Java 通过URL地址下载文本内容到本地文件中
2017-10-09 21:46
846 查看
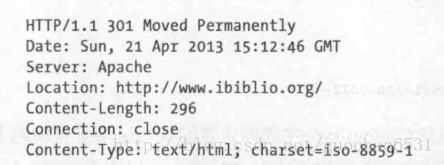
HTTP传输协议过程中,HTTP服务器在每个响应前面的首部中提供了大量信息,例如,下面一个Apache Web服务器返回的一个典型的HTTP首部:
通过URL进行资源下载时,创立连接,使用getContentType()确定文本类别,比如只下载txt文件,我们将指定非Content-Type里面非text文件,抛出异常。然后通过getContentLength()获取文本大小,通过IO流将文本内容保存到本地指定文件内。
代码如下:
通过URL进行资源下载时,创立连接,使用getContentType()确定文本类别,比如只下载txt文件,我们将指定非Content-Type里面非text文件,抛出异常。然后通过getContentLength()获取文本大小,通过IO流将文本内容保存到本地指定文件内。
代码如下:
import java.io.BufferedInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
public class BinarySaver {
private final static String url = "地址";
public static void main(String[] args) {
try {
URL root = new URL(url);
saveBinary(root);
} catch (MalformedURLException e) {
// TODO: handle exception
System.out.println(url + "is not URL");
} catch (IOException e) {
// TODO: handle exception
System.out.println(e);
}
}
public static void saveBinary(URL u) throws IOException {
// TODO Auto-generated method stub
URLConnection uc = u.openConnection();
String contentType = uc.getContentType();
int contentLength = uc.getContentLength();
/*
* 可以限制不下载哪种文本文件
if (contentType.startsWith("text/") || contentLength == -1) {
throw new IOException("This is not a binary file.");
}*/
try (InputStream raw = uc.getInputStream()) {
InputStream in = new BufferedInputStream(raw);
byte[] data = new byte[contentLength];
int offset = 0;
while (offset < contentLength) {
int bytesRead = in.read(data, offset, data.length - offset);
if (bytesRead == -1) {
break;
}
offset += bytesRead;
}
if (offset != contentLength) {
throw new IOException("Only read " + offset
+ " bytes; Expected " + contentLength + " bytes");
}
String filename = "存储位置";
try (FileOutputStream fout = new FileOutputStream(filename)) {
fout.write(data);
fout.flush();
}
}
}
}

相关文章推荐
- JAVA通过访问页面中的URL实现Http文件下载到本地
- JAVA 实现通过URL下载文件到本地库
- JAVA通过访问页面中的URL实现Http文件下载到本地
- QTP 通过URL地址下载文件到本地
- asp.net(c#)从url网络地址下载图片或文件到本地硬盘
- java通过一个url读取网站的源代码 储存到本地文件中
- 根据url地址下载文件到本地,返回本地文件地址
- Java访问Url地址并下载文件
- c#通过URL地址从服务器上下载文件
- java 通过url下载文件到浏览
- 爪哇国新游记之二十八----从url指定的地址下载文件到本地
- ASP.NET获取远程网页下载到本地文件,通过URL生成静态文件的做法
- java下载远程http地址的图片文件到本地-自动处理图片是否经过服务器gzip压缩的问题
- 通过java的io流将本地文件读取到控制台,并将文件内容再次写入另一个文件中
- 【JAVA】通过HttpURLConnection 上传和下载文件(二)
- java通过url读取文件内容示例
- 根据url地址下载文件到本地,返回本地文件地址
- java WEB项目通过url下载图片到本地
- Java通过Http请求下载文本附件到本地
- java 通过 URL 类和 URLConnection类 以及输入流实现文件下载功能