论文笔记——MobileNets(Efficient Convolutional Neural Networks for Mobile Vision Applications)
2017-10-23 20:05
821 查看
论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNet由Google提出的一种新的卷积计算方法,旨在加速卷积计算过程。
为了减小网络模型大小,提出了两种比较暴力的裁剪方法。
(1) 直接对channel进行裁剪,这种随机砍掉一些channel,也太暴力了吧,砍多了效果肯定不好,想想都知道。
(2) 减少输入图像的分辨率,也就是减小输入的尺寸大小。
我们还是关注新的卷积计算方法,要做压缩的话,还是另辟蹊径。
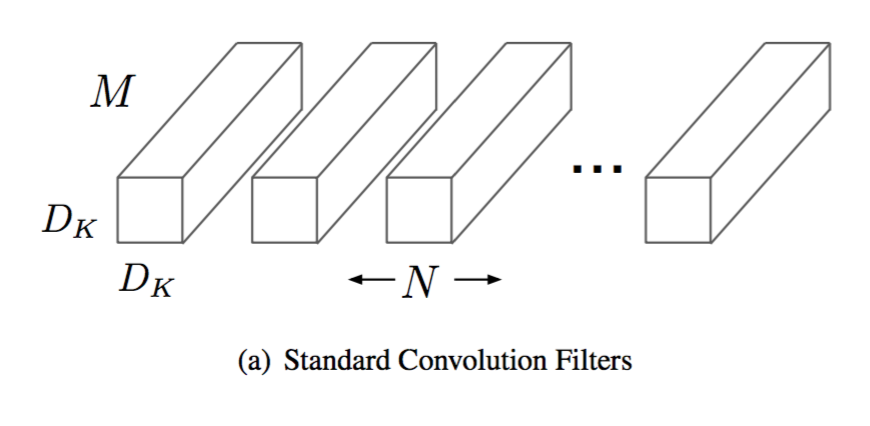
M表示输入的channel, N表示输出的channel,Dk表示kernel size.
我们可以看到输出的每一个channel,都跟所有的输入channel有关,也就是说,对于输出的一个channel,都是M个kernel与M个channel卷积以后的求和结果。
差别就在这里!在depthwise separable中,每一个输出的channel,只和一个输入的channel有关。
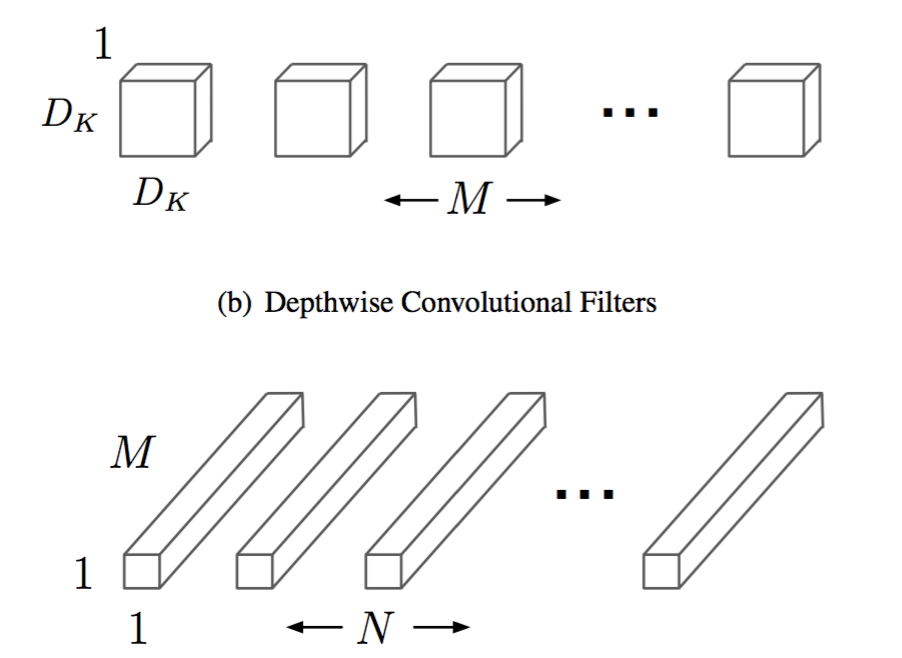
输入M个channel,那么输出也是M个channel,每一个channel都是由一个kernel在一个channel卷积以后得到的结果,不在是和所有的输入相关了。这也就是为什么名字叫做depthwise separable(深度级的分离,channel的分离)。
但是我们发现输出只有M个channel,而我们想要输出N个channel,这个时候我们应该想到1*1的convolution,这个时候的卷积就是full convolution。这个时候输出的每一个channel都和输入有关了,相当于输入的加权求和。所以1x1的卷积有联合(combine)的作用。
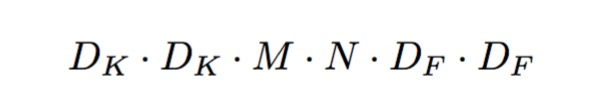
Dk表示kernel size, M表示输入的channel,也就是feature map的个数,N表示输出的channel。Df表示feature map的大小,也就是width和height, 上面这个式子再一次验证了我们上面说的,输出的每一个channel都和输入的所有channel有关。
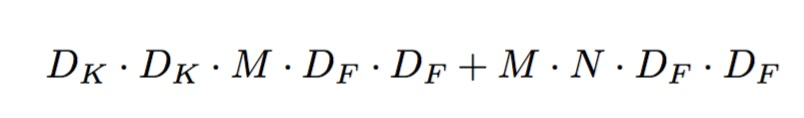
求和的左半部分,表示depthwise separable的计算量,可以看到输出为M个channel,每个输出channel只和一个channel有关。
求和的有半部分,表示1x1 pointwise convolution,可以看到每一个输出channel,都和M个输入有关(M个输入的加权求和)。
计算量较少比例
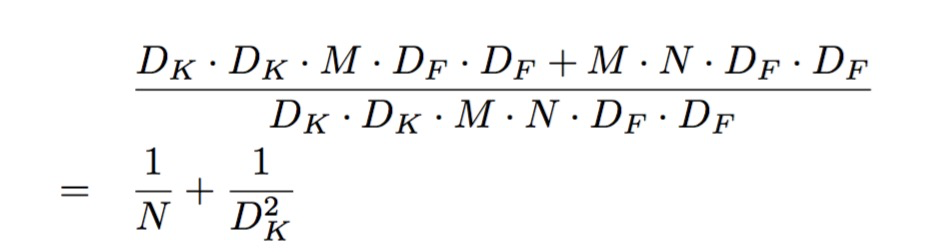
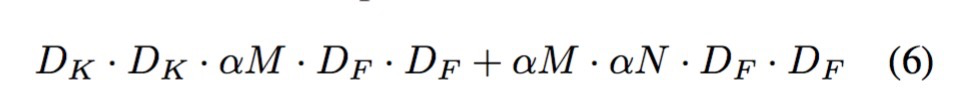
上面公式可以看到直接对输入的M个channel进行的压缩(随机采样)
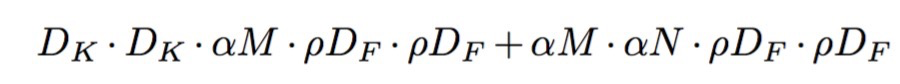
上面公式可以看到对不仅对输出的channel进行了采样,对输入图像的分辨率也进行了减小。

Caffe实现(trick): https://github.com/shicai/MobileNet-Caffe
(通过caffe 的group参数来实现depthwise的操作的,由于实现的问题和cuda/cudnn对其支持得不好,训练起来十分慢。前向预测时在CPU上的耗时大概是googlenet的70%。这个数据参考一篇博文的,未实践过。)
Pytorch实现:https://github.com/marvis/pytorch-mobilenet
现在市面上已经有很多裁剪方法了,没必要用这么暴力的进行裁剪来压缩模型大小。
MobileNet由Google提出的一种新的卷积计算方法,旨在加速卷积计算过程。
为了减小网络模型大小,提出了两种比较暴力的裁剪方法。
(1) 直接对channel进行裁剪,这种随机砍掉一些channel,也太暴力了吧,砍多了效果肯定不好,想想都知道。
(2) 减少输入图像的分辨率,也就是减小输入的尺寸大小。
我们还是关注新的卷积计算方法,要做压缩的话,还是另辟蹊径。
1. Full convolution VS. Depthwise separable convolution
1.1 Full convolution
M表示输入的channel, N表示输出的channel,Dk表示kernel size.
我们可以看到输出的每一个channel,都跟所有的输入channel有关,也就是说,对于输出的一个channel,都是M个kernel与M个channel卷积以后的求和结果。
差别就在这里!在depthwise separable中,每一个输出的channel,只和一个输入的channel有关。
1.2 Depthwise separable convolution
输入M个channel,那么输出也是M个channel,每一个channel都是由一个kernel在一个channel卷积以后得到的结果,不在是和所有的输入相关了。这也就是为什么名字叫做depthwise separable(深度级的分离,channel的分离)。
但是我们发现输出只有M个channel,而我们想要输出N个channel,这个时候我们应该想到1*1的convolution,这个时候的卷积就是full convolution。这个时候输出的每一个channel都和输入有关了,相当于输入的加权求和。所以1x1的卷积有联合(combine)的作用。
2. 计算量对比
只要理解了两个的差别,不难算出计算直接的差别。Dk表示kernel size, M表示输入的channel,也就是feature map的个数,N表示输出的channel。Df表示feature map的大小,也就是width和height, 上面这个式子再一次验证了我们上面说的,输出的每一个channel都和输入的所有channel有关。
求和的左半部分,表示depthwise separable的计算量,可以看到输出为M个channel,每个输出channel只和一个channel有关。
求和的有半部分,表示1x1 pointwise convolution,可以看到每一个输出channel,都和M个输入有关(M个输入的加权求和)。
计算量较少比例
3. 模型压缩
上面公式可以看到直接对输入的M个channel进行的压缩(随机采样)
上面公式可以看到对不仅对输出的channel进行了采样,对输入图像的分辨率也进行了减小。
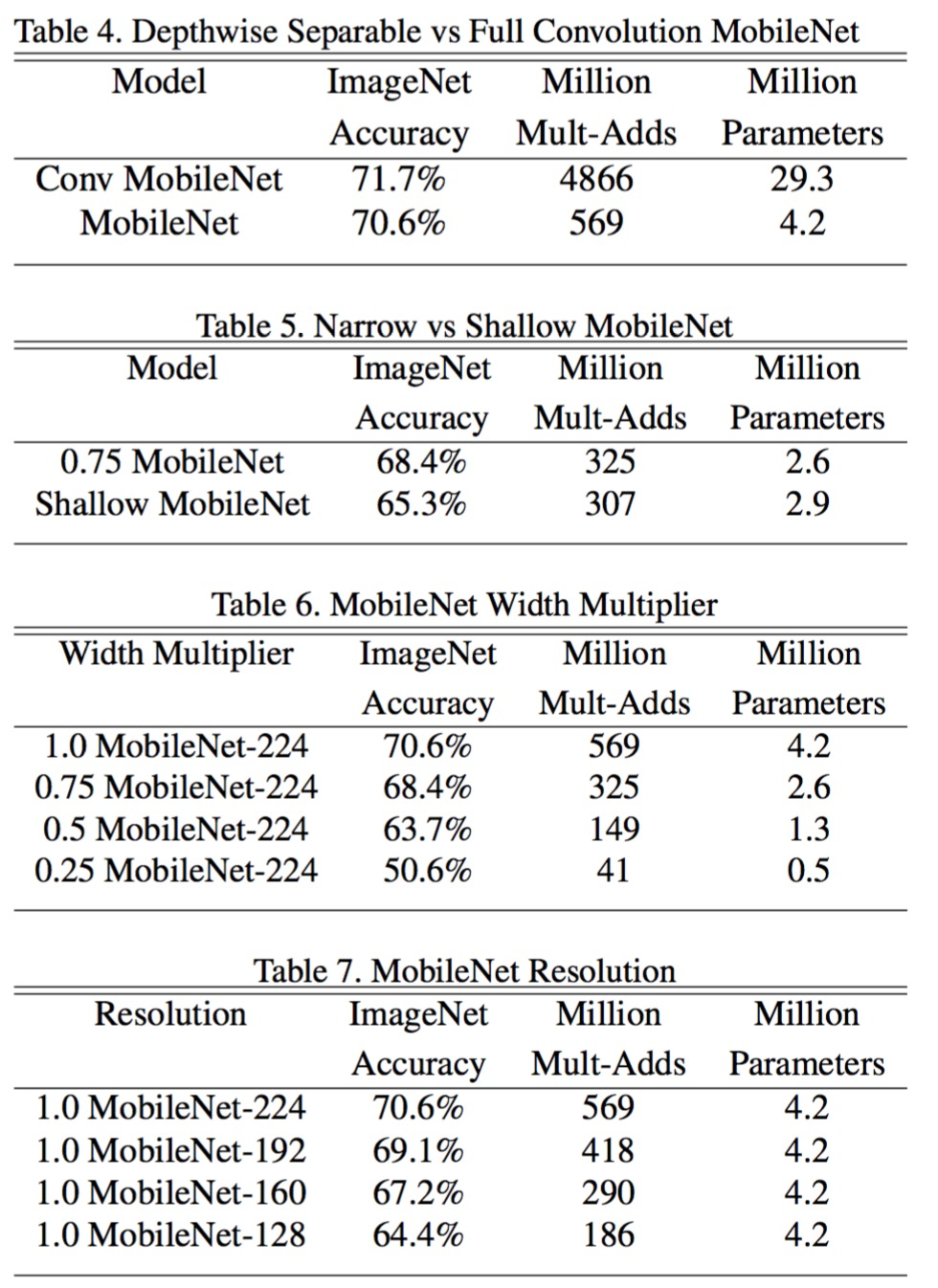
4. 对比实验
4.1 参数量的对比
4.2 实验结果
5. 实现
Tensorflow的实现: https://github.com/tensorflow/models/blob/master/slim/nets/mobilenet_v1.mdCaffe实现(trick): https://github.com/shicai/MobileNet-Caffe
(通过caffe 的group参数来实现depthwise的操作的,由于实现的问题和cuda/cudnn对其支持得不好,训练起来十分慢。前向预测时在CPU上的耗时大概是googlenet的70%。这个数据参考一篇博文的,未实践过。)
Pytorch实现:https://github.com/marvis/pytorch-mobilenet
6. 总结
根据实践经验的总结,这种新的卷积计算方式,对运算速度的改进还是比较明显的,精度影响不是很大,至于文中说的两个裁剪方法,我觉得还是慎重使用比较好。现在市面上已经有很多裁剪方法了,没必要用这么暴力的进行裁剪来压缩模型大小。

相关文章推荐
- 论文阅读笔记:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 【论文学习】MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications
- [论文阅读]MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- [论文解读] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 手机CNN网络模型--MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- Reading Note: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications个人理解
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 网络小型化MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 论文记录_MobileNets Efficient Convolutional Neural Networks for Mobile Vision Application
- How to design DL model(1):Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
- 论文记录_MobileNets Efficient Convolutional Neural Networks for Mobile Vision Application
- 论文阅读笔记:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- [论文解读] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- deeplearning论文学习笔记(1)Convolutional Neural Networks for Sentence Classification