深入理解计算机系统_3e 第三章家庭作业 CS:APP3e chapter 3 homework
2017-10-29 13:12
771 查看
3.58
long decode2(long x, long y, long z)
{
int result = x * (y - z);
if((y - z) & 1)
result = ~result;
return result;
}3.59
这个题考察的是2.3.4和2.3.5节的一个定理:w比特长度的两个数相乘,会产生一个2w长度的数,不管这两个数是无符号数还是补码表示的有符号数,把结果截取的低w比特都是相同的。所以我们可以用无符号数乘法指令mulq实现有符号数乘法:先把数有符号扩展致2w位,然后把这两个2w位的数相乘,截取低2w位即可。
截取就是求模运算,即 mod 2^w。
store_prod movq %rdx, %rax #rax中保存y cqto #将rax有符号扩展为rdx:rax,即rdx为全1 movq %rsi, %rcx #rcx中保存x sarq $63, %rcx #rcx为为全1若x小于0,否则为0,即将x有符号扩展 #下面把这两个扩展的数当成无符号数进行运算,取低128bit。 #此时y表示为rdx:rax,x表示为rcx:rsi, 即y = rdx*2^64 + rax, x = rcx*2^64 + rsi #x*y = rdx*rcx*2^128 + rdx*rsi*2^64 + rcx*rax*2^64 + rax*rsi #由于我们只需要取低128位,所以对x*y进行取模操作mod 128,得到公式:rdx*rsi*2^64mod2^128 + rcx*rax*2^64mod2^128 + rax*rsi #由于这里的寄存器都是64位的,所以对于rdx*rsi*2^64mod2^128这样的操作我们可以直接使用imulq指令,截取两个寄存器相乘的低64位,然后把他加到rax*rsi的高64位。 #下面实现公式 imulq %rax, %rcx #rcx*rax*2^64mod2^128(随后放在高64位) imulq %rsi, %rdx #rdx*rsi*2^64mod2^128(随后放在高64位) addq %rdx, %rcx #随后放在高64位 mulq %rsi #x*y即rax*rsi addq %rcx, %rdx #放在高64位 movq %rax, (%rdi) #存储低64位 movq %rdx, 8(%rdi) #存储高64位 ret
3.60
A. x : %rdi n : %esi result : %rax mask : %rdxB. result = 0 mask = 1
C. mask != 0
D. mask >>= n
E. result |= (x & mask)
long loop(long x, int n)
{
long result = 0;
long mask;
for(mask = 1; mask != 0; mask >>= n)
{
result |= (x & mask);
}
return result;
}3.61
long cread_alt(long *xp)
{
static long tmp = 0;
if(xp == 0)
{
xp = &tmp;
}
return *xp;
}这个地方也是很无语,在我的环境下必须将tmp的存储类型设置为静态存储,并且将gcc的优化设置为O3,这样才能生成使用conditional transfer的指令(才能让gcc相信优化是值得的。。):
00000000004004f0 <cread_alt>: 4004f0: 48 85 ff test %rdi,%rdi 4004f3: b8 38 10 60 00 mov $0x601038,%eax 4004f8: 48 0f 44 f8 cmove %rax,%rdi 4004fc: 48 8b 07 mov (%rdi),%rax 4004ff: c3 retq
3.62
typedef enum {MODE_A, MODE_B, MODE_C, MODE_D, MODE_E}
long switch3(long *p1, long *p2, mode_t action)
{
long result = 0;
switch(action)
{
case MODE_A:
result = *p2;
*p2 = *p1;
break;
case MODE_B:
result = *p1 + *p2;
*p1 = result;
break;
case MODE_C:
*p1 = 59;
result = *p2;
break;
case MODE_D:
*p1 = *p2;
case MODE_E:
result = 27;
break;
default:
result = 12;
}
return result;
}3.63
long switch_prob(long x, long n)
{
long result = x;
switch(n)
{
case 0:
case 2:
result += 8;
break;
case 3:
result >>= 3;
break;
case 4:
result = (result << 4) - x;
case 5:
result *= result;
default:
result += 0x4b;
}
return result;
}3.64
A. &A[i][j][k] = Xa + L(i*S*T + j*T + k)B. R = 7,S = 5,T = 13
3.65
A. rdx (每次移位8,即按行移动)B. rax(每次移位120 = 8 * 15,按列移动)
C. 由B,M = 15
3.66
NR(n)是数组的行数,所以我们找循环的次数,即rdi,得到rdi = 3n.NC(n)是数组的列数,所以我们应该找每次循环更新时对指针增加的值,这个值等于sizeof(long) * NC(n),即r8,得到r8 = 8 * (4n + 1).
综上,可知两个宏定义:
#define NR(n) (3*(n)) #define NC(n) (4*(n)+1)
3.67
A.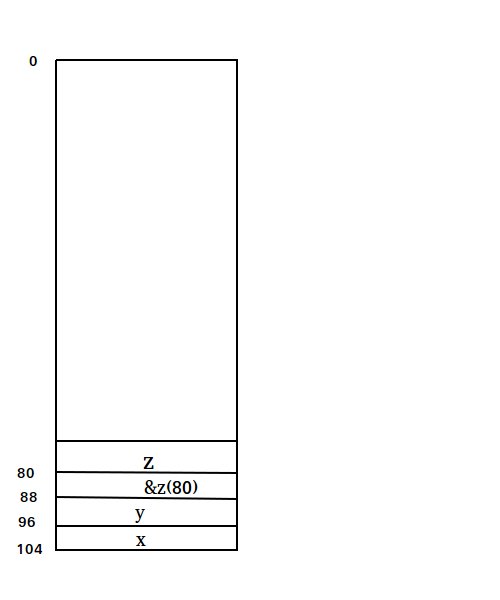
B. %rsp + 64
C. 通过以%rsp作为基地址,偏移8、16、24来获取strA s的内容(由于中间夹了一个返回地址,所以都要加8)
D. 通过传进来的参数%rdi(%rsp + 64 + 8),以此作为基地址,偏移8、16、24来写入strB r
E.
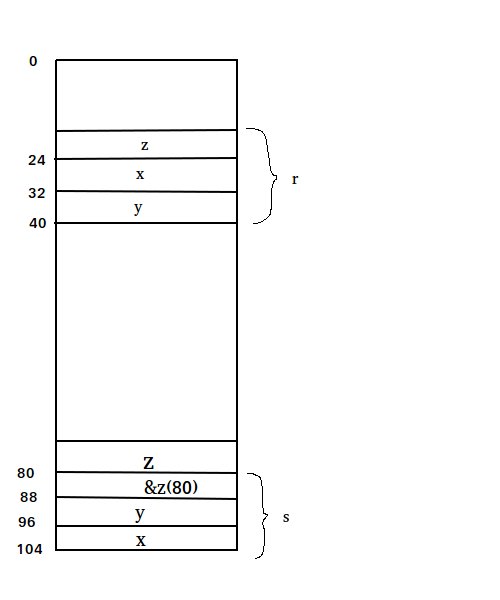
F. 我记得我在看《C语言程序设计: 现代方法 2rd》的时候,里面说传递聚合类型的变量可以使用指针,这样比传递整个数据结构要快一些(当然写操作会改变实参)。这个题目里面也都是读操作,可以发现编译器自动进行了优化——传递了基地址而非复制了整个数据结构。返回就是在调用它的函数的栈帧中存入一个相关的数据结构。(这个题里面process其实没有栈帧,如果返回地址算eval的话)
3.68
这题考察的是内存对齐。通过结构体成员的位置逐渐缩小范围:int t 为8(%rsi),所以4<B<=8
long u 为32(%rsi),所以24 < 8 + 4 + 2*a <= 32,得到6<A<=10
long y 为184(%rdi),所以176 < 4*A*B <= 184,得44 < A*B <=46。
所以AB = 45 或者AB = 46,结合A, B各自的范围,只可能为A = 9, B = 5.
3.69
A. 根据第4、5行的指令, idx的值为(bp + 40i + 8),由第1、2行指令,这里的8是因为第一个int first整数和内存对齐的原因,所以每一个a_struct的大小为40字节。由于0x120 - 0x8 = 280字节,所以CNT = 280/40 = 7.
B. 由第6、7行指令知,idx和x数组内元素都是signed long类型的。由于整个a_struct数据类型大小为40字节,所以其内部应该为8*5 = 8 + 8*4:
typedef struct
{
long idx;
long x[4];
}3.70
A.e1.p : 0
e1.y : 8
e2.x : 0
e2.next : 8
B. 16 bytes
C.
void proc(union ele *up)
{
up->x = *(up->e2.next->e1.p) - up->e2.next->e1.y;
}3.71
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE_OF_BUFFER 10
int good_echo(void)
{
char *buffer = calloc(SIZE_OF_BUFFER, sizeof(char));
if (buffer == NULL)
{
fprintf(stderr, "Error: failed to allocate buffer.\n");
return -1;
}
while(1)
{
fgets(buffer, SIZE_OF_BUFFER, stdin);
if (strlen(buffer) == SIZE_OF_BUFFER-1) /*两种情况,一种是刚好输入了能填满缓冲区的字符数,另一种是大于缓冲区,一次不能读完*/
{
fputs(buffer, stdout);
if (buffer[SIZE_OF_BUFFER-1-1] == '\n')/*刚好输入了能填满缓冲区的字符数,结束读入*/
{
break;
}
memset(buffer, 0, strlen(buffer));/*清空缓冲区,因为要通过strlen判断读入了多少字符,继续读入*/
}
else if (strlen(buffer) < SIZE_OF_BUFFER-1)/*一定是最后一次读入,结束读入*/
{
fputs(buffer, stdout);
break;
}
else
{
break;
}
}
free(buffer);
return 0;
}
int main(int argc, char const *argv[])
{
return good_echo();
}3.72
A. andq $-16, X这条指令相当于将低4位置零,也就是使得rax中保存的8n+30对16取整。所以s2-s1为8n+30对16取整的结果。B. p的值为rsp(r8)-15对16取整的结果,确保了p数组的起始地址为16的整数倍。
C. 8n + 30对16取整有两种可能:一种是8n本身就是16的整数倍即n = 2k,此时取整后为8n+16; 另一种是8n = 16k + 8即n = 2k + 1,此时取整后为8n + 24。由System V AMD64 ABI标准可知,s1的地址为16的整数倍(即结尾为0000),所以s2的地址也肯定是16的整数倍(结尾为0000)。又因p是由s2减15对16取整得到的结果,所以p和s2之间肯定相差2字节,即e2 = 2 bytes. 所以e1最大为(n为奇数) :8n + 24 - 16 - 8n = 8 bit, 最小为(n为偶数):8n + 16 -16 - 8n = 0.(这个题我估计没有考虑到ABI标准对于栈帧对齐的问题,s1的地址本来就应该是16的整数倍)
D. 由A B C可知,这种方法保证了s2 和 p的起始地址为16的整数倍,而且保证了e1最小为8n,能够存储p数组。
浮点数部分并未测试
3.73
find_range: vxorps %xmm1, %xmm1, %xmm1 vucomiss %xmm0, %xmm1 ja .L5 jp .L8 movl $1, %eax je .L3 .L8: seta %al movzbl %al, %eax addl $2, %eax ret .L5: movl $0, %eax .L3: rep;ret
3.74
find_range: vxorps %xmm1, %xmm1, %xmm1 vucomiss %xmm0, %xmm1 cmova $0, %eax cmove $1, %eax cmovb $2, %eax cmovp $3, %eax rep;ret
3.75
A. 每一个复数变量使用两个%xmm寄存器传送。B. 通过%xmm0和%xmm1返回一个复数类型值。

相关文章推荐
- 深入理解计算机系统_3e 第四章家庭作业(部分) CS:APP3e chapter 4 homework
- 深入理解计算机系统_3e 第二章家庭作业 CS:APP3e chapter 2 homework
- 深入理解计算机系统_3e 第五章家庭作业 CS:APP3e chapter 5 homework
- 深入理解计算机系统_3e 第八章家庭作业 CS:APP3e chapter 8 homework
- 深入理解计算机系统_3e 第十章家庭作业 CS:APP3e chapter 10 homework
- 深入理解计算机系统_3e 第七章家庭作业 CS:APP3e chapter 7 homework
- 深入理解计算机系统_3e 第十一章家庭作业 CS:APP3e chapter 11 homework
- 深入理解计算机系统_3e 第六章家庭作业 CS:APP3e chapter 6 homework
- CS:APP3e 深入理解计算机系统_3e Y86-64模拟器指南
- CS:APP3e 深入理解计算机系统_3e Attacklab 实验
- CS:APP3e 深入理解计算机系统_3e Datalab实验
- CS:APP3e 深入理解计算机系统_3e ShellLab(tsh)实验
- CS:APP3e 深入理解计算机系统_3e C Programming Lab实验
- CS:APP3e 深入理解计算机系统_3e CacheLab实验
- CS:APP3e 深入理解计算机系统_3e MallocLab实验
- CS:APP3e 深入理解计算机系统_3e bomblab实验
- 深入理解计算机系统(第二版) 家庭作业 第三章
- 知其然,也要知其所以然,《CS: APP--深入理解计算机系统(原书第2版)》 书评
- cs app深入理解计算机系统:第五章 优化程序性能 几个优化的java实现