排序算法(四)堆排序的Python实现及算法详解
2017-10-17 17:50
676 查看
一、前言
如果需要Java版本的堆排序或者堆排序的基础知识——树的概念,请参看本人博文《排序算法(二)堆排序》
关于选择排序的问题
选择排序最大的问题,就是不能知道待排序数据是否已经有序,比较了所有数据也没有在比较中确定数据的顺序。
堆排序对简单选择排序进行了改进。
二、准备知识
堆:它是一个完全二叉树
大顶堆:每个非叶子结点都要大于或者等于其左右孩子结点的值称为大顶堆
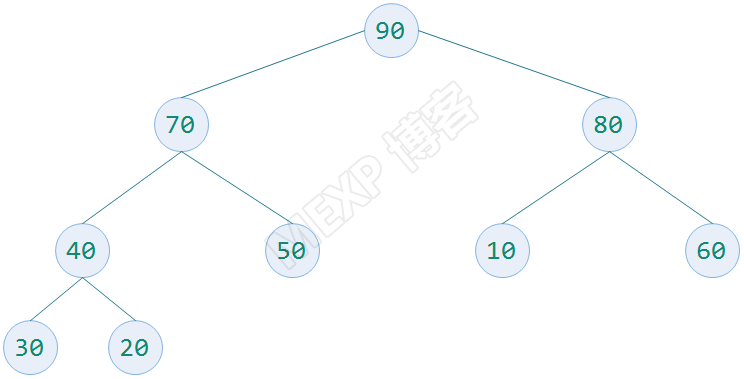
小顶堆:每个非叶子结点都要小于或者等于其左右孩子结点的值称为小顶堆
三、算法思路
堆排序大致可以分为下面几个步骤:
1、构建完全二叉树
将原始数据放入完全二叉树中
2、构建大顶堆
需要选择起点结点,选择下一个结点,以及如何调整堆
3、排序
将堆顶数据依次拿走,生成排序的树,最后用层序遍历就可以难道所有的排序元素
四、算法实现
(一)构建完全二叉树
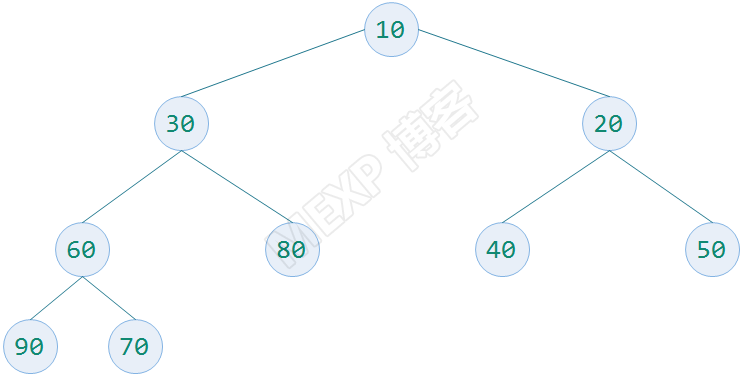
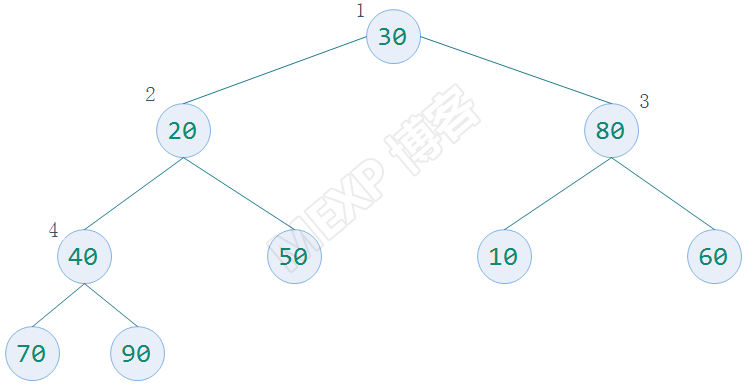
待排序数字为 30,20,80,40,50,10,60,70,90
构建一个完全二叉树存放数据,并根据性质5对元素编号,放入顺序的数据结构中
构造一个列表为[0,30,20,80,40,50,10,60,70,90],用它来描述完全二叉树
(二)打印树(辅助函数)
为了方便观察,生成一个打印列表为树结构的函数,方便观察树结点的变动,不属于算法函数
为了适应不同的完全二叉树,这个打印函数还需要特殊处理一下。
思路:
第一行取1个,第二行取2个,第三行取3个,以此类推
投影来思考一个类栅格系统,就可以很好的打印这个树了
(三)构建大顶堆
核心算法
对于堆排序的核心算法就是堆结点的调整
1. 度数为2的结点A,如果它的左右孩子结点的最大值比它大的,将这个最大值和该结点交换
2. 度数为1的结点A,如果它的左孩子的值大于它,则交换
3. 如果结点A被交换到新的位置,还需要和其孩子结点重复上面的过程
核心算法实现如下:
到目前为止也只是解决了单个结点的调整,下面要使用循环来依次解决解决比起始结点编号小的结点。
起点的选择
从最下层最右边叶子结点的父结点开始
由于构造了一个前置的0,所以编号和列表的索引正好重合
但是,元素个数等于长度减1
下一个结点
按照二叉树性质5编号的结点,从起点开始找编号逐个递减的结点,直到编号1
(四)排序
思路
1. 每次都要让堆顶的元素和最后一个结点交换,然后排除最后一个元素,形成一个新的被破坏的堆。
2. 让它重新调整,调整后,堆顶一定是最大的元素。
3. 再次重复第1、2步直至剩余一个元素
改进
如果最后剩余2个元素的时候,如果后一个结点比堆顶大,就不用调整了。
五、算法分析
1、利用堆性质的一种选择排序,在堆顶选出最大值或者最小值
2、时间复杂度
堆排序的时间复杂度为O(nlogn)
由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn)
3、空间复杂度
只是使用了一个交换用的空间,空间复杂度就是O(1)
4、稳定性
不稳定的排序算法
六、完整代码
如果有需要,请自行将算法函数封装成类。
如果需要Java版本的堆排序或者堆排序的基础知识——树的概念,请参看本人博文《排序算法(二)堆排序》
关于选择排序的问题
选择排序最大的问题,就是不能知道待排序数据是否已经有序,比较了所有数据也没有在比较中确定数据的顺序。
堆排序对简单选择排序进行了改进。
二、准备知识
堆:它是一个完全二叉树
大顶堆:每个非叶子结点都要大于或者等于其左右孩子结点的值称为大顶堆
小顶堆:每个非叶子结点都要小于或者等于其左右孩子结点的值称为小顶堆
三、算法思路
堆排序大致可以分为下面几个步骤:
1、构建完全二叉树
将原始数据放入完全二叉树中
2、构建大顶堆
需要选择起点结点,选择下一个结点,以及如何调整堆
3、排序
将堆顶数据依次拿走,生成排序的树,最后用层序遍历就可以难道所有的排序元素
四、算法实现
(一)构建完全二叉树
待排序数字为 30,20,80,40,50,10,60,70,90
构建一个完全二叉树存放数据,并根据性质5对元素编号,放入顺序的数据结构中
构造一个列表为[0,30,20,80,40,50,10,60,70,90],用它来描述完全二叉树
(二)打印树(辅助函数)
为了方便观察,生成一个打印列表为树结构的函数,方便观察树结点的变动,不属于算法函数
为了适应不同的完全二叉树,这个打印函数还需要特殊处理一下。
思路:
第一行取1个,第二行取2个,第三行取3个,以此类推
投影来思考一个类栅格系统,就可以很好的打印这个树了
import math
def print_tree(array):
'''
深度 前空格 元素间空格
1 7 0
2 3 7
3 1 3
4 0 1
'''
index = 1
depth = math.ceil(math.log2(len(array))) # 因为补0了,不然应该是math.ceil(math.log2(len(array)+1))
sep = ' '
for i in range(depth):
offset = 2 ** i
print(sep * (2 ** (depth - i - 1) - 1), end='')
line = array[index:index + offset]
for j, x in enumerate(line):
print("{:>{}}".format(x, len(sep)), end='')
interval = 0 if i == 0 else 2 ** (depth - i) - 1
if j < len(line) - 1:
print(sep * interval, end='')
index += offset
print()
print_tree([0, 30, 20, 80, 40, 50, 10, 60, 70, 90, 22])
print_tree([0, 30, 20, 80, 40, 50, 10, 60, 70, 90, 22, 33, 44, 55, 66, 77])
print_tree([0, 30, 20, 80, 40, 50, 10, 60, 70, 90, 22, 33, 44, 55, 66, 77, 88, 99, 11])(三)构建大顶堆
核心算法
对于堆排序的核心算法就是堆结点的调整
1. 度数为2的结点A,如果它的左右孩子结点的最大值比它大的,将这个最大值和该结点交换
2. 度数为1的结点A,如果它的左孩子的值大于它,则交换
3. 如果结点A被交换到新的位置,还需要和其孩子结点重复上面的过程
核心算法实现如下:
# 为了和编码对应,增加一个无用的0在首位 origin = [0, 30, 20, 80, 40, 50, 10, 60, 70, 90] total = len(origin) - 1 # 初始待排序元素个数,即n print(origin) print_tree(origin) def heap_adjust(n, i, array: list): ''' 调整当前结点(核心算法) 调整的结点的起点在n//2,保证所有调整的结点都有孩子结点 :param n: 待比较数个数 :param i: 当前结点的下标 :param array: 待排序数据 :return: None ''' while 2 * i <= n: # 孩子结点判断 2i为左孩子,2i+1为右孩子 lchile_index = 2 * i max_child_index = lchile_index # n=2i if n > lchile_index and array[lchile_index + 1] > array[lchile_index]: # n>2i说明还有右孩子 max_child_index = lchile_index + 1 # n=2i+1 # 和子树的根结点比较 if array[max_child_index] > array[i]: array[i], array[max_child_index] = array[max_child_index], array[i] i = max_child_index # 被交换后,需要判断是否还需要调整 else: break # print_tree(array) heap_adjust(total, total // 2, origin) print(origin) print_tree(origin)
到目前为止也只是解决了单个结点的调整,下面要使用循环来依次解决解决比起始结点编号小的结点。
起点的选择
从最下层最右边叶子结点的父结点开始
由于构造了一个前置的0,所以编号和列表的索引正好重合
但是,元素个数等于长度减1
下一个结点
按照二叉树性质5编号的结点,从起点开始找编号逐个递减的结点,直到编号1
# 构建大顶堆、大根堆 def max_heap(total,array:list): for i in range(total//2,0,-1): heap_adjust(total,i,array) return array print_tree(max_heap(total,origin))
(四)排序
思路
1. 每次都要让堆顶的元素和最后一个结点交换,然后排除最后一个元素,形成一个新的被破坏的堆。
2. 让它重新调整,调整后,堆顶一定是最大的元素。
3. 再次重复第1、2步直至剩余一个元素
def sort(total, array:list): while total > 1: array[1], array[total] = array[total], array[1] # 堆顶和最后一个结点交换 total -= 1 heap_adjust(total,1,array) return array print_tree(sort(total,origin))
改进
如果最后剩余2个元素的时候,如果后一个结点比堆顶大,就不用调整了。
def sort(total, array:list): while total > 1: array[1], array[total] = array[total], array[1] # 堆顶和最后一个结点交换 total -= 1 if total == 2 and array[total] >= array[total-1]: break heap_adjust(total,1,array) return array print_tree(sort(total,origin))
五、算法分析
1、利用堆性质的一种选择排序,在堆顶选出最大值或者最小值
2、时间复杂度
堆排序的时间复杂度为O(nlogn)
由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn)
3、空间复杂度
只是使用了一个交换用的空间,空间复杂度就是O(1)
4、稳定性
不稳定的排序算法
六、完整代码
如果有需要,请自行将算法函数封装成类。
import math
def print_tree(array):
'''
前空格元素间
170
237
313
4 01
'''
index = 1
depth = math.ceil(math.log2(len(array))) # 因为补0了,不然应该是math.ceil(math.log2(len(array)+1))
sep = ' '
for i in range(depth):
offset = 2 ** i
print(sep * (2 ** (depth - i - 1) - 1), end='')
line = array[index:index + offset]
for j, x in enumerate(line):
print("{:>{}}".format(x, len(sep)), end='')
interval = 0 if i == 0 else 2 ** (depth - i) - 1
if j < len(line) - 1:
print(sep * interval, end='')
index += offset
print()
# Heap Sort
# 为了和编码对应,增加一个无用的0在首位
origin = [0, 30, 20, 80, 40, 50, 10, 60, 70, 90]
total = len(origin) - 1 # 初始待排序元素个数,即n
print(origin)
print_tree(origin)
print("="*50)
def heap_adjust(n, i, array: list):
'''
调整当前结点(核心算法)
调整的结点的起点在n//2,保证所有调整的结点都有孩子结点
:param n: 待比较数个数
:param i: 当前结点的下标
:param array: 待排序数据
:return: None
'''
while 2 * i <= n:
# 孩子结点判断 2i为左孩子,2i+1为右孩子
lchile_index = 2 * i
max_child_index = lchile_index # n=2i
if n > lchile_index and array[lchile_index + 1] > array[lchile_index]: # n>2i说明还有右孩子
max_child_index = lchile_index + 1 # n=2i+1
# 和子树的根结点比较
if array[max_child_index] > array[i]:
array[i], array[max_child_index] = array[max_child_index], array[i]
i = max_child_index # 被交换后,需要判断是否还需要调整
else:
break
# print_tree(array)
# 构建大顶堆、大根堆 def max_heap(total,array:list): for i in range(total//2,0,-1): heap_adjust(total,i,array) return array print_tree(max_heap(total,origin))
print("="*50)
# 排序
def sort(total, array:list): while total > 1: array[1], array[total] = array[total], array[1] # 堆顶和最后一个结点交换 total -= 1 if total == 2 and array[total] >= array[total-1]: break heap_adjust(total,1,array) return array print_tree(sort(total,origin))
print(origin)

相关文章推荐
- 排序算法(三)冒泡、选择排序的Python实现及算法优化详解 推荐
- 机器学习经典算法详解及Python实现---Logistic回归(LR)分类器
- 机器学习经典算法详解及Python实现--CART分类决策树、回归树和模型树
- 机器学习经典算法详解及Python实现--K近邻(KNN)算法
- 必须知道的八大种排序算法【java实现】(二) 选择排序,插入排序,希尔算法【详解】
- 机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用
- 数据挖掘之Apriori算法详解和Python实现代码分享
- 笔试面试最常涉及到的12种排序算法(包括插入排序、二分插入排序、希尔排序、选择排序、冒泡排序、鸡尾酒排序、快速排序、堆排序、归并排序、桶排序、计数排序和基数排序)进行了详解。每一种算法都有基本介绍、算
- 【人脸识别】人脸验证算法Joint Bayesian详解及实现(Python版)
- Python实现的数据结构与算法之双端队列详解
- 排序算法总结(简单选择排序、堆排序)(python实现)
- 算法 排序 python 实现--堆排序
- 人脸验证算法Joint Bayesian详解及实现(Python版)
- CART分类决策树、回归树和模型树算法详解及Python实现
- python算法实现系列-堆排序
- 机器学习经典算法详解及Python实现–K近邻(KNN)算法
- 人脸验证算法Joint Bayesian详解及实现(Python版)
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
- 机器学习经典算法详解及Python实现--CART分类决策树、回归树和模型树
- 机器学习经典算法详解及Python实现--元算法、AdaBoost