基于Spark Mllib,SparkSQL的电影推荐系统
2017-09-19 17:16
465 查看
本文测试的Spark版本是1.3.1
本文将在Spark集群上搭建一个简单的小型的电影推荐系统,以为之后的完整项目做铺垫和知识积累
整个系统的工作流程描述如下:
1.某电影网站拥有可观的电影资源和用户数,通过各个用户对各个电影的评分,汇总得到了海量的用户-电影-评分数据
2.我在一个电影网站上看了几部电影,并都为其做了评分操作(0-5分)
3.该电影网站的推荐系统根据我对那几部电影的评分,要预测出在该网站的电影资源库中,有哪些电影是适合我的,并推荐给我看
4.根据我的观影习惯和用户的一个个人信息,预测该网站用户库中,哪些人和我的兴趣爱好是差不多的,并推荐给我认识
使用到的数据集有4个:
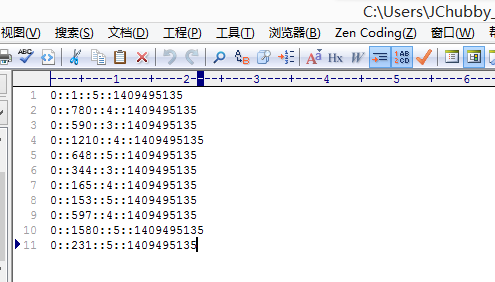
test.dat(我的评分数据),格式如下:
0-我的用户Id::电影Id::对该电影的评分::评分的时间戳
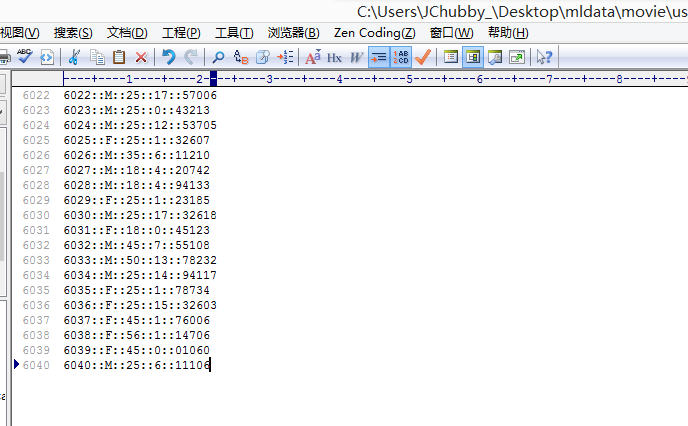
users.dat(用户数据),格式如下:
用户Id::性别::年龄::工作类型::ZIP-CODE
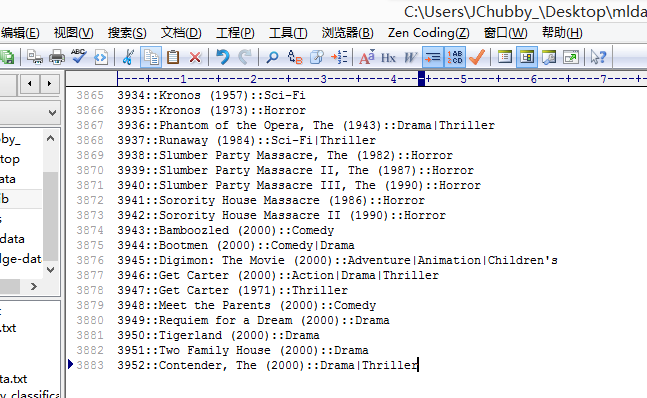
movies.dat(电影资源数据),格式如下:
电影Id::电影名::电影类型
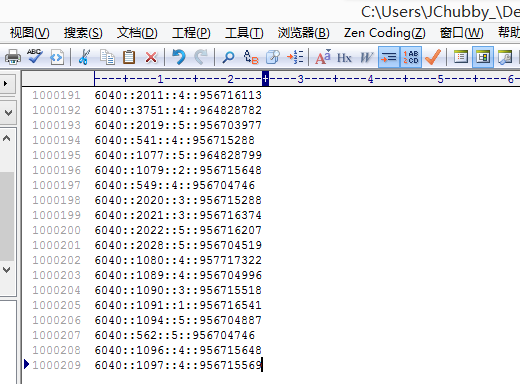
ratings.dat(用户-电影-评分数据),格式如下:
用户Id::电影Id::该用户对该电影的评分
(这个数据集中不包含我的评分数据,也就是用户Id为0的数据)
推荐系统数据集下载地址
大概拥有6000+个用户,3800+部电影,100多万的评分数据
具体的数据格式请看完整数据集中的README,其中有详细介绍
下载数据集之后注意检查一下有没有漏空的行,如果有请删除它,因为它会在读取数据的时候产生异常
在开始动手之前,最好先理清一下思路,之后再进行coding会有所向睥睨的一种感觉~
在本系统中,我们要使用的是ALS算法来做协同过滤
该算法建立模型需要一个训练数据集
那么,首先我们要明确的是
1.ALS算法要拿什么样的数据进行训练?
2.训练之后得到的模型要对什么样的数据进行预测?
3.预测之后的数据是什么样子的?
训练数据集很明显就是ratings.dat,因为这是用户-电影-评分数据
但是,单单ratings.dat是不够的,为什么?
因为在本系统中,功能很简单,只对一个用户(也就是我,用户Id为0)进行电影推荐,但是ratings.dat中并没有包含我的评分数据,没有我的评分数据,算法怎么能根据我的喜好来推荐电影呢?
所以作为训练的数据应该是ratings.dat+test.dat
ALS算法根据这些数据,来训练出一个模型
之后就可以使用这个模型对电影列表中,我没看过的电影进行预测打分,在从中筛选出10个评分最高的电影推荐
so,得到答案:
1.训练数据集是ratings.dat+test.dat
2.要进行预测的是movies.dat-我已经看过的那些电影
3.模型的预测结果就是,一个带评分的movies列表(该评分是针对我而言)
当然,上面描述的是系统的一个主线任务,还有一些其他的支线任务如:计算方差啊,打印输出啊,我们看代码说话~
关于在Mllib中协同过滤算法的基本使用,请先看:
Spark(十一) – Mllib API编程 线性回归、KMeans、协同过滤演示
废话不说,上代码:
为了方便理解数据的格式和意义,规定变量/常量名命名方式如下:
数据名_数据类型
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
系统在Spark集群上运行的结果如下图:
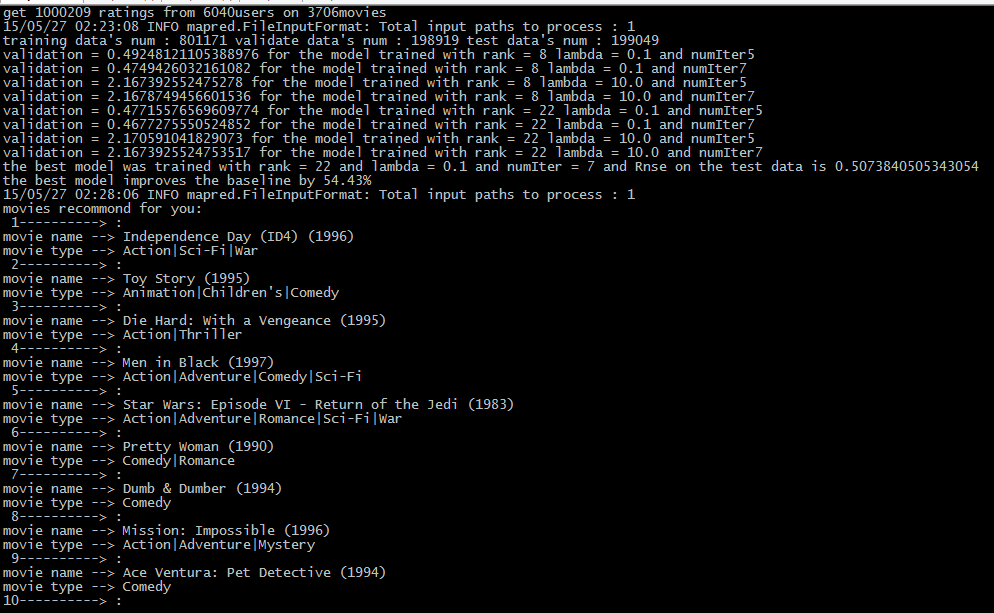
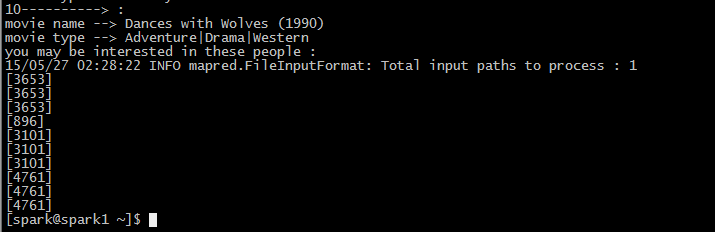
关于SparkSQL的一些基本操作请看:
Spark(九) – SparkSQL API编程
如果本文有中任何不足或者错误之处,万请指出~
如果你有任何疑问,欢迎联系交流~
本文将在Spark集群上搭建一个简单的小型的电影推荐系统,以为之后的完整项目做铺垫和知识积累
整个系统的工作流程描述如下:
1.某电影网站拥有可观的电影资源和用户数,通过各个用户对各个电影的评分,汇总得到了海量的用户-电影-评分数据
2.我在一个电影网站上看了几部电影,并都为其做了评分操作(0-5分)
3.该电影网站的推荐系统根据我对那几部电影的评分,要预测出在该网站的电影资源库中,有哪些电影是适合我的,并推荐给我看
4.根据我的观影习惯和用户的一个个人信息,预测该网站用户库中,哪些人和我的兴趣爱好是差不多的,并推荐给我认识
使用到的数据集有4个:
test.dat(我的评分数据),格式如下:
0-我的用户Id::电影Id::对该电影的评分::评分的时间戳
users.dat(用户数据),格式如下:
用户Id::性别::年龄::工作类型::ZIP-CODE
movies.dat(电影资源数据),格式如下:
电影Id::电影名::电影类型
ratings.dat(用户-电影-评分数据),格式如下:
用户Id::电影Id::该用户对该电影的评分
(这个数据集中不包含我的评分数据,也就是用户Id为0的数据)
推荐系统数据集下载地址
大概拥有6000+个用户,3800+部电影,100多万的评分数据
具体的数据格式请看完整数据集中的README,其中有详细介绍
下载数据集之后注意检查一下有没有漏空的行,如果有请删除它,因为它会在读取数据的时候产生异常
在开始动手之前,最好先理清一下思路,之后再进行coding会有所向睥睨的一种感觉~
在本系统中,我们要使用的是ALS算法来做协同过滤
该算法建立模型需要一个训练数据集
那么,首先我们要明确的是
1.ALS算法要拿什么样的数据进行训练?
2.训练之后得到的模型要对什么样的数据进行预测?
3.预测之后的数据是什么样子的?
训练数据集很明显就是ratings.dat,因为这是用户-电影-评分数据
但是,单单ratings.dat是不够的,为什么?
因为在本系统中,功能很简单,只对一个用户(也就是我,用户Id为0)进行电影推荐,但是ratings.dat中并没有包含我的评分数据,没有我的评分数据,算法怎么能根据我的喜好来推荐电影呢?
所以作为训练的数据应该是ratings.dat+test.dat
ALS算法根据这些数据,来训练出一个模型
之后就可以使用这个模型对电影列表中,我没看过的电影进行预测打分,在从中筛选出10个评分最高的电影推荐
so,得到答案:
1.训练数据集是ratings.dat+test.dat
2.要进行预测的是movies.dat-我已经看过的那些电影
3.模型的预测结果就是,一个带评分的movies列表(该评分是针对我而言)
当然,上面描述的是系统的一个主线任务,还有一些其他的支线任务如:计算方差啊,打印输出啊,我们看代码说话~
关于在Mllib中协同过滤算法的基本使用,请先看:
Spark(十一) – Mllib API编程 线性回归、KMeans、协同过滤演示
废话不说,上代码:
为了方便理解数据的格式和意义,规定变量/常量名命名方式如下:
数据名_数据类型
object MoviesRecommond {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage : <master> <hdfs dir path>")
System.exit(1)
}
//屏蔽日志,由于结果是打印在控制台上的,为了方便查看结果,将spark日志输出关掉
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//创建入口对象
val conf = new SparkConf().setMaster(args(0)).setAppName("Collaborative Filtering")
val sc = new SparkContext(conf)
//评分训练总数据集,元组格式
val ratingsList_Tuple = sc.textFile(args(1) + "/ratings.dat").map { lines =>
val fields = lines.split("::")
(fields(0).toInt, fields(1).toInt, fields(2).toDouble, fields(3).toLong % 10)//这里将timespan这列对10做取余操作,这样一来个评分数据的这一列都是一个0-9的数字,做什么用?接着看下面
}
//评分训练总数据集,模拟键值对形式,键是0-9中的一个数字,值是Rating类型
val ratingsTrain_KV = ratingsList_Tuple.map(x =>
(x._4, Rating(x._1, x._2, x._3)))
//打印出从ratings.dat中,我们从多少个用户和电影之中得到了多少条评分记录
println("get " + ratingsTrain_KV.count()
+ " ratings from " + ratingsTrain_KV.map(_._2.user).distinct().count()
+ "users on " + ratingsTrain_KV.map(_._2.product).distinct().count() + "movies")
//我的评分数据,RDD[Rating]格式
val myRatedData_Rating = sc.textFile(args(2)).map { lines =>
val fields = lines.split("::")
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}
//从训练总数据总分出80%作为训练集,20%作为验证数据集,20%作为测试数据集,前面的将timespan对10做取余操作的作用就是为了从总数据集中分出三部分
//设置分区数
val numPartitions = 3
//将键的数值小于8的作为训练数据
val traningData_Rating = ratingsTrain_KV.filter(_._1 < 8)
.values//注意,由于原本的数据集是伪键值对形式的,而当做训练数据只需要RDD[Rating]类型的数据,即values集合
.union(myRatedData_Rating)//使用union操作将我的评分数据加入训练集中,以做为训练的基准
.repartition(numPartitions)
.cache()
//格式和意义和上面的类似,由于是验证数据,并不需要我的评分数据,所以不用union
val validateData_Rating = ratingsTrain_KV.filter(x => x._1 >= 6 && x._1 < 8)
.values
.repartition(numPartitions)
.cache()
val testData_Rating = ratingsTrain_KV.filter(_._1 >= 8)
.values
.cache()
//打印出用于训练,验证和测试的数据集分别是多少条记录
println("training data's num : " + traningData_Rating.count()
+ " validate data's num : " + validateData_Rating.count()
+ " test data's num : " + testData_Rating.count())
//开始模型训练,根据方差选择最佳模型
val ranks = List(8, 22)
val lambdas = List(0.1, 10.0)
val iters = List(5, 7)//这里的迭代次数要根据各自集群机器的硬件来选择,由于我的机器不行最多只能迭代7次,再多就会内存溢出
var bestModel: MatrixFactorizationModel = null
var bestValidateRnse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestIter = -1
//一个三层嵌套循环,会产生8个ranks ,lambdas ,iters 的组合,每个组合都会产生一个模型,计算8个模型的方差,最小的那个记为最佳模型
for (rank <- ranks; lam <- lambdas; iter <- iters) {
val model = ALS.train(traningData_Rating, rank, iter, lam)
//rnse为计算方差的函数,定义在最下方
val validateRnse = rnse(model, validateData_Rating, validateData_Rating.count())
println("validation = " + validateRnse
+ " for the model trained with rank = " + rank
+ " lambda = " + lam
+ " and numIter" + iter)
if (validateRnse < bestValidateRnse) {
bestModel = model
bestValidateRnse = validateRnse
bestRank = rank
bestLambda = lam
bestIter = iter
}
}
//将最佳模型运用在测试数据集上
val testDataRnse = rnse(bestModel, testData_Rating, testData_Rating.count())
println("the best model was trained with rank = " + bestRank + " and lambda = " + bestLambda
+ " and numIter = " + bestIter + " and Rnse on the test data is " + testDataRnse)
//计算和原先基础的相比其提升了多少
val meanRating = traningData_Rating.union(validateData_Rating).map(_.rating).mean()
val baseLineRnse = math.sqrt(testData_Rating.map(x => (meanRating - x.rating) * (meanRating - x.rating)).mean())
val improvent = (baseLineRnse - testDataRnse) / baseLineRnse * 100
println("the best model improves the baseline by " + "%2.2f".format(improvent) + "%")
//电影列表总数据,元组格式
val movieList_Tuple = sc.textFile(args(1) + "/movies.dat").map { lines =>
val fields = lines.split("::")
(fields(0).toInt, fields(1), fields(2))
}
//电影名称总数据,Map类型,键为id,值为name
val movies_Map = movieList_Tuple.map(x =>
(x._1, x._2)).collect().toMap
//电影类型总数据,Map类型,键为id,值为type
val moviesType_Map = movieList_Tuple.map(x =>
(x._1, x._3)).collect().toMap
var i = 1
println("movies recommond for you:")
//得到我已经看过的电影的id
val myRatedMovieIds = myRatedData_Rating.map(_.product).collect().toSet
//从电影列表中将这些电影过滤掉,剩下的电影列表将被送到模型中预测每部电影我可能做出的评分
val recommondList = sc.parallelize(movies_Map.keys.filter(myRatedMovieIds.contains(_)).toSeq)
//将结果数据按评分从大小小排序,选出评分最高的10条记录输出
bestModel.predict(recommondList.map((0, _))).collect().sortBy(-_.rating).take(10).foreach { r =>
println("%2d".format(i) + "----------> : \nmovie name --> "
+ movies_Map(r.product) + " \nmovie type --> "
+ moviesType_Map(r.product))
i += 1
}
//计算可能感兴趣的人
println("you may be interested in these people : ")
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
//将电影,用户,评分数据转换成为DataFrame,进行SparkSQL操作
val movies = movieList_Tuple
.map(m => Movies(m._1.toInt, m._2, m._3))
.toDF()
val ratings = ratingsList_Tuple
.map(r => Ratings(r._1.toInt, r._2.toInt, r._3.toInt))
.toDF()
val users = sc.textFile(args(1) + "/users.dat").map { lines =>
val fields = lines.split("::")
Users(fields(0).toInt, fields(2).toInt, fields(3).toInt)
}.toDF()
ratings.filter('rating >= 5)//过滤出评分列表中评分为5的记录
.join(movies, ratings("movieId") === movies("id"))//和电影DataFrame进行join操作
.filter(movies("mType") === "Drama")//筛选出评分为5,且电影类型为Drama的记录(本来应该根据我的评分数据中电影的类型来进行筛选操作,由于数据格式的限制,这里草草的以一个Drama作为代表)
.join(users, ratings("userId") === users("id"))//对用户DataFrame进行join
.filter(users("age") === 18)//筛选出年龄=18(和我的信息一致)的记录
.filter(users("occupation") === 15)//筛选出工作类型=18(和我的信息一致)的记录
.select(users("id"))//只保存用户id,得到的结果为和我的个人信息差不多的,而且喜欢看的电影类型也和我差不多 的用户集合
.take(10)
.foreach(println)
}
//计算方差函数
def rnse(model: MatrixFactorizationModel, predictionData: RDD[Rating], n: Long): Double = {
//根据参数model,来对验证数据集进行预测
val prediction = model.predict(predictionData.map(x => (x.user, x.product)))
//将预测结果和验证数据集join之后计算评分的方差并返回
val predictionAndOldRatings = prediction.map(x => ((x.user, x.product), x.rating))
.join(predictionData.map(x => ((x.user, x.product), x.rating))).values
math.sqrt(predictionAndOldRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ - _) / n)
}
//样例类,用作SparkSQL隐式转换
case class Ratings(userId: Int, movieId: Int, rating: Int)
case class Movies(id: Int, name: String, mType: String)
case class Users(id: Int, age: Int, occupation: Int)
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
系统在Spark集群上运行的结果如下图:
关于SparkSQL的一些基本操作请看:
Spark(九) – SparkSQL API编程
如果本文有中任何不足或者错误之处,万请指出~
如果你有任何疑问,欢迎联系交流~

相关文章推荐
- 基于Spark Mllib,SparkSQL的电影推荐系统
- <转>基于Spark Mllib,SparkSQL的电影推荐系统
- 基于Spark Mllib,SparkSQL的电影推荐系统
- 基于Spark Mllib,SparkSQL的电影推荐系统
- 基于Spark Mllib,SparkSQL的电影推荐系统
- 基于Spark Mllib,SparkSQL的电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- 基于Spark MLlib平台和基于模型的协同过滤算法的电影推荐系统(二)代码实现
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统