大数据-Hadoop-MapReduce (二) WrodCount单词计算
2017-10-29 12:39
337 查看
一句话理解: 将很多很多的文本文件遍历计算出每一个单词出现的次数
-扩展阅读TF-IDF词频-逆向文档频率
(WordCount).单词计算
有文本如下:a b c
b b c
c d c
需得到结果为:
a 1
b 3
c 4
d 1
原理如图:
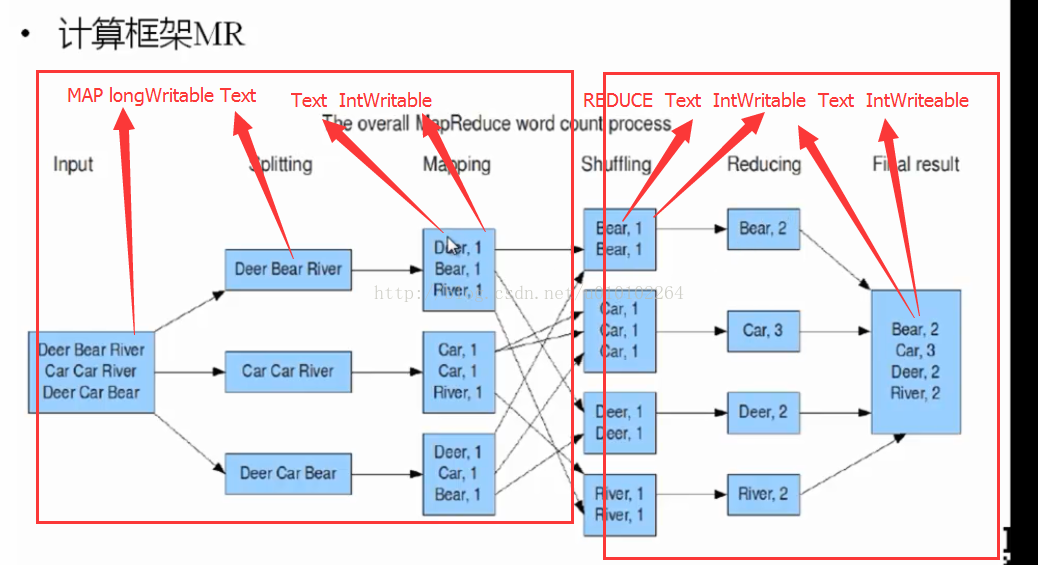
1)Map 将每一行的单词计数为1 Map<word,1>
// 输入为一行行的数据 其中 LongWritable key为下标,Text value 为这一行文本
// 假设这一行数据为 b c d e e e e
public static class TokenizerMapper extends Mapper {
protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper.Context context)
throws IOException, InterruptedException {
String lineStr = value.toString();// 得到一行文本
// 使用空格分离 默认参数为空格
StringTokenizer words = new StringTokenizer(lineStr);
while (words.hasMoreElements()) {
String word = words.nextToken();// 得到这个单词
//if(word.contains("Maturity"))
// 交这个单词计数+1
context.write(new Text(word), new IntWritable(1));// 输出到map
}
}
}2)Shuffling 对每一个单词进行分类合并 Map<word,<1,1>>
3)Reduce 对每一个单词累加 word = 1 + 1
// input e1 e1 e1 e1
// output e4
//public static class IntSumReducer extends Reducer {
public static class IntSumReducer extends Reducer {
public void reduce(Text key, Iterable values, Reducer.Context context) throws IOException, InterruptedException {
int count = 0;
// String word = key.toString();
for (IntWritable intWritable : values) {
// 循环
count += intWritable.get();
}
// 输出
context.write(key, new IntWritable(count));
}
}4)Job运算
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String inputPath = "input/wordcount";
String outputPath = "output/wordcount";
// String[] otherArgs = (new GenericOptionsParser(conf,
// args)).getRemainingArgs();
String[] otherArgs = new String[] { inputPath, outputPath }; /* 直接设置输入参数 */
// delete output
Path outputPath2 = new Path(outputPath);
outputPath2.getFileSystem(conf).delete(outputPath2, true);
// run
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] ");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
//job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//output file total
//job.setNumReduceTasks(1);//reducer task num
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}转载请注明出处,谢谢!

相关文章推荐
- Hadoop2.2.0 第一步完成MapReduce wordcount计算文本数量
- [python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差
- hadoop之魂--mapreduce计算框架,让收集的数据产生价值
- hadoop之魂--mapreduce计算框架,让收集的数据产生价值
- 和我一起学Hadoop(五):MapReduce的单词统计,wordcount
- 一个mapreduce得到需要计算单词概率的基础数据
- hadoop初识之十二:wordcount 处理过程和mapreduce的数据类型
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
- HADOOP(1)__Mapreduce_WordCount统计单词数
- hadoop基础----hadoop实战(三)-----hadoop运行MapReduce---对单词进行统计--经典的自带例子wordcount
- Hadoop学习笔记—4.初识MapReduce 一、神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算。对于大数据
- hadoop案例实现之WordCount (计算单词出现的频数)
- hadoop基础----hadoop实战(三)-----hadoop运行MapReduce---对单词进行统计--经典的自带例子wordcount
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
- hadoop入门(六)JavaAPI+Mapreduce实例wordCount单词计数详解
- [hadoop]简单的MapReduce项目,计算文件中单词出现的次数(五)
- 使用Hadoop的mapReduce实现计算单词数
- Hadoop的集群数据、mapreduce管理及安全机制介绍
- Hadoop之道--MapReduce之Hello World实例wordcount