Push or Pull?
2017-09-15 09:57
197 查看
采用Pull模型还是Push模型是很多中间件都会面临的一个问题。消息中间件、配置管理中心等都会需要考虑Client和Server之间的交互采用哪种模型:
服务端主动推送数据给客户端?
客户端主动从服务端拉取数据?
本篇文章对比Pull和Push,结合消息中间件的场景进一步探讨有没有其他更合适的模型。
Push即服务端主动发送数据给客户端。在服务端收到消息之后立即推送给客户端。
Push模型最大的好处就是实时性。因为服务端可以做到只要有消息就立即推送,所以消息的消费没有“额外”的延迟。
但是Push模式在消息中间件的场景中会面临以下一些问题:
在Broker端需要维护Consumer的状态,不利于Broker去支持大量的Consumer的场景
Consumer的消费速度是不一致的,由Broker进行推送难以处理不同的Consumer的状况
Broker难以处理Consumer无法消费消息的情况(Broker无法确定Consumer的故障是短暂的还是永久的)
大量的推送消息会加重Consumer的负载或者冲垮Consumer
Pull模式可以很好的应对以上的这些场景。
2.Pull
Pull模式由Consumer主动从Broker获取消息。
这样带来了一些好处:
Broker不再需要维护Consumer的状态(每一次pull都包含了其实偏移量等必要的信息)
状态维护在Consumer,所以Consumer可以很容易的根据自身的负载等状态来决定从Broker获取消息的频率
Pull模式还有一个好处是可以聚合消息。
因为Broker无法预测写一条消息产生的时间,所以在收到消息之后只能立即推送给Consumer,所以无法对消息聚合后再推送给Consumer。 而Pull模式由Consumer主动来获取消息,每一次Pull时都尽可能多的获取已近在Broker上的消息。
但是,和Push模式正好相反,Pull就面临了实时性的问题。
因为由Consumer主动来Pull消息,所以实时性和Pull的周期相关,这里就产生了“额外”延迟。如果为了降低延迟来提升Pull的执行频率,可能在没有消息的时候产生大量的Pull请求(消息中间件是完全解耦的,Broker和Consumer无法预测下一条消息在什么时候产生);如果频率低了,那延迟自然就大了。
另外,Pull模式状态维护在Consumer,所以多个Consumer之间需要相互协调,这里就需要引入ZK或者自己实现NameServer之类的服务来完成Consumer之间的协调。
有没有一种方式,能结合Push和Pull的优势,同时变各自的缺陷呢?答案是肯定的。
long-polling不是一种Push模式,而是Pull的一个变种。
那么:
在Broker一直有可读消息的情况下,long-polling就等价于执行间隔为0的pull模式(每次收到Pull结果就发起下一次Pull请求)。
在Broker没有可读消息的情况下,请求阻塞在了Broker,在产生下一条消息或者请求“超时之前”响应请求给Consumer。
以上两点避免了多余的Pull请求,同时也解决Pull请求的执行频率导致的“额外”的延迟。
注意上面有一个概念:“超时之前”。每一个请求都有超时时间,Pull请求也是。“超时之前”的含义是在Consumer的“Pull”请求超时之前。
基于long-polling的模型,Broker需要保证在请求超时之前返回一个结果给Consumer,无论这个结果是读取到了消息或者没有可读消息。
因为Consumer和Broker之间的时间是有偏差的,且请求从Consumer发送到Broker也是需要时间的,所以如果一个请求的超时时间是5秒,而这个请求在Broker端阻塞了5秒才返回,那么Consumer在收到Broker响应之前就会判定请求超时。所以Broker需要保证在Consumer判定请求超时之前返回一个结果。
通常的做法时在Broker端可以阻塞请求的时间总是小于long-polling请求的超时时间。比如long-polling请求的超时时间为30秒,那么Broker在收到请求后最迟在25s之后一定会返回一个结果。中间5s的差值来应对Broker和Consumer的始终存在偏差和网络存在延迟的情况。 (可见Long-Polling模式的前提是Broker和Consumer之间的时间偏差没有“很大”)
Long-Polling还存在什么问题吗,还能改进吗?
这是上面long-polling在服务端一直有可消费消息的处理情况。在这个情况下,一条消息如果在long-polling请求返回时到达服务端,那么它被Consumer消费到的延迟是:
另外,在这种情况下Broker和Consumer之间一直在进行请求和响应(long-polling变成了间隔为0的pull)。
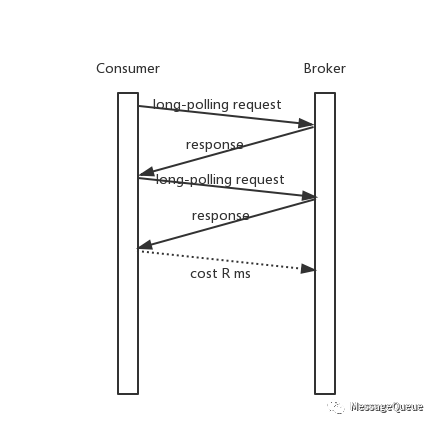
考虑这样一种方式,它有long-polling的优势,同时能减少在有消息可读的情况下由Broker主动push消息给Consumer,减少不必要的请求。
消息中间件的Consumer实现
在消息中间件的Consumer中会有一个Buffer来缓存从Broker获取的消息,而用户的消费线程从这个Buffer中获取消费来消息,获取消息的线程和消费线程通过这个Buffer进行数据传递。

pull线程从服务端获取数据,然后写入到Buffer
consume线程从Buffer获取消息进行消费
有这个Buffer的存在,是否可以在long-polling请求时将Buffer剩余空间告知给Broker,由Broker负责推送数据。此时Broker知道最多可以推送多少条数据,那么就可以控制推送行为,不至于冲垮Consumer。
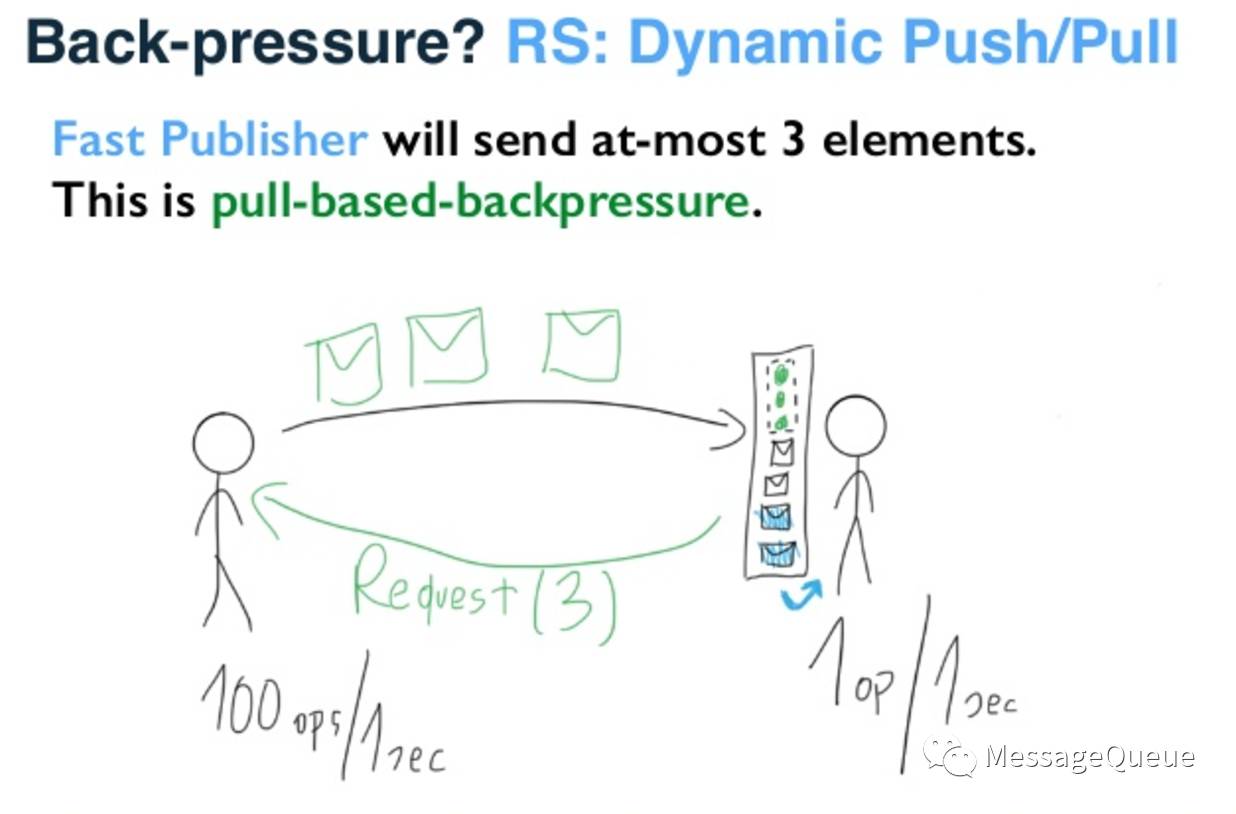
上面这幅图是akka的Dynamic Push/Pull示意图,思路就是每次请求会带上本地当前可以接收的数据的容量,这样在一段时间内可以由Server端主动推送消息给请求方,避免过多的请求。
akka的Dynamic Push/Pull模型非常适合应用到Consumer获取消息的场景。
Broker端对Dynamic Push/Pull的处理流程大致如下:
Consumer端对Dynamic Push/Pull的处理流程大致如下:
举个例子:
Consumer发起请求时Buffer剩余容量为100,Broker每次最多返回32条消息,那么Consumer的这次long-polling请求Broker将在执行3次push(共push96条消息)之后返回response给Consumer(response包含4条消息)。
如果采用long-polling模型,Consumer每发送一次请求Broker执行一次响应,这个例子需要进行4次long-polling交互(共4个request和4个response,8次网络操作;Dynamic Push/Pull中是1个request,三次push和一个response,共5次网络操作)。
总结:
Dynamic Push/Pull的模型利用了Consumer本地Buffer的容量作为一次long-polling最多可以返回的数据量,相对于long-polling模型减少了Consumer发起请求的次数,同时减少了不必要的延迟(连续的Push之间没有延迟,一批消息到Consumer的延迟就是一个网络开销;long-polling最大会是3个网络开销)。
Dynamic Push/Pull还有一些需要考虑的问题,比如连续推送的顺序性保证,如果丢包了怎么处理之类的问题,有兴趣可以自己考虑一下(也可以私下交流)。
Push模型实时性好,但是因为状态维护等问题,难以应用到消息中间件的实践中。
Pull模式实现起来会相对简单一些,但是实时性取决于轮训的频率,在对实时性要求高的场景不适合使用。
Long-Polling结合了Push和Pull各自的优势,在Pull的基础上保证了实时性,实现也不会非常复杂,是比较常用的一种实现方案。
Dynamic Push/Pull在Long-Polling的基础上,进一步优化,减少更多不必要的请求。但是先对实现起来会复杂一些,需要处理更多的异常情况。
参考内容:Google->Reactive Stream Processing with Akka Streams
往期文章:
消息中间件核心实体(1)
消息中间件核心实体(0)
消息的写入和读取流程
NameServer模块划分
Client模块划分
Broker模块划分
消息中间件架构讨论
业务方对消息中间件的需求
消息中间件中的一些概念
什么是分布式消息中间件?

服务端主动推送数据给客户端?
客户端主动从服务端拉取数据?
本篇文章对比Pull和Push,结合消息中间件的场景进一步探讨有没有其他更合适的模型。
Push VS Pull
1. PushPush即服务端主动发送数据给客户端。在服务端收到消息之后立即推送给客户端。
Push模型最大的好处就是实时性。因为服务端可以做到只要有消息就立即推送,所以消息的消费没有“额外”的延迟。
但是Push模式在消息中间件的场景中会面临以下一些问题:
在Broker端需要维护Consumer的状态,不利于Broker去支持大量的Consumer的场景
Consumer的消费速度是不一致的,由Broker进行推送难以处理不同的Consumer的状况
Broker难以处理Consumer无法消费消息的情况(Broker无法确定Consumer的故障是短暂的还是永久的)
大量的推送消息会加重Consumer的负载或者冲垮Consumer
Pull模式可以很好的应对以上的这些场景。
2.Pull
Pull模式由Consumer主动从Broker获取消息。
这样带来了一些好处:
Broker不再需要维护Consumer的状态(每一次pull都包含了其实偏移量等必要的信息)
状态维护在Consumer,所以Consumer可以很容易的根据自身的负载等状态来决定从Broker获取消息的频率
Pull模式还有一个好处是可以聚合消息。
因为Broker无法预测写一条消息产生的时间,所以在收到消息之后只能立即推送给Consumer,所以无法对消息聚合后再推送给Consumer。 而Pull模式由Consumer主动来获取消息,每一次Pull时都尽可能多的获取已近在Broker上的消息。
但是,和Push模式正好相反,Pull就面临了实时性的问题。
因为由Consumer主动来Pull消息,所以实时性和Pull的周期相关,这里就产生了“额外”延迟。如果为了降低延迟来提升Pull的执行频率,可能在没有消息的时候产生大量的Pull请求(消息中间件是完全解耦的,Broker和Consumer无法预测下一条消息在什么时候产生);如果频率低了,那延迟自然就大了。
另外,Pull模式状态维护在Consumer,所以多个Consumer之间需要相互协调,这里就需要引入ZK或者自己实现NameServer之类的服务来完成Consumer之间的协调。
有没有一种方式,能结合Push和Pull的优势,同时变各自的缺陷呢?答案是肯定的。
Long-Polling
使用long-polling模式,Consumer主动发起请求到Broker,正常情况下Broker响应消息给Consumer;在没有消息或者其他一些特殊场景下,可以将请求阻塞在服务端延迟返回。long-polling不是一种Push模式,而是Pull的一个变种。
那么:
在Broker一直有可读消息的情况下,long-polling就等价于执行间隔为0的pull模式(每次收到Pull结果就发起下一次Pull请求)。
在Broker没有可读消息的情况下,请求阻塞在了Broker,在产生下一条消息或者请求“超时之前”响应请求给Consumer。
以上两点避免了多余的Pull请求,同时也解决Pull请求的执行频率导致的“额外”的延迟。
注意上面有一个概念:“超时之前”。每一个请求都有超时时间,Pull请求也是。“超时之前”的含义是在Consumer的“Pull”请求超时之前。
基于long-polling的模型,Broker需要保证在请求超时之前返回一个结果给Consumer,无论这个结果是读取到了消息或者没有可读消息。
因为Consumer和Broker之间的时间是有偏差的,且请求从Consumer发送到Broker也是需要时间的,所以如果一个请求的超时时间是5秒,而这个请求在Broker端阻塞了5秒才返回,那么Consumer在收到Broker响应之前就会判定请求超时。所以Broker需要保证在Consumer判定请求超时之前返回一个结果。
通常的做法时在Broker端可以阻塞请求的时间总是小于long-polling请求的超时时间。比如long-polling请求的超时时间为30秒,那么Broker在收到请求后最迟在25s之后一定会返回一个结果。中间5s的差值来应对Broker和Consumer的始终存在偏差和网络存在延迟的情况。 (可见Long-Polling模式的前提是Broker和Consumer之间的时间偏差没有“很大”)
Long-Polling还存在什么问题吗,还能改进吗?
Dynamic Push/Pull
“在Broker一直有可读消息的情况下,long-polling就等价于执行间隔为0的pull模式(每次收到Pull结果就发起下一次Pull请求)。”这是上面long-polling在服务端一直有可消费消息的处理情况。在这个情况下,一条消息如果在long-polling请求返回时到达服务端,那么它被Consumer消费到的延迟是:
假设Broker和Consumer之间的一次网络开销时间为R毫秒, 那么这条消息需要经历3R才能到达Consumer 第一个R:消息已经到达Broker,但是long-polling请求已经读完数据准备返回Consumer,从Broker到Consumer消耗了R 第二个R:Consumer收到了Broker的响应,发起下一次long-polling,这个请求到达Broker需要一个R 的时间 第三个R:Broker收到请求读取了这条数据,那么返回到Consumer需要一个R的时间 所以总共需要3R(不考虑读取的开销,只考虑网络开销)
另外,在这种情况下Broker和Consumer之间一直在进行请求和响应(long-polling变成了间隔为0的pull)。
考虑这样一种方式,它有long-polling的优势,同时能减少在有消息可读的情况下由Broker主动push消息给Consumer,减少不必要的请求。
消息中间件的Consumer实现
在消息中间件的Consumer中会有一个Buffer来缓存从Broker获取的消息,而用户的消费线程从这个Buffer中获取消费来消息,获取消息的线程和消费线程通过这个Buffer进行数据传递。
pull线程从服务端获取数据,然后写入到Buffer
consume线程从Buffer获取消息进行消费
有这个Buffer的存在,是否可以在long-polling请求时将Buffer剩余空间告知给Broker,由Broker负责推送数据。此时Broker知道最多可以推送多少条数据,那么就可以控制推送行为,不至于冲垮Consumer。
上面这幅图是akka的Dynamic Push/Pull示意图,思路就是每次请求会带上本地当前可以接收的数据的容量,这样在一段时间内可以由Server端主动推送消息给请求方,避免过多的请求。
akka的Dynamic Push/Pull模型非常适合应用到Consumer获取消息的场景。
Broker端对Dynamic Push/Pull的处理流程大致如下:
收到long-polling请求
while(有数据可以消费&请求没超时&Buffer还有容量) {
读取一批消息
Push到Consumer
Buffer-PushedAmount 即减少Buffer容量
}
response long-polling请求
结束(等待下一个long-polling再次开始这个流程)Consumer端对Dynamic Push/Pull的处理流程大致如下:
收到Broker的响应:
if (long-polling的response) {
将获取的消息写入Buffer
获取Buffer的剩余容量和其他状态
发起新的long-polling请求
} else {
// Dynamic Push/Pull的推送结果
将获取的消息写入到Buffer(不发起新的请求)
}举个例子:
Consumer发起请求时Buffer剩余容量为100,Broker每次最多返回32条消息,那么Consumer的这次long-polling请求Broker将在执行3次push(共push96条消息)之后返回response给Consumer(response包含4条消息)。
如果采用long-polling模型,Consumer每发送一次请求Broker执行一次响应,这个例子需要进行4次long-polling交互(共4个request和4个response,8次网络操作;Dynamic Push/Pull中是1个request,三次push和一个response,共5次网络操作)。
总结:
Dynamic Push/Pull的模型利用了Consumer本地Buffer的容量作为一次long-polling最多可以返回的数据量,相对于long-polling模型减少了Consumer发起请求的次数,同时减少了不必要的延迟(连续的Push之间没有延迟,一批消息到Consumer的延迟就是一个网络开销;long-polling最大会是3个网络开销)。
Dynamic Push/Pull还有一些需要考虑的问题,比如连续推送的顺序性保证,如果丢包了怎么处理之类的问题,有兴趣可以自己考虑一下(也可以私下交流)。
结语
本篇内容比较了Push、Poll、Long-Polling、Dynamic Push/Pull模型。Push模型实时性好,但是因为状态维护等问题,难以应用到消息中间件的实践中。
Pull模式实现起来会相对简单一些,但是实时性取决于轮训的频率,在对实时性要求高的场景不适合使用。
Long-Polling结合了Push和Pull各自的优势,在Pull的基础上保证了实时性,实现也不会非常复杂,是比较常用的一种实现方案。
Dynamic Push/Pull在Long-Polling的基础上,进一步优化,减少更多不必要的请求。但是先对实现起来会复杂一些,需要处理更多的异常情况。
参考内容:Google->Reactive Stream Processing with Akka Streams
往期文章:
消息中间件核心实体(1)
消息中间件核心实体(0)
消息的写入和读取流程
NameServer模块划分
Client模块划分
Broker模块划分
消息中间件架构讨论
业务方对消息中间件的需求
消息中间件中的一些概念
什么是分布式消息中间件?

相关文章推荐
- Refactoring--Pull Up /Push Down Method or Field
- Push or Pull
- Push OR Pull
- Windows下Git push or pull免输入密码设置
- push or pull 与hadoop 的机制
- Integrates Git with Sublime 3 to pull or push to Github by using Sublime plugin Git
- observer, pull or push?
- Push Or Pull?
- git使用push或者pull命令每次都需要输入用户名和密码?
- GIT的Push和Pull,强制Pull覆盖本地命令
- Web显示层技术评估; Iterator vs Visitor, Pull vs Push
- JMS学习(八)-ActiveMQ Consumer 使用 push 还是 pull 获取消息
- 关于视图控制器push or present...处理的相关
- git clone,push,pull,fetch命令详解
- adb uninstall/pull/push 命令的使用总结
- git clone,push,pull,fetch
- 第二章-第二题(练习使用git的add/commit/push/pull/fetch/clone等基本命令)--龙秋娴
- Git CMD - pull: Fetch from and integrate with another repository or a local branch
- Git push与pull的默认行为
- MVC 的 Pull 和 Push 类型的区别