深度学习——提高网络性能(一)
2017-09-22 20:31
357 查看
一、偏差/方差:
深度学习很少谈论偏差,方差权衡问题,一般都是分开讨论:
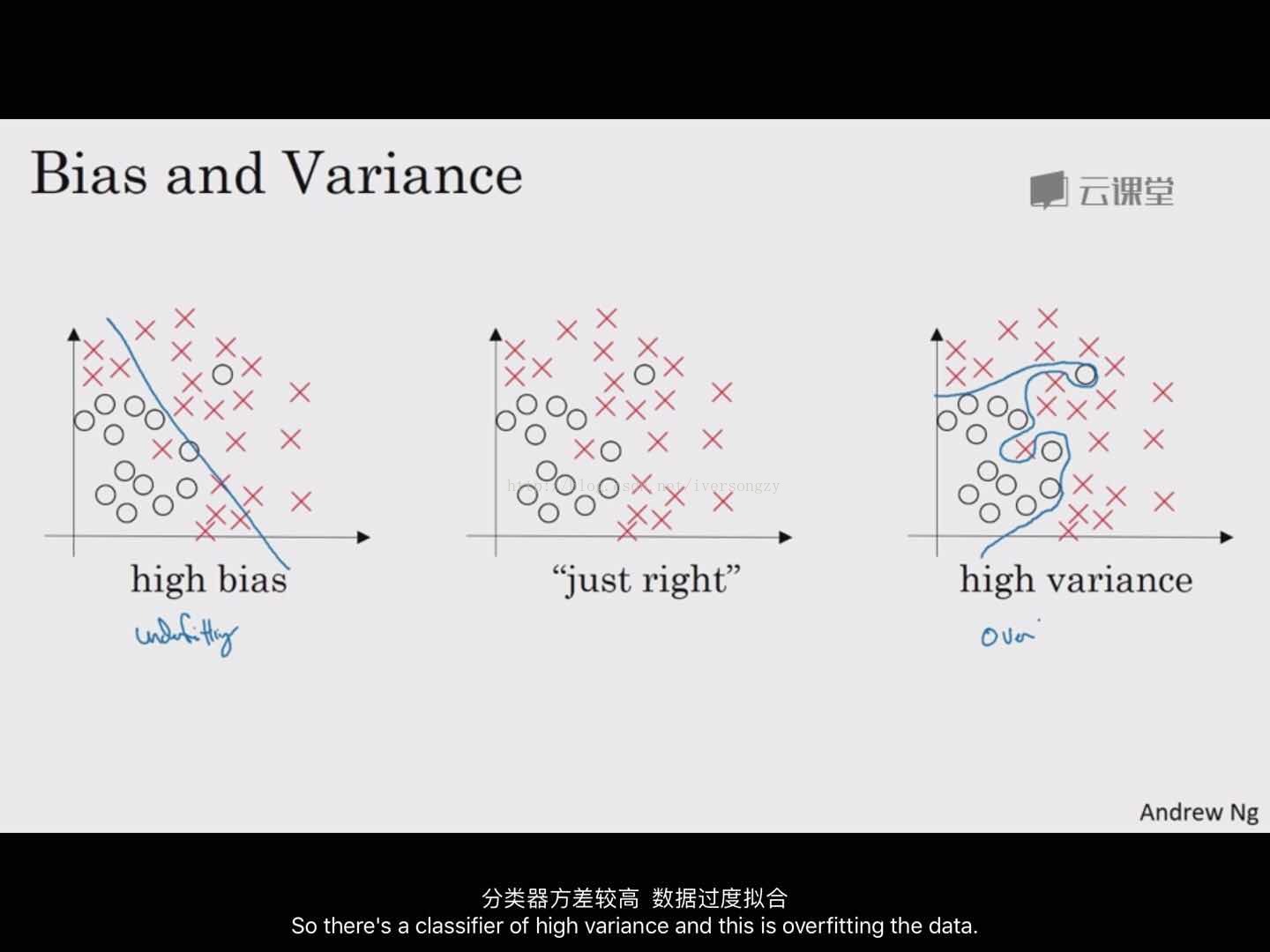
high bias(underfitting):在训练集上表现的不好
high variance(overfitting):在测试集表现的不好
如下图所示,可以通过training error and dev error 来判断拟合程度:

二、机器学习基础:
在机器学习中通常会考虑方差、偏差均衡问题,需要设计算法使减低任何一方的同时很少影响另一方,而在深度学习中我们不太需要考虑这一点。
通常解决办法: (training data performance)high bias-->1、增加网络的深度或增加隐含层节点数(主要);2、优化算法;3、考虑神经网络架构问题(不常需要考虑)
(dev data performance)high variance-->1、增大数据量(主要);2、正则化;3、考虑神经网络框架

四三、正则化:
1、Logistic Regression:
L1正则化、L2正则化:公式入下图所示:使用L1正则化会使权重稀疏化
其中λ被称作regularization parameter,它可以通过交叉验证寻得最优值。

Neural Network:
Frobenius norm (weight decay)不称作L2 Regularizaion

如果λ设置的很大,权重矩阵W会被设置为接近0的数,调整λ会使权重的影响发生变化(变小),不容易发生过拟合
so如果正则化参数变得很大,参数W会变小,Z也会相对变小,这使得激活函数逼近线性,整个神经网络会计算离线性函数近的值,所以不会过拟合

Dropout Regularization(随机失活):
遍历每一层——设置节点概率——消除一些节点——删除与节点有关的连接
keep_prob:表示保留某个隐藏单元的概率,消除一个隐藏单元的概率为1-keep_prob-->生成随机矩阵
inverted dropout(例:设层数为3):
因为z4 = W4·a3+b4 a3有1-keep_prob的元素归零,为了不影响z4的期望值,/keep_prob将会修正或弥补1-keep_prob概率的那部分
在预测测试阶段不使用dropout,因为测试时候我们不希望输出的结果是随机的

如果担心神经网络的某些层容易发生过拟合,可以把这些层的keep_prob值设置的比其他层的更低
dropout在计算机视觉中应用的比较多,dropout是个正则化方法有助于预防过拟合,在其他领域用的很少
关闭dropout确保J函数单调递减,然后在打开它,这样不会引入bug
其他正则化的方法:
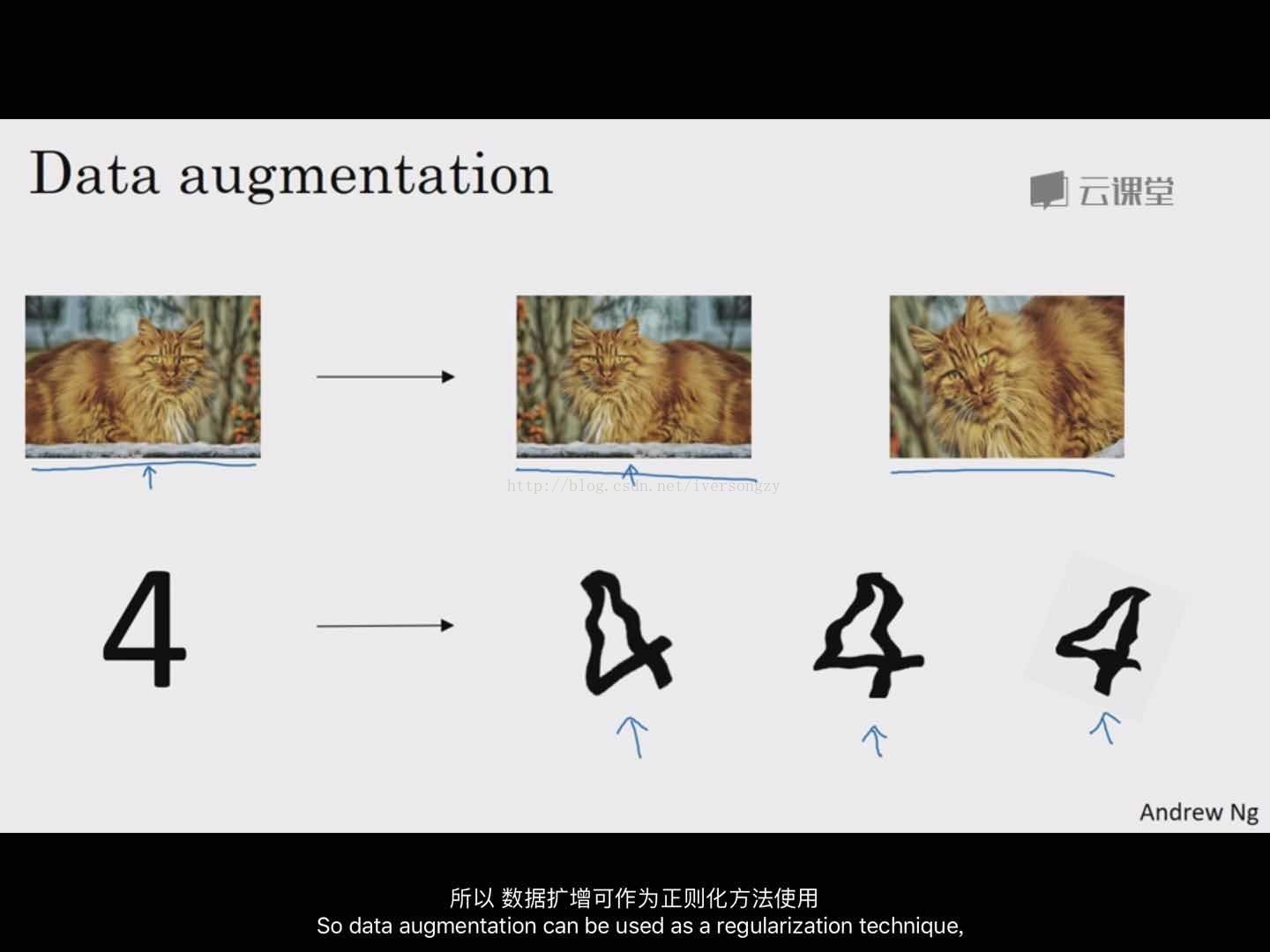
数据增广,data augmentation,或者early stopping
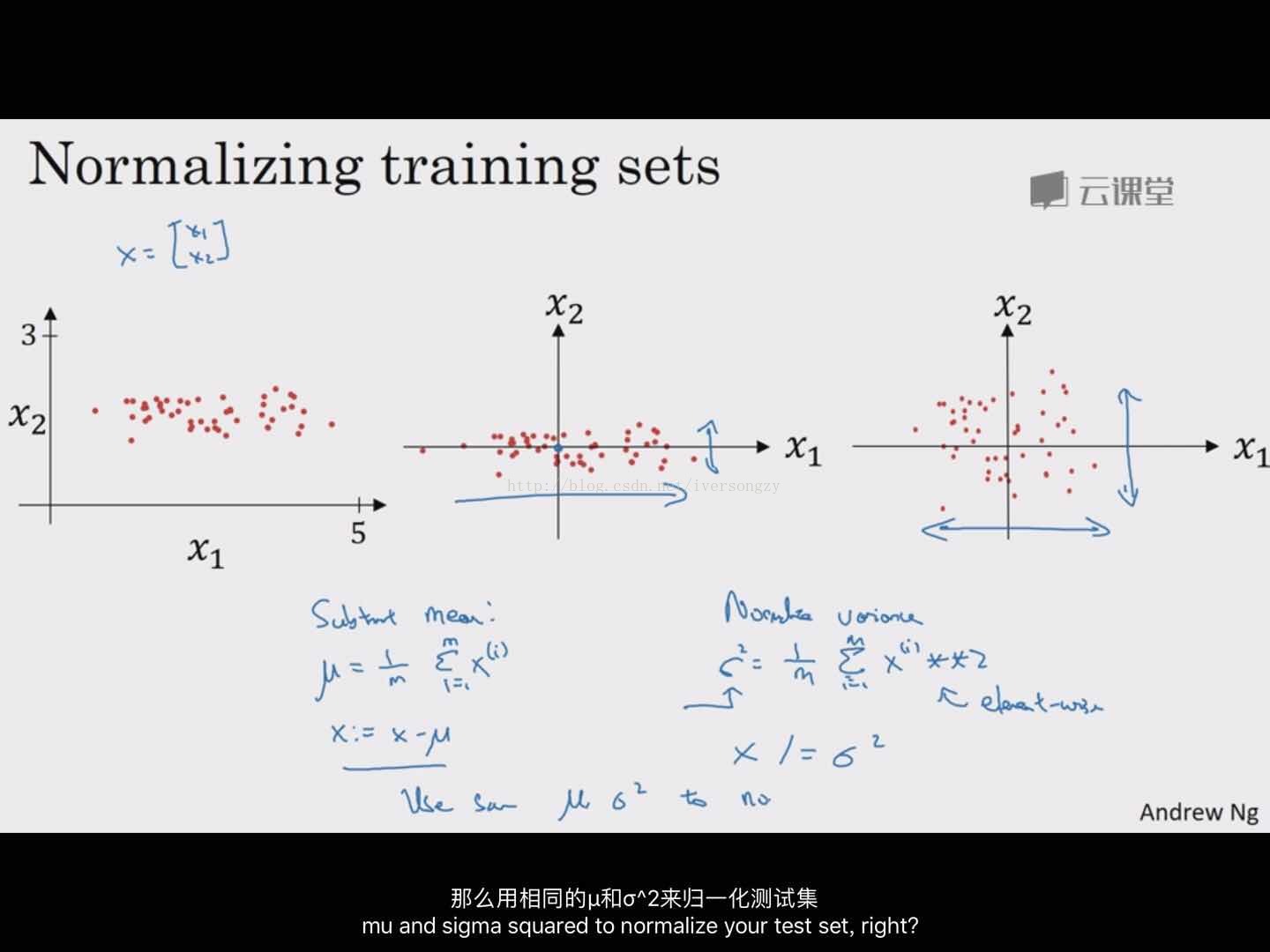
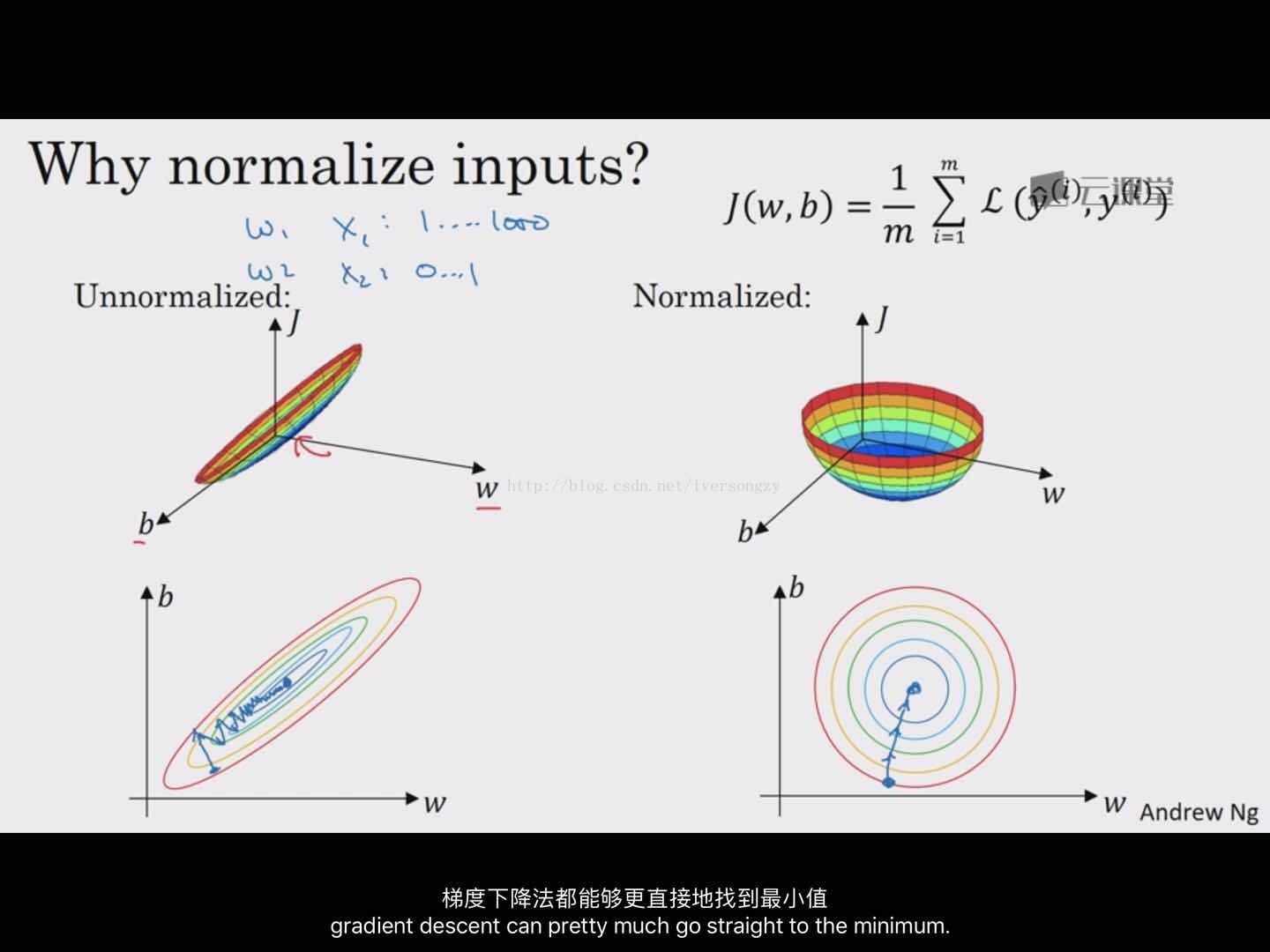
归一化输入(一个加速训练的方法):如果特征值处于相似范围,归一化不是很重要了就。
第一步:零归一化;第二步:归一化方差
如下图左边,必须使用很小的学习率多次迭代才能找到最小值,如果函数是一个更圆的球形轮廓,梯度下降法能更快找到最小值。
深度学习很少谈论偏差,方差权衡问题,一般都是分开讨论:
high bias(underfitting):在训练集上表现的不好
high variance(overfitting):在测试集表现的不好
如下图所示,可以通过training error and dev error 来判断拟合程度:
二、机器学习基础:
在机器学习中通常会考虑方差、偏差均衡问题,需要设计算法使减低任何一方的同时很少影响另一方,而在深度学习中我们不太需要考虑这一点。
通常解决办法: (training data performance)high bias-->1、增加网络的深度或增加隐含层节点数(主要);2、优化算法;3、考虑神经网络架构问题(不常需要考虑)
(dev data performance)high variance-->1、增大数据量(主要);2、正则化;3、考虑神经网络框架
四三、正则化:
1、Logistic Regression:
L1正则化、L2正则化:公式入下图所示:使用L1正则化会使权重稀疏化
其中λ被称作regularization parameter,它可以通过交叉验证寻得最优值。
Neural Network:
Frobenius norm (weight decay)不称作L2 Regularizaion
如果λ设置的很大,权重矩阵W会被设置为接近0的数,调整λ会使权重的影响发生变化(变小),不容易发生过拟合
so如果正则化参数变得很大,参数W会变小,Z也会相对变小,这使得激活函数逼近线性,整个神经网络会计算离线性函数近的值,所以不会过拟合
Dropout Regularization(随机失活):
遍历每一层——设置节点概率——消除一些节点——删除与节点有关的连接
keep_prob:表示保留某个隐藏单元的概率,消除一个隐藏单元的概率为1-keep_prob-->生成随机矩阵
inverted dropout(例:设层数为3):
d3 = np.randn.random(a3.shape[0], a3.shape[1] a3 = np.multiply(a3, d3)<keep_prob a3 = a3/keep_prob #确保a3期望值不变
因为z4 = W4·a3+b4 a3有1-keep_prob的元素归零,为了不影响z4的期望值,/keep_prob将会修正或弥补1-keep_prob概率的那部分
在预测测试阶段不使用dropout,因为测试时候我们不希望输出的结果是随机的
如果担心神经网络的某些层容易发生过拟合,可以把这些层的keep_prob值设置的比其他层的更低
dropout在计算机视觉中应用的比较多,dropout是个正则化方法有助于预防过拟合,在其他领域用的很少
关闭dropout确保J函数单调递减,然后在打开它,这样不会引入bug
其他正则化的方法:
数据增广,data augmentation,或者early stopping
归一化输入(一个加速训练的方法):如果特征值处于相似范围,归一化不是很重要了就。
第一步:零归一化;第二步:归一化方差
如下图左边,必须使用很小的学习率多次迭代才能找到最小值,如果函数是一个更圆的球形轮廓,梯度下降法能更快找到最小值。

相关文章推荐
- 提高深度学习性能的四种方式
- 第五章(1.6)深度学习——常用的八种神经网络性能调优方案
- 深度学习DL调参隐藏层节点数对网络性能的影响
- 提高深度学习的性能的几点小意见
- 深度学习DL调参隐藏层节点数对网络性能的影响
- 四大深度学习框架+四类GPU+七种神经网络:交叉性能评测
- 【深度学习】笔记7: CNN训练Cifar-10技巧 ---如何进行实验,如何进行构建自己的网络模型,提高精度
- 深度学习6:softmax线性分类器与神经网络分类的性能比较
- 重磅长文|提高深度学习性能的四种方式
- 提高深度学习和机器学习性能的方法
- 【神经网络与深度学习】【C/C++】比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能
- 提高深度学习性能的四种方式
- 深度学习卷积网络的资源
- 机器学习语料,深度学习语料,神经网络语料,nlp语料,机器视觉语料,持续更新
- 单层神经网络、多层感知机、深度学习的总结
- 深度学习——缩减+召回加速网络训练
- 从神经网络说起:深度学习初学者不可不知的25个术语和概念
- 深度学习神经网络纯C语言基础版【转】
- [深度学习]理解RNN, GRU, LSTM 网络
- 人工智能、机器学习、深度学习、神经网络