Core Java Volume I 读书笔记---第十三章 集合
2017-09-25 23:18
344 查看
第十三章: 集合
13.1 集合接口
Java 集合类库将接口与实现分离。
集合类的基本接口是Collection接口, 其定义如下:
public interface
Collection<E>extendsIterable<E>
{
//Query Operations
int size();
// 返回当前存储在集合中的元素个数
boolean isEmpty();
//如果集合中没有元素,返回true
booleancontains(Object o);
//如果集合中包含了一个与o相等的对象,返回true
Iterator<E>iterator();
//返回一个用于访问集合中每个元素的迭代器
Object[]toArray();
//返回这个集合的对象数组
<T>T[]toArray(T[]
a);
//返回这个集合的对象数组,如果a 足够大,就讲元素填入这个数组,否则分配一个新数组
//Modification Operations
booleanadd(Ee);
//将一个元素添加到集合中,如果这个调用改变了集合,返回true
boolean remove(Object o);
//从这个集合删除等于obj,如果匹配的对象被删除,返回true
//Bulk Operations
boolean containsAll(Collection<?> c);
//如果这个集合包含c集合中的所有元素,则返回true
booleanaddAll(Collection<?extendsE>c);
//将c 集合中的所有元素添加到这个集合,如果调用改变了集合,返回true
booleanremoveAll(Collection<?> c);
//从这个集合中删除c集合中存在的所有元素,如果这个调用改变了集合,返回true
default booleanremoveIf(Predicate<?superE>
filter) {
Objects.requireNonNull(filter);
booleanremoved = false;
finalIterator<E> each = iterator();
while(each.hasNext()) {
if (filter.test(each.next())){
each.remove();
removed = true;
}
}
return removed;
}
booleanretainAll(Collection<?> c);
//从这个集合中删除所有与other集合中元素不同的元素,如果这个调用改变了集合,返回true
voidclear();
//从这个集合中删除所有元素
<
4000
span style="color:#808080;">//Comparison and hashing
booleanequals(Object o);
inthashCode();
@Override
defaultSpliterator<E>spliterator() {
return Spliterators.spliterator(this,0);
}
defaultStream<E>stream()
{
return StreamSupport.stream(spliterator(), false);
}
defaultStream<E>parallelStream()
{
return StreamSupport.stream(spliterator(), true);
}
}
Collection 接口有几个必要重要的方法:
1. boolean add(E e);
add 方法用于向集合中添加元素, 如果元素确实改变了集合就返回true, 如果集合没有发生变化就返回false. 集合中不允许有重复的对象, 如果一个对象已在集合中, 再掉用add 方法添加就不会生效
2. Iterator<E> iterator();
Iterator 方法用于返回一个实现了Iterator 接口的对象,用来遍历集合中的元素。 Iterator 方法是从Iterable 接口继承来的。
Iterator 接口定义如下:
publicinterface Iterator<E>
{
E next();
Boolean hasNext();
void remove();
}
foreach 循环就是通过迭代器实现的, 编译器简单的将for each 循环翻译成带有迭代器的循环的。 for each 循环可以与任何实现了Iterable接口的对象一起工作。标准库中任何集合都可以使用for each ,因为Collection 接口实现了扩展了Iterable接口。
Java中迭代器是位与两个元素之间, 当调用next 时, 迭代器就越过下一个元素,并返回刚刚越过的那个元素的引用。
remove方法会删除上次调用next 方法时返回的元素, 所以next方法和remove方法具有相互依赖性。 如果调用remove 之前没有调用next方法时非法的。如果next 方法后集合已经发生了改变, remove 方法也会抛出异常。
Collection 接口中方法毕竟多, 如果都要自己实现比较麻烦。 所以Java 类库提供了AbstractCollection 类, 里面很多方法提供了实现。 扩展AbstractCollection 来实现自己的集合类是比较合适的。
13.2 具体的集合
13.2.1 ArrayList
(Odered)有序集合,使用数组实现, 支持快速随机访问,缺点是在中间位置插入或者删除元素效率很低,因为要移动被插入或者删除位置之后的所有元素
13.2.2 LinkedList
(Odered)有序集合,使用双向链表(注意不是循环链表)实现,在中间位置添加或者删除元素很高效, 访问元素效率低
有一个专门供List 使用的迭代器类ListIterator:
public interface
ListIterator<E>extends
Iterator<E> {
//Query Operations
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
//Modification Operations
void remove();
void set(Ee);
void add(Ee);
在普通的Iterator接口上,增加了previous() 和hasPrevious() 用来方向遍历链表
同时还增加了add ,set 方法,不过对LinkedList 来说效率不高
13.2.3 Vector
Vector 也是一种List, (Odered)有序集合, 使用数组实现。
和ArrayList 区别在于,Vector 是线程安全的, 在单线程情况下ArrayList效率更高
13.2.4 Hashset
无序集合, 使用散列表实现(JAVA中散列表用链表数组来实现HashMap)。能快速查询元素, 通过hashCode % 散列表桶总数即可得到元素的位置。
装填因子决定何时对散列表进行再散列,默认为0.75,即如果表中超过75%的位置已填入元素,这个表就会使用双倍的桶数进行再散列。
SET 接口扩展了Collection接口, 不过Collection 不能有重复的元素(同一个对象存两个),SET 则更加严格一点,不能有equal 的元素(equals 方法放回true), 对于HashSet来说, equal 的对象hashCode 也一样,会散列到同一个位置。
public interface
Set<E>extends
Collection<E> {
//Query Operations
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E>iterator();
Object[] toArray();
<T>T[]
toArray(T[] a);
//Modification Operations
boolean add(Ee);
boolean remove(Object o);
//Bulk Operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<?extendsE>c);
boolean retainAll(Collection<?> c);
boolean removeAll(Collection<?> c);
void clear();
//Comparison and hashing
boolean equals(Object o);
int hashCode();
@Override
defaultSpliterator<E>spliterator() {
return Spliterators.spliterator(this,Spliterator.DISTINCT);
}
}
public HashSet()
//构造一个空的散列集
public HashSet(Collection<?extends
E> c)
//构造一个散列集,并将集合中的所有元素添加到这个散列集中
public HashSet(intinitialCapacity)
//构造一个空的具有指定容量的散列集
public HashSet(intinitialCapacity,
floatloadFactor)
//构造一个具有指定容量和装填因子的散列集
13.2.5 TreeSet
(Sorted)有序集合, 并且元素是按照顺序排列的。对集合遍历时,每个值自动安装排序后的顺序呈现
排序使用红黑树完成(JavaTreeMap), 将元素添加到树中要比添加到散列表中慢,比添加到数组或者链表中间快。
TreeSet 会对元素排序,所以要求提供比较对象的compareTo 方法。 默认情况下TreeSet 要求元素实现Comparable 接口, 如果不想使用元素的compareTo方法,还可以将Comparator对象传递给TreeSet的构造器。
public TreeSet()
//构造一个用于排列Comparable对象的树集
public TreeSet(Comparator<?super
E> comparator)
//构造一个树集,并使用指定的比较器对其中的元素进行排序
public TreeSet(Collection<?extends
E> c)
//构造一个树集,将有序集中的所有元素添加到这个树集中,并使用与给定集相同的元素比较器
13.2.6 队列和双端队列
队列接口:
public interface
Queue<E>extends
Collection<E> {
boolean add(Ee);
boolean offer(Ee);
//如果队列没有满,将给定的元素的添加到这个队列的尾部并返回true;如果队列已满,第一个方法抛出IllegalStateException,第二个方法返回false
E remove();
E poll();
//如果队列不为空,删除并返回这个队列头部的元素。如果队列为空,第一个方法抛出NoSuchElementExcetion, 第二个方法返回null
E element();
E peek();
//如果队列不为空,返回这个队列头部的元素,但不删除。 如果队列为空,第一个方法返回NoSuchElementException,第二个方法返回null
}
双端队列接口:
public interface
Deque<E>extends
Queue<E> {
void addFirst(Ee);
void addLast(Ee);
booleanofferFirst(Ee);
boolean offerLast(Ee);
//将给定的对象添加到双端队列的头部或者尾部。 如果队列满了,前两个方法抛出一个IllegalStateException, 而后两个方法返回false.
E removeFirst();
E removeLast();
E pollFirst();
E pollLast();
//如果队列不为空,删除并返回队列头部或者尾部的元素。如果队列为空,前面两个方法抛出一个NoSuchElementException,后面两个方法返回null.
E getFirst();
E getLast();
E peekFirst();
E peekLast();
//如果队列非空,返回队列头部或尾部的元素,但不删除。如果队列为空,前两个方法抛出一个NoSuchElementException,后两个方法返回null
boolean removeFirstOccurrence(Object o);
boolean removeLastOccurrence(Object o);
//*** Queue methods ***
boolean add(Ee);
boolean offer(Ee);
E poll();
E element();
E peek();
//*** Stack methods ***
void push(Ee);
E pop();
//*** Collection methods ***
boolean remove(Object o);
boolean contains(Object o);
public int size();
Iterator<E>iterator();
Iterator<E>descendingIterator();
}
双端队列在Java标准库中有两个实现,ArrayDeque 和LinkedList. LinkedList 前面涉及过,这里不在描述。
/**
* Constructs an empty array deque withan initial capacity
* sufficient to hold 16 elements.
*/
public ArrayDeque() {
elements=newObject[16];
}
/**
* Constructs an empty array deque withan initial capacity
* sufficient to hold the specifiednumber of elements.
*
* @param numElements
lower bound on initial capacity of the deque
*/
public ArrayDeque(intnumElements) {
allocateElements(numElements);
}
ArrayDeque使用数组实现, 有两个常用的构造器。
默认构造器会构造一个队列, 长度为16;或者使用给定的初始容量来构造一个队列。
13.2.7 优先级队列
优先级队列(priority queue) 中的元素可以按照任意的顺序插入, 却总是按照排序的顺序进行检索, 无论何时调用remove方法,总会获得当前优先级队列中最小的元素。
优先级队列没有对所有元素排序,使用了一种优雅而高兴的数据结构堆(heap). 堆是一种可以自我调整的二叉树, 对树执行add和remove 操作,可以让最小的元素移动到根。
使用优先级队列最典型的场景时任务调度。
public PriorityQueue()
public PriorityQueue(intinitialCapacity)
//使用默认容量11或者初始容量构造一个存放Comparable对象的优先级队列
public PriorityQueue(Comparator<?superE>
comparator)
public PriorityQueue(intinitialCapacity,
Comparator<? superE> comparator)
//使用默认容量11 或者初始容量构造一个优先级队列,并用指定的比较器对元素进行比较
13.2.8 映射表Map
Map用来存储键值对, 如果提供了键,就能查找到值。
public interface
Map<K,V> {
//Query Operations
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
//获取键对应的值,若不存在则返回null
//Modification Operations
V put(Kkey,
V value);
V remove(Object key);
//Bulk Operations
void putAll(Map<?extends
K,?
extends V> m);
//将给定Map中的所有条目添加到这个Map中
void clear();
//Views
Set<K>keySet();
//返回映射表中所有键的集视图。可以从这个集中删除元素,同时Map中也删除了它们,但不能添加元素
Collection<V>values();
// 返回映射表中所有值的集合视图。可以从这个集中删除元素,同时也从映射表中删除了它们,但不能添加任何元素。
Set<Map.Entry<K,V>>
entrySet();
//返回Map.Entry对象的视图,即映射表中的键/值对。可以从这个集中删除元素,同时也从Map中删除了它们,但不能添加元素。
interface Entry<K,V> {
K getKey();
V getValue();
//返回这个条目的键或值
V setValue(Vvalue);
//设置条目的值,同时返回旧值
boolean equals(Object o);
int hashCode();
…………….
}
//Comparison and hashing
booleanequals(Object o);
inthashCode();
//Defaultable methods
………
}
要注意Map 中定义了一个内部类型 Map.Entry<K,V> 用来表示Map 中的条目。
Map 本身不被视为一个集合(Collection), 不过Map 的三个视图都是集合。
Java类库为Map提供了两个通用的实现:HashMap 和TreeMap
HashMap 本质还是通过哈希表(链表数组)实现的,通过key 的hash值来定位, 数据同时存储了key 和Value ,所以可以根据Key找到Value
public HashMap() {
this.loadFactor=
DEFAULT_LOAD_FACTOR;// all other fieldsdefaulted
}
//使用默认装填因子0.75构造HashMap
public HashMap(intinitialCapacity) {
this(initialCapacity,DEFAULT_LOAD_FACTOR);
}
//使用初始容量和默认装填因子构造HashMap
public HashMap(intinitialCapacity,
floatloadFactor) {
if(initialCapacity <0)
throw new IllegalArgumentException("Illegal initial capacity: "+
initialCapacity);
if(initialCapacity > MAXIMUM_CAPACITY)
initialCapacity =MAXIMUM_CAPACITY;
if(loadFactor <= 0|| Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: "+
loadFactor);
this.loadFactor= loadFactor;
this.threshold=
tableSizeFor(initialCapacity);
}
//使用给定的初始容量和装填因子构造HashMap
Node<K,V>[]table;
static class Node<K,V>implements
Map.Entry<K,V> {
finalint hash;
finalK key;
Vvalue;
Node<K,V>next;
Node(inthash,
K key,V
value,Node<K,V>
next) {
this.hash= hash;
this.key= key;
this.value= value;
this.next= next;
}
publicfinal KgetKey() {returnkey;}
publicfinal VgetValue() {returnvalue;}
publicfinal StringtoString() {return
key +
"=" +value;
}
publicfinal int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
publicfinal VsetValue(VnewValue) {
V oldValue =value;
value = newValue;
returnoldValue;
}
publicfinal boolean equals(Object o) {
if (o ==this)
returntrue;
if(o instanceofMap.Entry) {
Map.Entry<?,?> e =(Map.Entry<?,?>)o;
if(Objects.equals(key,e.getKey()) &&
Objects.equals(value,e.getValue()))
return true;
}
return false;
}
}
TreeMap 是使用树构造的, 树中的元素为<K,V> 对:
public TreeMap() {
comparator=null;
}
//构造一个空的TreeMap
public TreeMap(Comparator<?superK>comparator)
{
this.comparator= comparator;
}
//构造一个TreeMap,并使用给定的比较器来排序
public TreeMap(Map<?extends
K,?
extends V> m) {
comparator=null;
putAll(m);
}
//构造一个TreeMap,并将某个Map
中的所有天目添加进去
public TreeMap(SortedMap<K,?
extends V> m) {
comparator= m.comparator();
try{
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
}catch
(java.io.IOExceptioncannotHappen) {
}catch(ClassNotFoundException cannotHappen) {
}
}
//构造一个TreeMap 并将某个有序Map中的所有条目添加进去,并使用给定有序Map 相同的比较器
13.2.9 专用集与映射表类
1. 若散列映射表(WeakHashMap): 使用若引用(WeakReference 来保存键), 如果键被回收,WeakHashMap 会将对应的条目删除。
2. LinkedHashSet 和LinkedHashMap, 用来记住插入元素项的顺序
LInkedHashMap 是HashMap 的子类, 增加了两个标记用来记录条目链表的头和尾:
/**
* The head (eldest) of the doubly linkedlist.
*/
transient LinkedHashMap.Entry<K,V>head;
/**
* The tail (youngest) of the doublylinked list.
*/
transient LinkedHashMap.Entry<K,V>tail;
HashMap 是使用链表数组实现的, 根据Key 的hash 值散列到数组位置。 而链表节点之间是孤立的, Node 节点的next 都是null .
LinkedHashMap 的链表节点是Linked 的, 条目之间构造了一个链表。 然后记录了链表的头和尾位置, 所以知道元素的顺序。
使用迭代器访问keySet或者ValueSet 时, 都按照访问顺序输出结果的
LinkedHashMap 元素位置会变(条目在链表中位置改变)。 每次调用get或者put , 受影响的条目都会移动到链表的尾部。(条目在Hash表中的实际位置没变,调整了链表中顺序)
LinkedHashMap 还可以用来实现高速缓存:将不用的老的元素自动删除掉,覆盖其removeEldestEntry方法就可以。
LinkedHashSet 和LinkedHashMap 基本类似, 只不过Set 中只存储一个数据, 而map存储了两个数据
3. 枚举集和映射表
EnumSet 内部用位序列实现,如果对应的值在集中,则相应的位置为1;
EnumMap 是一个键类型为枚举类型的映射表, 使用值数组实现。
4. IdetityHashMap
键的散列值不是用键的hashCode 函数计算,而是用System.identityHashCode(即Obeject.hashCOde)计算。
对象比较时也使用== ,而不是equals.
即不同的键对象,即时内容相同也被视为不同的对象
13.3 集合框架
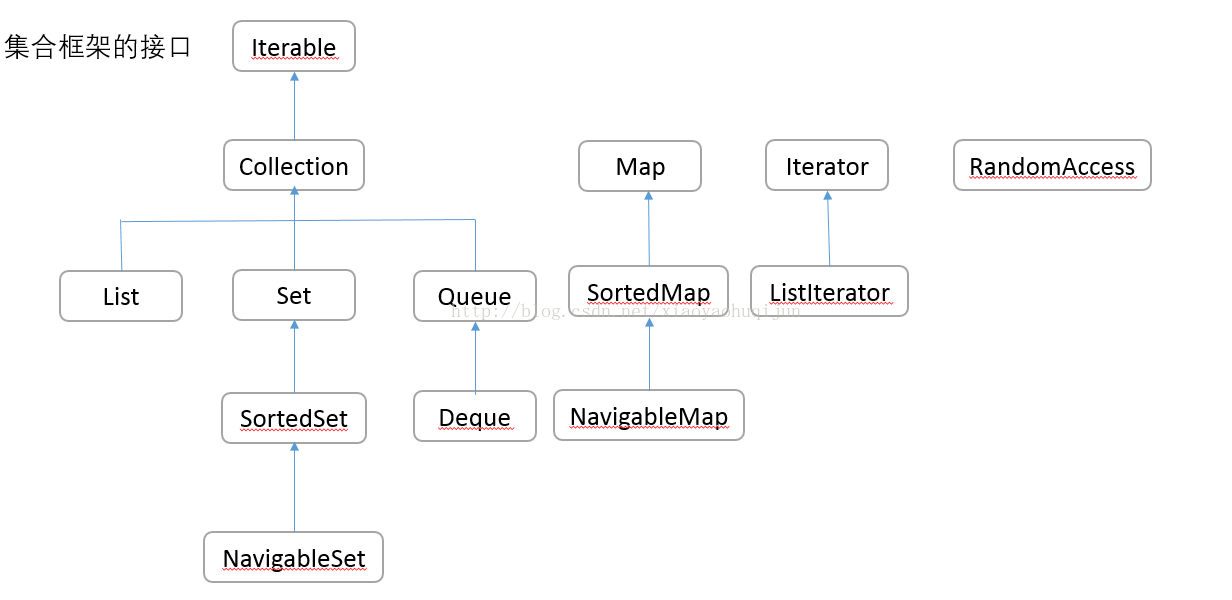
集合框架的接口如上图所示。
集合有两个基本的接口:Collection 和Map
RandomAccess 是一个标记接口,标记某个特定的集合是否支持高效的随机访问。

1. 轻量级集包装器
Arrays.asList 将返回一个包装了普通Java 数组的List 包装器, 它时一个视图对象。
2. 子范围视图
例如List group2 = staff.subList(10,20); 第一个索引包含在内,第二个索引不包含在内
3. 不可修改视图
4. 同步视图
类库的设计者使用视图机制来确保常规集合的线程安全,而不是实现线程安全的集合类。
例如Collections 类的静态反复synchronizedMap 方法可以将任何一个映射表转换成具有同步访问方法的Map.
集合与数组之间的转换:
1. 数组转集合
Arrays.asList 包装器
2. 集合转数组
Object[] toArray();
<T>
T[]
toArray(T[] a);
第一种toArray返回Obejct[]不是我们需要的, 使用第二种toArray 方法即可。
13.4 算法
泛型算法, 类似C++STL中的算法。
Collection 接口的 算法都定义在Collections类中,整个类中方法非常多,这里挑一些常用的介绍下:
1. Max 和Min
public static <T
extends Object &Comparable<?
super T>>
T min(Collection<?
extendsT>coll) {
Iterator<?extends T> i = coll.iterator();
Tcandidate = i.next();
while(i.hasNext()) {
T next = i.next();
if(next.compareTo(candidate) <
0)
candidate = next;
}
returncandidate;
}
public static <T>
T min(Collection<?
extends T> coll,
Comparator<? super
T> comp) {
if(comp==null)
return (T)min((Collection) coll);
Iterator<?extends
T> i = coll.iterator();
Tcandidate = i.next();
while(i.hasNext()) {
T next = i.next();
if(comp.compare(next,candidate) <
0)
candidate = next;
}
returncandidate;
}
public static <T
extends Object &Comparable<?
super T>>
T max(Collection<?
extendsT>coll) {
Iterator<?extends T> i = coll.iterator();
Tcandidate = i.next();
while(i.hasNext()) {
T next = i.next();
if(next.compareTo(candidate) >
0)
candidate = next;
}
returncandidate;
}
public static <T>
T max(Collection<?
extends T> coll,
Comparator<? super
T> comp) {
if(comp==null)
return (T)max((Collection)coll);
Iterator<?extends
T> i = coll.iterator();
Tcandidate = i.next();
while(i.hasNext()) {
T next = i.next();
if(comp.compare(next,candidate) >
0)
candidate = next;
}
returncandidate;
}
2. 排序和混排
public static <T
extends Comparable<?
super T>>
void sort(List<T> list) {
list.sort(null);
}
public static <T>
void sort(List<T> list,
Comparator<? super
T> c) {
list.sort(c);
}
public static void
shuffle(List<?> list) {
Random rnd =r;
if(rnd == null)
r= rnd =
newRandom();// harmless race.
shuffle(list,
rnd);
}
public static void
shuffle(List<?> list,
Random rnd) {
intsize = list.size();
if(size < SHUFFLE_THRESHOLD|| list
instanceofRandomAccess) {
for (int
i=size;
i>1;
i--)
swap(list, i-1,
rnd.nextInt(i));
}else
{
Object arr[] = list.toArray();
// Shuffle array
for (int
i=size;
i>1;
i--)
swap(arr, i-1,
rnd.nextInt(i));
// Dump array back into list
// instead of using a raw typehere, it's possible to capture
// the wildcard but it willrequire a call to a supplementary
// private method
ListIterator it = list.listIterator();
for(int
i=0;
i<arr.length;
i++) {
it.next();
it.set(arr[i]);
}
}
}
排序算法实现: 将所有元素转入一个数组, 使用一种归并排序的变体对数组进行排序, 然后将排序后的序列赋值回列表
Shuffle 的实现: 如果排序的列表没有实现RandomAccess 接口, shuffle方法将元素复制到数组中,然后打乱数组的顺序, 再将打乱的后的元素复制回列表。
3. 二分查找
public static <T>
int binarySearch(List<?
extends Comparable<?
super T>> list,
T key) {
if(list
instanceofRandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list,
key);
else
returnCollections.iteratorBinarySearch(list,
key);
}
二分查找要求List 是有序的, 否则将会返回错误的结果
13.5 遗留的集合
1. Hashtable
Hashtable 与HashMap 作用一样,有相同的接口。Hashtable 是线程安全的, 如果对同步性没有要求,应该使用HashMap
2. 遗留集合使用Enumeration接口对元素进行遍历, 类似Iterator, Enumerator 接口有两个方法: hashMoreElements 和nextElement.
3. 属性映射表(property map)
Property map 是一种特殊的映射表: 键值都是自符串, 表可以保存到文件中也可以从文件中加载, 一般用于配置项
4. Stack
Push 压入栈,Pop 弹出栈。
5. BitSet
public BitSet(int
nbits)
//创建一个位集
public void set(int
bitIndex)
//设置某一位为true
public void clear(int
bitIndex)
//将某一位置为false
public boolean get(int
bitIndex)
获取某一位的状态

相关文章推荐
- 【Core Java Volume 6】集合算法--二分查找法
- Core Java Volume I 读书笔记
- 【Core Java Volume 4】java中数组Array和集合之间的相互转换
- 【Core Java Volume 5】集合算法---查找数组、集合最大值的通用方法
- Core Java Volume I 读书笔记---第十四章 多线程
- 【Core Java Volume 3】反射---编写泛型数组代码
- Java设置的读书笔记和集合框架Collection API
- 《Core Java Volume I》学习笔记之命令行方式开发java程序
- 【java读书笔记】——Collection集合之六大接口(Collection、Set、List、Map、Iterator和Comparable)
- corejava[读书笔记]第四章
- 读书笔记--编写高质量代码:改善java程序的151个建议(五)数组和集合
- 【java读书笔记】——Collection集合之六大接口(Collection、Set、List、Map、Iterator和Comparable)
- <Core Java Volume I Fundamentals 9th Edition> Note 01
- Core Java. Volume I. Fundamentals, 8th Edition 下载地址及读后感
- thingking in java 读书笔记---对象集合和容器
- 读书笔记(java集合)
- Core Java Volume I — 5.1. Classes, Superclasses, and Subclasses
- 【java读书笔记】——Collection集合之六大接口(Collection、Set、List、Map、Iterator和Comparable)
- Core Java --集合--LinkedHashMap的实现原理
- 《Servlet与JSP核心编程》笔记(Note of 《Core Servlets and JavaServer Pages:Volume 1:Core Technologies 2nd》)