吴恩达Deeplearning.ai专项课程笔记(一)-- 神经网络基础
2017-11-02 18:42
681 查看
吴恩达深度学习专项课程Deeplearning.ai共开设五门课,目前已经学了大半,想起来忘了整理课程笔记,这几天抽空补上。
1.基础概念
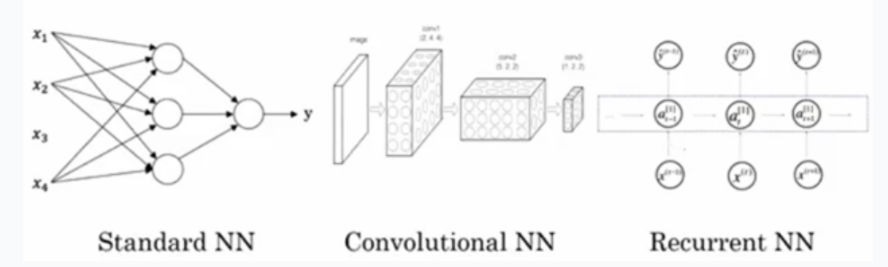
神经网络 :输入一些数据,经过隐藏层,最终得到输出,圆形节点为神经元。
神经网络样例 :(标准神经网络/卷积神经网络/循环神经网络)
结构化数据与非结构化数据 :结构化数据通常指数据库数据(每个特征都有清晰定义),非结构化数据如音频、原始音频、图像、文本等。
2.Logistic回归(二分类)
特征向量构建exm.图像特征向量的提取,把每个像素上的RGB数值(假设共nx个)提取出来排列入一个向量中,就得到一个nx维的特征向量;

深度学习符号约束
1.样本:
对(x,y)表示一个单独样本,其中x为nx维特征向量,y∈{ 0,1} (二分分类)。
2.训练集:
对于训练集中的单个样本,用圆括号加上标进行标注,如:(x(1),y(1)),(x(2),y(2)),…(x(m),y(m)) 其中m表示训练集样本个数,即:m=Mtrain。
3.矩阵符号约束:
训练集矩阵X的约定形式,将样本横向排列,写成矩阵X的列,因此矩阵维度为(nx,m),输出矩阵Y的约定形式,将样本对应标签依旧横向排列,写成矩阵Y的列,因此输出矩阵维度为(1,m)。

logistic回归
对于单个样本x,其正确标签值为y,通过logistic回归得到的预测值记为y^=P(y=1|x)(读作y hat或y帽),对应参数分别为ω,b。其中ω维数同x,为一个nx维向量,b为实数。
给定样本x(i),logistic回归公式为:
y^(i)=σ(ωTx(i)+b),z(i)=ωTx(i)+b
激发函数sigmoid函数控制y^的值在0与1之间,函数公式为σ(x)=11+e−x,函数图像如下图所示。

损失函数(也叫误差函数),用于衡量预测值与实际值间的接近程度,其定义方法有多种,如L2范数平方均值等,在Logistic回归中,定义损失函数L为:
L(y^,y)=−(ylog(y^)+(1−y)log(1−y^))
损失函数L基于单个样本定义,衡量模型在单个训练样本上的表现,针对整个训练集,采用成本函数J(cost function)衡量基于参数的总成本。
1m∑mi=1L(y^(i),y(i))=−1m∑mi=1[y(i)log(y^(i))+(1−y(i))log(1−y^(i))]
目标:找到合适的参数ω,b,使成本函数值降到最低。
梯度下降
目标:学习使成本函数尽可能小的参数ω,b
方法:首先初始化ω,b,然后进行沿最陡的下坡方向下降,直至抵达最低点(收敛到全局最优解或接近全局最优解)
公式:ω=ω−αdJ(ω)dω, α为学习率,也称为每次下降的步长,而梯度可以理解为函数曲线/曲面的方向。
1.单个样本的梯度下降
由于单个样本而言,损失函数为:
l(y^(i),y(i))=−(y(i)log(y^(i))+(1−y(i))log(1−y^(i)))
其中:z(i)=ωTx(i)+b, y^(i)=σ(z(i))
dldz=−(y(i)1σ(z)σ(z)(1−σ(z))+(1−y)11−y^(i)σ(z)(σ(z)−1))
化简结果为:σ(z)−y(i)
→dldω=dldzdzdω=(σ(z)−y(i))x(i)
→dldb=dldzdzdb=σ(z)−y(i)=dldz
2.m个样本的梯度下降
对成本函数L(ω,b)=1m∑mi=1l(y^(i),y(i)):
→dLdω=1m∑mi=1(σ(z)−y(i))x(i)
→dLdb=1m∑mi=1(σ(z)−y(i))
3.向量化
在实际编程过程中,由于在训练大数据集时,采用显式for循环导致程序运行时间复杂度过高。采用向量化的方法将消除显式for循环,加快代码运行速度。1、举例
调用numpy包,实现逻辑回归的乘法部分:z=np.dot(ω.T,x)
对向量v中每个元素做指数运算:np.exp(v)
对向量v中每个元素做对数运算:np.log(v)]
将向量v中每个元素变为绝对值:np.abs(v)
求v中每个元素和0相比的最大值:np.maximum(v,0)
对向量v中所有元素求和:np.sum(v)
2、logistic回归中向量化的实现
初始化:
参数ω初始化:ω=np.random.rand((nx,1)),维度为(nx,1)
参数b初始化,b=0,numpy的广播机制将在计算时扩充b的维度为(nx,1)
训练集矩阵:X,大小为(nx,m)
训练集样本标签: Y,大小为(1,m)
预测:
定义矩阵Z,大小为(1,m),z=np.dot(ω.T,x)+b:
Z=[ωTx(1)+b,...,ωTx(m)+b]=[z(1),z(2),...,z(m)]
预测值: A ,大小同Y,为(1,m),A=np.sigmoid(Z):
A=[σ(zx(1)),σ(z(2)),...,σ(z(m))]=[a(1),a(2),...,a(m)]
梯度下降:
由单样本梯度下降推导结果dldz=σ(z)−y(i),及m个样本推导结果{dLdω=1m∑mi=1(σ(z)−y(i))x(i)$ dLdb=1m∑mi=1(σ(z)−y(i))
有:
⎧⎩⎨⎪⎪dz=A−Ydw=1mnp.dot(dz.T,X)db=1mnp.sum(dz)
则→{ω=ω−αdω b=b−αdb

相关文章推荐
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础(转载)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-4)-- 深层神经网络(转载)
- Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-4)-- 深层神经网络
- 吴恩达 deeplearning.ai课程-卷积神经网络 (1)卷积神经网络基础
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(5-1)-- 循环神经网络
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-3)-- 浅层神经网络(转载)
- Coursera深度学习课程DeepLearning.ai 提炼笔记(1-3)-- 浅层神经网络
- Coursera吴恩达《神经网络与深度学习》课程笔记(2)-- 神经网络基础之逻辑回归
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(4-1)-- 卷积神经网络基础
- 吴恩达DeepLearning.ai笔记(1-4)-- 深层神经网络
- Coursera吴恩达《神经网络与深度学习》课程笔记(3)-- 神经网络基础之Python与向量化
- 吴恩达神经网络和深度学习课程自学笔记(二)之神经网络基础
- 302页吴恩达Deeplearning.ai课程笔记,详记基础知识与作业代码
- 【吴恩达deeplearning.ai笔记二】通俗讲解神经网络上
- Coursera吴恩达《神经网络与深度学习》课程笔记(3)-- 神经网络基础之Python与向量化
- 302页吴恩达Deeplearning.ai课程笔记,详记基础知识与作业代码
- 吴恩达深度学习课程笔记之神经网络基础