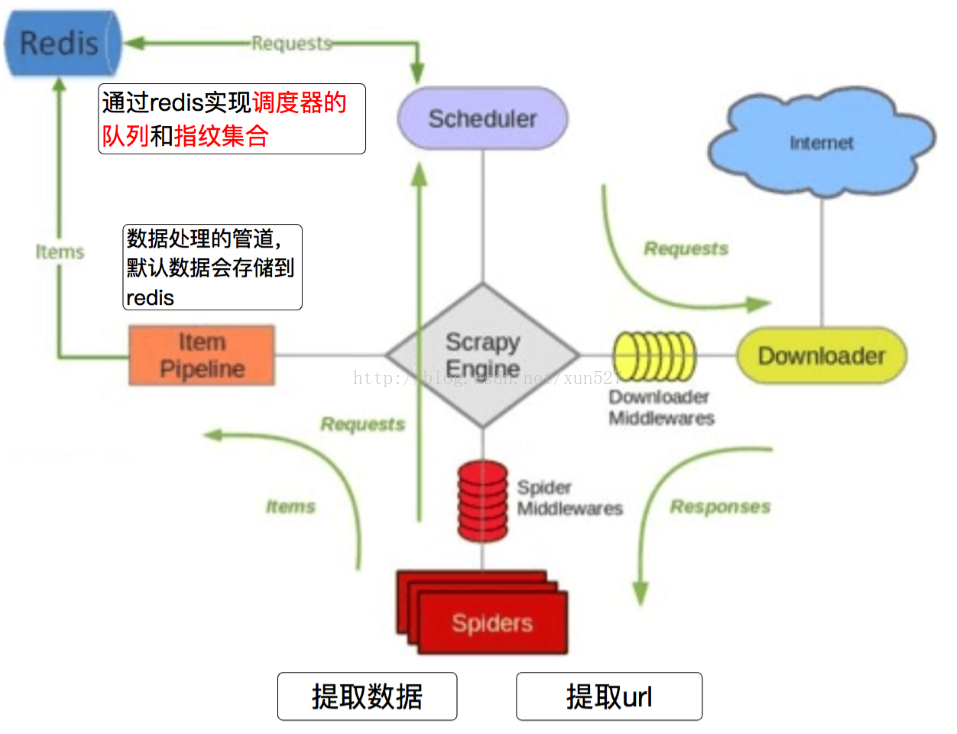
Scrapy-Redis分布式策略:
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:reqeust去重,爬虫持久化,和轻松实现分布式
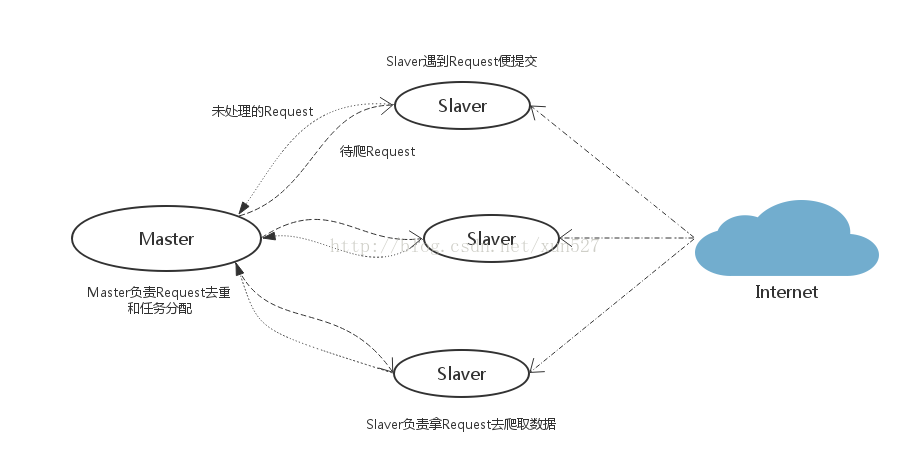
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
Slaver端(爬虫程序执行端) :使用 Mac OS X 、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
当当网图书信息抓取案例:
1、创建Scrapy项目
使用全局命令startproject创建项目,创建新文件夹并且使用命令进入文件夹,创建一个名为jingdong的Scrapy项目。
[python] view
plain copy
scrapy startproject dangdang
2.使用项目命令genspider创建Spider
[python] view
plain copy
scrapy genspider dangdang dangdang.com
3、发送请求,接受响应,提取数据
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
from copy import deepcopy
class DangdangSpider(RedisSpider):
name = 'dangdang'
allowed_domains = ['dangdang.com']
# start_urls = ['http://book.dangdang.com/']
redis_key = "dangdang"
def parse(self, response):
div_list = response.xpath("//div[@class='con flq_body']/div")
# print(len(div_list),"("*100)
for div in div_list:#大分类
item = {}
item["b_cate"] = div.xpath("./dl/dt//text()").extract()
#中间分类
dl_list = div.xpath("./div//dl[@class='inner_dl']")
# print(len(dl_list),")"*100)
for dl in dl_list:
item["m_cate"] = dl.xpath("./dt/a/text()").extract_first()
#获取小分类
a_list = dl.xpath("./dd/a")
# print("-"*100,len(a_list))
for a in a_list:
item["s_cate"] = a.xpath("./@title").extract_first()
item["s_href"] = a.xpath("./@href").extract_first()
if item["s_href"] is not None:
yield scrapy.Request( #发送图书列表页的请求
item["s_href"],
callback=self.parse_book_list,
meta = {"item":deepcopy(item)}
)
def parse_book_list(self,response):
item = response.meta["item"]
li_list = response.xpath("//ul[@class='bigimg']/li")
for li in li_list:
item["book_title"] = li.xpath("./a/@title").extract_first()
item["book_href"] = li.xpath("./a/@href").extract_first()
item["book_detail"] = li.xpath("./p[@class='detail']/text()").extract_first()
item["book_price"] = li.xpath(".//span[@class='search_now_price']/text()").extract_first()
item["book_author"] = li.xpath("./p[@class='search_book_author']/span[1]/a/@title").extract_first()
item["book_publish_date"] = li.xpath("./p[@class='search_book_author']/span[2]/text()").extract_first()
item["book_press"] = li.xpath("./p[@class='search_book_author']/span[3]/a/@title").extract_first()
print(item)
4.pipelines设置保存文件:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class BookPipeline(object): def process_item(self, item, spider): item["book_name"] = item["book_name"].strip() if item["book_name"] is not None else None item["book_publish_date"] = item["book_publish_date"].strip() if item["book_publish_date"] is not None else None print(item) # return item
5.配置settings设置,文件保存在redis中:
注意:setting中的配置都是可以自己设定的,意味着我们的可以重写去重和调度器的方法,包括是否要把数据存储到redis(pipeline)view
plain cop
# -*- coding: utf-8 -*-
# Scrapy settings for book project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'book'
SPIDER_MODULES = ['book.spiders']
NEWSPIDER_MODULE = 'book.spiders'
#实现scrapyredis的功能,持久化的功能
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
REDIS_URL = "redis://127.0.0.1:6379"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = {
# 'book.middlewares.BookSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = {
# 'book.middlewares.MyCustomDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html #EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = {
'book.pipelines.BookPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
6.进行爬取:执行项目命令crawl,启动Spider:
[python] view
plain copy
scrapy crawl dangdang
注意:setting中的配置都是可以自己设定的,意味着我们的可以重写去重和调度器的方法,包括是否要把数据存储到redis(pipeline)] view
plain cop

相关文章推荐
- 使用scrapy-redis实现分布式爬虫
- 使用scrapy,redis, mongodb实现的一个分布式网络爬虫
- Scrapy爬虫(5)爬取当当网图书畅销榜
- Scrapy基于scrapy_redis实现分布式爬虫部署
- scrapy-redis实现爬虫分布式爬取分析与实现
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
- 基于Python,scrapy,redis的分布式爬虫实现框架
- scrapy-redis 更改队列和分布式爬虫
- 基于Python+scrapy+redis的分布式爬虫实现框架
- (5)分布式下的爬虫Scrapy应该如何做-windows下的redis的安装与配置
- Scrapy爬虫(5)爬取当当网图书畅销榜
- Scrapy-redis爬虫分布式爬取的分析和实现
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
- 基于scrapy和redis的分布式爬虫环境搭建
- scrapy-redis实现爬虫分布式爬取分析与实现
- scrapy-redis实现爬虫分布式爬取分析与实现
- Python之Scrapy框架Redis实现分布式爬虫详解
- 爬虫必备—scrapy-redis(分布式爬虫)
- scrapy-redis分布式爬虫原理分析