Spatial Transformer Networks 论文笔记
2017-10-27 19:26
751 查看
Spatial Transformer Networks 论文笔记
简介
Spatial Transformer Networks和BN一样相当于一个小插件,放在卷积网络中,其主要目的是对齐网络的每个输入。比如MNIST的手写数字识别,如果有一个图像中的数字有一定角度倾斜或偏移,Spatial Transformer可以对输入图像进行仿射变换,让CNN真正的输入变成对齐后的数字图像。
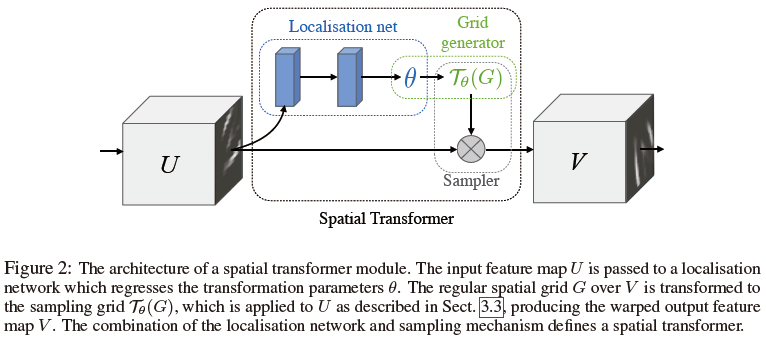
网络
网络结构如Figure2所示。比如一开始某层CNN是以U作为输入的话,添加一个Spatial Transformer,该层的输入就变成V了。Spatial Transformer由Localisation Network、grid generator和sampler三个部分组成。Localisation Network以特征图U为输入,输出一组参数θ。参数具体多少取决于需要的转换形式,例如仿射变换中θ就需要6-dimension。网络可以是全连接,也可以是卷积,不管怎样最后都有一个regression layer。
4000
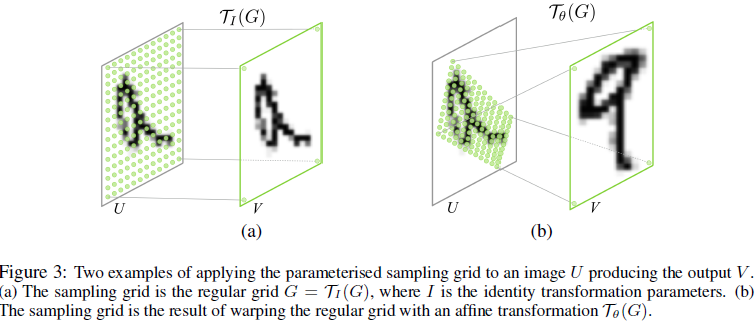
Grid generator其实就是生成一堆grid,对图像进行变换(可以是恒等变换,也可以是仿射变换)。
这一步的公式为
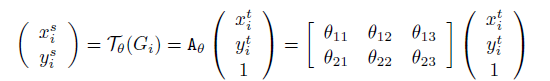
看上去像是从目标V变到原始的U,但其实这用的是逆向坐标映射。不用正向的原因网上说是会牺牲额外的空间存储映射源。此时V还未知,所以需要下一步的sampler提取。
Sampler用的是双线性插值核,前面先通过V中的坐标找到了U中的坐标,这一步就是再通过双线性插值采样出真实的像素值,放到V中:

之所以这样设计,是为了使采样过程可微,便于反向传播。
这一块还是没有怎么看明白,尤其是Grid的Tθ(G)为什么是从V中得来,这样就不是单纯的前向传播网络。这里描述的公式在网络中的流动形式也不是很懂。
封装
总之,实现了上面的spatial transformer networks后,就可以将它放到CNN里面。它会把如何变换每个训练样本这一知识储存到localisation network的权重中。另外,一个CNN里面也可以放置多个STN,后面的STN转换的就是特征图了。实验
作者在Distorted MNIST、Street View House Numbers、Fine-Grained Classification三个方面做了实验。前两个做的都是数字识别,加了STN的网路都能够自动对齐数字,准确度也有提高。比较有意思的是第三个,作者在CUB-200-2011 birds dataset上实验,并且只有图像级的分类标注。在训练过后,两个pipeline的STN居然可以做到一个检测头部,一个检测身体,变成了一个part detector,而且并没有任何关于part的标注数据。

相关文章推荐
- 论文笔记:Spatial Transformer Networks中的仿射变换和双线性插值
- [深度学习论文笔记][Attention] Spatial Transformer Networks
- 【论文笔记】Spatial Transformer Networks
- 论文笔记:Spatial Transformer Networks(空间变换网络)
- 论文笔记:Spatial Transformer Networks中的仿射变换和双线性插值
- 【论文笔记】Spatial Transformer Networks
- 论文笔记:Spatial Transformer Networks(空间变换网络)
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
- 深度学习论文笔记-Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文阅读《Spatial Transformer Networks》
- 【论文阅读笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- spatial transformer networks 这篇论文
- 论文笔记|Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文笔记 《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
- RCNN学习笔记(1):《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》论文笔记
- 深度学习论文笔记:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 【论文笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition--SPP-net论文笔记
- 论文阅读笔记-Segmentation-Aware Convolutional Networks Using Local Attention Masks
- 经典重读 | 深度学习方法:卷积神经网络结构变化——Spatial Transformer Networks