如何用通俗易懂地解释什么是数据挖掘
2017-09-29 11:19
281 查看
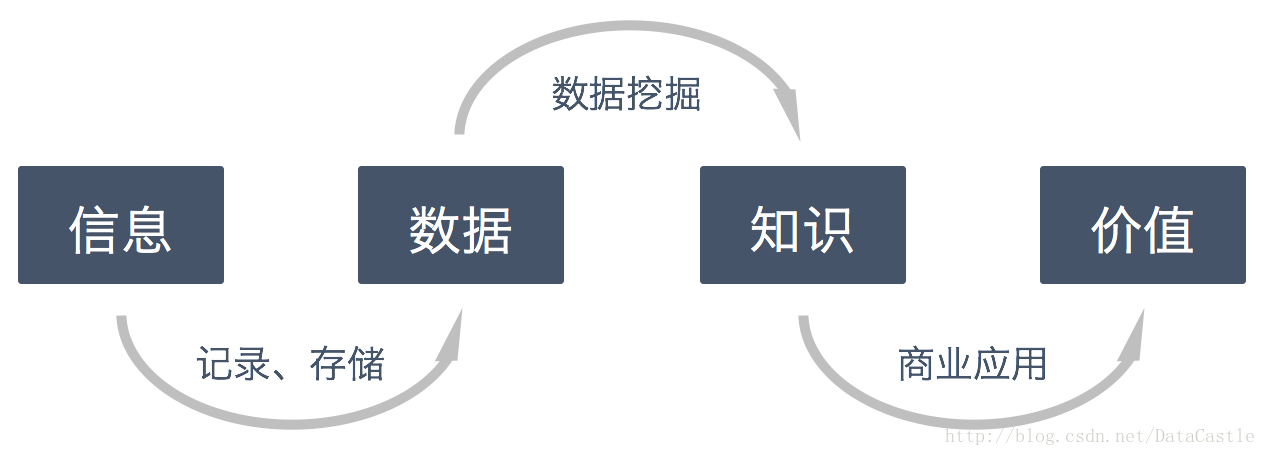
通常我们把信息转化为价值,要经历信息、数据、知识、价值四个层面,数据挖掘就是中间的重要环节,是从数据中发现知识的过程。
举个例子来说明。(例子仅供解释,不包含其他意思,Σ( ° △ °|||)︴)
傍晚你一个人从火车站出来,看到路边有一个漂亮妹子,这个妹子朝你抛了一个媚眼,这个媚眼它也是信息,虽然它很难定量化分析,也不是个记录。但你成功的接收到了这个信息,你认为是女个女孩对你有感觉。
那你就被这个信息所影响,于是你很激动,决定要上前去搭讪。(这个地方,媚眼这个信息能够被发送、传播和接收,并且影响你的行为,但还谈不上数据。)
去搭讪的时候,你问:美女,在等人吗?
然后美女对你说:老板,包夜800……
于是这里面就有定量化分析的内容了,虽然它只是一个很小的数据片段,单独看起来没有办法分析出任何深刻的结果。但如果你在一个本子上把它记录下来。比如你记录的是:
2017年10月15日,汉东省金舟市火车站包夜800
如果你的本子上有几千条这样的记录,这就是数据。通过简单的查询和比较,你就可以从这些数据中获得知识。
如果你把这些数据输入电脑,绘制一幅金舟市的价格地图,你发现同等水平的妹子在金舟市汽车客运中心价格,只有火车站的70%左右,那绘制这个地图,做这个价格的统计分析,就是数据挖掘做的事情谈,它能够指导你去做一些事情。
当然用这个知识能不能产生价值,产生多大的价值,就要看如何应用了。比如是否能够根据这些价格来指导酒店的选址,这个能不能作为附近消费水平分析依据,这就是价值和应用层面的问题。
你看,数据挖掘其实就是我们从数据中发现知识的过程。
当然我们发现知识其实可以不走数据挖掘的道路,比如我们常常讲第一性原理:从公理体系和基本参数出发,通过演绎的方法得到知识。比如通过几何的公理推出了欧几里得的公理体系,推出大量的几何定义;我们通过薛定谔方程以及一些基本的物理参数,可以得到很多对于原子分子的认识。
而数据挖掘就不是这样,数据挖掘是直接从数据中获得知识。比如,我们看一个人跑步,我们可以通过不同体型的人多次跑一百米所需要的时间,得到一些经验的公式。比如说身高每高一厘米,跑一百米的时间相应缩短0.015秒(这是随便说的,不要当真)。这样的公式是没有办法从牛顿定律中推出来的,但是我们可以从数据挖掘中得到。
就第一性原理和数据挖掘而言,数据挖掘的可信度是不如第一性原理的,因为有很多关联都是假相关,但是它能够处理很复杂的系统。而这往往是我们从量子力学、经典力学等已知的公理中不能够得到的。因为它太复杂,必须要从实验的测量中得到。
但这两者是可以相互补余的。首先,有了第一性原理的认知,他就能够提前去帮助我们提前去感觉到哪些数据可能对我们的结论最有用。比如我们看跑步,通过认知我们知道腿的长度,对跑步的速度可能是有帮助的,而腋毛的长度对跑步的速度应该是没有什么帮助的。
所以我们拿得到一个人的身体和跑步运动员跑步速度的关系,很多研究都在探索运动员的身高、腿长和跑步速度的关系,但是没什么人研究腋毛长度和跑步速度的关系。如果我们什么知识都没有的话,为什么不去研究腋毛呢?那我们就应该把腋毛和身高、腿长看成同样重要。
我们有了这些数据挖掘的工具,其实是可以反向去推导一些基本的定律。
利用数据挖掘,我们还可以做非常多的事情。
1.发现数据项之间的相关性
比如我们拿到各个城市环境、人口、交通等数据,就可以通过相关性分析来看人均汽车保有量,和空气质量各个指标之间的关系,从而定量化地帮助制定产业经济和环保政策。比如要不要进行更严厉的限购,要不要收取为其的排放税等等。
2.把数据对象进行聚类
比如我们知道大量的人在电子商务网络消费数据,我么就可以根据消费的特征把他们聚成很多类,每一类人我们制定不同的营销手段,从而能够取得销售量的提升。比如电信运营商对人群进行聚类,然后针对性地推出电话套餐。
3.把数据对象进行分类
当我们已经有了分类之后,来了一些新的数据之后,我们可以把他分到不同不同的类去。比如医疗影像上查看肺部的病灶,可能是肺结核、可能是早起肺癌,中晚期肺癌,可能是肺上的疖结,可能是愈合的病灶等等,来了一张新的片子,我们可以通过图像处理,就把它分到不同的类别(当然这需要我们提前对很多片子的数据进行学习)。
4.预测缺失数据或者未来的数据
很多数据集中,比如生物数据,我们已知的知识全部数据集中的一小部分,这需要我们做一些事情去预测这些数据。还有一些,想大选、股票价格预测、河流径流量预测、城市用电量预测等,这些就是对未来数据的预测。
如果想学习数据分析相关的知识,推荐DC学院的课程《数据分析师(入门)》

相关文章推荐
- 如何向普通人解释机器学习、数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 如何向普通人解释机器学习、数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 趣文:如何向外行解释机器学习和数据挖掘
- 如何通俗易懂地解释遗传算法?有什么例子?
- 如何向普通人解释机器学习、数据挖掘
- 如何向普通人解释机器学习、数据挖掘
- 如何准确又通俗易懂地解释大数据及其应用价值?
- 如何通俗易懂地解释遗传算法?有什么例子?
- 趣文:如何向外行解释机器学习和数据挖掘
- 如何给老婆解释什么是微服务?
- 如何免费使用数据挖掘软件RapidMiner - 申请学生许可证
- 戴琨受访《中国经济周刊》 分享如何用大数据精准挖掘二手车残值