opencv(c++)图像处理(imgproc模块)[2]
2017-11-07 14:38
836 查看
参考:
1、https://docs.opencv.org/3.2.0/
2、https://github.com/opencv/opencv/
根据像素值的范围检测对象
在本教程中,我们将学习如何使用cv :: inRange函数来做到这一点。
这个概念保持不变,但现在我们添加一个我们需要的像素值的范围。
创建两个矩阵元素来存储帧
从默认捕获设备捕获视频流。
创建一个窗口来显示默认框架和阈值框架。
创建轨迹条来设置RGB值的范围
在用户希望程序退出之前,请执行以下操作
显示图像
对于控制范围较低的轨迹栏,例如Red值:
对于控制上限的轨迹栏,例如红色值:
有必要找到最大值和最小值,以避免阈值的高值变得低于低值的差异。

将内核锚放置在确定的像素顶部,内核的其余部分覆盖图像中相应的局部像素。
将核系数乘以相应的图像像素值并对结果进行求和。
将结果放置在输入图像中的锚点的位置。
通过在整个图像上扫描内核重复所有像素的过程。
用等式的形式表示上述过程,我们可以得到:
H(x,y) = ∑Mi−1i=0∑Mj−1j=0I(x+i−ai,y+j−aj)K(i,j)
幸运的是,OpenCV为您提供了函数cv :: filter2D,所以您不必编写所有这些操作。
加载图像
执行规范化的框过滤器。 例如,对于大小size=3的内核,内核将是:
K= 13⋅3⎡⎣⎢111111111⎤⎦⎥
程序将执行大小为3,5,7,9和11的内核的过滤操作。
过滤器输出(每个内核)将在500毫秒内显示
2、教程代码的显示如下。 您也可以从这里下载
2、初始化线性滤波器的参数
3、执行更新内核大小的无限循环,并将线性滤波器应用于输入图像。 我们来更详细地分析一下:
4、首先我们定义我们的过滤器将要使用的内核。 这里是:
第一行是将kernel_size更新为范围内的奇数值:[3,11]。 第二行实际上是通过将它的值设置为一个用1填充的矩阵并通过将其除以元素数来规范它来建立内核。
5、设置内核之后,我们可以使用函数cv :: filter2D生成过滤器:
参数表示:
src:源图像
dst:目标图像
ddepth:dst的深度。 负值(如-1)表示深度与源相同。
内核:要通过映像扫描的内核
anchor:锚点相对于其内核的位置。 位置点(-1,-1)默认显示中心。
delta(增量):在卷积过程中要添加到每个像素的值。 默认情况下它是0
BORDER_DEFAULT:我们默认设置这个值(在下面的教程中有更多的细节)
6、我们的程序将实现一个while循环,每500 ms,我们的过滤器的内核大小将在指定的范围内更新。
大多数OpenCV函数做的是将给定的图像复制到另一个稍大的图像,然后自动填充边界(通过下面示例代码中解释的任何方法)。
这样,卷积可以在没有问题的情况下在所需的像素上执行(在完成操作之后,额外的填充被切掉)。
在本教程中,我们将简要介绍两种为图像定义额外填充(边框)的方法:
BORDER_CONSTANT:用一个常量值(即黑色或0)填充图像
BORDER_REPLICATE:将原始边缘处的行或列复制到额外边框。 代码部分将更清楚地看到这一点。
加载图像
让用户选择在输入图像中使用什么样的填充。 有两个选项:
常量值边框:为整个边框应用一个常量值的填充。 该值将每0.5秒随机更新一次。
复制的边框:将从原始图像边缘的像素值复制边框。 用户通过按’c’(常数)或’r’(复制)选择任一选项,
程序结束时,用户按下“ESC”
2、教程代码的显示如下。 您也可以从这里下载
特别值得注意的是随机数发生器的变量rng。 我们用它来生成随机的边框颜色,我们很快就会看到。
2、像往常一样,我们加载我们的源图像src:
3、在介绍如何使用该程序之后,我们创建一个窗口:
4、现在我们初始化定义边界大小的参数(顶部,底部,左侧和右侧)。 我们给他们一个src大小的5%的值。
5、该程序运行在一个for循环。 如果用户按下“c”或“r”,borderType变量分别取BORDER_CONSTANT或BORDER_REPLICATE的值:
6、在每次迭代中(0.5秒后),变量值被更新…
与由RNG变量rng生成的随机值进行比较。 该值是在[0,255]范围内随机选取的数字,
7、最后,我们调用函数cv :: copyMakeBorder来应用相应的填充:
参数是:
src:源图像
dst:目标图像
top, bottom, left, right:图像两侧边框的长度(以像素为单位)。 我们将它们定义为图像原始大小的5%。
borderType:定义应用的边界类型。 这个例子可以是常量或复制。
value :如果borderType是BORDER_CONSTANT,则这是用来填充边界像素的值。
8、我们在之前创建的图像中显示我们的输出图像
使用OpenCV函数cv :: Scharr来为大小为3⋅3的内核计算更精确的导数
2、为什么图像中导数的微积分可能很重要? 让我们想象我们想要检测图像中存在的边缘。 例如:

你可以很容易地注意到,在一个边缘,像素的强度以一种显著的方式变化。 表达变化的好方法是使用导数工具。 梯度的高度变化表示图像的主要变化。
3、为了图形化,我们假设我们有一维图像。 在下图中,边缘由强度的“跳跃”表示:

4、如果我们采用一阶导数(实际上,这里显示为最大值),则可以更容易地看到边缘“跳跃”

5、所以,从上面的解释中,我们可以推断出一种检测图像中边缘的方法可以通过定位梯度高于其邻域(或推广,高于阈值)的像素位置来执行。
6、更详细的解释请参考Bradski和Kaehler学习OpenCV
Sobel算子结合了高斯平滑和差分。
1、我们计算两个导数:
水平变化:这是通过将I与具有奇数大小的内核Gx进行卷积来计算的。 例如,对于3的内核大小,Gx将被计算为:
Gx =⎡⎣⎢−1−2−1000+1+2+1⎤⎦⎥∗I
垂直变化:这是通过将I与具有奇数大小的内核Gy进行卷积来计算的。 例如,对于3的内核大小,Gy将被计算为:
Gy = ⎡⎣⎢−10+1−20+2−10+1⎤⎦⎥∗I
2、在图像的每个点上,我们通过结合上面的两个结果来计算该点上的渐变的近似值:
G = G2x+G2y−−−−−−−√
尽管有时会使用以下更简单的公式:
G = |Gx|+|Gy|
注:
当内核大小为3时,上面显示的Sobel内核可能会产生明显的不准确性(毕竟,Sobel只是导数的近似值)。 OpenCV通过使用cv :: Scharr函数来解决大小为3的内核的这种不准确性。 这与标准的Sobel功能一样快,但更准确。 它实现了以下内核:
Gx = ⎡⎣⎢−3−10−3000+3+10+3⎤⎦⎥
Gy = ⎡⎣⎢−30+3−100+10−30+3⎤⎦⎥
您可以在OpenCV参考(cv :: Scharr)中查看该函数的更多信息。 另外,在下面的示例代码中,您会注意到在cv :: Sobel函数的代码之上还有cv :: Scharr函数注释的代码。 取消注释(并明显评论Sobel的东西)应该给你一个这个功能如何工作的想法。
应用Sobel算子,并在较暗的背景上产生检测到边缘明亮的图像。
2、教程代码的显示如下。 您也可以从这里下载
2、像往常一样,我们加载我们的源图像src:
3、首先,我们将cv :: GaussianBlur应用于图像,以减少噪声(内核大小= 3)
4、现在我们将我们过滤的图像转换成灰度图:
5、其次,我们计算x和y方向上的“导数”。 为此,我们使用函数cv :: Sobel,如下所示:
该函数采用以下参数:
src_gray:在我们的例子中,输入图像。 这是CV_8U
grad_x / * grad_y *:输出图像。
ddepth:输出图像的深度。 我们将其设置为CV_16S以避免溢出。
x_order:x方向的导数的阶数。
y_order:y方向上的导数的阶数。
scale,delta 和BORDER_DEFAULT:我们使用默认值。
请注意,要计算x方向上的梯度,我们使用:xorder = 1和yorder= 0。 我们做类似的y方向。
6、我们将部分结果转换回CV_8U:
7、最后,我们尝试通过添加两个方向梯度来近似梯度(请注意,这根本不是一个精确的计算,但它对我们的目的是有利的)。
8、最后,我们展示我们的结果:


2、而且…如果我们采用二阶导数会发生什么?

你可以观察到二阶导数是零! 所以,我们也可以使用这个标准来尝试检测图像中的边缘。 但是,请注意,零不仅会出现在边缘(它们实际上可能出现在其他无意义的位置)。 这可以通过在需要的地方应用过滤来解决。
2、拉普拉斯算子定义如下:
Laplace(f) = ∂2f∂x2+∂2f∂y2
3、拉普拉斯算子在OpenCV中由函数cv :: Laplacian实现。 实际上,由于拉普拉斯算子使用图像的梯度,所以它在内部调用Sobel算子来执行它的计算。
加载图像
应用高斯模糊消除噪声,然后将原始图像转换为灰度
将拉普拉斯算子应用于灰度图像并存储输出图像
在一个窗口中显示结果
2、教程代码的显示如下。 您也可以从这里下载
2、加载源图像:
3、应用高斯模糊来减少噪音:
4、使用cv :: cvtColor将图像转换为灰度
5、将拉普拉斯算子应用于灰度图像:
参数是:
src_gray:输入图像。
dst:目标(输出)图像
ddepth:目标图像的深度。 由于我们的输入是CV_8U,我们定义ddepth = CV_16S以避免溢出
kernel_size:内部应用的Sobel运算符的内核大小。 在这个例子中我们使用3。
scale,delta和BORDER_DEFAULT:我们将它们作为默认值。
6、将拉普拉斯算子的输出转换为CV_8U图像:
7、在窗口中显示结果:
低错误率:意味着仅存在边缘的良好检测。
良好的定位:检测到的边缘像素与真实的边缘像素之间的距离必须最小化。
最小响应:每条边只有一个检测器响应。
K = 1159⎡⎣⎢⎢⎢⎢⎢⎢245424912945121512549129424542⎤⎦⎥⎥⎥⎥⎥⎥
2、找到图像的强度梯度。 为此,我们遵循一个类似于Sobel的程序:
应用一对卷积掩膜(在x和y方向:
Gx= ⎡⎣⎢−1−2−1000+1+2+1⎤⎦⎥
Gy = ⎡⎣⎢−10+1−20+2−10+1⎤⎦⎥
通过以下方式查找梯度强度和方向:
G=G2x+G2y−−−−−−−√θ=arctan(GyGx)
方向被四舍五入为四个可能的角度之一(即0,45,90或135)
3、非最大抑制应用。 这将删除不被视为边缘一部分的像素。 因此,只有细线(候选边缘)将保留。
4、迟滞:最后一步。 Canny确实使用了两个阈值(上限和下限):
如果像素梯度高于阈值上限,则该像素被接受为边缘
如果像素梯度值低于下限,则拒绝。
如果像素梯度在两个阈值之间,那么只有当它连接到高于阈值上限的像素时才会被接受。
Canny建议上限:下限比例 在2:1和3:1之间。
5、欲了解更多详情,您可以随时咨询您最喜爱的计算机视觉书籍。
要求用户输入一个数值来设置Canny Edge Detector的下限(通过Trackbar)
应用Canny Detector并生成一个掩膜(亮线代表黑色背景上的边缘)。
应用在原始图像上获得的掩膜并将其显示在窗口中。
2、教程代码的显示如下。 您也可以从这里下载
请注意以下几点:
我们建立了一个比例下限:上限3:1(可变比例)
我们将内核大小设置为3(Sobel操作由Canny函数内部执行)
我们设置一个最大阈值下限为100。
2、加载源图像:
3、创建一个与src相同类型和大小的矩阵(即dst)
4、将图像转换为灰度(使用函数cv :: cvtColor:
5、创建一个窗口来显示结果
6、为用户创建一个跟踪栏,为我们的Canny探测器输入较低的阈值:
注意以下几点:
Trackbar控制的变量是lowThreshold,其限制为max_lowThreshold(我们之前设置为100)
Trackbar每次注册一个动作,就会调用回调函数CannyThreshold。
7、让我们一步一步检查CannyThreshold函数:
首先,我们用一个内核大小为3的滤镜来模糊图像:
其次,我们使用OpenCV函数cv :: Canny
参数是:
detected_edges:源图像,灰度
detected_edges:检测器的输出(可以与输入相同)
lowThreshold:用户移动轨迹栏输入的值
highThreshold:在程序中设置为下限阈值的三倍(按照Canny的建议)
kernel_size:我们将其定义为3(Sobel内核在内部使用的大小)
8、我们用零填充一个dst图像(意思是图像是完全黑色的)。
9、最后,我们将使用函数cv :: Mat :: copyTo来仅映射被识别为边缘的图像区域(在黑色背景上)。 cv :: Mat :: copy将src图像复制到dst。 但是,它只会复制具有非零值的位置的像素。 由于Canny检测器的输出是黑色背景上的边缘轮廓,因此得到的dst在所有区域中将是黑色的,但检测到的边缘是黑色的。
10、我们显示我们的结果:

为了应用变换,首先需要边缘检测预处理。
在笛卡尔坐标系中:参数:(m,b)。
在极坐标系中:参数:(r,θ)

对于霍夫变换,我们将在极坐标系中表示线。 因此,一个线性方程可以写成:
y =(−cosθsinθ)x+(rsinθ)
式中:r= xcosθ+ysinθ
①、一般而言,对于每个点(x0,y0),我们可以定义通过该点的线族:
rθ= x0⋅cosθ+y0⋅sinθ
这意味着每对(rθ,θ)代表通过(x0,y0)的每条线。
②、如果对于给定的(x0,y0)我们绘制经过它的线的族,我们得到一个正弦曲线。 例如,对于x0=8和y0=6,我们得到下面的图(在θ−r平面内):

我们只考虑r>0和0<θ<2π的点。
③、我们可以对图像中的所有点进行相同的操作。 如果两个不同点的曲线在θ−r平面上相交,就意味着两个点属于同一条直线。 例如,按照上面的例子,再画两点:x1=4,y1=9,x2=12,y2=3,得到:

这三个图相交于一个点(0.925,9.6),这些坐标是参数(θ,r)或(x0,y0),(x1,y1)和(x2,y2)所在的线。
④、上面所有的东西是什么意思? 这意味着一般情况下,可以通过查找曲线之间的交点数来检测线。越多的曲线相交意味着由该交点表示的线具有更多的点。 一般来说,我们可以定义检测线所需的最小交点数阈值。
⑤、这就是霍夫曲线变换所做的。 它跟踪图像中每个点的曲线之间的交集。 如果交点的数量超过某个阈值,则将其声明为交点的参数(θ,rθ)的一条直线。
1、 标准霍夫曲线变换
它几乎包含了我们在前一节中所解释的内容。 它给你一对向量(θ,rθ)
在OpenCV中,它使用函数cv :: HoughLines来实现
2、 概率霍夫曲线变换
霍夫线变换的更有效的实现。 它将检测到的线(x0,y0,x1,y1)的极值作为输出,
在OpenCV中,它使用函数cv :: HoughLinesP来实现
加载图像
应用标准Hough Line Transform或概率霍夫曲线变换。
在两个窗口中显示原始图像和检测线。
2、我们将解释的示例代码可以从这里下载。 可以在这里找到一个稍微更有趣的版本(显示Hough标准和带有改变阈值的trackbars的概率)。
2、通过使用Canny检测器来检测图像的边缘
现在我们将应用霍夫线变换。 我们将解释如何使用可用于此目的的OpenCV功能:
3、标准霍夫曲线变换
a、首先,你应用转换:
有以下参数:
dst:边缘检测器的输出。 它应该是一个灰度图像(虽然实际上它是一个二进制)
lines:将存储检测线的参数(r,θ)的矢量
rho:以像素为单位的参数r的分辨率。 我们使用1个像素。
θ:弧度参数θ的分辨率。 我们使用1度(CV_PI / 180)
阈值:“检测”线的最小交点数
srn和stn:默认参数为零。 查看OpenCV参考了解更多信息。
b、然后通过画线来显示结果。
4、概率霍夫线变换
a、首先你应用转换:
以下参数:
dst:边缘检测器的输出。 它应该是一个灰度图像(虽然实际上它是一个二进制)
lines:将存储检测到的行的参数(xstart,ystart,xend,yend)的向量
rho:以像素为单位的参数r的分辨率。 我们使用1个像素。
θ:弧度参数θ的分辨率。 我们使用1度(CV_PI / 180)
阈值:“检测”线的最小交点数
minLinLength:可以形成直线的最小点数。 少于这个点数的线被忽略。
maxLineGap:在同一行中考虑的两点之间的最大差距。
b、然后通过画线来显示结果。
5、显示原始图像和检测线:
6、等到用户退出程序
在线检测情况下,一条线由两个参数(r,θ)定义。 在圆的情况下,我们需要三个参数来定义一个圆:
C:(xcenter,ycenter,r)
其中(xcenter,ycenter)定义中心位置(绿色点),r是半径,这使得我们可以完全定义一个圆,如下所示:

为了提高效率,OpenCV实现的检测方法比标准霍夫曲线变换稍微复杂一些:Hough梯度法,它由两个主要阶段组成。 第一阶段涉及边缘检测和找到可能的圆心,第二阶段找到每个候选中心的最佳半径。 有关更多详细信息,请查阅学习OpenCV或您最喜爱的计算机视觉参考书目
加载图像并模糊图像以减少噪音
将Hough Circle Transform应用于模糊的图像。
在窗口中显示检测到的圆。
2、我们将解释的示例代码可以从这里下载。 稍微更漂亮的版本(显示改变阈值的轨迹栏)可以在这里找到。
2、转成灰度
3、应用中值滤波来减少噪音并避免错误的圆圈检测:
4、继续应用Hough Circle Transform:
以下参数:
gray:输入图像(灰度)。
circles:一个存储3个值的向量:对于每个检测到的圆圈,xc,yc,r。
HOUGH_GRADIENT:定义检测方法。 目前这是OpenCV中唯一可用的。
dp = 1:分辨率的反比。
min_dist = gray.rows / 16:检测到的中心之间的最小距离。
param_1 = 200:内部Canny边缘检测器的上阈值。
param_2 = 100 *:中心检测的阈值。
min_radius = 0:要检测的最小半径。 如果未知,则将默认设置为零。
max_radius = 0:要检测的最大半径。 如果未知,则将默认设置为零。
5、绘制检测到的圈子:
你可以看到,我们将绘制圆(红色)和中心(S)与一个小绿点
6、显示检测到的圆并等待用户退出程序:
为了完成映射过程,可能需要对非整数像素位置进行一些插值,因为在源图像和目的图像之间不总是有一对一的像素对应关系。
我们可以将每个像素位置(x,y)的重映射表示为:
g(x,y)=f(h(x,y))
其中g()是重映射后的图像,f()是源图像,h(x,y)是对(x,y)进行操作的映射函数。
让我们以一个简单的例子来思考。 想象一下,我们有一个图像,比方说,我们想要做一个重映射:
h(x,y)=(I.cols−x,y)
会发生什么? 很容易看到图像将在x方向上翻转。 例如,考虑输入图像:

观察红圈如何改变x的位置(考虑x的水平方向):

在OpenCV中,函数cv :: remap提供了一个简单的重映射实现。
加载图像
每秒钟,将4个不同的重映射过程中的1个应用于图像,并无限期地显示在窗口中。
等待用户退出程序
2、教程代码的显示如下。 您也可以从这里下载
2、加载图像
3、创建目标图像和两个映射矩阵(对于x和y)
4、创建一个窗口来显示结果
5、建立一个循环。 每1000毫秒我们更新我们的映射矩阵(mat_x和mat_y)并将它们应用到我们的源图像:
应用重映射的函数是cv :: remap。 我们给出以下参数:
src:源图像
dst:与src大小相同的目标图像
map_x:x方向的映射函数。 它相当于h(i,j)的第一个分量,
map_y:与上面相同,但在y方向。 请注意,map_y和map_x的大小都与src相同
INTER_LINEAR:用于非整数像素的插值类型。 这是默认的。
BORDER_CONSTANT:默认
我们如何更新我们的映射矩阵mat_x和mat_y? 继续阅读:
6、更新映射矩阵:我们将执行4个不同的映射:
a、将图片缩小一半,并将其显示在中间:
h(i,j)=(2∗i−src.cols/2+0.5,2∗j−src.rows/2+0.5)
对于所有对(i,j),使得:src.cols4<i<3⋅src.cols4 和src.rows4<j<3⋅src.rows4
b、翻转图像:h(i,j)=(i,src.rows−j)
c、从左到右反映图像:h(i,j)=(src.cols−i,j)
d、b和c的组合:h(i,j)=(src.cols−i,src.rows−j)
这在以下片段中表示。 这里,map_x表示h(i,j)的第一个坐标,map_y表示第二个坐标。
使用OpenCV函数cv :: getRotationMatrix2D来获得一个2×3的旋转矩阵
2、从上面我们可以用仿射变换来表示:
旋转(线性变换)
翻转(矢量添加)
比例运算(线性变换)
您可以看到,实质上,仿射变换表示两个图像之间的关系。
3、表示仿射变换的常用方法是使用2×3矩阵。

考虑到我们想要变换2D矢量X=[xy] 通过使用A和B,我们可以等价地做到:T=A⋅[xy]+B 和 T=M⋅[x,y,1]T
T=[a00x+a01y+b00a10x+a11y+b10]
我们知道X和T,我们也知道它们是相关的。 那么我们的工作就是找M
我们知道M和X.为了获得T,我们只需要应用T=M⋅X。
我们的M的信息可能是明确的(即具有2×3的矩阵),或者它可以作为点之间的几何关系。
2、让我们稍微解释一下(b)。 由于M涉及02图像,我们可以分析两幅图像中三点相关的最简单情况。 看下面的图:

点1,点2和点3(在图像1中形成一个三角形)映射到图像2,仍然形成一个三角形,但是现在它们已经改变了。 如果我们找到这3个点的仿射变换(可以随意选择它们),那么我们可以将这个找到的关系应用到图像中的整个像素上。
加载图像
将仿射变换应用于图像。 这个变换是从三点的关系中获得的。 为此,我们使用函数cv :: warpAffine。
在转换后将旋转应用于图像。 这种旋转是相对于图像中心而言的
等待用户退出程序
2、教程代码的显示如下。 您也可以从这里下载
2、加载图像
3、将目标图像初始化为与源具有相同的大小和类型:
4、仿射变换:正如我们在上面解释的那样,我们需要两组3点来导出仿射变换关系。 看一看:
你可能想要画出点来更好地了解它们如何改变。 它们的位置与示例图(在“理论”部分)中描述的位置大致相同。 您可能会注意到3点定义的三角形的大小和方向会改变。
5、用两组点来武装,我们使用OpenCV函数cv :: getAffineTransform来计算仿射变换:
6、我们将刚刚发现的仿射变换应用于src图像
有以下参数:
src:输入图像
warp_dst:输出图像
warp_mat:仿射变换
warp_dst.size():输出图像的所需大小
我们刚刚得到了我们的第一个转化的形象 我们将显示在一个位。 在此之前,我们也想旋转它…
7、旋转:要旋转图像,我们需要知道两件事:
中心相对于图像将旋转
要旋转的角度。 在OpenCV中,正角度是逆时针的
可选:比例因子
我们用下面的代码定义这些参数:
8、我们使用OpenCV函数cv :: getRotationMatrix2D生成旋转矩阵,该函数返回一个2×3矩阵(本例中为rot_mat)
9、我们现在将找到的旋转应用到之前的变换的输出。
10、最后,我们在两个窗口中加上原始图像来显示我们的结果,
11、我们只需要等到用户退出程序
通过使用OpenCV函数cv :: equalizeHist来均衡图像的直方图
它量化考虑的每个强度值的像素数量。
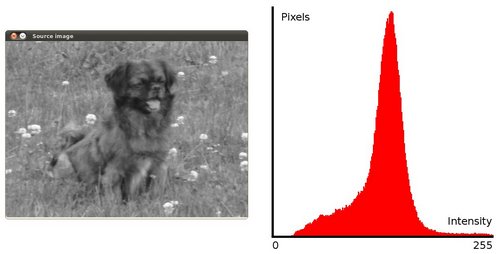
为了使其更清楚,从上面的图像中,可以看到像素似乎聚集在可用强度范围的中间。 直方图均衡化的作用就是扩展这个范围。
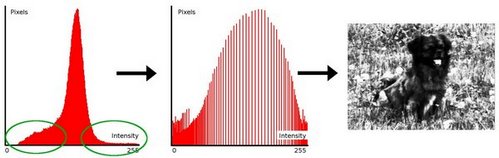
看看下图:绿色的圆圈表示人口密度不足。 在应用均衡之后,我们得到一个像中心的数字的直方图。 结果图像显示在右边的图片中。
为了实现均衡效果,重映射应该是累积分布函数(cdf)(更多细节请参考学习OpenCV)。 对于直方图H(i),其累积分布H′(i)为:
H′(i)=∑0≤j<iH(j)
为了将其用作重映射函数,必须使H′(i)归一化,使得最大值为255(或图像强度的最大值)。 从上面的例子来看,累积函数是:

最后,我们使用一个简单的重新映射程序来获取均衡图像的强度值:
equalized(x,y)=H′(src(x,y))
加载图像
将原始图像转换为灰度
通过使用OpenCV函数cv :: equalizeHist来均衡直方图
在窗口中显示来源和均衡的图像。
可下载的代码:点击这里
代码一览:
2、加载图像
3、转成灰度图
4、使用函数cv :: equalizeHist应用直方图均衡:
因为它可以很容易地看到,唯一的参数是原始图像和输出(均衡)图像。
5、显示两个图像(原始和均衡):
6、等到用户退出程序
通过使用OpenCV函数cv :: calcHist来计算图像数组的直方图
通过使用函数cv :: normalize来规范一个数组
当我们说数据时,我们并没有将其限制为强度值(正如我们在前面的教程中看到的那样)。 收集的数据可以是任何您认为有用的特征来描述您的图像。
我们来看一个例子。 设想矩阵包含图像的信息(即0-255范围内的强度):

如果我们想有组织地计算这些数据会发生什么? 既然我们知道这种情况下信息值的范围是256个值,我们可以将我们的范围分割成子部分(称为bins),如下所示:
[0,255]=[0,15]∪[16,31]∪....∪[240,255]range=bin1∪bin2∪....∪binn=15
并且我们可以保持在每个二进制范围内的像素数。 把这个应用到上面的例子中,我们得到下面的图像(轴x代表箱和轴y每个像素的数量)。

这只是一个简单的例子,直方图如何工作,为什么它是有用的。
直方图不仅可以计算颜色强度,而且可以计算我们要测量的任何图像特征(即,渐变,方向等)。
让我们确定直方图的一些部分:
dims:您想要收集数据的参数数量。 在我们的例子中,dims = 1,因为我们只计算每个像素的灰度值(在灰度图像中)。
bin:每个dim中的细分数。 在我们的例子中,bin= 16
range:要测量的值的限制。 在这种情况下:range= [0,255]
如果你想要计算两个功能呢?在这种情况下,你的结果直方图是一个三维图(其中x和y对每个特征都是binx和biny,z是每个(binx,biny)组合的计数数量。(当然它变得更复杂)。
加载图像
使用函数cv :: split将图像分割成R,G和B平面
通过调用函数cv :: calcHist来计算每个单通道平面的直方图
在窗口中绘制三个直方图
可下载的代码:点击这里
代码一览:
2、加载原图像
3、在三个R,G和B平面中分离源图像。 为此,我们使用OpenCV函数cv :: split:
我们的输入是要分割的图像(这种情况下有三个通道),输出是Mat的矢量)
4、现在我们准备开始配置每个平面的直方图。 由于我们正在使用B,G和R平面,所以我们知道我们的值将在[0,255]
建立bins数量(5,10 …):
设置值的范围(如我们所说的,在0和255之间)
我们希望我们的箱子具有相同的尺寸(统一),并在开始时清除直方图,因此:
最后,我们创建Mat对象来保存我们的直方图。 创建3(每个飞机一个):
我们继续使用OpenCV函数cv :: calcHist来计算直方图:
参数是:
&bgr_planes [0]:源数组
1:源数组的数量(在这种情况下,我们使用的是1.我们可以在这里输入一个数组列表)
0:要测量的通道(dim)。 在这种情况下,它只是强度(每个阵列是单通道),所以我们只写0。
Mat():要在源数组上使用的掩码(指示要被忽略的像素的零)。 如果没有定义,则不使用
b_hist:存储直方图的Mat对象
1:直方图维度。
histSize:每个使用尺寸的箱数
histRange:每个维度要测量的值的范围
uniform and accumulate:仓大小相同,直方图在开始时被清除。
5、创建一个图像来显示直方图:
6、请注意,在绘制之前,我们首先cv::normalize直方图,使其值落在输入参数指定的范围内:
这个函数接收这些参数:
b_hist:输入数组
b_hist:输出标准化数组(可以相同)
0和* histImage.rows:对于这个例子,它们是对r_hist的值进行标准化的上限和下限*
NORM_MINMAX:指示规范化类型的参数(如上所述,它调整之前设置的两个限制之间的值)
* - 1:*意味着输出归一化数组将与输入类型相同
Mat():可选掩码
7、最后,观察到访问bin(在这种情况下在这个1D柱状图):
我们使用表达式:
i在哪里指出维度。 如果这是一个二维直方图,我们会使用类似于:
8、最后我们显示我们的直方图并等待用户退出:
使用不同的指标来比较直方图
OpenCV实现了函数cv :: compareHist来执行比较。 它还提供了4种不同的度量来计算匹配:
1、相关性(CV_COMP_CORREL)
d(H1,H2)=∑I(H1(I)−H1¯)(H2(I)−H2¯)∑I(H1(I)−H1¯)2∑I(H2(I)−H2¯)2√
这里的:
Hk¯=1N∑JHk(J)
N是直方图bins的总数。
2、Chi-Square ( CV_COMP_CHISQR )
d(H1,H2)=∑I(H1(I)−H2(I))2H1(I)
3、相交(method= CV_COMP_INTERSECT)
d(H1,H2)=∑Imin(H1(I),H2(I))
4、Bhattacharyya距离(CV_COMP_BHATTACHARYYA)
d(H1,H2)=1−1H1¯H2¯N2√∑IH1(I)⋅H2(I)−−−−−−−−−−−√−−−−−−−−−−−−−−−−−−−−−−−−−−√
加载一个基本图像和2个测试图像进行比较。
生成基本图像的下半部分的1图像
将图像转换为HSV格式
计算所有图像的H-S直方图并对它们进行归一化处理,以便比较它们。
比较基本图像的直方图与2个测试直方图,下半部分基本图像的直方图和相同的基本图像直方图。
显示获得的数字匹配参数。
可下载的代码:点击这里
代码一览:
2、加载基本图像(src_base)和另外两个测试图像:
3、将它们转换为HSV格式:
4、另外,创建基本图像的一半(以HSV格式)的图像:
5、初始化参数以计算直方图(bins,范围和通道H和S)。
6、创建MatND对象来存储直方图:
7、计算基础图像,2个测试图像和半下基本图像的直方图:
8、依次应用基本图像(Hist_base)的直方图和其他直方图之间的4种比较方法:
1、https://docs.opencv.org/3.2.0/
2、https://github.com/opencv/opencv/
阈值操作使用inRange
使用OpenCV函数cv :: inRange执行基本的阈值操作根据像素值的范围检测对象
理论
在之前的教程中,我们学习了如何使用cv :: threshold函数执行阈值处理。在本教程中,我们将学习如何使用cv :: inRange函数来做到这一点。
这个概念保持不变,但现在我们添加一个我们需要的像素值的范围。
代码
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
#include <iostream>
#include <stdlib.h>
using namespace std;
using namespace cv;
void on_low_r_thresh_trackbar(int, void *);
void on_high_r_thresh_trackbar(int, void *);
void on_low_g_thresh_trackbar(int, void *);
void on_high_g_thresh_trackbar(int, void *);
void on_low_b_thresh_trackbar(int, void *);
void on_high_b_thresh_trackbar(int, void *);
int low_r=30, low_g=30, low_b=30;
int high_r=100, high_g=100, high_b=100;
int main()
{
Mat frame, frame_threshold;
VideoCapture cap(0);
namedWindow("Video Capture", WINDOW_NORMAL);
namedWindow("Object Detection", WINDOW_NORMAL);
//-- Trackbars to set thresholds for RGB values
createTrackbar("Low R","Object Detection", &low_r, 255, on_low_r_thresh_trackbar);
createTrackbar("High R","Object Detection", &high_r, 255, on_high_r_thresh_trackbar);
createTrackbar("Low G","Object Detection", &low_g, 255, on_low_g_thresh_trackbar);
createTrackbar("High G","Object Detection", &high_g, 255, on_high_g_thresh_trackbar);
createTrackbar("Low B","Object Detection", &low_b, 255, on_low_b_thresh_trackbar);
createTrackbar("High B","Object Detection", &high_b, 255, on_high_b_thresh_trackbar);
while((char)waitKey(1)!='q'){
cap>>frame;
if(frame.empty())
break;
//-- Detect the object based on RGB Range Values
inRange(frame,Scalar(low_b,low_g,low_r), Scalar(high_b,high_g,high_r),frame_threshold);
//-- Show the frames
imshow("Video Capture",frame);
imshow("Object Detection",frame_threshold);
}
return 0;
}
void on_low_r_thresh_trackbar(int, void *)
{
low_r = min(high_r-1, low_r);
setTrackbarPos("Low R","Object Detection", low_r);
}
void on_high_r_thresh_trackbar(int, void *)
{
high_r = max(high_r, low_r+1);
setTrackbarPos("High R", "Object Detection", high_r);
}
void on_low_g_thresh_trackbar(int, void *)
{
low_g = min(high_g-1, low_g);
setTrackbarPos("Low G","Object Detection", low_g);
}
void on_high_g_thresh_trackbar(int, void *)
{
high_g = max(high_g, low_g+1);
setTrackbarPos("High G", "Object Detection", high_g);
}
void on_low_b_thresh_trackbar(int, void *)
{
low_b= min(high_b-1, low_b);
setTrackbarPos("Low B","Object Detection", low_b);
}
void on_high_b_thresh_trackbar(int, void *)
{
high_b = max(high_b, low_b+1);
setTrackbarPos("High B", "Object Detection", high_b);
}说明
1、我们来看看程序的一般结构:创建两个矩阵元素来存储帧
Mat frame, frame_threshold;
从默认捕获设备捕获视频流。
VideoCapture cap(0);
创建一个窗口来显示默认框架和阈值框架。
namedWindow("Video Capture", WINDOW_NORMAL);
namedWindow("Object Detection", WINDOW_NORMAL);创建轨迹条来设置RGB值的范围
//-- Trackbars to set thresholds for RGB values
createTrackbar("Low R","Object Detection", &low_r, 255, on_low_r_thresh_trackbar);
createTrackbar("High R","Object Detection", &high_r, 255, on_high_r_thresh_trackbar);
createTrackbar("Low G","Object Detection", &low_g, 255, on_low_g_thresh_trackbar);
createTrackbar("High G","Object Detection", &high_g, 255, on_high_g_thresh_trackbar);
createTrackbar("Low B","Object Detection", &low_b, 255, on_low_b_thresh_trackbar);
createTrackbar("High B","Object Detection", &high_b, 255, on_high_b_thresh_trackbar);在用户希望程序退出之前,请执行以下操作
cap>>frame; if(frame.empty()) break; //-- Detect the object based on RGB Range Values inRange(frame,Scalar(low_b,low_g,low_r), Scalar(high_b,high_g,high_r),frame_threshold);
显示图像
//-- Show the frames
imshow("Video Capture",frame);
imshow("Object Detection",frame_threshold);对于控制范围较低的轨迹栏,例如Red值:
void on_low_r_thresh_trackbar(int, void *)
{
low_r = min(high_r-1, low_r);
setTrackbarPos("Low R","Object Detection", low_r);
}对于控制上限的轨迹栏,例如红色值:
void on_high_r_thresh_trackbar(int, void *)
{
high_r = max(high_r, low_r+1);
setTrackbarPos("High R", "Object Detection", high_r);
}有必要找到最大值和最小值,以避免阈值的高值变得低于低值的差异。
制作你自己的线性过滤器!
使用OpenCV函数cv :: filter2D创建您自己的线性过滤器。理论
卷积
从一般意义上讲,卷积是图像的每个部分与运算符(内核)之间的操作。什么是内核
内核本质上是一个数值系数的固定大小的数组,以及该数组中的锚点,该数组通常位于中心。卷积如何使用内核工作?
假设您想知道图像中特定位置的结果值。 卷积的值按以下方式计算:将内核锚放置在确定的像素顶部,内核的其余部分覆盖图像中相应的局部像素。
将核系数乘以相应的图像像素值并对结果进行求和。
将结果放置在输入图像中的锚点的位置。
通过在整个图像上扫描内核重复所有像素的过程。
用等式的形式表示上述过程,我们可以得到:
H(x,y) = ∑Mi−1i=0∑Mj−1j=0I(x+i−ai,y+j−aj)K(i,j)
幸运的是,OpenCV为您提供了函数cv :: filter2D,所以您不必编写所有这些操作。
代码
1、这个程序做什么?加载图像
执行规范化的框过滤器。 例如,对于大小size=3的内核,内核将是:
K= 13⋅3⎡⎣⎢111111111⎤⎦⎥
程序将执行大小为3,5,7,9和11的内核的过滤操作。
过滤器输出(每个内核)将在500毫秒内显示
2、教程代码的显示如下。 您也可以从这里下载
#include "opencv2/imgproc.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
int main ( int, char** argv )
{
Mat src, dst;
Mat kernel;
Point anchor;
double delta;
int ddepth;
int kernel_size;
const char* window_name = "filter2D Demo";
src = imread( argv[1], IMREAD_COLOR ); // Load an image
if( src.empty() )
{ return -1; }
anchor = Point( -1, -1 );
delta = 0;
ddepth = -1;
int ind = 0;
for(;;)
{
char c = (char)waitKey(500);
if( c == 27 )
{ break; }
kernel_size = 3 + 2*( ind%5 );
kernel = Mat::ones( kernel_size, kernel_size, CV_32F )/ (float)(kernel_size*kernel_size);
filter2D(src, dst, ddepth , kernel, anchor, delta, BORDER_DEFAULT );
imshow( window_name, dst );
ind++;
}
return 0;
}说明
1、加载图像src = imread( argv[1], IMREAD_COLOR ); // Load an image
if( src.empty() )
{ return -1; }2、初始化线性滤波器的参数
anchor = Point( -1, -1 ); delta = 0; ddepth = -1;
3、执行更新内核大小的无限循环,并将线性滤波器应用于输入图像。 我们来更详细地分析一下:
4、首先我们定义我们的过滤器将要使用的内核。 这里是:
kernel_size = 3 + 2*( ind%5 ); kernel = Mat::ones( kernel_size, kernel_size, CV_32F )/ (float)(kernel_size*kernel_size);
第一行是将kernel_size更新为范围内的奇数值:[3,11]。 第二行实际上是通过将它的值设置为一个用1填充的矩阵并通过将其除以元素数来规范它来建立内核。
5、设置内核之后,我们可以使用函数cv :: filter2D生成过滤器:
filter2D(src, dst, ddepth , kernel, anchor, delta, BORDER_DEFAULT );
参数表示:
src:源图像
dst:目标图像
ddepth:dst的深度。 负值(如-1)表示深度与源相同。
内核:要通过映像扫描的内核
anchor:锚点相对于其内核的位置。 位置点(-1,-1)默认显示中心。
delta(增量):在卷积过程中要添加到每个像素的值。 默认情况下它是0
BORDER_DEFAULT:我们默认设置这个值(在下面的教程中有更多的细节)
6、我们的程序将实现一个while循环,每500 ms,我们的过滤器的内核大小将在指定的范围内更新。
为图像添加边框
使用OpenCV函数cv :: copyMakeBorder来设置边框(额外的填充图像)。理论
在我们以前的教程中,我们学会了使用卷积来处理图像。 自然产生的一个问题是如何处理边界。 如果评估点位于图像的边缘,我们如何进行卷积?大多数OpenCV函数做的是将给定的图像复制到另一个稍大的图像,然后自动填充边界(通过下面示例代码中解释的任何方法)。
这样,卷积可以在没有问题的情况下在所需的像素上执行(在完成操作之后,额外的填充被切掉)。
在本教程中,我们将简要介绍两种为图像定义额外填充(边框)的方法:
BORDER_CONSTANT:用一个常量值(即黑色或0)填充图像
BORDER_REPLICATE:将原始边缘处的行或列复制到额外边框。 代码部分将更清楚地看到这一点。
代码
1、这个程序做什么?加载图像
让用户选择在输入图像中使用什么样的填充。 有两个选项:
常量值边框:为整个边框应用一个常量值的填充。 该值将每0.5秒随机更新一次。
复制的边框:将从原始图像边缘的像素值复制边框。 用户通过按’c’(常数)或’r’(复制)选择任一选项,
程序结束时,用户按下“ESC”
2、教程代码的显示如下。 您也可以从这里下载
#include "opencv2/imgproc.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
Mat src, dst;
int top, bottom, left, right;
int borderType;
const char* window_name = "copyMakeBorder Demo";
RNG rng(12345);
int main( int, char** argv )
{
src = imread( argv[1], IMREAD_COLOR ); // Load an image
if( src.empty() )
{
printf(" No data entered, please enter the path to an image file \n");
return -1;
}
printf( "\n \t copyMakeBorder Demo: \n" );
printf( "\t -------------------- \n" );
printf( " ** Press 'c' to set the border to a random constant value \n");
printf( " ** Press 'r' to set the border to be replicated \n");
printf( " ** Press 'ESC' to exit the program \n");
namedWindow( window_name, WINDOW_AUTOSIZE );
top = (int) (0.05*src.rows); bottom = (int) (0.05*src.rows);
left = (int) (0.05*src.cols); right = (int) (0.05*src.cols);
dst = src;
imshow( window_name, dst );
for(;;)
{
char c = (char)waitKey(500);
if( c == 27 )
{ break; }
else if( c == 'c' )
{ borderType = BORDER_CONSTANT; }
else if( c == 'r' )
{ borderType = BORDER_REPLICATE; }
Scalar value( rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255) );
copyMakeBorder( src, dst, top, bottom, left, right, borderType, value );
imshow( window_name, dst );
}
return 0;
}说明
1、首先我们声明我们要使用的变量:Mat src, dst; int top, bottom, left, right; int borderType; const char* window_name = "copyMakeBorder Demo"; RNG rng(12345);
特别值得注意的是随机数发生器的变量rng。 我们用它来生成随机的边框颜色,我们很快就会看到。
2、像往常一样,我们加载我们的源图像src:
src = imread( argv[1], IMREAD_COLOR ); // Load an image
if( src.empty() )
{
printf(" No data entered, please enter the path to an image file \n");
return -1;
}3、在介绍如何使用该程序之后,我们创建一个窗口:
namedWindow( window_name, WINDOW_AUTOSIZE );
4、现在我们初始化定义边界大小的参数(顶部,底部,左侧和右侧)。 我们给他们一个src大小的5%的值。
top = (int) (0.05*src.rows); bottom = (int) (0.05*src.rows); left = (int) (0.05*src.cols); right = (int) (0.05*src.cols);
5、该程序运行在一个for循环。 如果用户按下“c”或“r”,borderType变量分别取BORDER_CONSTANT或BORDER_REPLICATE的值:
char c = (char)waitKey(500);
if( c == 27 )
{ break; }
else if( c == 'c' )
{ borderType = BORDER_CONSTANT; }
else if( c == 'r' )
{ borderType = BORDER_REPLICATE; }6、在每次迭代中(0.5秒后),变量值被更新…
Scalar value( rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255) );
与由RNG变量rng生成的随机值进行比较。 该值是在[0,255]范围内随机选取的数字,
7、最后,我们调用函数cv :: copyMakeBorder来应用相应的填充:
copyMakeBorder( src, dst, top, bottom, left, right, borderType, value );
参数是:
src:源图像
dst:目标图像
top, bottom, left, right:图像两侧边框的长度(以像素为单位)。 我们将它们定义为图像原始大小的5%。
borderType:定义应用的边界类型。 这个例子可以是常量或复制。
value :如果borderType是BORDER_CONSTANT,则这是用来填充边界像素的值。
8、我们在之前创建的图像中显示我们的输出图像
imshow( window_name, dst );
Sobel 导数
使用OpenCV函数cv :: Sobel来计算图像的导数。使用OpenCV函数cv :: Scharr来为大小为3⋅3的内核计算更精确的导数
理论
1、在最后两篇教程中,我们看到了卷积的应用例子。 其中最重要的一个卷积是计算图像中的导数(或对它们的近似)。2、为什么图像中导数的微积分可能很重要? 让我们想象我们想要检测图像中存在的边缘。 例如:
你可以很容易地注意到,在一个边缘,像素的强度以一种显著的方式变化。 表达变化的好方法是使用导数工具。 梯度的高度变化表示图像的主要变化。
3、为了图形化,我们假设我们有一维图像。 在下图中,边缘由强度的“跳跃”表示:
4、如果我们采用一阶导数(实际上,这里显示为最大值),则可以更容易地看到边缘“跳跃”
5、所以,从上面的解释中,我们可以推断出一种检测图像中边缘的方法可以通过定位梯度高于其邻域(或推广,高于阈值)的像素位置来执行。
6、更详细的解释请参考Bradski和Kaehler学习OpenCV
Sobel操作
Sobel算子是一个离散的差分算子。 它计算图像强度函数梯度的近似值。Sobel算子结合了高斯平滑和差分。
公式
假设要操作的图像是I:1、我们计算两个导数:
水平变化:这是通过将I与具有奇数大小的内核Gx进行卷积来计算的。 例如,对于3的内核大小,Gx将被计算为:
Gx =⎡⎣⎢−1−2−1000+1+2+1⎤⎦⎥∗I
垂直变化:这是通过将I与具有奇数大小的内核Gy进行卷积来计算的。 例如,对于3的内核大小,Gy将被计算为:
Gy = ⎡⎣⎢−10+1−20+2−10+1⎤⎦⎥∗I
2、在图像的每个点上,我们通过结合上面的两个结果来计算该点上的渐变的近似值:
G = G2x+G2y−−−−−−−√
尽管有时会使用以下更简单的公式:
G = |Gx|+|Gy|
注:
当内核大小为3时,上面显示的Sobel内核可能会产生明显的不准确性(毕竟,Sobel只是导数的近似值)。 OpenCV通过使用cv :: Scharr函数来解决大小为3的内核的这种不准确性。 这与标准的Sobel功能一样快,但更准确。 它实现了以下内核:
Gx = ⎡⎣⎢−3−10−3000+3+10+3⎤⎦⎥
Gy = ⎡⎣⎢−30+3−100+10−30+3⎤⎦⎥
您可以在OpenCV参考(cv :: Scharr)中查看该函数的更多信息。 另外,在下面的示例代码中,您会注意到在cv :: Sobel函数的代码之上还有cv :: Scharr函数注释的代码。 取消注释(并明显评论Sobel的东西)应该给你一个这个功能如何工作的想法。
代码
1、这个程序做什么?应用Sobel算子,并在较暗的背景上产生检测到边缘明亮的图像。
2、教程代码的显示如下。 您也可以从这里下载
#include "opencv2/imgproc.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
int main( int, char** argv )
{
Mat src, src_gray;
Mat grad;
const char* window_name = "Sobel Demo - Simple Edge Detector";
int scale = 1;
int delta = 0;
int ddepth = CV_16S;
src = imread( argv[1], IMREAD_COLOR ); // Load an image
if( src.empty() )
{ return -1; }
GaussianBlur( src, src, Size(3,3), 0, 0, BORDER_DEFAULT );
cvtColor( src, src_gray, COLOR_BGR2GRAY );
Mat grad_x, grad_y;
Mat abs_grad_x, abs_grad_y;
//Scharr( src_gray, grad_x, ddepth, 1, 0, scale, delta, BORDER_DEFAULT );
Sobel( src_gray, grad_x, ddepth, 1, 0, 3, scale, delta, BORDER_DEFAULT );
//Scharr( src_gray, grad_y, ddepth, 0, 1, scale, delta, BORDER_DEFAULT );
Sobel( src_gray, grad_y, ddepth, 0, 1, 3, scale, delta, BORDER_DEFAULT );
convertScaleAbs( grad_x, abs_grad_x );
convertScaleAbs( grad_y, abs_grad_y );
addWeighted( abs_grad_x, 0.5, abs_grad_y, 0.5, 0, grad );
imshow( window_name, grad );
waitKey(0);
return 0;
}说明
1、首先我们声明我们要使用的变量:Mat src, src_gray; Mat grad; const char* window_name = "Sobel Demo - Simple Edge Detector"; int scale = 1; int delta = 0; int ddepth = CV_16S;
2、像往常一样,我们加载我们的源图像src:
src = imread( argv[1], IMREAD_COLOR ); // Load an image
if( src.empty() )
{ return -1; }3、首先,我们将cv :: GaussianBlur应用于图像,以减少噪声(内核大小= 3)
GaussianBlur( src, src, Size(3,3), 0, 0, BORDER_DEFAULT );
4、现在我们将我们过滤的图像转换成灰度图:
cvtColor( src, src_gray, COLOR_BGR2GRAY );
5、其次,我们计算x和y方向上的“导数”。 为此,我们使用函数cv :: Sobel,如下所示:
Mat grad_x, grad_y; Mat abs_grad_x, abs_grad_y; //Scharr( src_gray, grad_x, ddepth, 1, 0, scale, delta, BORDER_DEFAULT ); Sobel( src_gray, grad_x, ddepth, 1, 0, 3, scale, delta, BORDER_DEFAULT ); //Scharr( src_gray, grad_y, ddepth, 0, 1, scale, delta, BORDER_DEFAULT ); Sobel( src_gray, grad_y, ddepth, 0, 1, 3, scale, delta, BORDER_DEFAULT );
该函数采用以下参数:
src_gray:在我们的例子中,输入图像。 这是CV_8U
grad_x / * grad_y *:输出图像。
ddepth:输出图像的深度。 我们将其设置为CV_16S以避免溢出。
x_order:x方向的导数的阶数。
y_order:y方向上的导数的阶数。
scale,delta 和BORDER_DEFAULT:我们使用默认值。
请注意,要计算x方向上的梯度,我们使用:xorder = 1和yorder= 0。 我们做类似的y方向。
6、我们将部分结果转换回CV_8U:
convertScaleAbs( grad_x, abs_grad_x ); convertScaleAbs( grad_y, abs_grad_y );
7、最后,我们尝试通过添加两个方向梯度来近似梯度(请注意,这根本不是一个精确的计算,但它对我们的目的是有利的)。
addWeighted( abs_grad_x, 0.5, abs_grad_y, 0.5, 0, grad );
8、最后,我们展示我们的结果:
imshow( window_name, grad ); waitKey(0);
结果
拉普拉斯算子
使用OpenCV函数cv :: Laplacian来实现拉普拉斯算子的离散模拟。理论
1、在之前的教程中,我们学习了如何使用Sobel算子。 这是基于这样的事实,即在边缘区域,像素强度显示出“跳跃”或强度变化很大。 获得强度的一阶导数,我们观察到边缘的特征是最大的,如图中所示:2、而且…如果我们采用二阶导数会发生什么?
你可以观察到二阶导数是零! 所以,我们也可以使用这个标准来尝试检测图像中的边缘。 但是,请注意,零不仅会出现在边缘(它们实际上可能出现在其他无意义的位置)。 这可以通过在需要的地方应用过滤来解决。
拉普拉斯算子
1、从上面的解释中,我们推导出二阶导数可以用来检测边缘。 由于图像是“* 2D *”,因此我们需要在两个维度上都采用导数。 在这里,拉普拉斯算子来得方便。2、拉普拉斯算子定义如下:
Laplace(f) = ∂2f∂x2+∂2f∂y2
3、拉普拉斯算子在OpenCV中由函数cv :: Laplacian实现。 实际上,由于拉普拉斯算子使用图像的梯度,所以它在内部调用Sobel算子来执行它的计算。
代码
1、这个程序做什么?加载图像
应用高斯模糊消除噪声,然后将原始图像转换为灰度
将拉普拉斯算子应用于灰度图像并存储输出图像
在一个窗口中显示结果
2、教程代码的显示如下。 您也可以从这里下载
#include "opencv2/imgproc.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
int main( int, char** argv )
{
Mat src, src_gray, dst; int kernel_size = 3; int scale = 1; int delta = 0; int ddepth = CV_16S; const char* window_name = "Laplace Demo";
src = imread( argv[1], IMREAD_COLOR ); // Load an image if( src.empty() ) { return -1; }
GaussianBlur( src, src, Size(3,3), 0, 0, BORDER_DEFAULT );
cvtColor( src, src_gray, COLOR_BGR2GRAY ); // Convert the image to grayscale
Mat abs_dst;
Laplacian( src_gray, dst, ddepth, kernel_size, scale, delta, BORDER_DEFAULT );
convertScaleAbs( dst, abs_dst );
imshow( window_name, abs_dst ); waitKey(0); return 0;
}
说明
1、创建一些需要的变量:Mat src, src_gray, dst; int kernel_size = 3; int scale = 1; int delta = 0; int ddepth = CV_16S; const char* window_name = "Laplace Demo";
2、加载源图像:
src = imread( argv[1], IMREAD_COLOR ); // Load an image
if( src.empty() )
{ return -1; }3、应用高斯模糊来减少噪音:
GaussianBlur( src, src, Size(3,3), 0, 0, BORDER_DEFAULT );
4、使用cv :: cvtColor将图像转换为灰度
cvtColor( src, src_gray, COLOR_BGR2GRAY ); // Convert the image to grayscale
5、将拉普拉斯算子应用于灰度图像:
Laplacian( src_gray, dst, ddepth, kernel_size, scale, delta, BORDER_DEFAULT );
参数是:
src_gray:输入图像。
dst:目标(输出)图像
ddepth:目标图像的深度。 由于我们的输入是CV_8U,我们定义ddepth = CV_16S以避免溢出
kernel_size:内部应用的Sobel运算符的内核大小。 在这个例子中我们使用3。
scale,delta和BORDER_DEFAULT:我们将它们作为默认值。
6、将拉普拉斯算子的输出转换为CV_8U图像:
convertScaleAbs( dst, abs_dst );
7、在窗口中显示结果:
imshow( window_name, abs_dst ); waitKey(0);
Canny边缘检测器
使用OpenCV函数cv :: Canny来实现Canny边缘检测器。理论
Canny边缘检测器是由John F. Canny于1986年开发的。也被许多人称为最佳检测器,Canny算法旨在满足三个主要标准:低错误率:意味着仅存在边缘的良好检测。
良好的定位:检测到的边缘像素与真实的边缘像素之间的距离必须最小化。
最小响应:每条边只有一个检测器响应。
步骤
1、滤除任何噪音。 高斯滤波器用于此目的。 下面显示了一个大小为5的高斯内核的例子:K = 1159⎡⎣⎢⎢⎢⎢⎢⎢245424912945121512549129424542⎤⎦⎥⎥⎥⎥⎥⎥
2、找到图像的强度梯度。 为此,我们遵循一个类似于Sobel的程序:
应用一对卷积掩膜(在x和y方向:
Gx= ⎡⎣⎢−1−2−1000+1+2+1⎤⎦⎥
Gy = ⎡⎣⎢−10+1−20+2−10+1⎤⎦⎥
通过以下方式查找梯度强度和方向:
G=G2x+G2y−−−−−−−√θ=arctan(GyGx)
方向被四舍五入为四个可能的角度之一(即0,45,90或135)
3、非最大抑制应用。 这将删除不被视为边缘一部分的像素。 因此,只有细线(候选边缘)将保留。
4、迟滞:最后一步。 Canny确实使用了两个阈值(上限和下限):
如果像素梯度高于阈值上限,则该像素被接受为边缘
如果像素梯度值低于下限,则拒绝。
如果像素梯度在两个阈值之间,那么只有当它连接到高于阈值上限的像素时才会被接受。
Canny建议上限:下限比例 在2:1和3:1之间。
5、欲了解更多详情,您可以随时咨询您最喜爱的计算机视觉书籍。
代码
1、这个程序做什么?要求用户输入一个数值来设置Canny Edge Detector的下限(通过Trackbar)
应用Canny Detector并生成一个掩膜(亮线代表黑色背景上的边缘)。
应用在原始图像上获得的掩膜并将其显示在窗口中。
2、教程代码的显示如下。 您也可以从这里下载
#include "opencv2/imgproc.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
Mat src, src_gray; Mat dst, detected_edges; int edgeThresh = 1; int lowThreshold; int const max_lowThreshold = 100; int ratio = 3; int kernel_size = 3; const char* window_name = "Edge Map";
static void CannyThreshold(int, void*)
{
blur( src_gray, detected_edges, Size(3,3) );
Canny( detected_edges, detected_edges, lowThreshold, lowThreshold*ratio, kernel_size );
dst = Scalar::all(0);
src.copyTo( dst, detected_edges);
imshow( window_name, dst );
}
int main( int, char** argv )
{
src = imread( argv[1], IMREAD_COLOR ); // Load an image if( src.empty() ) { return -1; }
dst.create( src.size(), src.type() );
cvtColor( src, src_gray, COLOR_BGR2GRAY );
namedWindow( window_name, WINDOW_AUTOSIZE );
createTrackbar( "Min Threshold:", window_name, &lowThreshold, max_lowThreshold, CannyThreshold );
CannyThreshold(0, 0);
waitKey(0); return 0;
}
说明
1、创建一些需要的变量:Mat src, src_gray; Mat dst, detected_edges; int edgeThresh = 1; int lowThreshold; int const max_lowThreshold = 100; int ratio = 3; int kernel_size = 3; const char* window_name = "Edge Map";
请注意以下几点:
我们建立了一个比例下限:上限3:1(可变比例)
我们将内核大小设置为3(Sobel操作由Canny函数内部执行)
我们设置一个最大阈值下限为100。
2、加载源图像:
src = imread( argv[1], IMREAD_COLOR ); // Load an image
if( src.empty() )
{ return -1; }3、创建一个与src相同类型和大小的矩阵(即dst)
dst.create( src.size(), src.type() );
4、将图像转换为灰度(使用函数cv :: cvtColor:
cvtColor( src, src_gray, COLOR_BGR2GRAY );
5、创建一个窗口来显示结果
namedWindow( window_name, WINDOW_AUTOSIZE );
6、为用户创建一个跟踪栏,为我们的Canny探测器输入较低的阈值:
createTrackbar( "Min Threshold:", window_name, &lowThreshold, max_lowThreshold, CannyThreshold );
注意以下几点:
Trackbar控制的变量是lowThreshold,其限制为max_lowThreshold(我们之前设置为100)
Trackbar每次注册一个动作,就会调用回调函数CannyThreshold。
7、让我们一步一步检查CannyThreshold函数:
首先,我们用一个内核大小为3的滤镜来模糊图像:
blur( src_gray, detected_edges, Size(3,3) );
其次,我们使用OpenCV函数cv :: Canny
Canny( detected_edges, detected_edges, lowThreshold, lowThreshold*ratio, kernel_size );
参数是:
detected_edges:源图像,灰度
detected_edges:检测器的输出(可以与输入相同)
lowThreshold:用户移动轨迹栏输入的值
highThreshold:在程序中设置为下限阈值的三倍(按照Canny的建议)
kernel_size:我们将其定义为3(Sobel内核在内部使用的大小)
8、我们用零填充一个dst图像(意思是图像是完全黑色的)。
dst = Scalar::all(0);
9、最后,我们将使用函数cv :: Mat :: copyTo来仅映射被识别为边缘的图像区域(在黑色背景上)。 cv :: Mat :: copy将src图像复制到dst。 但是,它只会复制具有非零值的位置的像素。 由于Canny检测器的输出是黑色背景上的边缘轮廓,因此得到的dst在所有区域中将是黑色的,但检测到的边缘是黑色的。
src.copyTo( dst, detected_edges);
10、我们显示我们的结果:
imshow( window_name, dst );
结果
霍夫曲线变换
使用OpenCV函数cv :: HoughLines和cv :: HoughLinesP来检测图像中的行。霍夫曲线变换
霍夫线变换是一种用于检测直线的变换。为了应用变换,首先需要边缘检测预处理。
它是如何工作的?
1、如您所知,图像空间中的一条线可以用两个变量表示。 例如:在笛卡尔坐标系中:参数:(m,b)。
在极坐标系中:参数:(r,θ)
对于霍夫变换,我们将在极坐标系中表示线。 因此,一个线性方程可以写成:
y =(−cosθsinθ)x+(rsinθ)
式中:r= xcosθ+ysinθ
①、一般而言,对于每个点(x0,y0),我们可以定义通过该点的线族:
rθ= x0⋅cosθ+y0⋅sinθ
这意味着每对(rθ,θ)代表通过(x0,y0)的每条线。
②、如果对于给定的(x0,y0)我们绘制经过它的线的族,我们得到一个正弦曲线。 例如,对于x0=8和y0=6,我们得到下面的图(在θ−r平面内):
我们只考虑r>0和0<θ<2π的点。
③、我们可以对图像中的所有点进行相同的操作。 如果两个不同点的曲线在θ−r平面上相交,就意味着两个点属于同一条直线。 例如,按照上面的例子,再画两点:x1=4,y1=9,x2=12,y2=3,得到:
这三个图相交于一个点(0.925,9.6),这些坐标是参数(θ,r)或(x0,y0),(x1,y1)和(x2,y2)所在的线。
④、上面所有的东西是什么意思? 这意味着一般情况下,可以通过查找曲线之间的交点数来检测线。越多的曲线相交意味着由该交点表示的线具有更多的点。 一般来说,我们可以定义检测线所需的最小交点数阈值。
⑤、这就是霍夫曲线变换所做的。 它跟踪图像中每个点的曲线之间的交集。 如果交点的数量超过某个阈值,则将其声明为交点的参数(θ,rθ)的一条直线。
标准和概率Hough Line变换
OpenCV实现了两种Hough Line变换:1、 标准霍夫曲线变换
它几乎包含了我们在前一节中所解释的内容。 它给你一对向量(θ,rθ)
在OpenCV中,它使用函数cv :: HoughLines来实现
2、 概率霍夫曲线变换
霍夫线变换的更有效的实现。 它将检测到的线(x0,y0,x1,y1)的极值作为输出,
在OpenCV中,它使用函数cv :: HoughLinesP来实现
代码
1、这个程序做什么?加载图像
应用标准Hough Line Transform或概率霍夫曲线变换。
在两个窗口中显示原始图像和检测线。
2、我们将解释的示例代码可以从这里下载。 可以在这里找到一个稍微更有趣的版本(显示Hough标准和带有改变阈值的trackbars的概率)。
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace cv;
using namespace std;
static void help()
{
cout << "\nThis program demonstrates line finding with the Hough transform.\n"
"Usage:\n"
"./houghlines <image_name>, Default is ../data/pic1.png\n" << endl;
}
int main(int argc, char** argv)
{
cv::CommandLineParser parser(argc, argv,
"{help h||}{@image|../data/pic1.png|}"
);
if (parser.has("help"))
{
help();
return 0;
}
string filename = parser.get<string>("@image");
if (filename.empty())
{
help();
cout << "no image_name provided" << endl;
return -1;
}
Mat src = imread(filename, 0);
if(src.empty())
{
help();
cout << "can not open " << filename << endl;
return -1;
}
Mat dst, cdst;
Canny(src, dst, 50, 200, 3);
cvtColor(dst, cdst, COLOR_GRAY2BGR);
#if 0
vector<Vec2f> lines;
HoughLines(dst, lines, 1, CV_PI/180, 100, 0, 0 );
for( size_t i = 0; i < lines.size(); i++ )
{
float rho = lines[i][0], theta = lines[i][1];
Point pt1, pt2;
double a = cos(theta), b = sin(theta);
double x0 = a*rho, y0 = b*rho;
pt1.x = cvRound(x0 + 1000*(-b));
pt1.y = cvRound(y0 + 1000*(a));
pt2.x = cvRound(x0 - 1000*(-b));
pt2.y = cvRound(y0 - 1000*(a));
line( cdst, pt1, pt2, Scalar(0,0,255), 3, CV_AA);
}
#else
vector<Vec4i> lines;
HoughLinesP(dst, lines, 1, CV_PI/180, 50, 50, 10 );
for( size_t i = 0; i < lines.size(); i++ )
{
Vec4i l = lines[i];
line( cdst, Point(l[0], l[1]), Point(l[2], l[3]), Scalar(0,0,255), 3, LINE_AA);
}
#endif
imshow("source", src);
imshow("detected lines", cdst);
waitKey();
return 0;
}说明
1、加载图像Mat src = imread(filename, 0);
if(src.empty())
{
help();
cout << "can not open " << filename << endl;
return -1;
}2、通过使用Canny检测器来检测图像的边缘
Canny(src, dst, 50, 200, 3);
现在我们将应用霍夫线变换。 我们将解释如何使用可用于此目的的OpenCV功能:
3、标准霍夫曲线变换
a、首先,你应用转换:
vector<Vec2f> lines; HoughLines(dst, lines, 1, CV_PI/180, 100, 0, 0 );
有以下参数:
dst:边缘检测器的输出。 它应该是一个灰度图像(虽然实际上它是一个二进制)
lines:将存储检测线的参数(r,θ)的矢量
rho:以像素为单位的参数r的分辨率。 我们使用1个像素。
θ:弧度参数θ的分辨率。 我们使用1度(CV_PI / 180)
阈值:“检测”线的最小交点数
srn和stn:默认参数为零。 查看OpenCV参考了解更多信息。
b、然后通过画线来显示结果。
for( size_t i = 0; i < lines.size(); i++ )
{
float rho = lines[i][0], theta = lines[i][1];
Point pt1, pt2;
double a = cos(theta), b = sin(theta);
double x0 = a*rho, y0 = b*rho;
pt1.x = cvRound(x0 + 1000*(-b));
pt1.y = cvRound(y0 + 1000*(a));
pt2.x = cvRound(x0 - 1000*(-b));
pt2.y = cvRound(y0 - 1000*(a));
line( cdst, pt1, pt2, Scalar(0,0,255), 3, LINE_AA);
}4、概率霍夫线变换
a、首先你应用转换:
vector<Vec4i> lines; HoughLinesP(dst, lines, 1, CV_PI/180, 50, 50, 10 );
以下参数:
dst:边缘检测器的输出。 它应该是一个灰度图像(虽然实际上它是一个二进制)
lines:将存储检测到的行的参数(xstart,ystart,xend,yend)的向量
rho:以像素为单位的参数r的分辨率。 我们使用1个像素。
θ:弧度参数θ的分辨率。 我们使用1度(CV_PI / 180)
阈值:“检测”线的最小交点数
minLinLength:可以形成直线的最小点数。 少于这个点数的线被忽略。
maxLineGap:在同一行中考虑的两点之间的最大差距。
b、然后通过画线来显示结果。
for( size_t i = 0; i < lines.size(); i++ )
{
Vec4i l = lines[i];
line( cdst, Point(l[0], l[1]), Point(l[2], l[3]), Scalar(0,0,255), 3, LINE_AA);
}5、显示原始图像和检测线:
imshow("source", src);
imshow("detected lines", cdst);6、等到用户退出程序
waitKey();
霍夫圆变换
使用OpenCV函数cv :: HoughCircles来检测图像中的圆圈。理论
霍夫圆变换
霍夫圆变换的工作原理与上一个教程中介绍的霍夫曲线变换相似。在线检测情况下,一条线由两个参数(r,θ)定义。 在圆的情况下,我们需要三个参数来定义一个圆:
C:(xcenter,ycenter,r)
其中(xcenter,ycenter)定义中心位置(绿色点),r是半径,这使得我们可以完全定义一个圆,如下所示:
为了提高效率,OpenCV实现的检测方法比标准霍夫曲线变换稍微复杂一些:Hough梯度法,它由两个主要阶段组成。 第一阶段涉及边缘检测和找到可能的圆心,第二阶段找到每个候选中心的最佳半径。 有关更多详细信息,请查阅学习OpenCV或您最喜爱的计算机视觉参考书目
代码
1、这个程序做什么?加载图像并模糊图像以减少噪音
将Hough Circle Transform应用于模糊的图像。
在窗口中显示检测到的圆。
2、我们将解释的示例代码可以从这里下载。 稍微更漂亮的版本(显示改变阈值的轨迹栏)可以在这里找到。
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace cv;
using namespace std;
static void help()
{
cout << "\nThis program demonstrates circle finding with the Hough transform.\n"
"Usage:\n"
"./houghcircles <image_name>, Default is ../data/board.jpg\n" << endl;
}
int main(int argc, char** argv)
{
cv::CommandLineParser parser(argc, argv,
"{help h ||}{@image|../data/board.jpg|}"
);
if (parser.has("help"))
{
help();
return 0;
}
string filename = parser.get<string>("@image");
Mat img = imread(filename, IMREAD_COLOR);
if(img.empty())
{
help();
cout << "can not open " << filename << endl;
return -1;
}
Mat gray;
cvtColor(img, gray, COLOR_BGR2GRAY);
medianBlur(gray, gray, 5);
vector<Vec3f> circles;
HoughCircles(gray, circles, HOUGH_GRADIENT, 1,
gray.rows/16, // change this value to detect circles with different distances to each other
100, 30, 1, 30 // change the last two parameters
// (min_radius & max_radius) to detect larger circles
);
for( size_t i = 0; i < circles.size(); i++ )
{
Vec3i c = circles[i];
circle( img, Point(c[0], c[1]), c[2], Scalar(0,0,255), 3, LINE_AA);
circle( img, Point(c[0], c[1]), 2, Scalar(0,255,0), 3, LINE_AA);
}
imshow("detected circles", img);
waitKey();
return 0;
}说明
1、加载图像string filename = parser.get<string>("@image");
Mat img = imread(filename, IMREAD_COLOR);
if(img.empty())
{
help();
cout << "can not open " << filename << endl;
return -1;
}2、转成灰度
Mat gray; cvtColor(img, gray, COLOR_BGR2GRAY);
3、应用中值滤波来减少噪音并避免错误的圆圈检测:
medianBlur(gray, gray, 5);
4、继续应用Hough Circle Transform:
vector<Vec3f> circles; HoughCircles(gray, circles, HOUGH_GRADIENT, 1, gray.rows/16, // change this value to detect circles with different distances to each other 100, 30, 1, 30 // change the last two parameters // (min_radius & max_radius) to detect larger circles );
以下参数:
gray:输入图像(灰度)。
circles:一个存储3个值的向量:对于每个检测到的圆圈,xc,yc,r。
HOUGH_GRADIENT:定义检测方法。 目前这是OpenCV中唯一可用的。
dp = 1:分辨率的反比。
min_dist = gray.rows / 16:检测到的中心之间的最小距离。
param_1 = 200:内部Canny边缘检测器的上阈值。
param_2 = 100 *:中心检测的阈值。
min_radius = 0:要检测的最小半径。 如果未知,则将默认设置为零。
max_radius = 0:要检测的最大半径。 如果未知,则将默认设置为零。
5、绘制检测到的圈子:
for( size_t i = 0; i < circles.size(); i++ )
{
Vec3i c = circles[i];
circle( img, Point(c[0], c[1]), c[2], Scalar(0,0,255), 3, LINE_AA);
circle( img, Point(c[0], c[1]), 2, Scalar(0,255,0), 3, LINE_AA);
}你可以看到,我们将绘制圆(红色)和中心(S)与一个小绿点
6、显示检测到的圆并等待用户退出程序:
imshow("detected circles", img);
waitKey();重新映射
使用OpenCV函数cv :: remap来实现简单的重新映射例程。理论
什么是重映射?
这是从图像中的一个位置获取像素并将其定位在新图像中的另一个位置的过程。为了完成映射过程,可能需要对非整数像素位置进行一些插值,因为在源图像和目的图像之间不总是有一对一的像素对应关系。
我们可以将每个像素位置(x,y)的重映射表示为:
g(x,y)=f(h(x,y))
其中g()是重映射后的图像,f()是源图像,h(x,y)是对(x,y)进行操作的映射函数。
让我们以一个简单的例子来思考。 想象一下,我们有一个图像,比方说,我们想要做一个重映射:
h(x,y)=(I.cols−x,y)
会发生什么? 很容易看到图像将在x方向上翻转。 例如,考虑输入图像:
观察红圈如何改变x的位置(考虑x的水平方向):
在OpenCV中,函数cv :: remap提供了一个简单的重映射实现。
代码
1、这个程序做什么?加载图像
每秒钟,将4个不同的重映射过程中的1个应用于图像,并无限期地显示在窗口中。
等待用户退出程序
2、教程代码的显示如下。 您也可以从这里下载
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace cv;
Mat src, dst;
Mat map_x, map_y;
const char* remap_window = "Remap demo";
int ind = 0;
void update_map( void );
int main( int, char** argv )
{
src = imread( argv[1], IMREAD_COLOR );
dst.create( src.size(), src.type() );
map_x.create( src.size(), CV_32FC1 );
map_y.create( src.size(), CV_32FC1 );
namedWindow( remap_window, WINDOW_AUTOSIZE );
for(;;)
{
char c = (char)waitKey( 1000 );
if( c == 27 )
{ break; }
update_map();
remap( src, dst, map_x, map_y, INTER_LINEAR, BORDER_CONSTANT, Scalar(0, 0, 0) );
// Display results
imshow( remap_window, dst );
}
return 0;
}
void update_map( void )
{
ind = ind%4;
for( int j = 0; j < src.rows; j++ )
{ for( int i = 0; i < src.cols; i++ )
{
switch( ind )
{
case 0:
if( i > src.cols*0.25 && i < src.cols*0.75 && j > src.rows*0.25 && j < src.rows*0.75 )
{
map_x.at<float>(j,i) = 2*( i - src.cols*0.25f ) + 0.5f ;
map_y.at<float>(j,i) = 2*( j - src.rows*0.25f ) + 0.5f ;
}
else
{ map_x.at<float>(j,i) = 0 ;
map_y.at<float>(j,i) = 0 ;
}
break;
case 1:
map_x.at<float>(j,i) = (float)i ;
map_y.at<float>(j,i) = (float)(src.rows - j) ;
break;
case 2:
map_x.at<float>(j,i) = (float)(src.cols - i) ;
map_y.at<float>(j,i) = (float)j ;
break;
case 3:
map_x.at<float>(j,i) = (float)(src.cols - i) ;
map_y.at<float>(j,i) = (float)(src.rows - j) ;
break;
} // end of switch
}
}
ind++;
}说明
1、创建一些我们将使用的变量:Mat src, dst; Mat map_x, map_y; char* remap_window = "Remap demo"; int ind = 0;
2、加载图像
src = imread( argv[1], 1 );
3、创建目标图像和两个映射矩阵(对于x和y)
dst.create( src.size(), src.type() ); map_x.create( src.size(), CV_32FC1 ); map_y.create( src.size(), CV_32FC1 );
4、创建一个窗口来显示结果
namedWindow( remap_window, WINDOW_AUTOSIZE );
5、建立一个循环。 每1000毫秒我们更新我们的映射矩阵(mat_x和mat_y)并将它们应用到我们的源图像:
while( true )
{
char c = (char)waitKey( 1000 );
if( c == 27 )
{ break; }
update_map();
remap( src, dst, map_x, map_y, INTER_LINEAR, BORDER_CONSTANT, Scalar(0,0, 0) );
imshow( remap_window, dst );
}应用重映射的函数是cv :: remap。 我们给出以下参数:
src:源图像
dst:与src大小相同的目标图像
map_x:x方向的映射函数。 它相当于h(i,j)的第一个分量,
map_y:与上面相同,但在y方向。 请注意,map_y和map_x的大小都与src相同
INTER_LINEAR:用于非整数像素的插值类型。 这是默认的。
BORDER_CONSTANT:默认
我们如何更新我们的映射矩阵mat_x和mat_y? 继续阅读:
6、更新映射矩阵:我们将执行4个不同的映射:
a、将图片缩小一半,并将其显示在中间:
h(i,j)=(2∗i−src.cols/2+0.5,2∗j−src.rows/2+0.5)
对于所有对(i,j),使得:src.cols4<i<3⋅src.cols4 和src.rows4<j<3⋅src.rows4
b、翻转图像:h(i,j)=(i,src.rows−j)
c、从左到右反映图像:h(i,j)=(src.cols−i,j)
d、b和c的组合:h(i,j)=(src.cols−i,src.rows−j)
这在以下片段中表示。 这里,map_x表示h(i,j)的第一个坐标,map_y表示第二个坐标。
for( int j = 0; j < src.rows; j++ )
{ for( int i = 0; i < src.cols; i++ )
{
switch( ind )
{
case 0:
if( i > src.cols*0.25 && i < src.cols*0.75 && j > src.rows*0.25 && j < src.rows*0.75 )
{
map_x.at<float>(j,i) = 2*( i - src.cols*0.25 ) + 0.5 ;
map_y.at<float>(j,i) = 2*( j - src.rows*0.25 ) + 0.5 ;
}
else
{ map_x.at<float>(j,i) = 0 ;
map_y.at<float>(j,i) = 0 ;
}
break;
case 1:
map_x.at<float>(j,i) = i ;
map_y.at<float>(j,i) = src.rows - j ;
break;
case 2:
map_x.at<float>(j,i) = src.cols - i ;
map_y.at<float>(j,i) = j ;
break;
case 3:
map_x.at<float>(j,i) = src.cols - i ;
map_y.at<float>(j,i) = src.rows - j ;
break;
} // end of switch
}
}
ind++;
}仿射变换
使用OpenCV函数cv :: warpAffine实现简单的重新映射例程。使用OpenCV函数cv :: getRotationMatrix2D来获得一个2×3的旋转矩阵
理论
什么是仿射变换?
1、可以用矩阵乘法(线性变换)和矢量加法(平移)的形式表示任何变换。2、从上面我们可以用仿射变换来表示:
旋转(线性变换)
翻转(矢量添加)
比例运算(线性变换)
您可以看到,实质上,仿射变换表示两个图像之间的关系。
3、表示仿射变换的常用方法是使用2×3矩阵。
考虑到我们想要变换2D矢量X=[xy] 通过使用A和B,我们可以等价地做到:T=A⋅[xy]+B 和 T=M⋅[x,y,1]T
T=[a00x+a01y+b00a10x+a11y+b10]
我们如何获得仿射变换?
1、很好的问题。 我们提到仿射变换基本上是两个图像之间的关系。 关于这种关系的信息大致可以通过两种方式得出:我们知道X和T,我们也知道它们是相关的。 那么我们的工作就是找M
我们知道M和X.为了获得T,我们只需要应用T=M⋅X。
我们的M的信息可能是明确的(即具有2×3的矩阵),或者它可以作为点之间的几何关系。
2、让我们稍微解释一下(b)。 由于M涉及02图像,我们可以分析两幅图像中三点相关的最简单情况。 看下面的图:
点1,点2和点3(在图像1中形成一个三角形)映射到图像2,仍然形成一个三角形,但是现在它们已经改变了。 如果我们找到这3个点的仿射变换(可以随意选择它们),那么我们可以将这个找到的关系应用到图像中的整个像素上。
代码
1、这个程序做什么?加载图像
将仿射变换应用于图像。 这个变换是从三点的关系中获得的。 为此,我们使用函数cv :: warpAffine。
在转换后将旋转应用于图像。 这种旋转是相对于图像中心而言的
等待用户退出程序
2、教程代码的显示如下。 您也可以从这里下载
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace cv;
using namespace std;
const char* source_window = "Source image";
const char* warp_window = "Warp";
const char* warp_rotate_window = "Warp + Rotate";
int main( int, char** argv )
{
Point2f srcTri[3];
Point2f dstTri[3];
Mat rot_mat( 2, 3, CV_32FC1 );
Mat warp_mat( 2, 3, CV_32FC1 );
Mat src, warp_dst, warp_rotate_dst;
src = imread( argv[1], IMREAD_COLOR );
warp_dst = Mat::zeros( src.rows, src.cols, src.type() );
srcTri[0] = Point2f( 0,0 );
srcTri[1] = Point2f( src.cols - 1.f, 0 );
srcTri[2] = Point2f( 0, src.rows - 1.f );
dstTri[0] = Point2f( src.cols*0.0f, src.rows*0.33f );
dstTri[1] = Point2f( src.cols*0.85f, src.rows*0.25f );
dstTri[2] = Point2f( src.cols*0.15f, src.rows*0.7f );
warp_mat = getAffineTransform( srcTri, dstTri );
warpAffine( src, warp_dst, warp_mat, warp_dst.size() );
Point center = Point( warp_dst.cols/2, warp_dst.rows/2 );
double angle = -50.0;
double scale = 0.6;
rot_mat = getRotationMatrix2D( center, angle, scale );
warpAffine( warp_dst, warp_rotate_dst, rot_mat, warp_dst.size() );
namedWindow( source_window, WINDOW_AUTOSIZE );
imshow( source_window, src );
namedWindow( warp_window, WINDOW_AUTOSIZE );
imshow( warp_window, warp_dst );
namedWindow( warp_rotate_window, WINDOW_AUTOSIZE );
imshow( warp_rotate_window, warp_rotate_dst );
waitKey(0);
return 0;
}说明
1、声明我们将使用的一些变量,比如矩阵来存储我们的结果,以及2个点的数组来存储定义我们的仿射变换的2D点。Point2f srcTri[3]; Point2f dstTri[3]; Mat rot_mat( 2, 3, CV_32FC1 ); Mat warp_mat( 2, 3, CV_32FC1 ); Mat src, warp_dst, warp_rotate_dst;
2、加载图像
src = imread( argv[1], 1 );
3、将目标图像初始化为与源具有相同的大小和类型:
warp_dst = Mat::zeros( src.rows, src.cols, src.type() );
4、仿射变换:正如我们在上面解释的那样,我们需要两组3点来导出仿射变换关系。 看一看:
srcTri[0] = Point2f( 0,0 ); srcTri[1] = Point2f( src.cols - 1, 0 ); srcTri[2] = Point2f( 0, src.rows - 1 ); dstTri[0] = Point2f( src.cols*0.0, src.rows*0.33 ); dstTri[1] = Point2f( src.cols*0.85, src.rows*0.25 ); dstTri[2] = Point2f( src.cols*0.15, src.rows*0.7 );
你可能想要画出点来更好地了解它们如何改变。 它们的位置与示例图(在“理论”部分)中描述的位置大致相同。 您可能会注意到3点定义的三角形的大小和方向会改变。
5、用两组点来武装,我们使用OpenCV函数cv :: getAffineTransform来计算仿射变换:
warp_mat = getAffineTransform( srcTri, dstTri );
6、我们将刚刚发现的仿射变换应用于src图像
warpAffine( src, warp_dst, warp_mat, warp_dst.size() );
有以下参数:
src:输入图像
warp_dst:输出图像
warp_mat:仿射变换
warp_dst.size():输出图像的所需大小
我们刚刚得到了我们的第一个转化的形象 我们将显示在一个位。 在此之前,我们也想旋转它…
7、旋转:要旋转图像,我们需要知道两件事:
中心相对于图像将旋转
要旋转的角度。 在OpenCV中,正角度是逆时针的
可选:比例因子
我们用下面的代码定义这些参数:
Point center = Point( warp_dst.cols/2, warp_dst.rows/2 ); double angle = -50.0; double scale = 0.6;
8、我们使用OpenCV函数cv :: getRotationMatrix2D生成旋转矩阵,该函数返回一个2×3矩阵(本例中为rot_mat)
rot_mat = getRotationMatrix2D( center, angle, scale );
9、我们现在将找到的旋转应用到之前的变换的输出。
warpAffine( warp_dst, warp_rotate_dst, rot_mat, warp_dst.size() );
10、最后,我们在两个窗口中加上原始图像来显示我们的结果,
namedWindow( source_window, WINDOW_AUTOSIZE ); imshow( source_window, src ); namedWindow( warp_window, WINDOW_AUTOSIZE ); imshow( warp_window, warp_dst ); namedWindow( warp_rotate_window, WINDOW_AUTOSIZE ); imshow( warp_rotate_window, warp_rotate_dst );
11、我们只需要等到用户退出程序
waitKey(0);
直方图均衡
什么是图像直方图,为什么它是有用的通过使用OpenCV函数cv :: equalizeHist来均衡图像的直方图
理论
什么是图像直方图?
这是一个图像的强度分布的图形表示。它量化考虑的每个强度值的像素数量。
什么是直方图均衡?
这是一种提高图像对比度的方法,以便扩展强度范围。为了使其更清楚,从上面的图像中,可以看到像素似乎聚集在可用强度范围的中间。 直方图均衡化的作用就是扩展这个范围。
看看下图:绿色的圆圈表示人口密度不足。 在应用均衡之后,我们得到一个像中心的数字的直方图。 结果图像显示在右边的图片中。
它是如何工作的?
均衡意味着将一个分布(给定的直方图)映射到另一个分布(强度值的更宽和更均匀的分布),因此强度值遍布整个范围。为了实现均衡效果,重映射应该是累积分布函数(cdf)(更多细节请参考学习OpenCV)。 对于直方图H(i),其累积分布H′(i)为:
H′(i)=∑0≤j<iH(j)
为了将其用作重映射函数,必须使H′(i)归一化,使得最大值为255(或图像强度的最大值)。 从上面的例子来看,累积函数是:
最后,我们使用一个简单的重新映射程序来获取均衡图像的强度值:
equalized(x,y)=H′(src(x,y))
代码
这个程序做什么?加载图像
将原始图像转换为灰度
通过使用OpenCV函数cv :: equalizeHist来均衡直方图
在窗口中显示来源和均衡的图像。
可下载的代码:点击这里
代码一览:
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main( int, char** argv )
{
Mat src, dst;
const char* source_window = "Source image";
const char* equalized_window = "Equalized Image";
src = imread( argv[1], IMREAD_COLOR );
if( src.empty() )
{ cout<<"Usage: ./EqualizeHist_Demo <path_to_image>"<<endl;
return -1;
}
cvtColor( src, src, COLOR_BGR2GRAY );
equalizeHist( src, dst );
namedWindow( source_window, WINDOW_AUTOSIZE );
namedWindow( equalized_window, WINDOW_AUTOSIZE );
imshow( source_window, src );
imshow( equalized_window, dst );
waitKey(0);
return 0;
}说明
1、声明源图像和目标图像以及窗口名称:Mat src, dst; char* source_window = "Source image"; char* equalized_window = "Equalized Image";
2、加载图像
src = imread( argv[1], 1 );
if( !src.data )
{ cout<<"Usage: ./Histogram_Demo <path_to_image>"<<endl;
return -1;}3、转成灰度图
cvtColor( src, src, COLOR_BGR2GRAY );
4、使用函数cv :: equalizeHist应用直方图均衡:
equalizeHist( src, dst );
因为它可以很容易地看到,唯一的参数是原始图像和输出(均衡)图像。
5、显示两个图像(原始和均衡):
namedWindow( source_window, WINDOW_AUTOSIZE ); namedWindow( equalized_window, WINDOW_AUTOSIZE ); imshow( source_window, src ); imshow( equalized_window, dst );
6、等到用户退出程序
waitKey(0); return 0;
直方图计算
使用OpenCV函数cv :: split将图像分成对应的平面。通过使用OpenCV函数cv :: calcHist来计算图像数组的直方图
通过使用函数cv :: normalize来规范一个数组
什么是直方图?
收集直方图的数据组织成一组预定义的数据库当我们说数据时,我们并没有将其限制为强度值(正如我们在前面的教程中看到的那样)。 收集的数据可以是任何您认为有用的特征来描述您的图像。
我们来看一个例子。 设想矩阵包含图像的信息(即0-255范围内的强度):
如果我们想有组织地计算这些数据会发生什么? 既然我们知道这种情况下信息值的范围是256个值,我们可以将我们的范围分割成子部分(称为bins),如下所示:
[0,255]=[0,15]∪[16,31]∪....∪[240,255]range=bin1∪bin2∪....∪binn=15
并且我们可以保持在每个二进制范围内的像素数。 把这个应用到上面的例子中,我们得到下面的图像(轴x代表箱和轴y每个像素的数量)。
这只是一个简单的例子,直方图如何工作,为什么它是有用的。
直方图不仅可以计算颜色强度,而且可以计算我们要测量的任何图像特征(即,渐变,方向等)。
让我们确定直方图的一些部分:
dims:您想要收集数据的参数数量。 在我们的例子中,dims = 1,因为我们只计算每个像素的灰度值(在灰度图像中)。
bin:每个dim中的细分数。 在我们的例子中,bin= 16
range:要测量的值的限制。 在这种情况下:range= [0,255]
如果你想要计算两个功能呢?在这种情况下,你的结果直方图是一个三维图(其中x和y对每个特征都是binx和biny,z是每个(binx,biny)组合的计数数量。(当然它变得更复杂)。
OpenCV为您提供什么
为了简单起见,OpenCV实现了cv :: calcHist函数,它计算一组数组(通常是图像或图像平面)的直方图。 它可以运行多达32个维度。 我们将在下面的代码中看到它!代码
这个程序做什么?加载图像
使用函数cv :: split将图像分割成R,G和B平面
通过调用函数cv :: calcHist来计算每个单通道平面的直方图
在窗口中绘制三个直方图
可下载的代码:点击这里
代码一览:
#include "opencv2/highgui.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace std;
using namespace cv;
int main(int argc, char** argv)
{
Mat src, dst;
String imageName( "../data/lena.jpg" ); // by default
if (argc > 1)
{
imageName = argv[1];
}
src = imread( imageName, IMREAD_COLOR );
if( src.empty() )
{ return -1; }
vector<Mat> bgr_planes; split( src, bgr_planes );
int histSize = 256;
float range[] = { 0, 256 } ;
const float* histRange = { range };
bool uniform = true; bool accumulate = false;
Mat b_hist, g_hist, r_hist;
calcHist( &bgr_planes[0], 1, 0, Mat(), b_hist, 1, &histSize, &histRange, uniform, accumulate ); calcHist( &bgr_planes[1], 1, 0, Mat(), g_hist, 1, &histSize, &histRange, uniform, accumulate ); calcHist( &bgr_planes[2], 1, 0, Mat(), r_hist, 1, &histSize, &histRange, uniform, accumulate );
// Draw the histograms for B, G and R
int hist_w = 512; int hist_h = 400;
int bin_w = cvRound( (double) hist_w/histSize );
Mat histImage( hist_h, hist_w, CV_8UC3, Scalar( 0,0,0) );
normalize(b_hist, b_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() ); normalize(g_hist, g_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() ); normalize(r_hist, r_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() );
for( int i = 1; i < histSize; i++ ) { line( histImage, Point( bin_w*(i-1), hist_h - cvRound(b_hist.at<float>(i-1)) ) , Point( bin_w*(i), hist_h - cvRound(b_hist.at<float>(i)) ), Scalar( 255, 0, 0), 2, 8, 0 ); line( histImage, Point( bin_w*(i-1), hist_h - cvRound(g_hist.at<float>(i-1)) ) , Point( bin_w*(i), hist_h - cvRound(g_hist.at<float>(i)) ), Scalar( 0, 255, 0), 2, 8, 0 ); line( histImage, Point( bin_w*(i-1), hist_h - cvRound(r_hist.at<float>(i-1)) ) , Point( bin_w*(i), hist_h - cvRound(r_hist.at<float>(i)) ), Scalar( 0, 0, 255), 2, 8, 0 ); }
namedWindow("calcHist Demo", WINDOW_AUTOSIZE );
imshow("calcHist Demo", histImage );
waitKey(0); return 0;
}
说明
1、创建必要的矩阵:Mat src, dst;
2、加载原图像
src = imread( argv[1], 1 );
if( !src.data )
{ return -1; }3、在三个R,G和B平面中分离源图像。 为此,我们使用OpenCV函数cv :: split:
vector<Mat> bgr_planes; split( src, bgr_planes );
我们的输入是要分割的图像(这种情况下有三个通道),输出是Mat的矢量)
4、现在我们准备开始配置每个平面的直方图。 由于我们正在使用B,G和R平面,所以我们知道我们的值将在[0,255]
建立bins数量(5,10 …):
int histSize = 256; //from 0 to 255
设置值的范围(如我们所说的,在0和255之间)
float range[] = { 0, 256 } ; //the upper boundary is exclusive
const float* histRange = { range };我们希望我们的箱子具有相同的尺寸(统一),并在开始时清除直方图,因此:
bool uniform = true; bool accumulate = false;
最后,我们创建Mat对象来保存我们的直方图。 创建3(每个飞机一个):
Mat b_hist, g_hist, r_hist;
我们继续使用OpenCV函数cv :: calcHist来计算直方图:
calcHist( &bgr_planes[0], 1, 0, Mat(), b_hist, 1, &histSize, &histRange, uniform, accumulate ); calcHist( &bgr_planes[1], 1, 0, Mat(), g_hist, 1, &histSize, &histRange, uniform, accumulate ); calcHist( &bgr_planes[2], 1, 0, Mat(), r_hist, 1, &histSize, &histRange, uniform, accumulate );
参数是:
&bgr_planes [0]:源数组
1:源数组的数量(在这种情况下,我们使用的是1.我们可以在这里输入一个数组列表)
0:要测量的通道(dim)。 在这种情况下,它只是强度(每个阵列是单通道),所以我们只写0。
Mat():要在源数组上使用的掩码(指示要被忽略的像素的零)。 如果没有定义,则不使用
b_hist:存储直方图的Mat对象
1:直方图维度。
histSize:每个使用尺寸的箱数
histRange:每个维度要测量的值的范围
uniform and accumulate:仓大小相同,直方图在开始时被清除。
5、创建一个图像来显示直方图:
// Draw the histograms for R, G and B int hist_w = 512; int hist_h = 400; int bin_w = cvRound( (double) hist_w/histSize ); Mat histImage( hist_h, hist_w, CV_8UC3, Scalar( 0,0,0) );
6、请注意,在绘制之前,我们首先cv::normalize直方图,使其值落在输入参数指定的范围内:
normalize(b_hist, b_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() ); normalize(g_hist, g_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() ); normalize(r_hist, r_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() );
这个函数接收这些参数:
b_hist:输入数组
b_hist:输出标准化数组(可以相同)
0和* histImage.rows:对于这个例子,它们是对r_hist的值进行标准化的上限和下限*
NORM_MINMAX:指示规范化类型的参数(如上所述,它调整之前设置的两个限制之间的值)
* - 1:*意味着输出归一化数组将与输入类型相同
Mat():可选掩码
7、最后,观察到访问bin(在这种情况下在这个1D柱状图):
for( int i = 1; i < histSize; i++ )
{
line( histImage, Point( bin_w*(i-1), hist_h - cvRound(b_hist.at<float>(i-1)) ) ,
Point( bin_w*(i), hist_h - cvRound(b_hist.at<float>(i)) ),
Scalar( 255, 0, 0), 2, 8, 0 );
line( histImage, Point( bin_w*(i-1), hist_h - cvRound(g_hist.at<float>(i-1)) ) ,
Point( bin_w*(i), hist_h - cvRound(g_hist.at<float>(i)) ),
Scalar( 0, 255, 0), 2, 8, 0 );
line( histImage, Point( bin_w*(i-1), hist_h - cvRound(r_hist.at<float>(i-1)) ) ,
Point( bin_w*(i), hist_h - cvRound(r_hist.at<float>(i)) ),
Scalar( 0, 0, 255), 2, 8, 0 );
}我们使用表达式:
b_hist.at<float>(i)
i在哪里指出维度。 如果这是一个二维直方图,我们会使用类似于:
b_hist.at<float>( i, j )
8、最后我们显示我们的直方图并等待用户退出:
namedWindow("calcHist Demo", WINDOW_AUTOSIZE );
imshow("calcHist Demo", histImage );
waitKey(0);
return 0;直方图比较
使用函数cv :: compareHist得到一个数字参数,表示两个直方图相互匹配的程度。使用不同的指标来比较直方图
理论
为了比较两个直方图(H1和H2),首先我们必须选择一个度量(d(H1,H2))来表示两个直方图的匹配程度。OpenCV实现了函数cv :: compareHist来执行比较。 它还提供了4种不同的度量来计算匹配:
1、相关性(CV_COMP_CORREL)
d(H1,H2)=∑I(H1(I)−H1¯)(H2(I)−H2¯)∑I(H1(I)−H1¯)2∑I(H2(I)−H2¯)2√
这里的:
Hk¯=1N∑JHk(J)
N是直方图bins的总数。
2、Chi-Square ( CV_COMP_CHISQR )
d(H1,H2)=∑I(H1(I)−H2(I))2H1(I)
3、相交(method= CV_COMP_INTERSECT)
d(H1,H2)=∑Imin(H1(I),H2(I))
4、Bhattacharyya距离(CV_COMP_BHATTACHARYYA)
d(H1,H2)=1−1H1¯H2¯N2√∑IH1(I)⋅H2(I)−−−−−−−−−−−√−−−−−−−−−−−−−−−−−−−−−−−−−−√
代码
这个程序做什么?加载一个基本图像和2个测试图像进行比较。
生成基本图像的下半部分的1图像
将图像转换为HSV格式
计算所有图像的H-S直方图并对它们进行归一化处理,以便比较它们。
比较基本图像的直方图与2个测试直方图,下半部分基本图像的直方图和相同的基本图像直方图。
显示获得的数字匹配参数。
可下载的代码:点击这里
代码一览:
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace std;
using namespace cv;
int main( int argc, char** argv )
{
Mat src_base, hsv_base;
Mat src_test1, hsv_test1;
Mat src_test2, hsv_test2;
Mat hsv_half_down;
if( argc < 4 )
{
printf("** Error. Usage: ./compareHist_Demo <image_settings0> <image_settings1> <image_settings2>\n");
return -1;
}
src_base = imread( argv[1], IMREAD_COLOR );
src_test1 = imread( argv[2], IMREAD_COLOR );
src_test2 = imread( argv[3], IMREAD_COLOR );
if(src_base.empty() || src_test1.empty() || src_test2.empty())
{
cout << "Can't read one of the images" << endl;
return -1;
}
cvtColor( src_base, hsv_base, COLOR_BGR2HSV );
cvtColor( src_test1, hsv_test1, COLOR_BGR2HSV );
cvtColor( src_test2, hsv_test2, COLOR_BGR2HSV );
hsv_half_down = hsv_base( Range( hsv_base.rows/2, hsv_base.rows - 1 ), Range( 0, hsv_base.cols - 1 ) );
int h_bins = 50; int s_bins = 60;
int histSize[] = { h_bins, s_bins };
// hue varies from 0 to 179, saturation from 0 to 255
float h_ranges[] = { 0, 180 };
float s_ranges[] = { 0, 256 };
const float* ranges[] = { h_ranges, s_ranges };
// Use the o-th and 1-st channels
int channels[] = { 0, 1 };
MatND hist_base;
MatND hist_half_down;
MatND hist_test1;
MatND hist_test2;
calcHist( &hsv_base, 1, channels, Mat(), hist_base, 2, histSize, ranges, true, false );
normalize( hist_base, hist_base, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_half_down, 1, channels, Mat(), hist_half_down, 2, histSize, ranges, true, false );
normalize( hist_half_down, hist_half_down, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_test1, 1, channels, Mat(), hist_test1, 2, histSize, ranges, true, false );
normalize( hist_test1, hist_test1, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_test2, 1, channels, Mat(), hist_test2, 2, histSize, ranges, true, false );
normalize( hist_test2, hist_test2, 0, 1, NORM_MINMAX, -1, Mat() );
for( int i = 0; i < 4; i++ )
{
int compare_method = i;
double base_base = compareHist( hist_base, hist_base, compare_method );
double base_half = compareHist( hist_base, hist_half_down, compare_method );
double base_test1 = compareHist( hist_base, hist_test1, compare_method );
double base_test2 = compareHist( hist_base, hist_test2, compare_method );
printf( " Method [%d] Perfect, Base-Half, Base-Test(1), Base-Test(2) : %f, %f, %f, %f \n", i, base_base, base_half , base_test1, base_test2 );
}
printf( "Done \n" );
return 0;
}说明
1、声明变量,如矩阵来存储基础图像和其他两个图像进行比较(BGR和HSV)Mat src_base, hsv_base; Mat src_test1, hsv_test1; Mat src_test2, hsv_test2; Mat hsv_half_down;
2、加载基本图像(src_base)和另外两个测试图像:
if( argc < 4 )
{ printf("** Error. Usage: ./compareHist_Demo <image_settings0> <image_setting1> <image_settings2>\n");
return -1;
}
src_base = imread( argv[1], 1 );
src_test1 = imread( argv[2], 1 );
src_test2 = imread( argv[3], 1 );3、将它们转换为HSV格式:
cvtColor( src_base, hsv_base, COLOR_BGR2HSV ); cvtColor( src_test1, hsv_test1, COLOR_BGR2HSV ); cvtColor( src_test2, hsv_test2, COLOR_BGR2HSV );
4、另外,创建基本图像的一半(以HSV格式)的图像:
hsv_half_down = hsv_base( Range( hsv_base.rows/2, hsv_base.rows - 1 ), Range( 0, hsv_base.cols - 1 ) );
5、初始化参数以计算直方图(bins,范围和通道H和S)。
int h_bins = 50; int s_bins = 60;
int histSize[] = { h_bins, s_bins };
float h_ranges[] = { 0, 180 };
float s_ranges[] = { 0, 256 };
const float* ranges[] = { h_ranges, s_ranges };
int channels[] = { 0, 1 };6、创建MatND对象来存储直方图:
MatND hist_base; MatND hist_half_down; MatND hist_test1; MatND hist_test2;
7、计算基础图像,2个测试图像和半下基本图像的直方图:
calcHist( &hsv_base, 1, channels, Mat(), hist_base, 2, histSize, ranges, true, false ); normalize( hist_base, hist_base, 0, 1, NORM_MINMAX, -1, Mat() ); calcHist( &hsv_half_down, 1, channels, Mat(), hist_half_down, 2, histSize, ranges, true, false ); normalize( hist_half_down, hist_half_down, 0, 1, NORM_MINMAX, -1, Mat() ); calcHist( &hsv_test1, 1, channels, Mat(), hist_test1, 2, histSize, ranges, true, false ); normalize( hist_test1, hist_test1, 0, 1, NORM_MINMAX, -1, Mat() ); calcHist( &hsv_test2, 1, channels, Mat(), hist_test2, 2, histSize, ranges, true, false ); normalize( hist_test2, hist_test2, 0, 1, NORM_MINMAX, -1, Mat() );
8、依次应用基本图像(Hist_base)的直方图和其他直方图之间的4种比较方法:
for( int i = 0; i < 4; i++ )
{ int compare_method = i;
double base_base = compareHist( hist_base, hist_base, compare_method );
double base_half = compareHist( hist_base, hist_half_down, compare_method );
double base_test1 = compareHist( hist_base, hist_test1, compare_method );
double base_test2 = compareHist( hist_base, hist_test2, compare_method );
printf( " Method [%d] Perfect, Base-Half, Base-Test(1), Base-Test(2) : %f, %f, %f, %f \n", i, base_base, base_half , base_test1, base_test2 );
}

相关文章推荐
- opencv(c++)图像处理(imgproc模块)
- 基于opencv和c++的图像处理:直方图均衡化
- 基于opencv和c++的图像处理:直方图匹配
- opencv中图像伪彩色处理(C++ / Python)
- OpenCV3_C++_GaussianBlur()图像高斯模糊化处理 实例
- Symbian c++调用opencv库进行图像处理
- C#调用C++图像处理算法(opencv)
- 基于opencv和c++的图像处理:直方图均衡化
- 基于opencv和c++的图像处理:直方图匹配
- [转]opencv3 图像处理 之 图像缩放( python与c++实现 )
- C++ OpenCV图像特效处理(剪影/怀旧/浮雕/国画/彩虹/素描特效)
- 图像处理之其他杂项(一)之MeanShift的目标跟踪算法opencv c++代码 VS2015+opencv3.2
- eclipse下用使用opencv用C++做图像处理
- 【开发日记】C#调用C++图像处理算法(opencv)
- 【第五课:C++和opencv】腐蚀处理图像
- opencv3 图像处理(一)图像缩放( python与c++ 实现)
- 图像处理之其他杂项(五)之水平集 LevelSet 代码实现 opencv c++ (转载)
- OpenCV3_C++_Blur()图像的模糊化处理 实例
- 【OpenCV入门教程之十一】 形态学图像处理(二):开运算、闭运算、形态学梯度、顶帽、黑帽合辑
- 【OpenCV入门教程之十】 形态学图像处理(一):膨胀与腐蚀