spark基础之spark sql运行原理和架构
2017-10-27 09:21
495 查看
一 Spark SQL运行架构
Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑定、优化等处理过程。Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:
Core: 负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等
Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等
Hive: 负责对Hive数据进行处理
Hive-ThriftServer: 主要用于对hive的访问
1.1 TreeNode
逻辑计划、表达式等都可以用tree来表示,它只是在内存中维护,并不会进行磁盘的持久化,分析器和优化器对树的修改只是替换已有节点。
TreeNode有2个直接子类,QueryPlan和Expression。QueryPlam下又有LogicalPlan和SparkPlan. Expression是表达式体系,不需要执行引擎计算而是可以直接处理或者计算的节点,包括投影操作,操作符运算等
1.2 Rule & RuleExecutor
Rule就是指对逻辑计划要应用的规则,以到达绑定和优化。他的实现类就是RuleExecutor。优化器和分析器都需要继承RuleExecutor。每一个子类中都会定义Batch、Once、FixPoint. 其中每一个Batch代表着一套规则,Once表示对树进行一次操作,FixPoint表示对树进行多次的迭代操作。RuleExecutor内部提供一个Seq[Batch]属性,里面定义的是RuleExecutor的处理逻辑,具体的处理逻辑由具体的Rule子类实现。
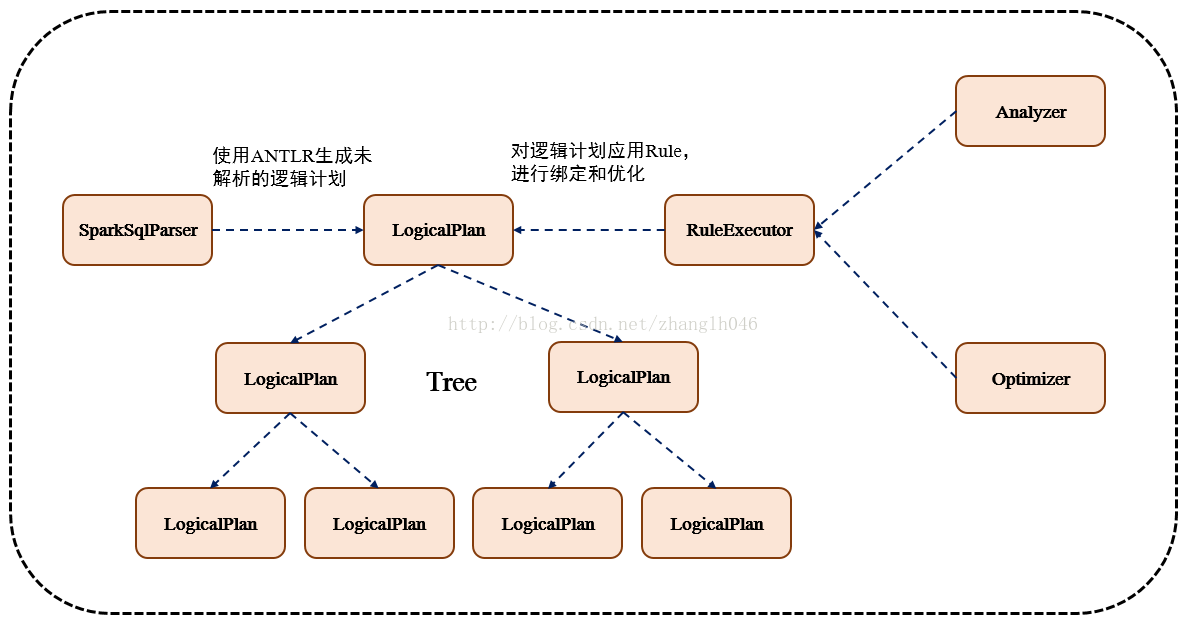
整个流程架构图:
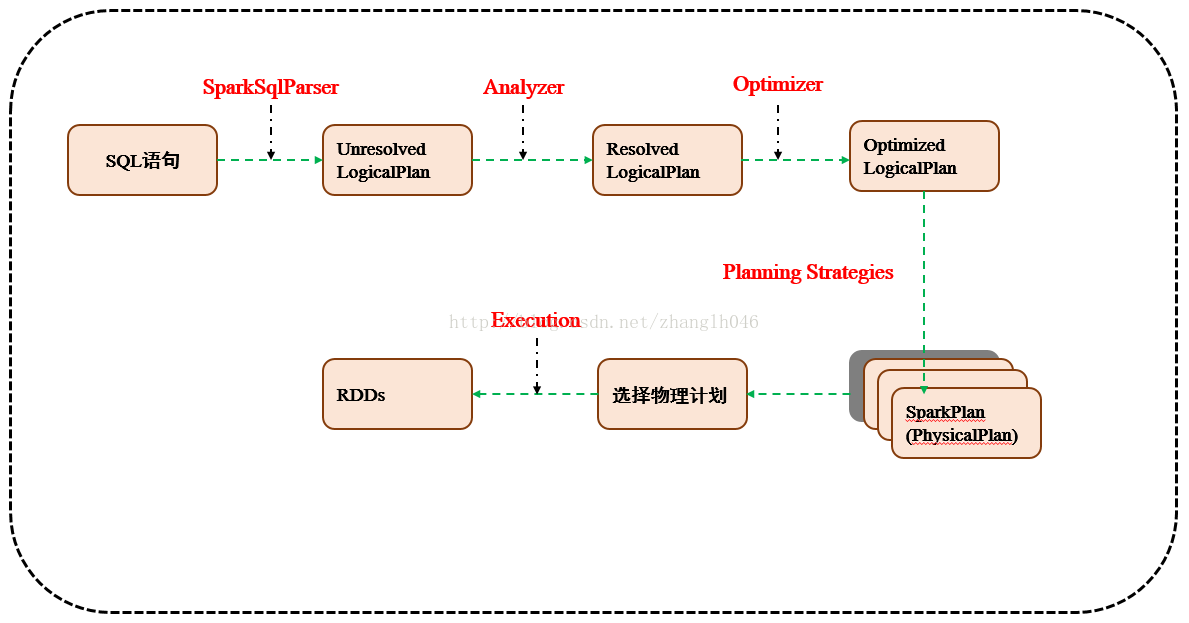
二 Spark SQL运行原理
2.1 使用SessionCatalog保存元数据
在解析SQL语句之前,会创建SparkSession,或者如果是2.0之前的版本初始化SQLContext,SparkSession只是封装了SparkContext和SQLContext的创建而已。会把元数据保存在SessionCatalog中,涉及到表名,字段名称和字段类型。创建临时表或者视图,其实就会往SessionCatalog注册
2.2 解析SQL,使用ANTLR生成未绑定的逻辑计划
当调用SparkSession的sql或者SQLContext的sql方法,我们以2.0为准,就会使用SparkSqlParser进行解析SQL. 使用的ANTLR进行词法解析和语法解析。它分为2个步骤来生成Unresolved LogicalPlan:
# 词法分析:Lexical Analysis,负责将token分组成符号类
# 构建一个分析树或者语法树AST
2.3 使用分析器Analyzer绑定逻辑计划
在该阶段,Analyzer会使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
2.4 使用优化器Optimizer优化逻辑计划
优化器也是会定义一套Rules,利用这些Rule对逻辑计划和Exepression进行迭代处理,从而使得树的节点进行和并和优化
2.5 使用SparkPlanner生成物理计划
SparkSpanner使用Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan.
2.6 使用QueryExecution执行物理计划
此时调用SparkPlan的execute方法,底层其实已经再触发JOB了,然后返回RDD
Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑定、优化等处理过程。Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:
Core: 负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等
Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等
Hive: 负责对Hive数据进行处理
Hive-ThriftServer: 主要用于对hive的访问
1.1 TreeNode
逻辑计划、表达式等都可以用tree来表示,它只是在内存中维护,并不会进行磁盘的持久化,分析器和优化器对树的修改只是替换已有节点。
TreeNode有2个直接子类,QueryPlan和Expression。QueryPlam下又有LogicalPlan和SparkPlan. Expression是表达式体系,不需要执行引擎计算而是可以直接处理或者计算的节点,包括投影操作,操作符运算等
1.2 Rule & RuleExecutor
Rule就是指对逻辑计划要应用的规则,以到达绑定和优化。他的实现类就是RuleExecutor。优化器和分析器都需要继承RuleExecutor。每一个子类中都会定义Batch、Once、FixPoint. 其中每一个Batch代表着一套规则,Once表示对树进行一次操作,FixPoint表示对树进行多次的迭代操作。RuleExecutor内部提供一个Seq[Batch]属性,里面定义的是RuleExecutor的处理逻辑,具体的处理逻辑由具体的Rule子类实现。
整个流程架构图:
二 Spark SQL运行原理
2.1 使用SessionCatalog保存元数据
在解析SQL语句之前,会创建SparkSession,或者如果是2.0之前的版本初始化SQLContext,SparkSession只是封装了SparkContext和SQLContext的创建而已。会把元数据保存在SessionCatalog中,涉及到表名,字段名称和字段类型。创建临时表或者视图,其实就会往SessionCatalog注册
2.2 解析SQL,使用ANTLR生成未绑定的逻辑计划
当调用SparkSession的sql或者SQLContext的sql方法,我们以2.0为准,就会使用SparkSqlParser进行解析SQL. 使用的ANTLR进行词法解析和语法解析。它分为2个步骤来生成Unresolved LogicalPlan:
# 词法分析:Lexical Analysis,负责将token分组成符号类
# 构建一个分析树或者语法树AST
2.3 使用分析器Analyzer绑定逻辑计划
在该阶段,Analyzer会使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
2.4 使用优化器Optimizer优化逻辑计划
优化器也是会定义一套Rules,利用这些Rule对逻辑计划和Exepression进行迭代处理,从而使得树的节点进行和并和优化
2.5 使用SparkPlanner生成物理计划
SparkSpanner使用Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan.
2.6 使用QueryExecution执行物理计划
此时调用SparkPlan的execute方法,底层其实已经再触发JOB了,然后返回RDD

相关文章推荐
- Spark SQL运行原理和架构
- MySQL运行原理与基础架构
- MySQL运行原理与基础架构
- 【转载】Spark系列之运行原理和架构
- MySQL运行原理与基础架构详解
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
- SparkSQL的原理以及架构
- MySQL----基础架构及运行原理
- Spark集群基础概念 与 spark架构原理
- sparkSQL1.1入门之二:sparkSQL运行架构
- MySQL运行原理与基础架构
- MySQL运行原理与基础架构细说
- sparkSQL1.1入门之二:sparkSQL运行架构
- sparkSQL1.1入门之二:sparkSQL运行架构
- MySQL运行原理与基础架构
- MySQL运行原理与基础架构
- Spark作业运行架构原理解析
- spark-sql架构与原理
- MySQL运行原理与基础架构 推荐