CNN卷积神经网络层级结构
2017-09-25 19:38
274 查看
卷积神经网络层次结构包括:
数据输入层/ Input layer
卷积计算层/ CONV layer
激励层 / ReLU layer
池化层 / Pooling layer
全连接层 / FC layer

去均值:把输入数据各个维度都中心化到0
归一化:幅度归一化到同一范围
PCA/白化:用PCA降维,白化是在对数据每个特征轴上的数据进行归一化。
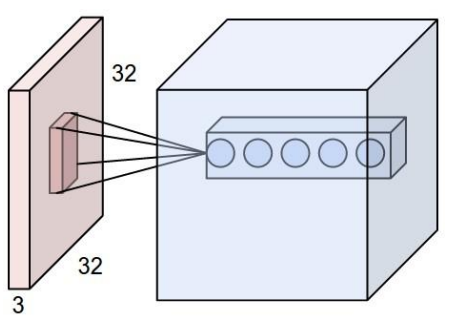
如上图图所示,左边为数据集,右边为一个神经网络
窗口:卷积计算层会在数据集上选定一个窗口,从窗口内选择数据
深度(depth):如下图所示,左边的数据集深度为3,右边的神经网络深度为5(有五个神经元)
步长(stride):窗口每次移动的距离
填充值(zero-padding):因为窗口移动到数据边缘时,可能不能正好遍历完所有数据,所以有时要在数据集周边填充上若干圈全为0的数据
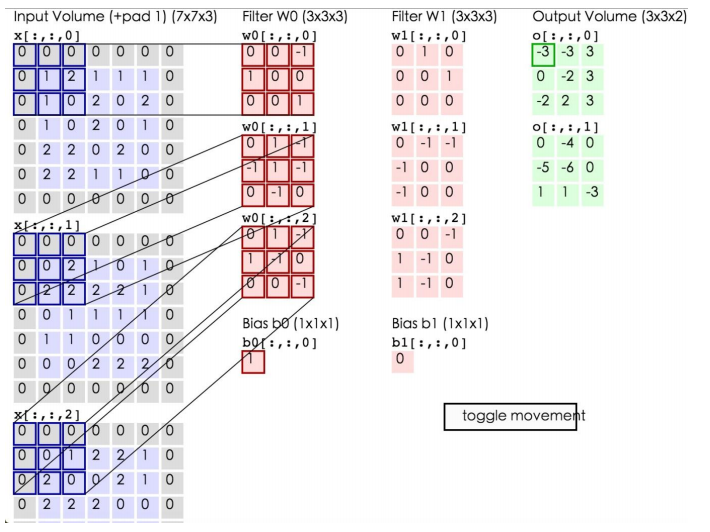
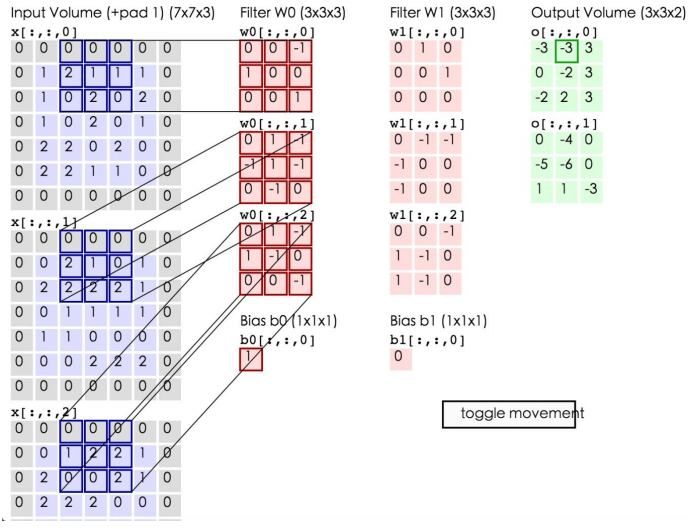
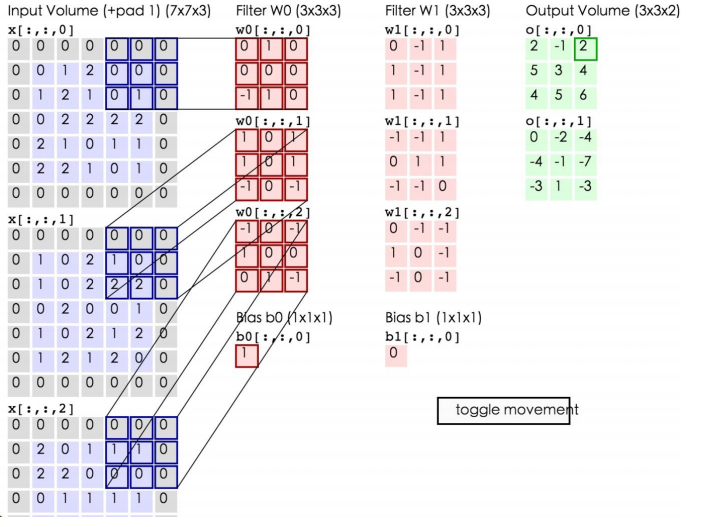
如上所示,左边为输入数据,中间为两个神经元,右边为输出。可以看到左边的输入数据中,窗口大小为3*3,每次移动的步长为2,周围有一层的填充数据,深度为3。中间为两个Filter,也就是线性方程的系数,注意Filter下面还有两个Bias偏移量。将窗口中的数据分别和Filter中的数据做卷积运算(即对应位置的数据相乘),再加上Bias偏移量即可得到一个输出矩阵中的一个值。比如在第一幅图的第三个窗口中的数据与Filter W0所做的运算为:
第一个窗口:0*0+0*0+0*(-1)+0*1+1*0+2*0+0*1+1*0+0*1=0
第二个窗口:0*0+0*1+0*(-1)+0*(-1)+0*1+2*(-1)+0*0+2*(-1)+2*0=-4
第三个窗口:0*0+0*1+0*(-1)+0*1+0*(-1)+1*0+0*0+2*0+0*(-1)=0
将这三个窗口中的值加起来再加上偏移量即得到了输出值:0+(-4)+0+1(偏移量)=-3,即第一个输出矩阵中的第一个值。
通过卷积层的计算后,可以使数据量大大减少,并且能够一定程度上保存数据集的信息
sigmoid函数如下所示:
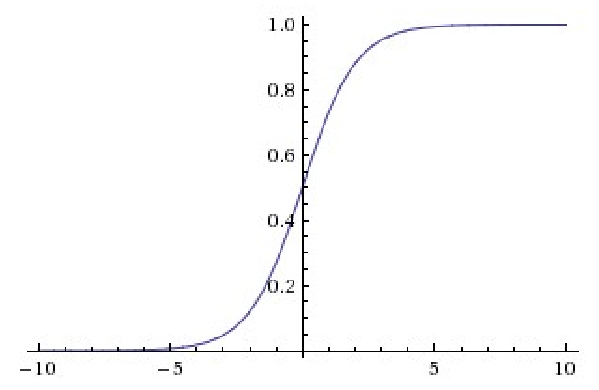
sigmoid函数是早期用的比较多的激励函数,但现在已经不常用了。主要是当输入特别大或者特别小时,sigmoid函数的偏导数趋于0,这样在使用反向传播算法时将会出现问题,并且sigmoid函数不是关于原点对称的,这样在进行反向传播时w的梯度要么全为正,要么全负(w的梯度即为x乘以上一层的梯度,x恒为正,所以梯度的正负一直不变),收敛速度会非常慢。tanh函数与sigmoid函数图像类似,但是它比sigmoid函数好的一点是tanh函数是关于原点对称的,这样可以减少数据的倾斜。
现在比较常用的激励函数为ReLu(The Rectified Linear Unit/修正线性单元),函数表达式为:f(x)=max(0,x),其函数图像如下所示:
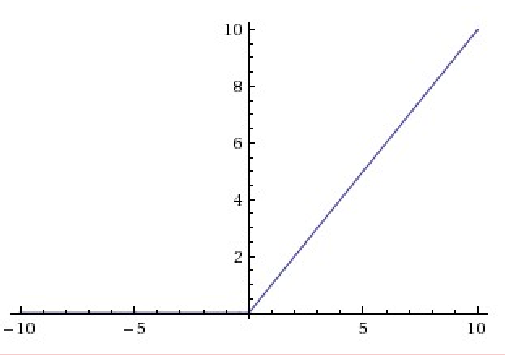
ReLu函数的有点是收敛非常快,因为在原点右侧它的偏导数为1,求导简单,这样在做反向传播时速度比较快。缺点时较为脆弱,原点左侧的函数具有的sigmoid相似的问题,即导数等于0。
Leaky ReLu在是ReLu的“增强版”,其函数表达式为:f(x)=max(ax,x),a通常为一个比较小的数,比如0.01,线面是a=0.01时的图像:
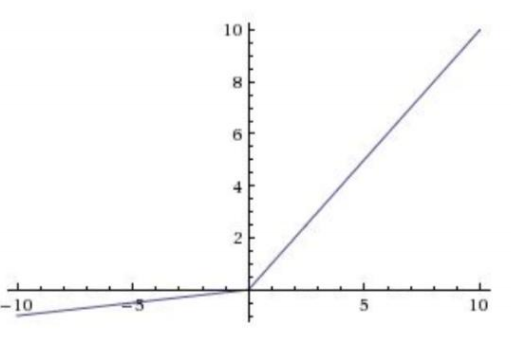
可以看到,相比ReLu,Leaky ReLu在原点左侧的表达式中对x乘以了一个比较小的系数,这样保证了在做反向传播时不会挂掉,并且其计算也很快。
ELU指数线性单元
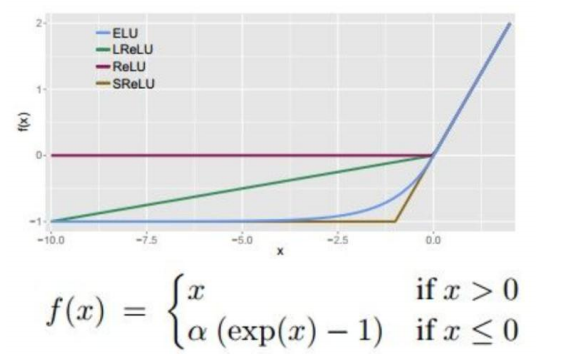
ELU不会挂掉,计算速度比较快,并且输出的均值趋于0,但是由于指数的存在,计算量略大。
Maxout:
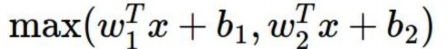
两条直线拼接而成,计算是线性的,比较快,不会饱和不会挂,但是参数比较多。
激励函数使用总结:
1.尽量不要用sigmoid函数
2.首选ReLu,速度快,但是需要小心,有可能会挂掉
3.ReLu不行的话再选用Leaky ReLu或者Maxout
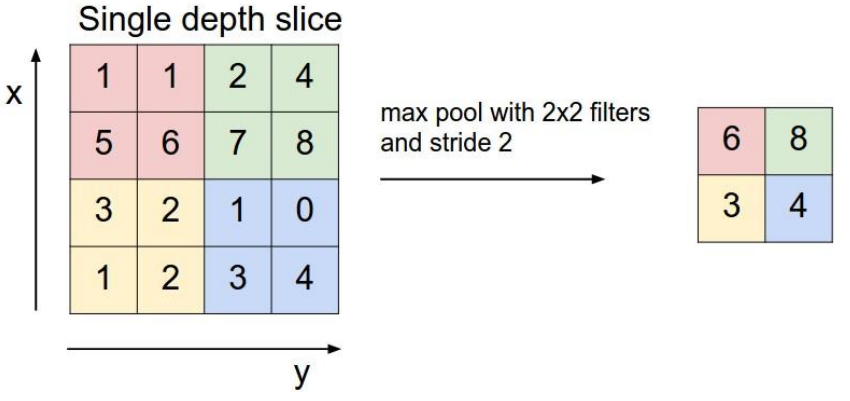
池化层的选择策略有max pooling和average Pooling,上图展示的就是max Pooling的过程。在原始的数据层上划分一个个小块,在每个小块中选择最大的那个数代表这个小块中所有的数(如果是average Pooling就选择平均数),放到下一层。这样就打打减少了数据量。这种做法的理论依据好像还不太清楚,但是可以想象在一幅图中,每个像素点和其周边的点大致是一样的,所以用一个点代替其周边点也有一定道理。
数据输入层/ Input layer
卷积计算层/ CONV layer
激励层 / ReLU layer
池化层 / Pooling layer
全连接层 / FC layer
输入层(Input layer)
输入数据,通常会作一些数据处理,例如:去均值:把输入数据各个维度都中心化到0
归一化:幅度归一化到同一范围
PCA/白化:用PCA降维,白化是在对数据每个特征轴上的数据进行归一化。
卷积计算层(CONV layer)
如上图图所示,左边为数据集,右边为一个神经网络
窗口:卷积计算层会在数据集上选定一个窗口,从窗口内选择数据
深度(depth):如下图所示,左边的数据集深度为3,右边的神经网络深度为5(有五个神经元)
步长(stride):窗口每次移动的距离
填充值(zero-padding):因为窗口移动到数据边缘时,可能不能正好遍历完所有数据,所以有时要在数据集周边填充上若干圈全为0的数据
如上所示,左边为输入数据,中间为两个神经元,右边为输出。可以看到左边的输入数据中,窗口大小为3*3,每次移动的步长为2,周围有一层的填充数据,深度为3。中间为两个Filter,也就是线性方程的系数,注意Filter下面还有两个Bias偏移量。将窗口中的数据分别和Filter中的数据做卷积运算(即对应位置的数据相乘),再加上Bias偏移量即可得到一个输出矩阵中的一个值。比如在第一幅图的第三个窗口中的数据与Filter W0所做的运算为:
第一个窗口:0*0+0*0+0*(-1)+0*1+1*0+2*0+0*1+1*0+0*1=0
第二个窗口:0*0+0*1+0*(-1)+0*(-1)+0*1+2*(-1)+0*0+2*(-1)+2*0=-4
第三个窗口:0*0+0*1+0*(-1)+0*1+0*(-1)+1*0+0*0+2*0+0*(-1)=0
将这三个窗口中的值加起来再加上偏移量即得到了输出值:0+(-4)+0+1(偏移量)=-3,即第一个输出矩阵中的第一个值。
通过卷积层的计算后,可以使数据量大大减少,并且能够一定程度上保存数据集的信息
激励层
激励层的主要作用是将卷积层的结果做非线性映射。常见的激励层函数有sigmoid、tanh、Relu、Leaky Relu、ELU、Maxoutsigmoid函数如下所示:
sigmoid函数是早期用的比较多的激励函数,但现在已经不常用了。主要是当输入特别大或者特别小时,sigmoid函数的偏导数趋于0,这样在使用反向传播算法时将会出现问题,并且sigmoid函数不是关于原点对称的,这样在进行反向传播时w的梯度要么全为正,要么全负(w的梯度即为x乘以上一层的梯度,x恒为正,所以梯度的正负一直不变),收敛速度会非常慢。tanh函数与sigmoid函数图像类似,但是它比sigmoid函数好的一点是tanh函数是关于原点对称的,这样可以减少数据的倾斜。
现在比较常用的激励函数为ReLu(The Rectified Linear Unit/修正线性单元),函数表达式为:f(x)=max(0,x),其函数图像如下所示:
ReLu函数的有点是收敛非常快,因为在原点右侧它的偏导数为1,求导简单,这样在做反向传播时速度比较快。缺点时较为脆弱,原点左侧的函数具有的sigmoid相似的问题,即导数等于0。
Leaky ReLu在是ReLu的“增强版”,其函数表达式为:f(x)=max(ax,x),a通常为一个比较小的数,比如0.01,线面是a=0.01时的图像:
可以看到,相比ReLu,Leaky ReLu在原点左侧的表达式中对x乘以了一个比较小的系数,这样保证了在做反向传播时不会挂掉,并且其计算也很快。
ELU指数线性单元
ELU不会挂掉,计算速度比较快,并且输出的均值趋于0,但是由于指数的存在,计算量略大。
Maxout:
两条直线拼接而成,计算是线性的,比较快,不会饱和不会挂,但是参数比较多。
激励函数使用总结:
1.尽量不要用sigmoid函数
2.首选ReLu,速度快,但是需要小心,有可能会挂掉
3.ReLu不行的话再选用Leaky ReLu或者Maxout
池化层(Pooling layer)
在连续的卷基层和激励层中间,用于压缩数据和参数的量,用于减少过拟合。池化层的选择策略有max pooling和average Pooling,上图展示的就是max Pooling的过程。在原始的数据层上划分一个个小块,在每个小块中选择最大的那个数代表这个小块中所有的数(如果是average Pooling就选择平均数),放到下一层。这样就打打减少了数据量。这种做法的理论依据好像还不太清楚,但是可以想象在一幅图中,每个像素点和其周边的点大致是一样的,所以用一个点代替其周边点也有一定道理。
全连接层(FC layer)
全连接层即两层之间的所有神经元都有权重连接,通常会在卷积神经网络的尾部。
相关文章推荐
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构的区别
- CNN入门讲解:如何理解卷积神经网络的结构
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- C++卷积神经网络实例:tiny_cnn代码详解(11)——层结构容器layers类源码分析
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?(知呼回答)
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- 卷积神经网络(CNN)模型结构
- 卷积神经网络(CNN)模型结构
- 卷积神经网络CNN介绍:结构框架,源码理解
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构区别
- 编写C语言版本的卷积神经网络CNN之二:CNN网络的总体结构
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN 卷积神经网络结构
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- 卷积神经网络(CNN)模型结构
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?