读论文 CVPR_2017_Scene-Text-Detection Method Robust against Orientation and Discontiguous Components of
2017-09-15 19:26
381 查看
写在前面:本文只为了自己日后忘记时,温习巩固用,本人没有做出任何见解,纯属方便回顾阅读。
--------------------------------------------------------------------------------------------------------------------------------------
原文标题:Scene-Text-Detection Method Robust against Orientation and Discontiguous Components of Characters
原文简单翻译:
解决多方向不连续字符的稳定场景文字检测
引言
对自然场景图片进行场景文字检测是很重要的技术,因为场景文字包含了位置信息,譬如建筑和位置的名称,但是在实际应用中依然存在很多难题。在本文中,我们解决了场景文字检测中的2个问题。第一个是某种包含不连续字符的语言的不连续成分问题。第二个就是所有语言里的多方向问题。为了解决这2个问题,我们提出了一个基于连接元素的场景文字检测方法。我们提出的方法涉及到我们新颖的相邻字符搜索方法,对不连续字符问题使用综合描绘子,并且我们新颖的区域描绘子被称为旋转字符的旋转边缘盒描绘子(RBBs)。我们把我们提出的场景文字检测方法在包含不连续的旋转字符数据集MSRA-TD500上进行评估。
1. 介绍
对于许多基于内容的应用,图片中的文字包含有价值的语义信息。具有代表性的例子就是位置信息,并且在城镇中拍摄的图片通常包含辨识位置的线索。交通标志位于城市的很多地方,并且他们包括街道和地点的名称。建筑和商场会放置品牌商标在入口。通过识别图片中的文本,我们能够使用文本信息来识别位置。这些定位信息能够用来城市导航和自动驾驶。另外,由于信息只能从图片数据中获取,因此这个方法能在室内或者地下任何GPS不能使用的地方。因此,文本识别方法有利于图像位置识别。
文本识别方法得到了广泛的研究,研究人员提出了有效的识别方法。尤其是,一种光学字符识别方法来识别扫描文档上打印的文字是最成功的。然而,对于计算机来说,检测和识别场景文字仍然是难题,因为有很多干扰因素,例如外观变化(字符大小,字体变化),语言,方向,失真,噪声,遮挡和复杂背景。在本文中,我们解决了场景文字检测存在的干扰造成的2个问题。其一是不连续的字符问题,另一个是多方向问题。
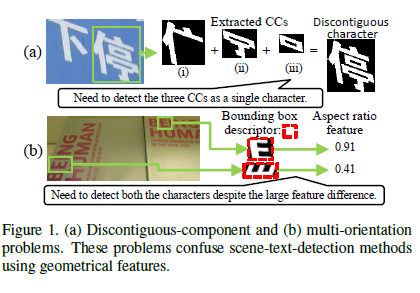
不连续组分问题是由不连续字符造成的。一个不连续的字符包含多个连接的组分,如图1所示。几何特征对于文本检测是重要的线索,从一个不连续字符的单组分中计算的几何特征与来自一个连续字符的特征极大的不同,并且这种差异很容易导致漏检。虽然在英语中只有i和j是不连续的字符,但是中文和日文中有大量的不连续字符。多方向问题是由场景文字的多种方向造成的。一般字符的几何特征与字符的方向无关,如图1所示。因此,解决检测如中文或日文的旋转场景文字这俩大问题是非常必要的。注意,文本以为着一个单词或者包含超过一个字符的句子。
虽然有很多场景文字检测方法已经提出了,但是大多数目标是水平英文文本。几种基于文本对齐方式和大小的均匀性的包括不连续字
db74
符的文本检测方法。然而,如果他们曾经用来检测包括不连续字符的旋转文本,那么大量的错误检测就会出现。现存的基于几何特征的方法受到旋转的影响,很难正确的消去失败的检测。然而,其他的方法也使用文本对齐一致性以至于当文本包含非连续字符时,方向估计很难确定,因为无法确定小区域是不连续的组分,字符的一部分,或者就是噪声。而且,在我们的调查中没有发现同时解决这两个问题的方法。
在本文中,我们提出了一个鲁棒的基于CC的场景文字检测方法,克服了非连续字符。我们的方法使用了我们新颖的想法,具有综合描绘相邻字符搜索方法去解决不连续组分问题。综合描绘子是一种能利用低计算成本的简单操作结合的特殊描绘子。我们的方法计算一个非连续的来自于采用综合描述子构成字符的独立CCs的特征符。为了解决多方向问题,我们的方法使用我们新颖的被称为RBBS的区域描绘子,这是综合描述子。RBBs通过乘以一个固定的角度表示旋转区域周围包围盒坐标,用于精确的计算区域几何特征。通过使用具有我们的RBBs相邻字符搜索方法和其他综合描绘子,我们的方法能检测包含不连续字符的旋转场景文字。
论文其余部分内容。在第二章,我们对基于CC方法的相关工作做了一个回顾,并且在第三章描述我们所提出的基于场景文字检测的方法。在第四章,我们解释实验结果且提出讨论。第五章结论。
2. 相关工作
现存的场景文字检测方法大致分为两种类型:基于滑窗和基于CC。基于滑窗的方法使用一个滑窗在一张图片中去搜索字符或者文本区域,然后使用机器学习技术来识别文本。虽然这些方法一般能检测不连续字符,但是它很难处理字符大小和方向有大变化的情况。因为滑窗只能检测与训练数据中一样大小和方向的字符。基于CC的方法抓取CCs作为字符候选且依据相似特征组成一组字符候选。这些方法能处理这个变化,但是现存的基于CC的方法没有考虑到不连续字符的问题。我们注重基于CC的方法去处理多类字符且描述相关工作。基于CC方法中的基于MSER的方法尤为成功。
大量基于MSER方法的场景文字检测性能都很好。因为他们能获取一种CC极值区域,这能稳定的对抗大小变化,低分辨率和混合背景。诺依曼和马塔斯使用多层字符分类来有效的减少失败字符候选的数量。Tin等人使用CCs的纵横比和稳定性来减少CCs的数量直到重叠区域被消除。然而,他们的方法没有考虑非连续字符的情况。不像英文,类似中文或日文都包含大量的非连续字符。在一些情况下,由于CC获取算法的限制,连续的字符会不可预期的被分割成多个CCs。诺依曼和马塔斯的方法能使用一种文本基线估计来检测这样的字符。然而,当文本是旋转的,文本基线就很难估计。
目前,基于深度神经网络的方法,是基于滑窗方法和基于CC方法的混合,已经成功应用于多类计算机视觉任务。虽然基于DNN的方法需要大量的训练数据和很高的计算性能,但是他们能从大量图片中高进度的检测字符。Bissacco等人利用直方图梯度特征优化深度学习方法,这个系统能在不受控制的情况下检测字符。He等人提出显著文本卷积神经网络,能学习一个文本区域的maks,特征标签和二值(文本/非文本)信息在统一模式。这些方法在英文中表现很好,但是仍然受非连续组分的影响。其中一个原因是包含非连续子的语言有很多种类型的字符。需要大量的训练数据和计算资源来正确的分类字符。GPU能解决计算资源的问题,但是我们假设使用没有GPU的设备,譬如智能手机。另一个原因是一些包含非连续字符的CCs的形状通常会跟那些连续字符的一样(譬如:在英文中,图1CC(iii)和O或者0是相似的)及时使用DNN,分辨他们也是很难的。
多方向问题还是需要被解决。大多数现存的方法基于文本方向是水平或近似水平的假设使用几何特征来检测文本候选。Yin等人提出了一个自适应聚类的方法,使用字符候选的几何和方向特征对来检测旋转文本。Zhang等人的方法通过几何特征和文本块特征来检测旋转文本,它是通过文本块网络检测。然而,现存方法的几何特征不够精确因为他们使用的是非旋转包围盒或者外接圆。当一个长形字符定向时,非U型暗转边界框会发生很大变化,如图1所示。外接圆的半径作为字符对的几何距离,但是外接圆受字符形状的影响。例如,在检测文本“Alice”时,现存的方法在假设字符属于同一个文本,距离值是相似的情况下,评估“Al,”
“li,” “ic”,和“ce”的距离值。然而“AI”的外接圆比“li”的要大,所以“Alice”检测失败。
3. 提出场景文字检测方法
图2大概描述了一下我们的方法。在所有过程开始之前,CCs从输入图片中获取,并分类为字符非字符。然后使用我们的RBBs相邻字符搜索方法和其他综合描述子来检测文本行候选。最后,所有的重叠文本行候选基于文本概率糅合成一个候选。因为我们方法的核心思想是综合描绘子和RBB,有助于相邻字符搜索方法,我们先描绘他,然后各个阶段的细节。注意,描绘子和特征在本文中是清楚划分的。描绘子是区域特性的存储格式。特征是在分类中用到的一个值或是一个值的集合。例如,包围盒就是一个描绘子,计算的边界框纵横比是一个特征。
3.1区域描绘子和特征
3.1.1综合描绘
我们提出了综合描述符来高效计算复合区域描述符,灵感来源于增量计算描述符。复合区域是指包含多个CCs的区域,其中一个非连续字符的区域总是复合区域。通过使用综合描述子,包含CCs的复合描述子能容易被计算根据只包含CCs描述子。设ri和rj是包含一个或多个CCs的区域,rc是ri和rj的复合区域,且φ(r)是r的描述子计算函数。当描述子是综合描述子时。存在+满足φ(rc)=φ(ri)+φ(rj),其中+表示ri和rj描述子的结合操作。提出的场景文字检测方法使用综合描述子计算复合区域描述子来减少计算开销。
接下来结合了我们方法的综合描述子用作复合区域:RBB和水平连续描述子和其他类型的描述子转换成综合描述子。没有特别提到描述符+是一个加法。
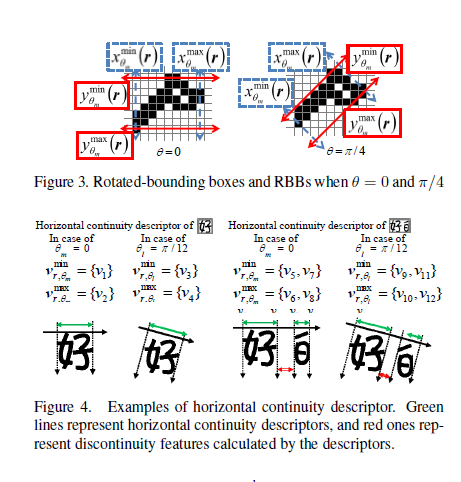
RBB(ymin(r),ymax(r),xmin(r),xmax(r))RBB表示旋转了任意角度θ的边界盒坐标如图3所示。RBB用来精确的计算旋转了θ的区域几何特征。每一个值如下定义:
Ymin(r)= ymax(r)= ……
其中xr和yr是区域r中像素r的坐标,h是输入图像的高度,且θ从大量计算角度中获得,Nori是预定义的固定值。Θ=π/2 + m/Nori 我们凭经验设置Nori=6.每一个RBB的+值分别是min,max,min和max。
水平连续性 (vmin vmax) 2个向量表示这个部分,其中区域r在角度θ是连续的如图4。初始向量vmin和vmax是{xmin(r)}和{xmax{r}}。+显示在算法1中。
面积 nara(r) 像素的个数
所有的颜色 (sc0(r) sc1(r) sc2(r)) HIS颜色空间中所有的像素值
笔画支持像素数SSPs nssp(r) SSP用于计算笔画的宽度。
全部笔画宽度 sswd(r) SSP全部的笔画值
周长 nperi(r)边界的长度
总平滑值 ssmt(r) 相邻边界像素梯度方向差的总值,平滑特征细节在早前的研究中。
对于RBB,在旋转θ角度的坐标系中,等式1和2表示垂直位置的最小值与最大值,且等式3和等式4表示水平位置的最小值和最大值。如图3所示。因此,在旋转θ角度坐标系中,θ角度的RBB能够精确精算r的大小,方向和位置。随着Nori的增加,更多不同角度的几何特征能计算得到,但是所有CCs的整个RBB计算开销增加。然而RBB逐步可计算的,这是一类特殊的描述符,可以通过MSER算法快速计算出所有CCs。一副N个像素的图片所有CCs描述子计算复杂度是O(N),在我们实验中,整个RBB计算时间在Nori=6时只是0.07秒比Nori=1时耗时长。
3.1.2综合描述子特征
旋转θ度的坐标系中不同几何特征能从θ度RBB中得到。单个区域对的基本特征如下所示。
r的一些大小特征能从区域r的RBB中容易计算出。旋转高度h(r)和旋转宽度w(r)这样计算h(r)=,…..w(r)=……c=sqrt()….其中c是系数防止出现0/0且当坐标系没有旋转时(θ=0)是1。每一个坐标系的长度有不同的比例,但是旋转的纵横比不需要标准化就能计算,因为同一坐标系的长度能直接比较。Aspect(r)=…….
RBB的区域对ri和rj能精确计算旋转区域对特征:高度差异hdiff,宽度差异wdiff,水平最小距离xdis,垂直重叠yovl。一般,每一个字符大小和每一个字符对的间隔是相似的;因此这些特征对旋转文本检测是有用的。ri和rj的这些特征定义为hdiff=……wdiff=…..xdis=….yovl=……
我们现在讨论高等特征从下列综合描绘子中得到。这些特征在第3.2.2章提到的文本行生成阶段去计算字符对距离。当这些特征值很小时,与特征相关的区域是字符的概率很高。不连续是我们在论文中提到的一个特征。其他特征与传统场景文字特征相似,但是一些特征用RBB进行扩展后对于多方向更加鲁棒。
单字符的不连续ddcn(r)=……
其中v[q]是向量v的第q+1个元素,ncnt是|vmin|,不连续表示包含同样复合区域的CCs之间的距离,如图4(b)。一般来说,正确字符的不连续性是很小或者是0.我们的方法通过不连续阻止了非关CCs这个意想不到的组合。
对的颜色差异dclr=……
其中 dc0=…..dc1=….. dc2=…..
对的笔画宽度差异 dswd=…..其中swdm(r)=sswd(r)/nssp(r)
对的垂直重叠 dovl=…..
对的高度和宽度差异dh=……dw=…..
顶部,底部和三条平行线
Dtop=…. Dbtm=…. Dboth=…..
其中,xctr=….Ydiff_t=….. ydiff_b=…..
三区间相似性研究dinter=….
间隔相似性表示最近的不包括相同文本的CC的几何距离。我们的方法通过使用间隔相似性促进相近CCs的复合。
注意RBB模型只就地旋转不发生透视失真。例如,等式18和19计算的属于统一文本的字符透视失真值往往很大,导致字符被确定属于不同文本。在公式20,21,22中显示的对齐特性对于检测此类文本非常重要。因为属于同一文本的字符有规律的排列且不管出不出现透视失真特征值都很低。
3.3文本检测流
3.2.1字符候选检测
我们的模型,使用MSER算法提取CCs,使用顺序分类器CCs被分类为字符候选或者非字符候选。这个分类被分为三个部分来更好的计算效率。第一和第二个阶段使用adaboost且第三个阶段使用DNN。根据前一个分类为字符的CCs进入下一个阶段。在第一个阶段和第二个阶段使用的特征几乎和[15]中一样。
在第一个阶段,分类器使用低计算花销特征且清除一定是非字符的CCs。不同于【15】的是小旋转角度代替一般角度。小旋转角度被定义为aspectmin(r)=…….在这里,aspectmin(r)对r旋转是鲁棒的且提高了旋转区域的分类精确度。
在第二阶段,我们的方法除了[15]中描述的特征,还使用了平滑性。平滑度由ssmt/nperi计算得到。第二个分类器输出类条件概率,且我们的方法减少了使用这个概率检测CCs时的冗余。冗余减少算法和[27]里面的线性减少算法相似,但是不同在于使用的是类条件概率,而不是正则变分
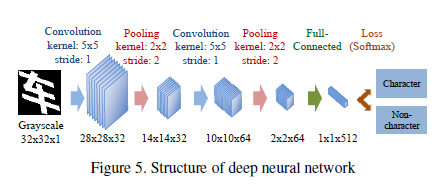
在第三阶段,我们的方法通过DNN强大的辨别能力检测有高概率的字符CCs。图5显示了我们方法的DNN结构。注意所有的图片都使用了最小旋转边界盒进行旋转归一化。在这个阶段后,每一个CC都有一个字符概率在[0,1]之间。
3.2.2文本行生成
在生成文本行阶段,很多旋转的文本行候选基于通过深度神经网络标为字符的CCs被检测.这样被标为字符的CC被称为基本字符。我们的方法使用搜索算法递归的搜索基本字符的邻居来组成文本行候选。搜索方法是基于一个字符对距离和一些启发式的规则。字符对距离表示字符之间的相似性,且当字符属于同一文本时,字符之间距离很小。
我们现在为了计算2个字符的相似性,定义1对字符距离。在某一个旋转θ坐标系中,字符区域ri到字符区域rj的距离的d(ri,rj)定义为wTxrirjθ,其中w是一个权值向量参数。然后,xrirjθ是一个10特征向量,在3.1.2由公式23和14计算得到。我们确定参数w通过使用距离测量学习(DML)技术,这是一个半监督聚类技术且学习一个距离度量满足给定的标签。Yin等人使用DML技术自动的确定权重和阈值从非字符中分离字符。我们也使用这个技术确定w,但是只有阈值是认为确定的。
我们的研究方法使用一对距离来检测ri的邻居字符。这个过程是基于包括ri在内的的四个区域进行的,其他距ri最近的字符预期被称为ri-1和两个未确定区域ri+1,ri+2。ri+1表示。ri+1表示ri一个相邻字符候选。ri-1和ri+2用来确定ri+1是否应该被包含在文本行候选中。在计算xriri+1θ时,等式14的输入时ri+1,等式20,21,22的输入是(ri-1,ri,ri+1),等式23的输入是(ri,ri+1,ri+2),其余等式输入为(ri,ri+1)。图6展示了4个区域和邻居字符搜索流的例子。我们的搜索方法搜索ri的邻居字符,通过选择和评估多个邻居字符候选作为ri+1.在选择ri+1和ri+2时,我们的搜索方法构建了ri封闭CC列表,如图6(a)所示。Ri的封闭CC列表是满足下列标间的rcc的集合:…………
这个封闭CC列表用来限制邻居字符搜索范围。每一个阈值thclr,thswd,thhor和thver定义为一个值,当所有正确训练样本被检测到时。接下来我们的搜索方法从基于启发式规则的封闭CC列表中选择一个初始ri+1。初始化的ri+1是最低xdis的CC,满足条件yovl>0和dh>0.5。另一方面,ri+2是在CC列表中满足yovl>0的最接近水平的CC。结果,我们的搜索方法计算xriri+1θ确定4个区域。
我们的方法从封闭CC列表中寻找更低对距离的组合。初始ri+1变成初始邻居候选rcand,且计算d(ri,rcand)。然后,创建临时复合区域rcand和CC列表里的其他CCs,计算成对距离。接下来,具有到ri最短距离的临时复合区域选作rlowest,且当d(ri,rcand)>d(ri,rlowest)时,rlowest代替rcand,且最后的rcand被选为ri的检测邻居字符,rnbr。最后,当d(ri,rnbr)<thdml时,这个方法将添加检测字符到文本行中,且再次执行邻居字符搜索。ri和ri-1在下一步中由rnbr和ri替代。
在这一阶段,计算候选文本行的概率为下一步文本行消去阶段做准备。t是角度为θ的候选文本行且ptxt(t)是t的概率。ptxt(t)初始值为0,当rnbr加入到t中,thdml – d(ri,rnbr) 添加到ptxt中。Ptxt(t)越高表示包含t的候选字符的特征越相似。
3.2.3文本行消去
文本行构建之后,还存在很多候选文本行且大量重叠,如图2(c)所示。我们的方法去掉重叠候选文本通过一个简单的消去算法。首先,我们的方法使用重叠t的候选tovl的概率ptxt(tovl)更新ptxt(t)。当θ和θ相同时,ptxt(tovl)添加到ptxt(t)里。另一方面,当θ和θ不相同时,-ptxt(tovl)添加到ptxt(t)里。接下来,当θ与θ不同,且ptxt(t)<ptxt(tovl)时,候选t删除。由以往经验可得,正确角度的候选文本行数量大于不正确角度候选。因此,虽然这个方法很简单,但是很有效。最后,对还存在的候选文本行使用传统特征Adaboost分类。
4. 实验
4.1参数设置
4.2MSRA-TD500性能评估
5. 结论
我们提出了一个基于MSER的场景文字检测方法,对旋转不连续字符很鲁棒。RBB精确的计算旋转几何特征且我们的邻居字符搜索方法利用综合描绘子检测不连续字符。我们的方法在MSRA-TD500的精度和F-测量上都取得了最好的分数。对于中文文本,召回率和现存的最好得分是一样的。因此,我们总结了我们的方法在检测包含了不连续字符的旋转场景文字中精度和F-度量实现了最好的性能。在未来的工作中,我们将研究一个更加合适的参数学习方法,且对密集文本检测时间进行改进。
1.现存的问题
2.方法大致过程

3.RBBs旋转边界盒 水平连续描绘子例子
4.算法1

5.DNN网络结构
6.邻近字符搜索流

7.实验结果图

--------------------------------------------------------------------------------------------------------------------------------------
原文标题:Scene-Text-Detection Method Robust against Orientation and Discontiguous Components of Characters
原文简单翻译:
解决多方向不连续字符的稳定场景文字检测
引言
对自然场景图片进行场景文字检测是很重要的技术,因为场景文字包含了位置信息,譬如建筑和位置的名称,但是在实际应用中依然存在很多难题。在本文中,我们解决了场景文字检测中的2个问题。第一个是某种包含不连续字符的语言的不连续成分问题。第二个就是所有语言里的多方向问题。为了解决这2个问题,我们提出了一个基于连接元素的场景文字检测方法。我们提出的方法涉及到我们新颖的相邻字符搜索方法,对不连续字符问题使用综合描绘子,并且我们新颖的区域描绘子被称为旋转字符的旋转边缘盒描绘子(RBBs)。我们把我们提出的场景文字检测方法在包含不连续的旋转字符数据集MSRA-TD500上进行评估。
1. 介绍
对于许多基于内容的应用,图片中的文字包含有价值的语义信息。具有代表性的例子就是位置信息,并且在城镇中拍摄的图片通常包含辨识位置的线索。交通标志位于城市的很多地方,并且他们包括街道和地点的名称。建筑和商场会放置品牌商标在入口。通过识别图片中的文本,我们能够使用文本信息来识别位置。这些定位信息能够用来城市导航和自动驾驶。另外,由于信息只能从图片数据中获取,因此这个方法能在室内或者地下任何GPS不能使用的地方。因此,文本识别方法有利于图像位置识别。
文本识别方法得到了广泛的研究,研究人员提出了有效的识别方法。尤其是,一种光学字符识别方法来识别扫描文档上打印的文字是最成功的。然而,对于计算机来说,检测和识别场景文字仍然是难题,因为有很多干扰因素,例如外观变化(字符大小,字体变化),语言,方向,失真,噪声,遮挡和复杂背景。在本文中,我们解决了场景文字检测存在的干扰造成的2个问题。其一是不连续的字符问题,另一个是多方向问题。
不连续组分问题是由不连续字符造成的。一个不连续的字符包含多个连接的组分,如图1所示。几何特征对于文本检测是重要的线索,从一个不连续字符的单组分中计算的几何特征与来自一个连续字符的特征极大的不同,并且这种差异很容易导致漏检。虽然在英语中只有i和j是不连续的字符,但是中文和日文中有大量的不连续字符。多方向问题是由场景文字的多种方向造成的。一般字符的几何特征与字符的方向无关,如图1所示。因此,解决检测如中文或日文的旋转场景文字这俩大问题是非常必要的。注意,文本以为着一个单词或者包含超过一个字符的句子。
虽然有很多场景文字检测方法已经提出了,但是大多数目标是水平英文文本。几种基于文本对齐方式和大小的均匀性的包括不连续字
db74
符的文本检测方法。然而,如果他们曾经用来检测包括不连续字符的旋转文本,那么大量的错误检测就会出现。现存的基于几何特征的方法受到旋转的影响,很难正确的消去失败的检测。然而,其他的方法也使用文本对齐一致性以至于当文本包含非连续字符时,方向估计很难确定,因为无法确定小区域是不连续的组分,字符的一部分,或者就是噪声。而且,在我们的调查中没有发现同时解决这两个问题的方法。
在本文中,我们提出了一个鲁棒的基于CC的场景文字检测方法,克服了非连续字符。我们的方法使用了我们新颖的想法,具有综合描绘相邻字符搜索方法去解决不连续组分问题。综合描绘子是一种能利用低计算成本的简单操作结合的特殊描绘子。我们的方法计算一个非连续的来自于采用综合描述子构成字符的独立CCs的特征符。为了解决多方向问题,我们的方法使用我们新颖的被称为RBBS的区域描绘子,这是综合描述子。RBBs通过乘以一个固定的角度表示旋转区域周围包围盒坐标,用于精确的计算区域几何特征。通过使用具有我们的RBBs相邻字符搜索方法和其他综合描绘子,我们的方法能检测包含不连续字符的旋转场景文字。
论文其余部分内容。在第二章,我们对基于CC方法的相关工作做了一个回顾,并且在第三章描述我们所提出的基于场景文字检测的方法。在第四章,我们解释实验结果且提出讨论。第五章结论。
2. 相关工作
现存的场景文字检测方法大致分为两种类型:基于滑窗和基于CC。基于滑窗的方法使用一个滑窗在一张图片中去搜索字符或者文本区域,然后使用机器学习技术来识别文本。虽然这些方法一般能检测不连续字符,但是它很难处理字符大小和方向有大变化的情况。因为滑窗只能检测与训练数据中一样大小和方向的字符。基于CC的方法抓取CCs作为字符候选且依据相似特征组成一组字符候选。这些方法能处理这个变化,但是现存的基于CC的方法没有考虑到不连续字符的问题。我们注重基于CC的方法去处理多类字符且描述相关工作。基于CC方法中的基于MSER的方法尤为成功。
大量基于MSER方法的场景文字检测性能都很好。因为他们能获取一种CC极值区域,这能稳定的对抗大小变化,低分辨率和混合背景。诺依曼和马塔斯使用多层字符分类来有效的减少失败字符候选的数量。Tin等人使用CCs的纵横比和稳定性来减少CCs的数量直到重叠区域被消除。然而,他们的方法没有考虑非连续字符的情况。不像英文,类似中文或日文都包含大量的非连续字符。在一些情况下,由于CC获取算法的限制,连续的字符会不可预期的被分割成多个CCs。诺依曼和马塔斯的方法能使用一种文本基线估计来检测这样的字符。然而,当文本是旋转的,文本基线就很难估计。
目前,基于深度神经网络的方法,是基于滑窗方法和基于CC方法的混合,已经成功应用于多类计算机视觉任务。虽然基于DNN的方法需要大量的训练数据和很高的计算性能,但是他们能从大量图片中高进度的检测字符。Bissacco等人利用直方图梯度特征优化深度学习方法,这个系统能在不受控制的情况下检测字符。He等人提出显著文本卷积神经网络,能学习一个文本区域的maks,特征标签和二值(文本/非文本)信息在统一模式。这些方法在英文中表现很好,但是仍然受非连续组分的影响。其中一个原因是包含非连续子的语言有很多种类型的字符。需要大量的训练数据和计算资源来正确的分类字符。GPU能解决计算资源的问题,但是我们假设使用没有GPU的设备,譬如智能手机。另一个原因是一些包含非连续字符的CCs的形状通常会跟那些连续字符的一样(譬如:在英文中,图1CC(iii)和O或者0是相似的)及时使用DNN,分辨他们也是很难的。
多方向问题还是需要被解决。大多数现存的方法基于文本方向是水平或近似水平的假设使用几何特征来检测文本候选。Yin等人提出了一个自适应聚类的方法,使用字符候选的几何和方向特征对来检测旋转文本。Zhang等人的方法通过几何特征和文本块特征来检测旋转文本,它是通过文本块网络检测。然而,现存方法的几何特征不够精确因为他们使用的是非旋转包围盒或者外接圆。当一个长形字符定向时,非U型暗转边界框会发生很大变化,如图1所示。外接圆的半径作为字符对的几何距离,但是外接圆受字符形状的影响。例如,在检测文本“Alice”时,现存的方法在假设字符属于同一个文本,距离值是相似的情况下,评估“Al,”
“li,” “ic”,和“ce”的距离值。然而“AI”的外接圆比“li”的要大,所以“Alice”检测失败。
3. 提出场景文字检测方法
图2大概描述了一下我们的方法。在所有过程开始之前,CCs从输入图片中获取,并分类为字符非字符。然后使用我们的RBBs相邻字符搜索方法和其他综合描述子来检测文本行候选。最后,所有的重叠文本行候选基于文本概率糅合成一个候选。因为我们方法的核心思想是综合描绘子和RBB,有助于相邻字符搜索方法,我们先描绘他,然后各个阶段的细节。注意,描绘子和特征在本文中是清楚划分的。描绘子是区域特性的存储格式。特征是在分类中用到的一个值或是一个值的集合。例如,包围盒就是一个描绘子,计算的边界框纵横比是一个特征。
3.1区域描绘子和特征
3.1.1综合描绘
我们提出了综合描述符来高效计算复合区域描述符,灵感来源于增量计算描述符。复合区域是指包含多个CCs的区域,其中一个非连续字符的区域总是复合区域。通过使用综合描述子,包含CCs的复合描述子能容易被计算根据只包含CCs描述子。设ri和rj是包含一个或多个CCs的区域,rc是ri和rj的复合区域,且φ(r)是r的描述子计算函数。当描述子是综合描述子时。存在+满足φ(rc)=φ(ri)+φ(rj),其中+表示ri和rj描述子的结合操作。提出的场景文字检测方法使用综合描述子计算复合区域描述子来减少计算开销。
接下来结合了我们方法的综合描述子用作复合区域:RBB和水平连续描述子和其他类型的描述子转换成综合描述子。没有特别提到描述符+是一个加法。
RBB(ymin(r),ymax(r),xmin(r),xmax(r))RBB表示旋转了任意角度θ的边界盒坐标如图3所示。RBB用来精确的计算旋转了θ的区域几何特征。每一个值如下定义:
Ymin(r)= ymax(r)= ……
其中xr和yr是区域r中像素r的坐标,h是输入图像的高度,且θ从大量计算角度中获得,Nori是预定义的固定值。Θ=π/2 + m/Nori 我们凭经验设置Nori=6.每一个RBB的+值分别是min,max,min和max。
水平连续性 (vmin vmax) 2个向量表示这个部分,其中区域r在角度θ是连续的如图4。初始向量vmin和vmax是{xmin(r)}和{xmax{r}}。+显示在算法1中。
面积 nara(r) 像素的个数
所有的颜色 (sc0(r) sc1(r) sc2(r)) HIS颜色空间中所有的像素值
笔画支持像素数SSPs nssp(r) SSP用于计算笔画的宽度。
全部笔画宽度 sswd(r) SSP全部的笔画值
周长 nperi(r)边界的长度
总平滑值 ssmt(r) 相邻边界像素梯度方向差的总值,平滑特征细节在早前的研究中。
对于RBB,在旋转θ角度的坐标系中,等式1和2表示垂直位置的最小值与最大值,且等式3和等式4表示水平位置的最小值和最大值。如图3所示。因此,在旋转θ角度坐标系中,θ角度的RBB能够精确精算r的大小,方向和位置。随着Nori的增加,更多不同角度的几何特征能计算得到,但是所有CCs的整个RBB计算开销增加。然而RBB逐步可计算的,这是一类特殊的描述符,可以通过MSER算法快速计算出所有CCs。一副N个像素的图片所有CCs描述子计算复杂度是O(N),在我们实验中,整个RBB计算时间在Nori=6时只是0.07秒比Nori=1时耗时长。
3.1.2综合描述子特征
旋转θ度的坐标系中不同几何特征能从θ度RBB中得到。单个区域对的基本特征如下所示。
r的一些大小特征能从区域r的RBB中容易计算出。旋转高度h(r)和旋转宽度w(r)这样计算h(r)=,…..w(r)=……c=sqrt()….其中c是系数防止出现0/0且当坐标系没有旋转时(θ=0)是1。每一个坐标系的长度有不同的比例,但是旋转的纵横比不需要标准化就能计算,因为同一坐标系的长度能直接比较。Aspect(r)=…….
RBB的区域对ri和rj能精确计算旋转区域对特征:高度差异hdiff,宽度差异wdiff,水平最小距离xdis,垂直重叠yovl。一般,每一个字符大小和每一个字符对的间隔是相似的;因此这些特征对旋转文本检测是有用的。ri和rj的这些特征定义为hdiff=……wdiff=…..xdis=….yovl=……
我们现在讨论高等特征从下列综合描绘子中得到。这些特征在第3.2.2章提到的文本行生成阶段去计算字符对距离。当这些特征值很小时,与特征相关的区域是字符的概率很高。不连续是我们在论文中提到的一个特征。其他特征与传统场景文字特征相似,但是一些特征用RBB进行扩展后对于多方向更加鲁棒。
单字符的不连续ddcn(r)=……
其中v[q]是向量v的第q+1个元素,ncnt是|vmin|,不连续表示包含同样复合区域的CCs之间的距离,如图4(b)。一般来说,正确字符的不连续性是很小或者是0.我们的方法通过不连续阻止了非关CCs这个意想不到的组合。
对的颜色差异dclr=……
其中 dc0=…..dc1=….. dc2=…..
对的笔画宽度差异 dswd=…..其中swdm(r)=sswd(r)/nssp(r)
对的垂直重叠 dovl=…..
对的高度和宽度差异dh=……dw=…..
顶部,底部和三条平行线
Dtop=…. Dbtm=…. Dboth=…..
其中,xctr=….Ydiff_t=….. ydiff_b=…..
三区间相似性研究dinter=….
间隔相似性表示最近的不包括相同文本的CC的几何距离。我们的方法通过使用间隔相似性促进相近CCs的复合。
注意RBB模型只就地旋转不发生透视失真。例如,等式18和19计算的属于统一文本的字符透视失真值往往很大,导致字符被确定属于不同文本。在公式20,21,22中显示的对齐特性对于检测此类文本非常重要。因为属于同一文本的字符有规律的排列且不管出不出现透视失真特征值都很低。
3.3文本检测流
3.2.1字符候选检测
我们的模型,使用MSER算法提取CCs,使用顺序分类器CCs被分类为字符候选或者非字符候选。这个分类被分为三个部分来更好的计算效率。第一和第二个阶段使用adaboost且第三个阶段使用DNN。根据前一个分类为字符的CCs进入下一个阶段。在第一个阶段和第二个阶段使用的特征几乎和[15]中一样。
在第一个阶段,分类器使用低计算花销特征且清除一定是非字符的CCs。不同于【15】的是小旋转角度代替一般角度。小旋转角度被定义为aspectmin(r)=…….在这里,aspectmin(r)对r旋转是鲁棒的且提高了旋转区域的分类精确度。
在第二阶段,我们的方法除了[15]中描述的特征,还使用了平滑性。平滑度由ssmt/nperi计算得到。第二个分类器输出类条件概率,且我们的方法减少了使用这个概率检测CCs时的冗余。冗余减少算法和[27]里面的线性减少算法相似,但是不同在于使用的是类条件概率,而不是正则变分
在第三阶段,我们的方法通过DNN强大的辨别能力检测有高概率的字符CCs。图5显示了我们方法的DNN结构。注意所有的图片都使用了最小旋转边界盒进行旋转归一化。在这个阶段后,每一个CC都有一个字符概率在[0,1]之间。
3.2.2文本行生成
在生成文本行阶段,很多旋转的文本行候选基于通过深度神经网络标为字符的CCs被检测.这样被标为字符的CC被称为基本字符。我们的方法使用搜索算法递归的搜索基本字符的邻居来组成文本行候选。搜索方法是基于一个字符对距离和一些启发式的规则。字符对距离表示字符之间的相似性,且当字符属于同一文本时,字符之间距离很小。
我们现在为了计算2个字符的相似性,定义1对字符距离。在某一个旋转θ坐标系中,字符区域ri到字符区域rj的距离的d(ri,rj)定义为wTxrirjθ,其中w是一个权值向量参数。然后,xrirjθ是一个10特征向量,在3.1.2由公式23和14计算得到。我们确定参数w通过使用距离测量学习(DML)技术,这是一个半监督聚类技术且学习一个距离度量满足给定的标签。Yin等人使用DML技术自动的确定权重和阈值从非字符中分离字符。我们也使用这个技术确定w,但是只有阈值是认为确定的。
我们的研究方法使用一对距离来检测ri的邻居字符。这个过程是基于包括ri在内的的四个区域进行的,其他距ri最近的字符预期被称为ri-1和两个未确定区域ri+1,ri+2。ri+1表示。ri+1表示ri一个相邻字符候选。ri-1和ri+2用来确定ri+1是否应该被包含在文本行候选中。在计算xriri+1θ时,等式14的输入时ri+1,等式20,21,22的输入是(ri-1,ri,ri+1),等式23的输入是(ri,ri+1,ri+2),其余等式输入为(ri,ri+1)。图6展示了4个区域和邻居字符搜索流的例子。我们的搜索方法搜索ri的邻居字符,通过选择和评估多个邻居字符候选作为ri+1.在选择ri+1和ri+2时,我们的搜索方法构建了ri封闭CC列表,如图6(a)所示。Ri的封闭CC列表是满足下列标间的rcc的集合:…………
这个封闭CC列表用来限制邻居字符搜索范围。每一个阈值thclr,thswd,thhor和thver定义为一个值,当所有正确训练样本被检测到时。接下来我们的搜索方法从基于启发式规则的封闭CC列表中选择一个初始ri+1。初始化的ri+1是最低xdis的CC,满足条件yovl>0和dh>0.5。另一方面,ri+2是在CC列表中满足yovl>0的最接近水平的CC。结果,我们的搜索方法计算xriri+1θ确定4个区域。
我们的方法从封闭CC列表中寻找更低对距离的组合。初始ri+1变成初始邻居候选rcand,且计算d(ri,rcand)。然后,创建临时复合区域rcand和CC列表里的其他CCs,计算成对距离。接下来,具有到ri最短距离的临时复合区域选作rlowest,且当d(ri,rcand)>d(ri,rlowest)时,rlowest代替rcand,且最后的rcand被选为ri的检测邻居字符,rnbr。最后,当d(ri,rnbr)<thdml时,这个方法将添加检测字符到文本行中,且再次执行邻居字符搜索。ri和ri-1在下一步中由rnbr和ri替代。
在这一阶段,计算候选文本行的概率为下一步文本行消去阶段做准备。t是角度为θ的候选文本行且ptxt(t)是t的概率。ptxt(t)初始值为0,当rnbr加入到t中,thdml – d(ri,rnbr) 添加到ptxt中。Ptxt(t)越高表示包含t的候选字符的特征越相似。
3.2.3文本行消去
文本行构建之后,还存在很多候选文本行且大量重叠,如图2(c)所示。我们的方法去掉重叠候选文本通过一个简单的消去算法。首先,我们的方法使用重叠t的候选tovl的概率ptxt(tovl)更新ptxt(t)。当θ和θ相同时,ptxt(tovl)添加到ptxt(t)里。另一方面,当θ和θ不相同时,-ptxt(tovl)添加到ptxt(t)里。接下来,当θ与θ不同,且ptxt(t)<ptxt(tovl)时,候选t删除。由以往经验可得,正确角度的候选文本行数量大于不正确角度候选。因此,虽然这个方法很简单,但是很有效。最后,对还存在的候选文本行使用传统特征Adaboost分类。
4. 实验
4.1参数设置
4.2MSRA-TD500性能评估
5. 结论
我们提出了一个基于MSER的场景文字检测方法,对旋转不连续字符很鲁棒。RBB精确的计算旋转几何特征且我们的邻居字符搜索方法利用综合描绘子检测不连续字符。我们的方法在MSRA-TD500的精度和F-测量上都取得了最好的分数。对于中文文本,召回率和现存的最好得分是一样的。因此,我们总结了我们的方法在检测包含了不连续字符的旋转场景文字中精度和F-度量实现了最好的性能。在未来的工作中,我们将研究一个更加合适的参数学习方法,且对密集文本检测时间进行改进。
1.现存的问题
2.方法大致过程
3.RBBs旋转边界盒 水平连续描绘子例子
4.算法1
5.DNN网络结构
6.邻近字符搜索流
7.实验结果图

相关文章推荐
- 论文学习(CVPR2018):Multi-Oriented Scene Text Detection via Coner Localization and Region Segmentation
- 【论文笔记】 R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
- A Novel Text Structure Feature Extractor for Chinese Scene Text Detection and Recognition论文笔记
- 【论文】Detection and segmentation of moving objects in complex scenes
- XiangBai——【CVPR2018】Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
- 经典论文阅读——DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations (CVPR 2
- 读CVPR2014论文<Saliency Optimization from Robust Background Detection>
- 论文阅读(XiangBai——【CVPR2017】Detecting Oriented Text in Natural Images by Linking Segments)
- 论文阅读:Automatic Detection and Classi cation of Teeth in CT Data
- 【论文笔记】Robust Scene Text Recognition with Automatic Rectification
- [论文笔记]Arbitrary-Oriented Scene Text Detection via Rotation Proposals
- 论文阅读(Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images)
- 1607.CVPR-Joint Learning of Single-image and Cross-image Representations for Person ReID 论文笔记
- 【论文笔记】 Arbitrary-Oriented Scene Text Detection via Rotation Proposals
- 论文阅读(Xiang Bai——【CVPR2015】Symmetry-Based Text Line Detection in Natural Scenes)
- 论文笔记:Chaotic Invariants of Lagrangian Particle Trajectories for Anomaly Detection in Crowded Scenes
- (Paper)Robust Text Detection in Natural Scene Images
- DropBand:A Simple and Effective Method for Promoting the VHR Scene Classification Accuracy of CNN