论文笔记:A Survey on Tag Recommendation Methods 上
2017-10-15 16:39
465 查看
感想
这篇文章是一篇2017年的综述,考虑的方面还是挺全的,几乎把标签推荐的所有技术都讲了一遍,但是它没有进行细化,但是适合写开题报告了,不适合找一个点来做研究,因为它里面说的公开挑战,还是蛮宽泛的。不过相信读了之后,对这个方向有着很全面的了解了。下面是我的一些笔记,翻译的不好,欢迎批评指正。介绍
在Web2.0应用中,标签被认为是和目标(例如视频和文本)相关元数据最佳的方式。用户自由选择关键词指派给目标,与在可控词汇下(a controlled vocabulary)的固定分类系统相比,标签(tags)可以一种更简单,更便宜和更自然的方式来组织内容。事实上,在像web2.0的非常动态的环境中,语料库的条目在增长和进化着,分类系统的方法显然不合适。另外,最近的研究证明,在所有的文本特征中,例如标题,描述和用户评论。标签(tags)是支持信息检索服务最有效的方式,例如搜索,自动分类和内容推荐。打标签的过程可以从标签推荐服务上中受益,这种服务可以帮助用户挑选一些推荐的标签,或者提出一些新的标签。标签推荐不仅改善了用户体验,也可能丰富(enrich)了生成标签的质量。间接的提升了信息检索服务的质量,信息检索服务本身依赖于标签作为数据来源。
除此之外,最明显的一点它改进了对目标的描述,这对比如浏览信息等服务有好处,标签推荐可以给信息检索服务带来好处,包括推荐标签直接应用在搜索和查询展开(query expansion),而前者利用推荐标签去衡量查询和文档间的相似度,改进了检索文档的质量,后者给用户推荐更多特定的并且清楚的查询,它可以获得更好的搜索结果。还要一些例子包括研究者人员信息总结(researcher profile summarization)和搜索结果总结(search
result summarization)。
和通常的条目推荐(item recommendation)不一样,条目推荐通常是把目标用户和兴趣匹配匹配起来,标签推荐的目标是描述,概述和组织目标的内容,在个性化推荐中,它也能匹配用户兴趣。但是,标签推荐的设计是一个挑战,它需要特定的解决方案,这是和其它UI件任务所用的方法有很大的不同。例如,文本挖掘,知识抽取,语义学在标签域(tag domain)上占着很重要的角色。另外,推荐效果是最重要的,糟糕的推荐可能不仅损害用户满意度,而且最终对多样的信息检索服务的性能是有害的,信息检索服务依赖于标签作为一个数据源。
因为这个原因,标签推荐是一些研究的重要科目,即使是巨大的标签推荐文献,据我们的了解,先前的工作还没有把这些方法概述和组织成一篇文章。最相关的工作是Gupta等人在2010年提出来的。研究者总结通常和打标签相关的问题,例如标签语义学,模型,可视化,应用和用法(usage)。但是没有集中到标签推荐问题,正如我们所做的,我们对许多推荐方法做了更深入的分析。
我们这篇文章的目标是提出一个分类法,去组织现存的标签推荐文献,对先前的标签推荐方法进行分组,这是根据四种不同的分类标准进行分的。即推荐的对象(target of the recommendations),他们的目标(objectives),利用的数据源,和潜在的技术。我们也提供了这些方法的关键概述(critical overview)。指出了他们的优点和缺点。最终,我们描述标签推荐主要的公开挑战,例如标签模糊性,冷启动,和评估问题。
情景和问题的陈述(Contextualization and Problem Statement)
首先,我们定义标签(tags)和目标(objects)的概念,这是标签推荐的目标,接着,我们我们规范化陈述标签推荐问题,规范化定义它的两个变体(标签推荐问题部分),以及其它可能利用的目标(其它推荐目标:新颖和多样性部分)。Web2.0的标签和目标
Web2.0的每一页都有一个主要的目标组成(例如,文本文档,一段音频,一个视频,一张图片)和多种与目标相关的信息源。这里提到了特征。这些特征可以分为内容特征,文本特征,用户信息特征和社交特征。内容特征可以从主要的目标中提取出来,例如一幅图片的颜色直方图。文本特征由与目标相关的自我包含的文本块(self-contained textual blocks),它通常有一个良好定义的功能(well-defined functionality)。文本特征的样例在不同的应用中通常都能找到的是标题,描述,分类,标签和用户评论。尤其,标签是关键词,用户随意指派这些词来简单描述目标的内容。因为标签是用户自由创造的,他们不是按字母表颠倒排列的字(unigrams),除非应用自动用空白把他们分割了。结果,合成词可以用于标签,要么用假定的空白分离或者连在一起的。
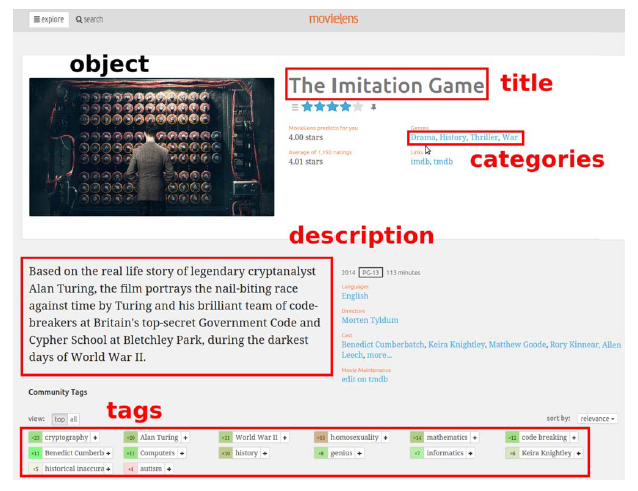
上图展示了把一个MovieLens页面,里面包含指派到一个目标的文本特征(这里的目标代表一张图片)。
用户信息特征(User profile features)涉及用户的特点,用户创造和上传内容(content),或者为其指派标签(tags),或者他和其它应用的交互(interactions)。最后,社交特征涉及用户之间的交互(例如,显式的的友谊链接(explicit friendship links),订阅(subscriptions),投票(upvotes)等)。尤其,友谊链接是用户社交关系的显示指标(explicit indicators),订阅(subscriptions,用户间建立的链接,用来表明对彼此的内容中表示兴趣),赞同(endorsments,例如upvotes)是用户间社交关系更显式的指标。
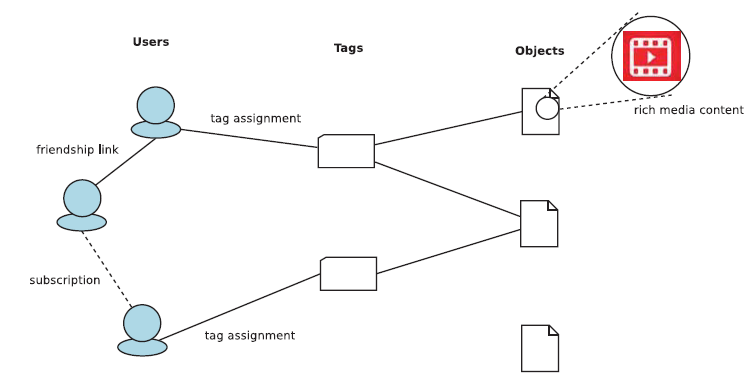
如上图,特征的例子通常在Web2.0的应用中找得到。通过应用建立的友谊和订阅链接是社交特征(social features)的样例。在应用中,用户指派到目标的标签集合可能被认为是用户资料特征的一种。从主要目标(main object,例如颜色直方图)的内容中抽取的特征是内容特征(content features)。
Web2.0标签,目标和用户构成了大众分类(folksonomies)的基本结构。Folksonomies是folks(people)和taxonomy(taxis意思是分类,nomos或者nomia意思是管理)的融合词。Folksonomy涉及目标分类,分类使用用户自由选择的关键字。与分类学(taxonomy)不同,分类学提供的是一个有良好定义类别的层级的分类,folksonomy建立类别(每个标签可能被认为一个类别),它没有规定或者必要衍生出一个标签的层级结构。
正式的,folksonomy被定义一个关系结构F=(U,T,O,P),U,T,O分别代表用户,标签,目标的有限集合,P是这些元素的三元关系(ternary relation)
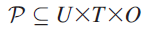
每一个元素(u,t,o)∈P代表委派一个标签t到一个用户u的目标o. Wal (2005)辨识了两种类型的folksonomies:broad和narrow. 当多个用户对一个目标应用相同的标签的时候,broad folksonomy就会上升,它提供了信息关于哪个标签是最流行的,broad folksonomies的样例包含在线电台(online radio station)LastFM和发布分享应用(publication sharing application)BibSonomy。当只有一个用户给一个给定的物体打标签的时候,narrow
folksonomy就出现了,图片分享网站Flickr是narrow folksonomy的一个样例。Broad和narrow folksonomy都可以进行内容组织(content organization)并且有可查找性(findability)。broad folksonomy可以按流行度对指派标签排序,也能跟踪标签用法和词汇发展呈现的轨迹趋势(tracking of emerging trends),通常,标签流行度在broad folksonomies上以标签云进行可视化,标签云提供很简单的方式去导航标签,目标,和folksonomy的用户。
标签(tag)推荐问题
标签推荐问题可以分为两个子任务:目标中心(object-centered)问题和个性化(personalized)问题。前者的解决方法由候选标签的列表组成,并根据与他们的对象目标的相关性(relevance to the target object)排序。即标签和目标对象的相关程度。这种推荐为一个目标提供相同的标签,不管这个用户。它的目标是改进这些目标的标签质量,进而改进信息检索服务的效果,例如搜索,索引,和分类,这些都利用标签作为数据源。另一方面,个性化标签推荐也把目标用户考虑在内。它的目标是推荐标签,这个标签与目标对象和用户都相关,因此,个性化标签推荐可能对相同目标对象提供不同的答案,但是更多的是对不同用户或者有不同资料的用户(but different users (or users with different profiles))。这些推荐可能更好的捕捉到用户兴趣,人物资料(profile)和背景。另外,分享在Web2.0应用经常被多方面的(multifaceted),和多种话题相关,并且不同的用户可能和这样的话题相关程度不一样。于是,多个用户可以把标签指派到相同的目标,在这种应用中,例如流行的LastFM,一个个性化的推荐不仅对单个用户有用,而且在一个集体意识下同样有用。这是因为对不同用户的标签推荐提供了对目标的一个更完整的描述,这间接的帮助了搜索和推荐服务。换句话说,对于不同用户相同目标的个性化标签的集合,用户有不同的背景和兴趣,帮助覆盖同一事物的多方面或解释性,进而帮助跨越语义鸿沟。
正式的,我们定义两种标签推荐任务。目标中心的标签推荐(Object-centered tag recommendation),给定一个输入集合Io,Io和目标对象o相关,产生一个候选列表Co,Co∩Io=∅,根据他们和目标o的相关性进行排序,并且在C0的顶部位置推荐k个候选项。
个性化标签推荐,给定一个输入标签集合Io,Io与目标对象o相关,产生一个候选列表C0,u,Co,u∩Io=∅,根据他们和目标o的相关性进行排序,推荐Co,u顶部位置的k个候选项。
这些定义集中于相关性,把相关性作为唯一的目标进行最大化,可是,其它方面的问题,例如新颖性和多样性,在通常的推荐情境下也很重要。可是,在特定的标签推荐情境下,只有很少的方法处理标签推荐问题,旨在最大化一个新颖性和多样性相关的结合。
其它推荐目标:新颖性和多样性
正如上面提到的,标签关联可以用两种观点定义。从目标中心观点角度,如果一个标签正确的描述了目标对象的内容,那么该标签就是有关的。从个性化观点角度,一个相关的标签不仅能很好的描述目标对象的内容,也可以让用户和兴趣进行匹配。注意,根据定义,其中有一个假设,推荐列表里的每个标签的相关性和列表里其它标签的是独立的。可是,假定一个推荐满足了用户的需要,相似推荐(similar recommendations,如同义词)的有效性是可辩论的(arguable)。因此,正如其它研究者察觉到的那样,除了相关性外,新颖性和多样性的概念应该被顾及,它把其它推荐的标签考虑在内。
在通常的推荐环境下,一则信息的新颖性涉及这个条目(this item)和之前用户之前看到的或消费的有多大的不同,或者和一个社区整体上看到的或消费的不同。在这个情景下,一个推荐条目的新颖性在文学上用了两种主要观点进行评估。其中一个是给定条目(given item)相比其他条目是罕见程度。从这个观点看,在一个给定情境下,一个条目的新颖性由它的流行度的倒转(the inverse of its popularity)进行评估,其他的观点是条目与其他条目的不同程度。在这种观点下,新颖性可以被条目和其它羡慕的平均距离进行评估,在标签推荐中,基于一个候选标签的不相似性的新颖性可以在话题级别上进行评估,至于标签是否能带来一个新的话题,这个话题和推荐列列表的目标对象相关。新颖性是一个重要的因素,因为,通常,推荐的目标是把用户暴露在相关的经历(例如条目item)中,其中这些经历,用户本身不容易被察觉。
在标签推荐中,一个标签的新颖性在应用中已经从流行度的角度被定义了。研究者通过在一个集合里面标签的频率来估计标签的新颖性,一个用于标签的术语使用了次数非常多,它就是一个更明显的推荐(“obvious” recommendation),于是,在给定标签集合下,这对于改进对目标对象的描述的用处很小。我们注意到,根据其定义,噪声项可能是非常新颖的,例如打印错误。但是,标签推荐方法一定要同时利用新颖性,相关性,和多样性,于是最小化了推荐噪声的几率。注意到新颖性(novelty)的定义和标签紧密相关,考虑到罕见的词更特别,根据Baeza-Yates和Ribeiro-Neto
(2011),以及Choi(2015)。特异性是术语语义的一个特性(property of the term semantics),即一个术语或者标签或多或少的特别依赖于其自身的意义。例如,“feline”与“cat”或“persian”相比就不那么明确的(specific),特异性的解释是基于作为一个目标话题的术语的精度,另外,特异性可以用这个术语使用的统计属性,它是用一个倒序函数来估计的,函数是一个目标中术语出现的次数,这是现存的标签新颖性概念(tag novelty concept)。可是,我们选择术语“新颖性(novelty)”,而不用“特异性(specificity)”,这是因为我们保持与一般的推荐文献一致。与目标描述的一个相关属性是穷举(exhaustivity),它的定义覆盖目标的主要话题,这个和我们多样性相适应,我们在下面会讨论。
推荐条目的列表的多样性(diversity)涉及推荐条目之间的区别,两种类型的多样化方法已经用于通常的信息检索环境中:隐式方法和显式方法。前者利用的是推荐条目的属性,后者利用的是推荐对象的属性或者来自查询,例如,一个用户对多个话题感兴趣,一个模糊查询的多种解释。多样性已经在搜索中被用于解决查询的模糊性,增加了至少一篇文档会满足目标用户的信息需要。
基于这些想法,提出了用两种方法去估计标签推荐中的多样性。隐式的方法用推荐的top标签中的平均语义距离来(average pairwise semantic distance)估计多样性,同义词和语义相关词的列表呈现较低的多样性。显式多样化方法旨在尽可能多的把话题与目标对象覆盖到。我们注意到通过增加话题的覆盖度,也间接地减少了了推荐条目(recommended items)的话题冗余,这也对提高新颖性话题推荐有很大的贡献。
标签推荐方法的分类(Taxonomy)
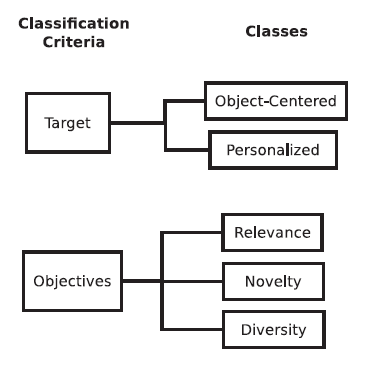
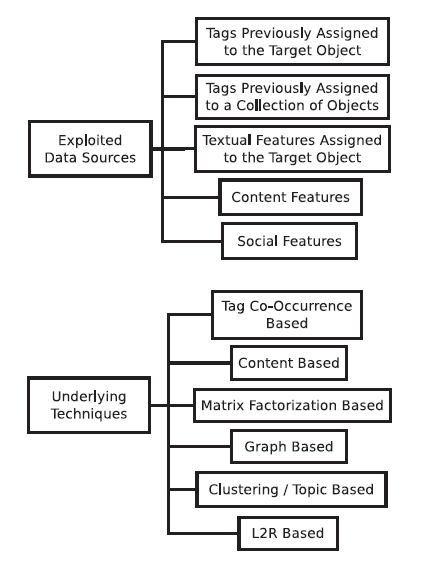
上图是提出的分类学方法,用来根据多种准则来分类标签推荐方法,分类方法考虑到了两个级别:第一个级别中,我们使用了四个分类准则,即
(1) 推荐的对象(target)
(2) 它们的目标(objectives)
(3) 方法利用的数据源(data sources)
(4) 他们使用的潜在技术(underlying techniques)
所有的推荐方法可以根据上述四个标准的每一个准则进行分组。第二个级别是或者树的叶子(the “leaves” of the trees),对应每一个标准的已存在的类别。我们注意到,许多标签推荐方法可以和多种类别相关(more than one of these classes)。
第一种标准(推荐的对象),前面的标签推荐方法可以分为两类:目标中心方法以目标(object)为主要对象(target),而个性化方法是以用户目标(user-object)为对象,这在前面也提到过。
第二种标准(objectives),先前的推荐方法考虑了三种主要目标(objectives):相关性,新颖性和多样性。但是大多数现有的方法仅仅考虑了相关性这个单个目标,最近很少有方法把相关性,新颖性和多样性三者结合起来用到标签推荐问题中。特别地,Belem
et al. (2016)提供了这三个数据集,覆盖多种不同应用,这可以用于研究标签推荐和标签分析。
考虑第三个分类标准(数据源),前面的方法利用的:
(1) 先前指派给目标对象的标签;
(2) 先前指派给一个训练对象的集合的标签;
(3) 文本特征(除了标签),例如标题,描述,和用户评论;
(4) 丰富的媒体内容(rich media content),图片,音频或者视频;
(5) 社交特征,例如社交网络中的友谊链接以及用户之间的其他交互。
据我们了解,最多同时利用了前面的三个数据源,这样就可以进一步利用更多的数据源进行研究。
对于第四种分类标准(潜在的技术),标签推荐方法可以分为六组:基于标签同时出现的方法(Tag co-occurrence-based methods)利用关联规则,搜索先前指定到训练目标集合的标签。他们用候选标签同时出现的频率来估计候选标签的相关性。换句话说,给定初始了标签集合Io,目标对象为O,那些经常在Io中一起用的标签即为推荐给O的好的候选项。
基于内容的方法,是从目标对象中提取候选标签(例如从图像里面提取的与标签相关的视觉特征),或者从他的特征中提取的候选标签(例如文本特征)。他们都假设了最相关的信息都包含在目标对象中或者与之相关的特征中。
矩阵分解方法(Matrix factorization methods)把标签指派作为一个矩阵,在这个矩阵上运用降维方法。他们的目标通过预测用户,标签和目标之间的关系来推荐标签,其中目标是来自一个小的并且低噪声表达的标签数据。
基于图的方法(Graph-based methods)把打标签的系统作为一个图(例如目标就是结点,边表示两个结点很相似)。他们的目标是利用目标对象的邻近来抽取候选标签。
基于聚类的方法(Clustering-based methods),即应用聚类的技术去分组目标和标签,并推荐目标对象簇(target object’s cluster)的最有代表性的标签。他们假设可能从标签中抽取相关的标签,这些标签描述了目标对象或用户的主要话题。
基于排序学习(learning-to-rank,L2R)的方法是有监督的方法,它自动学习一个推荐函数,推荐函数是基于候选标签标示成标签质量属性的向量的训练样例训练得来的。这些属性可能是由先前提到的技术产生的结果,甚至是其它的基于L2R的方法。L2R的目标是自动结合不同的标签质量的证据(evidence,例如属性或者特征),在给定推荐目的(相关性,新颖性和多样性)下,产生一个模型把这些属性映射到一个分数或者排序位置。
我们注意到,正如在表示方法部分概述(Overview of Representative Methods section)看到的那样。 这些分组不是完全的不相交的,大多数标签推荐方法使用了多种技术,也利用了一些数据源。我们这里把这些方法称为混合标签推荐策略(hybrid tag recommendation
strategies)。例如,一些方法既利用了标签同现又利用了基于内容的技术,并把它们通过基于L2R技术进行结合。
我们的分类方法是基于Colon分类方案(Colon Classification scheme),是由Ranganathan在1965年提出来的。在这个方案中,每个类别都被分析并且被分解成基本的元素,按照其公有的属性分组在一起,叫做facets。因此,我们通过结合facets来描述标签推荐方法。新的facets可以很容易用来表达新的概念。这种方法和传统的分类方案不一样,它在一组固定的静态和预定义类中枚举了定域的所有知识,通常用一个层级的树结构来表示。
表示方法(Representative Methods)的概述
在这个部分,我们描述主要的标签推荐方法,把他们分为6组,每个组代表其用到的潜在技术。基于标签同现的方法
基于标签同现方法利用了先前指定到目标集合的标签,去提取标签同现对。尤其,他们中很多利用这些对来拓展I0标签初始集合,Io与目标o相关。因此,Heymann等人(2008)使用了关联规则,即蕴含的形式,,前项X是一个标签集合,后键y是用于推荐的候选标签。我们用一个置信度阈值(confidence threshold)来限制规则。可是,研究者不提供推荐标签的排序。相反,Sigurbjornsson 和 Zwol (2008)利用了简单的标签同现的全局矩阵(例如置信度)。把他们应用到所有初始的标签集合中,去产生一个最终的候选标签的排序。他们也利用的一些与标签频率相关的矩阵来捕获每个候选项之间的关联(the “relevance” of each candidate)。
由于效率问题,大多数策略通常是计算两个标签建的同现性(co-occurrences),例如X仅包含一个标签,这可能丢失了重要的同现关系(cooccurrence relationships)。为了解决这个问题,Menezes等人 (2010)提出了LATRE((Lazy Associative Tag Recommendation,标签推荐的懒相关性),以一个按需要的方式来计算关联规则,这样做会高效的产生更复杂并且潜在更好的规则,与Sigurbj€ornsson和Zwol (2008)最好的方法比,LATRE取得了更好的结果。
一些研究利用了标签共现技术去解决个性化标签推荐问题。Garg 和 Weber (2008)提出了一个交互式方法,当一个用户输入或者选择一个目标的新标签的时候,这个系统把相关的标签建议给他或者她,基于用户过去已经用过的这些标签和用户现在输入的标签,推荐的标签动态的更新每一个额外的输入或选择的标签。Rae等人(2010)拓展了Sigurbjornsson和 Zwol (2008)的方法去解决个性化标签推荐问题。它利用了标签在不同环境下同时出现:
(1) 完整的数据集
(2) 一个特定用户的目标
(3) 用户的社交关系(the social contacts ofthe user)
(4) 包含目标用户的分组(the groups in whichthe target user is included)。
标签同现方法(tag co-occurrence methods)的优点有三点:
(1) 标签的同现很容易计算;
(2) 这些方法利用了标签相关性的最强迹象之一;
(3) 他们的主要数据源是可获取的,即标签指派的历史。
可是,这组方法可能被冷启动问题严重影响,即缺乏目标对象的信息,例如,对于一些新插入的目标。另一个与冷启动相关的问题是当打标签服务是新的时候,标签指派的历史仍然很稀疏。在标签推荐中处理冷启动问题,一个通常的解决方法是利用推荐target(目标或者用户)的内容特征,在一般的条目推荐环境下也是一样,我们把这种方法称为基于内容的方法。
基于内容的方法
这组方法从目标对象和相关的特征或者来自目标用户资料的特征中提取标签。经常被利用的目标特征是目标文本特征的集合,例如标题,描述,和用户评论。例如,Wang,Hong,和Davison(2009)从目标的文本特征中提取候选项(candidate terms)。使用传统的TF-IDF矩阵去对这些项通过他们与目标对象的相关性进行排序。Lipczak等人(2009)和Lipczak(2011)等人提出了一个从目标对象的标题和描述中提取项的混合方法,之后利用标签共现方法拓展候选标签集合,他们通过训练集和的标签的用法来衡量提取项的相关性。
另一种混合方法由Belem等人提出来的。除了从文本特征提取的候选标签外,研究者利用目标对象中标签的同时出现性,结合多种矩阵来估计标签相关性,这使用了启发式和L2R技术。在他们利用的这些矩阵中,他们发现在项传播(term spread)上比传统的项频率的性能好,其中前面的项传播是用包含候选标签的不同文本特征的数量定义的,而后面传统的项传播计算在相同文本特征中所有重复的相同项。他们也发现,当考虑不同文本特征的不同权重是,效果更好了。考虑到文本特征中的一些,例如标题什么的,这通常会呈现更高的描述能力。
另一个基于内容的标签推荐方法是Ribeiro等人在2015年提出的,它产生标签云来描述学术专家(academic experts)。研究者从多种文本特征中产生候选标签,文本特征是与目标专家(target expert)的著作相关的。候选标签根据相关矩阵排序,例如项的频率和覆盖度,它用L2R技术集合起来。研究者发现传统的基于内容的标签推荐在识别基于专业化的标签(expertise-orientedtags)效果更好。文章的关键字是一个特别有效的贯穿不同只知识领域的来源,有这各种级别的稀疏性。(我翻译的可能有些欠妥,直接上原文with
article keywords being a particularly effective source ofevidence across profiles in different knowledge areas and with various levelsof sparsity.,)另外,L2R方法对专业化分析(expertiseprofiling)提供了更有效的改进。
目标用户的特征是用户标签指派历史,通常用基于内容的标签推荐方法,这是用户兴趣最好的证据。从目标用户历史中提取候选标签,用于个性化推荐。另外,Belem等人(2014)量化了个性化标签推荐的益处,用以改进对目标对象的描述,这里的标签主要来自用户的标签指派历史。他们发现他们最好的个性化方法在相关性方面取得了可观的效果,这里指基于目标中心的标签推荐中。
其它的方法是利用与目标对相关的丰富的媒体内容。例如,Wu等人(2009)计算标签和从图片中提取的视觉特征的共现性,利用了叫做Rankboost的L2R技术去产生最后的分类函数。Lin等人(2012)在有相似视觉内容的图片的图生(graph of images withsimilar visual content)运用了一个随机游走的过程。在这个图(graph)中,结点时目标(图片),如果两个目标有相同的视觉特征,我们就用边连接。Siersdorfer等人(2009,2011)创造了一个基于内容县相似度的视频图,并且通过标签之间的边传播标签。可是,语义鸿沟(semantic
gap)依然对利用媒体产生精确的标签是一个挑战。因为视频或图片的视觉相似度可能不会对应他们关系的力量程度(the strength of their relationship),为了缓解这个局限,Zhu等人提出了有适应有自适应量子隐形传态的概率(adaptiveteleportation probabilities)的随机游走模型(random walk model)。
除了和目标内容相关的文本特征外,Chen和shin(2013)利用推荐标签的社交特征。他们考虑频繁出现在目标中的标签,并且被目标用户(target user)标记为喜欢,以此作为候选项推荐。
基于内容的技术(Content-based techniques)通常用于缓解冷启动问题(缺乏初始标签)。例如,Martins等人评估了推荐方法家族对冷启动的影响。结果显示,当这些方法不依赖于目标对象中先前分配的标签是,这些方法的有效性会受到影响。另外,通过自动过滤策略利用其它候选标签源取得的效果不明显。于是,研究者提出了同时利用正相关和负相关反馈的新策略,反馈来自用户迭代的选择输入标签到这些推荐方法中,这个策略取得了在最佳考虑的基准线(best considered baseline)上去的了很好的效果(达到了45%的精度),并且在缺乏用户合作的情况下也是鲁棒的(robust)。
基于内容的技术的主要问题是缺乏新颖性,推荐的已经指派到内容的条目可能对产生更多互补的和多样标签是没有用的,这些产生的标签来自其他的源。相似的,用户先前感兴趣的标签可能是精确的,代表用户过去的喜好,但是他们可能不能捕获到新的兴趣。除此之外还有,这些方法得处理大量的有噪声存在的文本和内容特征。
基于矩阵分解的方法
最有代表性的方法是PITF(pair-wise interactions tensor factorization), 在2009PKDD Discovery Challenge competition中获胜的一个方法。在这个方法中,张量是对用户,条目和标签的成对交互(pairwise interactions)的建模,例如排序更倾向于每个用户目标对(pair user-object)的标签,张量被分解为低维矩阵用以减少噪声。PITF模型是从一个适应的贝叶斯个性化排序标准(Bayesian personalizedranking criterion)下学出来的。这个方法的优点是降维(dimensionality reduction),降维可以减少噪声并且较少后验计算的复杂度(complexity of posterior computations)。可是,矩阵分解操作的代价操作使得扩展性问题更加严重(exacerbates scalability problems)。另外,数据系数也是这些技术的主要问题。即使矩阵分解已经用于使数据密集(denser data),因为不流行的标签,用户和目标被过滤掉了。这个方法效果超过了Belem等(2014)提出的混合方法,混合方法不假定这种过滤。
基于图的方法
基于图的标签推荐方法从目标对象或用户的邻居中提出候选项。图的结点对应目标或者用户,如果两个用户或者目标相似的话,他们就用边相连。计算相似度的主要源是目标的文本特征,其中包括标签和folksonomy。这是用户的打标签的历史,另外,从图片和视频中提取的视觉特征可以估算内容相似度。基于协同过滤的技术也被分在次类别中,应为他们利用相似用户的历史给目标用户(targetuser),他们共享标签。Jaschke等人(2007)建立了一个相似图,图中顶点是用户,每个边连接两个有共同标签的用户,边的权重用一些相似度量,例如Jaccard coefficient。这个方法推荐给一个用户u标签,标签是最相似用户u的k个标签,另一个方法由同一个研究者提出来的,叫做FolkRank,它基于著名的PageRank算法。这个方法的理论是一个目标接收来自重要用户的相关标签,这个目标也变得重要了,这时推荐的好的源(good
source)。对称的,如果一个标签和重要用户的重要目标相关,那么它是相关的。于是,一个图的相互强化(mutual reinforcement graph)就建立起来了,并且可以对标签进行评分和推荐。Hu, Lim,等人(2010)提出了一个概率方法,利用用户和对象的词汇表,和相似用户的词汇表。软就这提出使用Kullback-Leibler divergence去估计两个用户间的相似性。
Lu, Yu等人提出了用相似文本内容的目标传播标签,Feng等人用folksonomy用一个异构的图进行建模,图包括标签,用户,和目标作为结点。他们利用了一个优化策略去学习连接这些结点边的权重,叫做OptRank。Lops等人同时利用了协同过滤和基于内容的标签推荐技术,前者利用用户和社区打标签行为去做推荐,而后者利用一些启发式方法去直接从目标文本内容中提取标签。Liu等人通过用户之间的显式链接来增强基于图的标签推荐。Guan等人把标签推荐作为一个查询和排序的问题,提出了一个基于图的排序算法,对于多种实体进行排序,如标签,用户和文档进行。当一个用户处理一个打标签的请求,文档和用户被当做一个查询的部分。标签然后通过基于图排序的算法进行排序,算法同时考虑了文档相关性和用户偏好。
最近,Yin等人(2013)不仅解决了推荐标签的问题也预测了不同种(例如用户,评论,条目和用户间的社交连接之间的关系)之间的关系。通过利用一个利用一个繁华的潜在因式模型(generalized latent factor model)和贝叶斯推理。研究者发现在同一个模型内的标签和评论的连接使得相互增强(mutual reinforcement)并且提高了预测的精度。
这组方法相比基于同时出现的方法相比,受冷启动问题的影响很小。可是,相比基于内容的技术,他们经常得处理更多的噪声(来源于文本或内容特征)。
基于聚类的方法
推荐标签的方法是基于聚类或者基于目标话题的方法,例如,Song等人提出了两个基于聚类的方法,第一个方法在两个二分图中(two bipartite graphs)表示标签数据:一个文档标签图和一个字文档图。在一个标签文档图中,标签和文档是结点,如果不止一个用户把t指派到d,在文档d和一个标签t上有一个边。这个方法通过利用图划分算法来找文档话题。第二个方法旨在数据集和范围内找到最有代表性的文档,并且提出一个稀疏的多类高斯过程分类器用于高效的文档分类。对于两种方法,在每一个簇中通过一个新颖的排序方法来排序标签,其中推荐过程是首先把一个新文档分类到一个或者多个簇,然后从那些簇中选择最相关的标签作为推荐标签。Krestel等人用LDA为目标,标签,和推荐标签指派多个话题,把目标的推荐标签是基于它的话题的。LDA是一个概率模型,基于的假设是一个文档可以表示一个不同话题的混合,于是一个话题定义为一个从一个固定词汇表的分布。在Krestel和Fankhauser(2012)的论文中,研究者提出了一个这个方法的个性化版本。
聚类可能是一个降维问题的有趣策略,产生候选互补的标签,这里的标签不是直接从目标对象的内容中或者相似目标中直接提取出来的。可是,这些候选项可莪能是太普遍了(低新颖性/特异性),结果对于描述特定目标对象的内容或者区别这些目标对象没有多大的用处。
基于L2R的方法
因为推荐经常把它看成一个排序问题,L2R技术包含一个处理它的自然方式,基于L2R的方法是一个有监督方法,能够自动学到一个基于训练集的排序函数。这个训练样例由候选标签组成,候选标签用标签质量属性向量表示,并且指定了相关的类别标签,这种方法的目标是保证模型能够把标签质量属性映射到一个相关分数或排序上。把L2R技术的应用到标签推荐问题,过去有一些尝试,Cao(2009)等人和Wu等人利用了RankSVM和RankBoost作为L2R技术,Belem等人(2011)把RankSVM和GeneticProgramming运用到了标签推荐问题。随后,他们比较了8中L2R方法,拓展了解决个性化推荐问题的主要方法,并且处理其他方面的问题,即新颖性和多样性。Canuto和Ribiro等人比较了多种L2R算法的有效性,例如随机森林,MART(Multiple Additive Regression Trees),
λ-MART,AdaRank, ListNet, Ranknet, Coordinate Ascent, Rankboost, RankSVM, 和GP。这两个研究都发现RF,MART, 和λ-MART在标签推荐问题上表现最好。
Liu(2009)概述了现存L2R算法在文档排序的背景下的应用,并把它们分为三类方法:point-wise, pair-wise, and list-wise。point-wise方法假定训练数据中的每个查询文档对都有一个数值分数,因此L2R问题可以近似为一个回归问题。Pair-wise方法近似为一个二分类-给定一堆文档,我们来预测哪一个文档是最好的。然而,list-wise方法尝试直接优化一个给定的评估度量(given evaluation measure)。论文都分析了这种方法的的优缺点,都讨论了这些方法的目标函数和IR评估度量的关系。另外,实验室以一个LETOR为基准,其中list-wise是这些方法中最有效的。
利用L2R方法的有点有3点:
(a) 这些方法在排序函数中有效利用许多属性。
(b) 可以很容易拓展到包含更多属性和目标的函数(includemore attributes and objective functions)。
(c) 学习方法有很强的理论背景,学习方法最近已经用于排序问题上了。
L2R的一个小缺点是,学习标签推荐模型的需要一定的训练时间。可是,这个步骤可以离线进行。另外,学习模型的在在线推荐步骤上的应用通常只需要很小的额外的代价,而无监督技术的方法的推荐时间更长。
还没有完,见下篇,讲的是公开的挑战问题。

相关文章推荐
- 论文笔记:A Survey on Tag Recommendation Methods 下
- 论文笔记:Personalized Tag Recommendation for Images Using Deep Transfer Learning
- 论文笔记:Personalized Deep Learning for Tag Recommendation
- 论文阅读笔记:Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
- 论文笔记:A survey on vision-based human action recognition.
- 论文笔记:Tag-Aware Personalized Recommendation Using a Hybrid Deep Model
- 论文笔记之Deep Convolutional Networks on Graph-Structured Data
- Flickr Tag Recommendation based on Collective KnowLedge
- [论文笔记] A service creation environment based on end to end composition of Web services (WWW, 2005)
- [论文笔记] Money, glory and cheap talk: analyzing strategic behavior of contestants in simultaneous crowdsourcing contests on TopCoder.com (WWW, 2010)
- 论文:Recommendation Based on Contextual Opinions 总结
- [论文笔记] Evaluation on crowdsourcing research: Current status and future direction (Information Systems Frontiers, 2012) (第一部分)
- 《Efficient Batch Processing for Multiple Keyword Queries on Graph Data》——论文笔记
- 论文笔记:Where Is Current Research on Blockchain Technology?—A Systematic Review
- 论文笔记《A Survey of Model Compression and Acceleration for Deep Neural Networks》
- 【云迁移论文笔记】A Comparison of On-premise to Cloud Migration Approaches
- 论文笔记:Fisher Kernels on Visual Vocab ularies for Image Categorization
- [论文笔记] A Survey of Software Refactoring(TOSE, 2004)第一部分
- [论文笔记] An Optimized Control Strategy for Load Balancing Based on Live Migration of Virtual Machine (ChinaGrid, 2011)
- 读论文笔记:Object Co-Segmentation Based on Shortes Path Algorithm and Saliency Mode