我们是如何做数据库运维和优化
2017-09-11 15:57
477 查看
摘要: 8月24日阿里云数据库技术峰会上,阿里云高级DBA专家玄惭带来面对超大规模的数据库集群,尤其是在每年像双11这样重大促销活动中,阿里云是如何进行运维和优化的。本文主要介绍了天象和CloudDBA两个产品,包括他们的起源、基于系统画像仓库的应用、产品化等,最后对RDS产品的可诊断性建设和可运维性建设作了补充。
8月24日阿里云数据库技术峰会上,阿里云高级DBA专家玄惭带来面对超大规模的数据库集群,尤其是在每年像双11这样重大促销活动中,阿里云是如何进行运维和优化的。本文主要介绍了天象和CloudDBA两个产品,包括他们的起源、基于系统画像仓库的应用、产品化等,最后对RDS产品的可诊断性建设和可运维性建设作了补充。
随着云数据库时代的到来,它的运维体系不仅仅包括保持数据库集群的稳定,同时我们还要关注用户体验。在业务上,体量大,用户各类,例如有公有云小客户,也有企业大客户,每类客户的需求都各式不一,众口难调。在系统上,为了实现故障切换和资源对用户透明,系统设计中包括了众多组件,例如RDS的数据访问链路从DNS-SLB-Proxy-DB节点,也有管理控制链路从前端控制台-OPEN API-后端组件-DB节点,这样给问题的排查带来了巨大的困难,出现了一个问题你不知道是出现在那个环节。在服务上,每个用户都要求一样高的SLA,服务的不好可能就会引发公关危机。所以在云数据库时代我们面临着下面三个挑战:
一. 实例数呈指数级别增长,后端运维压力急剧上升。
二. 用户端不在我们的管理范围内,无法配合排查,巨大的成本。
三. 除了RDS自身稳定,还需要确保用户数据库本身的稳定。
面对这样的挑战该如何突破,冰冻三尺非一日之寒,RDS在过去5年的发展历程中,在系统的可运维以及可诊断中我们是怎样做的?
起源
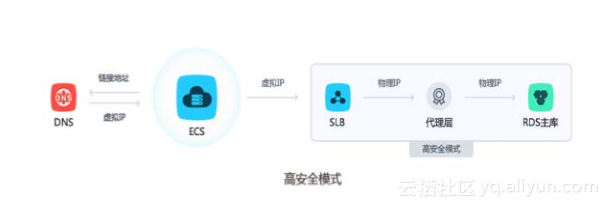
在2012年RDS刚刚成立之初,我们当时面临这一个非常严重的用户问题:闪断。当时很多游戏用户反馈游戏突然掉线了,应用的报错日志中显示应用和数据库的连接断开或者超时。面对这样的问题,很多时候是DB节点发生了主备切换,OOM或者crash,这样的情形是比较好排查的,但是对于DB上层的链路,比如proxy出现了抖动,上层SLB做了网络变更,甚至再上层的网络交换机出现了down机或者丢包,这个时候的网络闪断问题就非常难以排查了。出现这样的一个问题对于排查者来说是一个梦魇,因为他要去找很多的人去排查各个组件的负责人排查一下有没有问题,结果问了一圈都说没有问题,耗费大量的时间,客户也在哪里焦急的等待着回复。问题的根源每个组件的监控没有办法全链路统一起来。面对这样的问题,如何能够快速,简单的去发现问题出现在哪个环节?
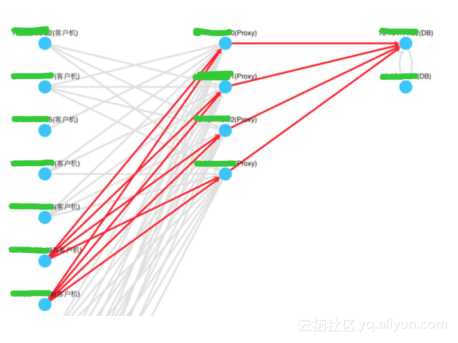
我们需要了解用户的服务质量,我们要做链路的可视化,全量秒级的可视化出链路各环节的延迟、丢包等数据。有了这样的目标,接着我们就开始将客户端到SLB,proxy,再到DB节点,所有的请求通过TCPRT全链路数据采集存储下来。TCPRT全链路系统对用户所有节点上的网络包进行实时分析并绘制出网络拓扑, 可以追溯到每段链路上每条用户链接任意每秒的延迟、丢包率、流量、异常等指标。通过可视化用户的真实链路拓扑, 我们可以在排查问题时, 很容易追溯发生问题的源头以及问题原因。整个系统目前每秒记录上百万条连接快照, 每天处理近百TB数据,远超传统监控系统的问题域,帮助我们可视化。上图中两台服务器的链路出现红色,最后反馈给用户进行排查,最终定位这两台服务器压力很大,原始情况下我们不知道问题出现在哪个节点,有了很直观的拓扑簇后,我们就可以快速定位问题。
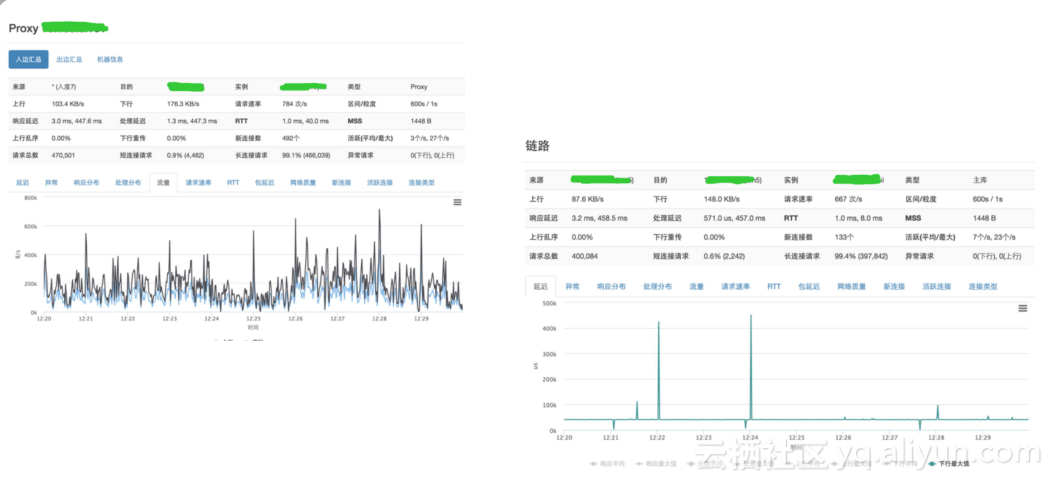
有了TCPRT的全链路数据之后,用户向云厂商提出问题,这时候我们要做自证清白,我们把用户实例所涉及到的组件,比如前端的proxy到后端的主机再到MySQL实例等等所有关键的核心链路指标,我们都会去做一次体检,这时候我们就可以快速去诊断问题到底出在DB节点还是主机上,有了这样的平台后,我们就可以快速地把我们运维能力规模化提升。
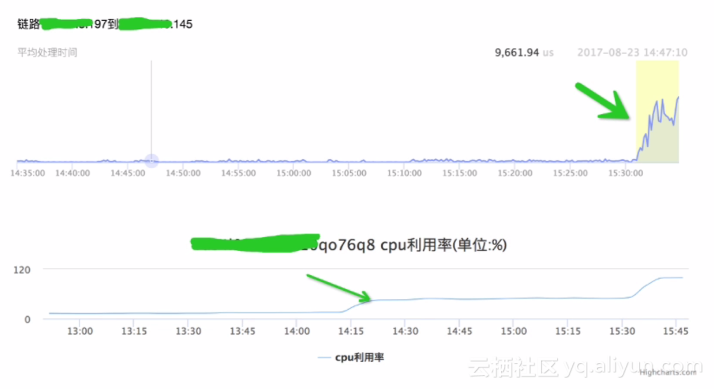
图为某用户链路RT反馈前端较慢,从监控数据可以看到RT增加了,再看后端DB监控对应的时间点,发现数据库CPU上去了,我们再去查后端用户的监控数据进行对比排查,这样就很方便的得出问题的节点在DB这一层,进而在深入排查用户数据库的资源,慢SQL以及其他内部诊断数据。有时候用户可能会说我的应用访问数据库慢了,他最直观的感觉是数据库出问题了,实际也有可能是应用到数据库中间链路出现了问题,这时,我们就可以通过链路数据最直观的看数据库端到用户中间的RT是多少,这有利于了解用户的服务质量。
随着集群规模的变大,机器数量越来越多,传统靠人的运维的模式已经不在持续,以前是被动接受用户投诉,现在变为主动发现问题,比如后端主机出现抖动(磁盘,内存,网卡故障),这时我们会快速的发现主机抖动原因,最终尝试自动解决问题,发现Top问题,并指导解决。
目前已经可以做自动化闭环牵引,当发现主机如果硬件出现问题,它的服务质量就会出现波动,我们就要自动化下线掉。如果我们发现某台主机有个实例出现争抢,我们把这个实例进行隔离,我们由被动变成闭环自动迁移处理,这是我们运维能力的提升。
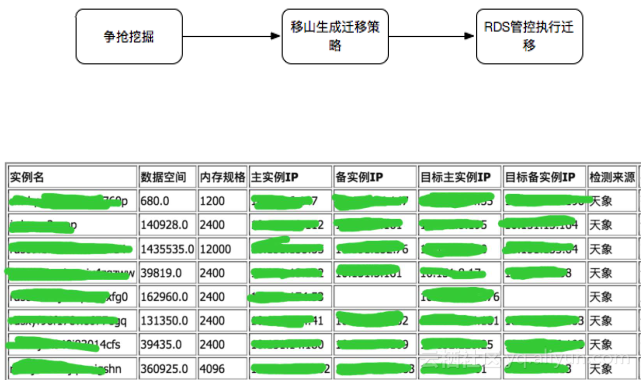
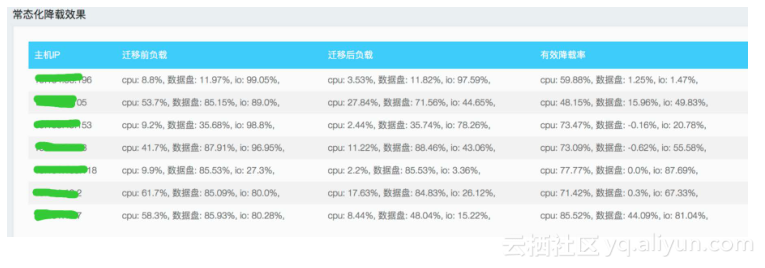
另外比如在双11大促活动的时候,我们为集群预备了2-3倍容量资源供用户弹性升级使用。为了使新上线的机器得到资源最大化利用,以保障系统的稳定,需要将老机器上的实例离散到新机器上。同时双11活动完后我们需要把这一批扩容的主机下线,将其补充到其他业务集群进行售卖,以实现资源利用率最大化。针对上面的两个应用场景,RDS启动了移山项目。移山离散策略着力于对主机以及实例最近的性能数据进行计算,得出需要迁移离散的实例列表。移山收容策略则对集群和主机的性能数据进行计算,进而得出需要收容的主机实例列表。
基于系统画像仓库的应用
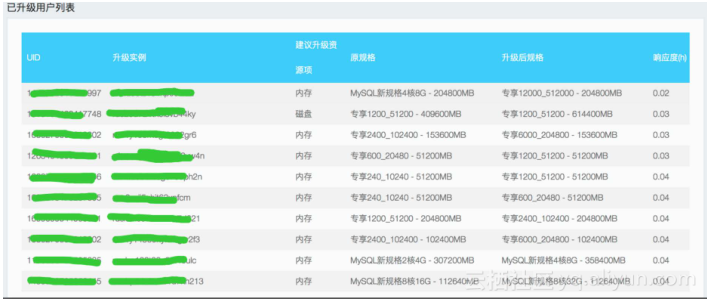
在双11大促销之前,弹性升级是商家在备战过程比不可少的一个环节,但是每年还是有很多用户不知道是否需要对数据库进行弹性升级,或者升级到多少规格。常常看到双11当天还有较多商家进行临时升级,这个时候其实已经比较危险了,这个时候系统压力往往非常大,对弹性升级的任务是有较大影响的。所以在双11备战前期,我们的系统能不能够针对用户的系统压力分析,提前通知用户进行升级,这样对双11的平稳渡过有着重要的意义。所以在每年双11期间,系统通过分析实例资源使用情况,通过一套智能算法预测用户未来用户的资源使用趋势,然后自动推动客户升级。
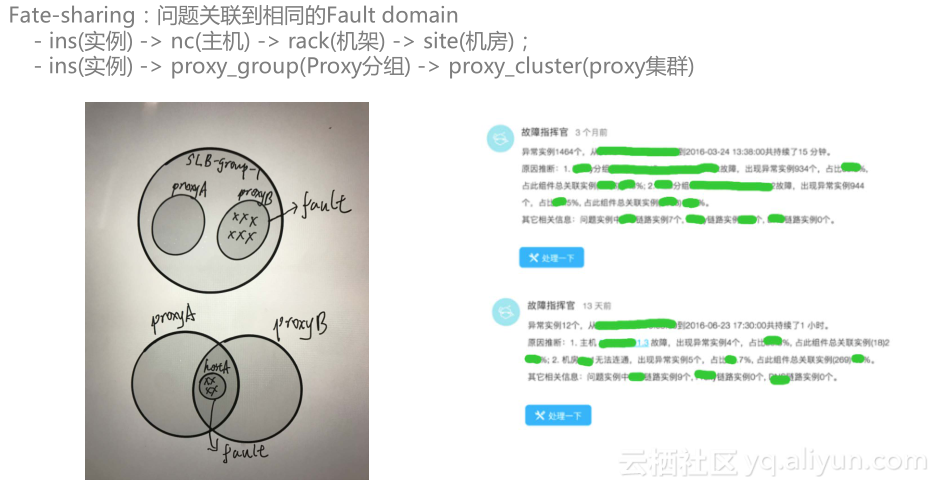
RDS在设计初期为了实现故障切换和后端节点对用户透明,系统设计中包括了众多组件,例如RDS的数据访问链路包括了DNS-SLB-Proxy-DB。面对如此复杂的数据访问链路,如何快速的帮助故障处理人员去发现问题?故障指挥官系统应运而生,该系统会基于天象数据,收集全链路数据,从实例到主机到机架到机房的物理部署链路,从实例到proxy到SLB的数据访问链路,帮助我们快速去发现故障问题点,逐点排查,这样帮助决策者大大降低故障的排查时间,减少故障的影响。
故障指挥官
云数据库服务不仅要保障底层系统的稳定,同时也要保证用户数据库运行稳定,用户这一层往往最困难的。用户的技术参差不齐,你无法去干涉用户怎么去使用数据库,或者说他们没有很好的规范去使用数据库,面对这种情况,我们该如何处理呢?在前面5年的客户保障中,我们积累了大量客户问题经验,但是人的精力是有限的,实例规模是在不断膨胀的,光靠人堆已经行不通了,所以我们决定将诊断经验产品化,将经验沉淀到产品中去,于是就有了CloudDBA这个产品。
用户使用数据库的问题各式各样,首先我们来分析一下用户在使用数据库过程中的分类,第一类运维操作,用户在购买完成一个数据库实例后,紧接着马上会做账号和DB的创建,或者添加只读节点,添加白名单,修改网络配置和访问模式等;第二类业务变更操作,比如创建表结构,存储过程和函数等对象操作,然后在将数据导入到数据库中去;第三类属于日常的巡检,优化以及故障排查,随着业务发展和数据量不断的变化,我们要实时关注数据库的健康运行,还有诸如IO、CPU、Disk 100%资源类的问题诊断,数据库出现锁等待和慢SQL后的业务优化等,类似这样的问题都是可以通过CloudDB进行解决,所以CloudDBA首先做巡检。
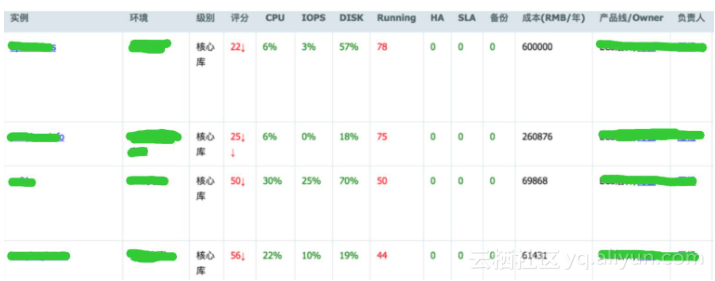
通过巡检可以直观看到数据库实例是否有问题,将数据库的核心指标比如活跃连接数、CPU、IO、Disk、可用性纳入到评分模型中去,给数据库的健康状况进行打分。通过巡检-优化-巡检这样不断去迭代优化,将数据库中存在的风险点一个个进行修复,提升系统整体的稳定性。
在每年的双11保障过程中发现双11当天往往最容易出现问题是用户自身的应用程序问题导致系统卡慢。双11前没有暴露出的问题,会由于双11当天巨量的订单和高频的系统调用将这些潜在问题放大。提前找出并解决问题是保障双11稳定运行的最佳手段。因此双11活动之前,我们就对所有相关数据库进行了全面的体检,将数据库中的潜在风险提前识别出来,并通知用户进行优化和升级。所以我们设计了体检报告,其主要特点:1)诊断报告生成的高度自动化。生成健康诊断报告上万份且全程无人工干预,这一全新的运维方式在之前是不可想象的;2)诊断内容的深度化。从基本的资源使用情况和慢SQL分析,到死锁检测和审计日志全方位统计,再到事务的深层次分析找出应用中的潜在问题等都包含在我们的诊断报告当中;3)运维保障的人性化。双11保障不是简单粗暴的让客户升级系统规格,而是以优化为主升级为辅的方式。提前主动给出诊断优化建议极大的提升了用户体验。

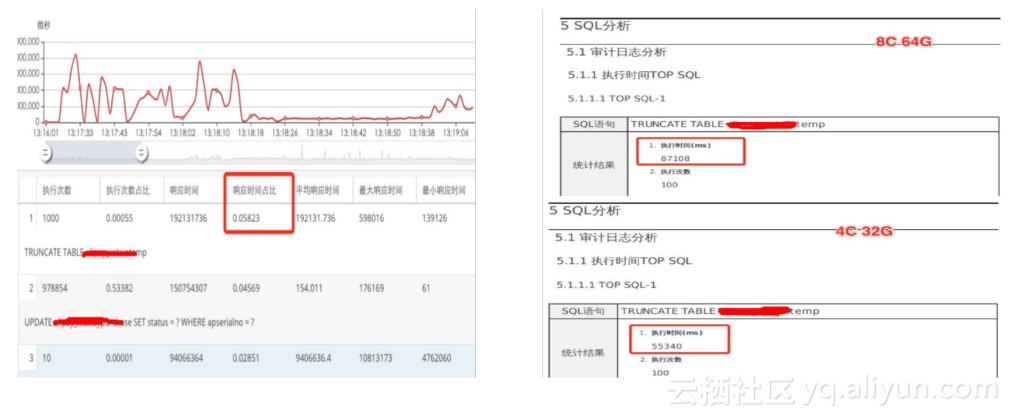
下面分享一个通过诊断报告解决一个大型在线系统压测选型问题。客户压测RDS内存12G和24G两种规格的性能,但是发现内存24G规格的还不如内存12G规格的,为什么规格升级性能反而下降了?我们必须进入到数据库中的每一条SQL去对比到底是那些SQL的执行时间增加了,但是如何在成千上万的SQL中找到性能差异的SQL是关键突破点。体检报告这个时候就成为了英雄,RDS的体检报告中含有TOP SQL的功能,我们发现 TOPSQL中TRUNCATE语句的性能出现了不一致,低规格的truncate语句执行速度优于高规格。通过这个报告定位差异的SQL,那么为什么truncate语句在大内存中变慢了,truncate
属于DDL语句,这个让我们联想到MySQL的一个bug,就MySQL DDL过程中会将内存中的脏页链表遍历一下,如果内存越大,脏页链表也就越长,所以遍历的时间也就越久,所以很快就定位到这里truncate语句变慢是因为内存上升后遍历脏页链表时间变长。
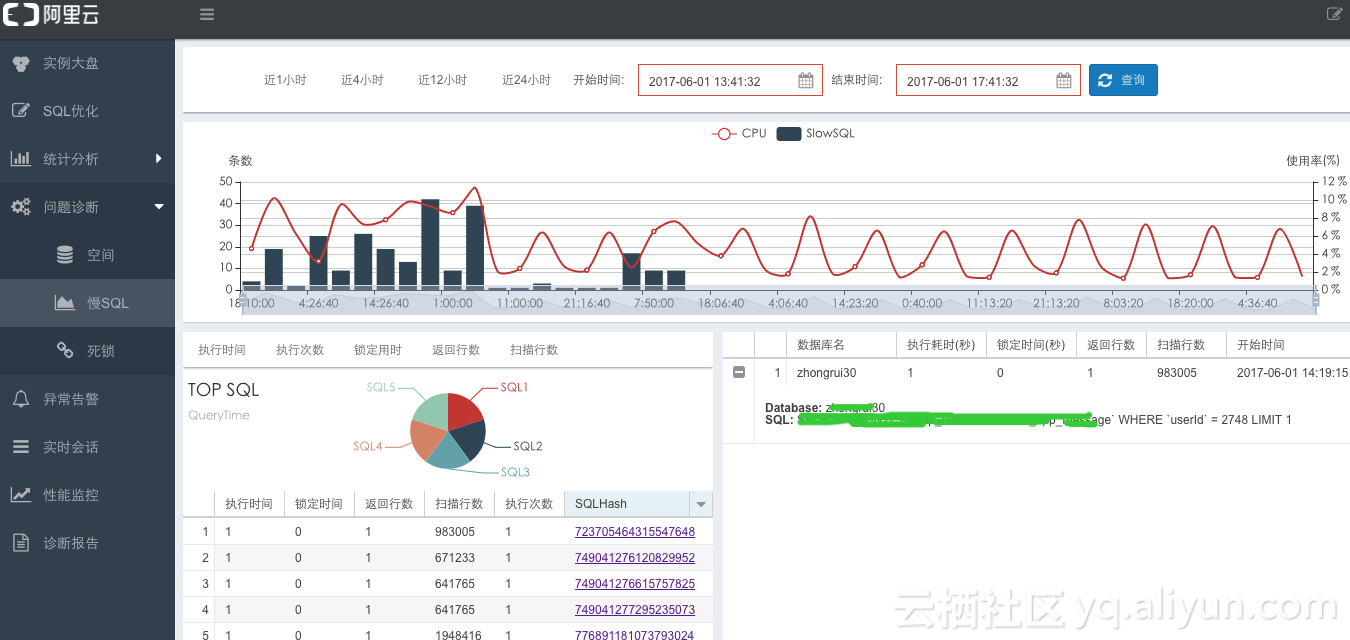
通过前面五年的积累,CloudDBA已经很好支持了我们内部管理人员快速简单的诊断数据库的性能问题,包括实例大盘(实例健康状态)、 实时问题检测、SQL多维度性能分析(全量SQL,慢SQL)、问题事务分析(事务未提交,查询开启事务,长事务,语句时间间隔)、SQL Review(事务列表,事务频率,时间轴分布)、实例空间分析、只读库延迟分析、死锁分析、实时会话状态、热点表/冗余索引分析、 SQL分析(执行计划,相关表DDL,索引建议)、健康体检报告。计划将在今年10月初将其产品化输出到控制台,真正将我们的经验和最佳实践赋能给我们的用户。
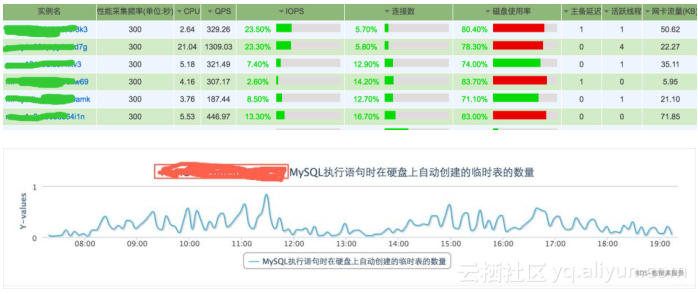
RDS经过5年的发展在稳定性和易用性上不断积累和沉淀,前面天象和CloudDBA这两个产品是这5年的一个浓缩。同时在产品的可诊断性上,全链路监控可以达到实例级别35个基本监控,主机级别13个基本监控,支持自定义分组监控大盘,监控粒度可达秒级。下面在重点介绍一下RDS的诊断快照。
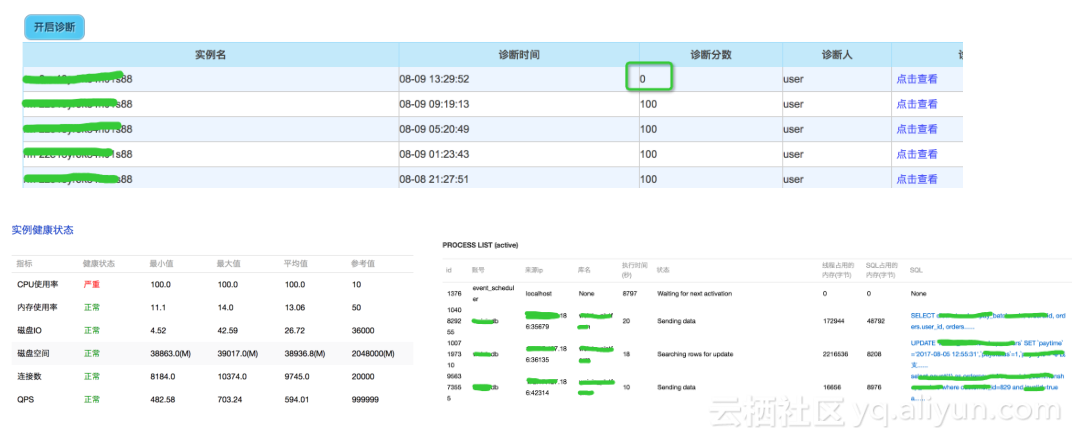
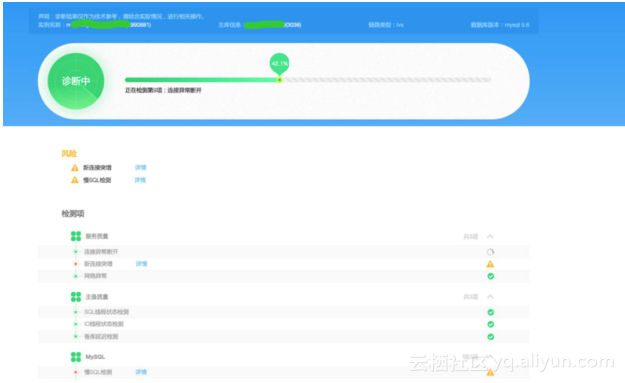
诊断快照的设计初衷在于诊断过去时间点发生的问题,比如某客户反馈昨天晚上凌晨3点中数据库出现了锁等待,或者数据库cpu瞬间抖动了一下,这个时候由于没有当时出现问题时候的现场,导致问题排查起来显得比较麻烦,不得不去查看慢日志,审计日志,监控数据等指标。所以如果能够把出问题时候的现场保留下来,比如核心的show full processlist,show engine innodb status,慢SQL,数据库中的事务状态等等,那么问题诊断起来将会非常容易。所以诊断快照为了解决保存现场的问题,我们设定了有不同类型的诊断快照,包括定时快照和触发快照。定时快照是每隔2个小时自动触发一次数据库快照,将数据库中的线程,锁,事务,慢SQL等信息保存下来。触发式快照可以设定CPU、磁盘,连接数等关键指标的阀值,触发式引发诊断快照,这样就可以把数据库出现异常情况的时候将现场保留下来,例如上图显示的诊断快照列表中,有一个诊断快照诊断分数为0分,就可以查看process
list这一列发现有很多的慢SQL出现了堆积,将数据库CPU打满,这样就非常方便的排查出问题的根源所在。
此外,可诊断性建设中还有较关键的审计日志,RDS最早的审计日志采用网络抓包的方式进行采集,但是这种方式收集日志存在严重的日志丢失和性能损耗。后面改进了数据库内核,采用类似general_log的方式进行收集审计日志,实现日志0丢失,性能损耗只有2%。审计日志记录字段:源ip,用户名,线程id,扫描行数,latency,执行时间(us),返回行数,更新行数错误号,消耗内存。在一些数据库性能优化中,比如出现QPS抖动,那么就可以通过TOP SQL功能找出QPS异常抖动是那些SQL带来的。还有一些问题比如遇到了锁等待问题,由于数据库已经持有锁的SQL是无法查看的,所以必须通过查审计日志去找到最终的业务调用来自哪里。

前面说过面对用户的行为习惯是不可控的,不好的使用方法会给后端的实例运维带来极大的压力。第一个就是用户建表时候不指定主键,简简单单的一个主键在用户删除数据的时候可能会导致备库直接hang主,这个时候主备失效,备份无法完成。所以这个简单的最佳实践并不所有用户都遵守的,作为云厂商该怎么处理,我们没有办法控制用户行为。所以我们在产品设计时需要规避掉这样的问题,我们在源码中进行优化,如果用户不指定主键,云端将会自动为用户创建主键。
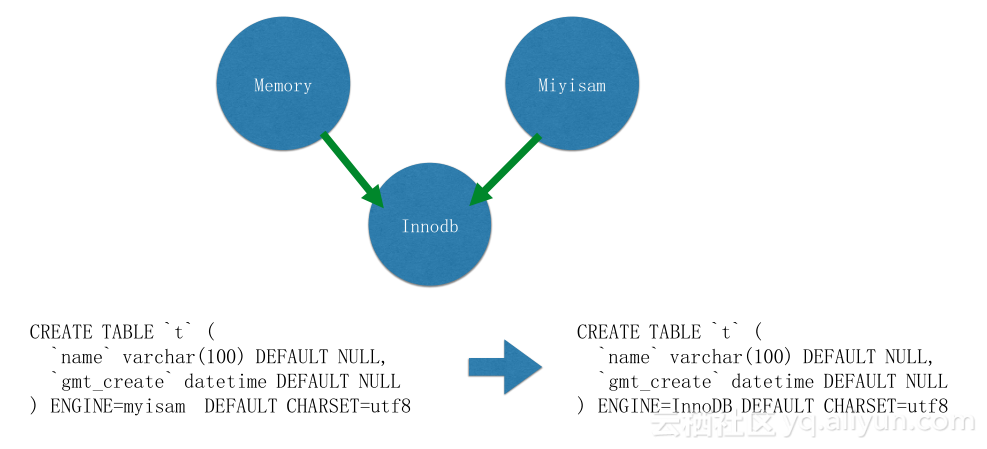
第二个问题是很多用户选择Memory、Miyisam存储引擎,在用户的眼里这些引擎的性能都是非常好的,却不知这些引擎后面留着非常多的坑。比如Memory引擎的实例宕掉后,数据就会丢失,进而主备同步会断。Miyisam引擎不支持事务,在备份时候会锁住全库,造成主备延迟,对后端维护挑战非常大。所以作为云厂商,我们需要有一定的规范来控制住这些引擎的使用,所以在产品设计的时候,我们将两个存储引擎自动转化成Innodb存储引擎,这样对系统的可维护性是具有非常大的帮助。
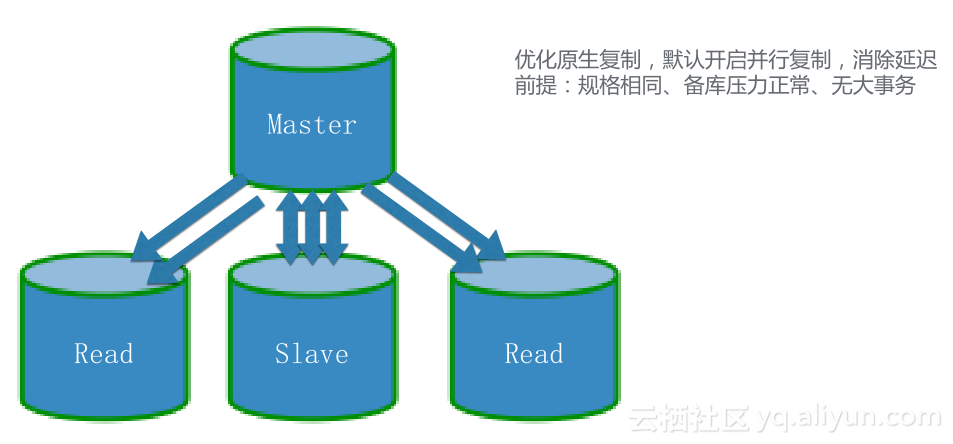
第三个问题是主备延迟的问题,MySQL原生复制是单线程复制,5.6版本可以支持库级别的并行复制,对于大部分用户来说,如果主库频繁写入,备库必然会出现延迟,主备失效。所以我们优化了MySQL原生复制,默认开启并行复制。

第四个是在主备复制中断上,MySQL原生的逻辑复制存在很多的问题,你会发现主备中断是一个逃不掉的问题,所以我们在自动化建设上,将常见的主备中断进行自动化修复,减小主备中断给客户带来的影响。
双11是全民的双11,云计算是全民的云计算,我们忠心希望未来用户在使用云计算的时候能够像使用水电煤一样简单。随着双11的全民化,有许多企业公司也开始做双11促销,但是他们的经验往往是比较匮乏的。历年双11当天我们收到了很多用户的援助请求,由于前期没有做好系统压测,导致在双十一当天业务高峰来临的时候系统垮掉,然后才考虑扩容,这个时候往往已经为时已晚。双11的护航保障经验是可以更广的传播到这些客户身上,我们也会不断地将最佳实践和保障经验沉淀到专家系统中,今年双十一,我们将会推出智能优化服务,将我们多年的数据库诊断优化经验直接赋能客户,只有这样才能将其作用最大化,规模化,可复制化,让用户真正简单方便的使用云计算。
原文链接:http://click.aliyun.com/m/30252/
8月24日阿里云数据库技术峰会上,阿里云高级DBA专家玄惭带来面对超大规模的数据库集群,尤其是在每年像双11这样重大促销活动中,阿里云是如何进行运维和优化的。本文主要介绍了天象和CloudDBA两个产品,包括他们的起源、基于系统画像仓库的应用、产品化等,最后对RDS产品的可诊断性建设和可运维性建设作了补充。
随着云数据库时代的到来,它的运维体系不仅仅包括保持数据库集群的稳定,同时我们还要关注用户体验。在业务上,体量大,用户各类,例如有公有云小客户,也有企业大客户,每类客户的需求都各式不一,众口难调。在系统上,为了实现故障切换和资源对用户透明,系统设计中包括了众多组件,例如RDS的数据访问链路从DNS-SLB-Proxy-DB节点,也有管理控制链路从前端控制台-OPEN API-后端组件-DB节点,这样给问题的排查带来了巨大的困难,出现了一个问题你不知道是出现在那个环节。在服务上,每个用户都要求一样高的SLA,服务的不好可能就会引发公关危机。所以在云数据库时代我们面临着下面三个挑战:
一. 实例数呈指数级别增长,后端运维压力急剧上升。
二. 用户端不在我们的管理范围内,无法配合排查,巨大的成本。
三. 除了RDS自身稳定,还需要确保用户数据库本身的稳定。
面对这样的挑战该如何突破,冰冻三尺非一日之寒,RDS在过去5年的发展历程中,在系统的可运维以及可诊断中我们是怎样做的?
天象
一.自证清白的救赎
起源在2012年RDS刚刚成立之初,我们当时面临这一个非常严重的用户问题:闪断。当时很多游戏用户反馈游戏突然掉线了,应用的报错日志中显示应用和数据库的连接断开或者超时。面对这样的问题,很多时候是DB节点发生了主备切换,OOM或者crash,这样的情形是比较好排查的,但是对于DB上层的链路,比如proxy出现了抖动,上层SLB做了网络变更,甚至再上层的网络交换机出现了down机或者丢包,这个时候的网络闪断问题就非常难以排查了。出现这样的一个问题对于排查者来说是一个梦魇,因为他要去找很多的人去排查各个组件的负责人排查一下有没有问题,结果问了一圈都说没有问题,耗费大量的时间,客户也在哪里焦急的等待着回复。问题的根源每个组件的监控没有办法全链路统一起来。面对这样的问题,如何能够快速,简单的去发现问题出现在哪个环节?
我们需要了解用户的服务质量,我们要做链路的可视化,全量秒级的可视化出链路各环节的延迟、丢包等数据。有了这样的目标,接着我们就开始将客户端到SLB,proxy,再到DB节点,所有的请求通过TCPRT全链路数据采集存储下来。TCPRT全链路系统对用户所有节点上的网络包进行实时分析并绘制出网络拓扑, 可以追溯到每段链路上每条用户链接任意每秒的延迟、丢包率、流量、异常等指标。通过可视化用户的真实链路拓扑, 我们可以在排查问题时, 很容易追溯发生问题的源头以及问题原因。整个系统目前每秒记录上百万条连接快照, 每天处理近百TB数据,远超传统监控系统的问题域,帮助我们可视化。上图中两台服务器的链路出现红色,最后反馈给用户进行排查,最终定位这两台服务器压力很大,原始情况下我们不知道问题出现在哪个节点,有了很直观的拓扑簇后,我们就可以快速定位问题。
有了TCPRT的全链路数据之后,用户向云厂商提出问题,这时候我们要做自证清白,我们把用户实例所涉及到的组件,比如前端的proxy到后端的主机再到MySQL实例等等所有关键的核心链路指标,我们都会去做一次体检,这时候我们就可以快速去诊断问题到底出在DB节点还是主机上,有了这样的平台后,我们就可以快速地把我们运维能力规模化提升。
图为某用户链路RT反馈前端较慢,从监控数据可以看到RT增加了,再看后端DB监控对应的时间点,发现数据库CPU上去了,我们再去查后端用户的监控数据进行对比排查,这样就很方便的得出问题的节点在DB这一层,进而在深入排查用户数据库的资源,慢SQL以及其他内部诊断数据。有时候用户可能会说我的应用访问数据库慢了,他最直观的感觉是数据库出问题了,实际也有可能是应用到数据库中间链路出现了问题,这时,我们就可以通过链路数据最直观的看数据库端到用户中间的RT是多少,这有利于了解用户的服务质量。
二.规模化运维能力提升
随着集群规模的变大,机器数量越来越多,传统靠人的运维的模式已经不在持续,以前是被动接受用户投诉,现在变为主动发现问题,比如后端主机出现抖动(磁盘,内存,网卡故障),这时我们会快速的发现主机抖动原因,最终尝试自动解决问题,发现Top问题,并指导解决。目前已经可以做自动化闭环牵引,当发现主机如果硬件出现问题,它的服务质量就会出现波动,我们就要自动化下线掉。如果我们发现某台主机有个实例出现争抢,我们把这个实例进行隔离,我们由被动变成闭环自动迁移处理,这是我们运维能力的提升。
另外比如在双11大促活动的时候,我们为集群预备了2-3倍容量资源供用户弹性升级使用。为了使新上线的机器得到资源最大化利用,以保障系统的稳定,需要将老机器上的实例离散到新机器上。同时双11活动完后我们需要把这一批扩容的主机下线,将其补充到其他业务集群进行售卖,以实现资源利用率最大化。针对上面的两个应用场景,RDS启动了移山项目。移山离散策略着力于对主机以及实例最近的性能数据进行计算,得出需要迁移离散的实例列表。移山收容策略则对集群和主机的性能数据进行计算,进而得出需要收容的主机实例列表。
基于系统画像仓库的应用
三.智能化推荐和故障预判
在双11大促销之前,弹性升级是商家在备战过程比不可少的一个环节,但是每年还是有很多用户不知道是否需要对数据库进行弹性升级,或者升级到多少规格。常常看到双11当天还有较多商家进行临时升级,这个时候其实已经比较危险了,这个时候系统压力往往非常大,对弹性升级的任务是有较大影响的。所以在双11备战前期,我们的系统能不能够针对用户的系统压力分析,提前通知用户进行升级,这样对双11的平稳渡过有着重要的意义。所以在每年双11期间,系统通过分析实例资源使用情况,通过一套智能算法预测用户未来用户的资源使用趋势,然后自动推动客户升级。 RDS在设计初期为了实现故障切换和后端节点对用户透明,系统设计中包括了众多组件,例如RDS的数据访问链路包括了DNS-SLB-Proxy-DB。面对如此复杂的数据访问链路,如何快速的帮助故障处理人员去发现问题?故障指挥官系统应运而生,该系统会基于天象数据,收集全链路数据,从实例到主机到机架到机房的物理部署链路,从实例到proxy到SLB的数据访问链路,帮助我们快速去发现故障问题点,逐点排查,这样帮助决策者大大降低故障的排查时间,减少故障的影响。
故障指挥官
CloudDBA
一.CloudDBA起源
云数据库服务不仅要保障底层系统的稳定,同时也要保证用户数据库运行稳定,用户这一层往往最困难的。用户的技术参差不齐,你无法去干涉用户怎么去使用数据库,或者说他们没有很好的规范去使用数据库,面对这种情况,我们该如何处理呢?在前面5年的客户保障中,我们积累了大量客户问题经验,但是人的精力是有限的,实例规模是在不断膨胀的,光靠人堆已经行不通了,所以我们决定将诊断经验产品化,将经验沉淀到产品中去,于是就有了CloudDBA这个产品。用户使用数据库的问题各式各样,首先我们来分析一下用户在使用数据库过程中的分类,第一类运维操作,用户在购买完成一个数据库实例后,紧接着马上会做账号和DB的创建,或者添加只读节点,添加白名单,修改网络配置和访问模式等;第二类业务变更操作,比如创建表结构,存储过程和函数等对象操作,然后在将数据导入到数据库中去;第三类属于日常的巡检,优化以及故障排查,随着业务发展和数据量不断的变化,我们要实时关注数据库的健康运行,还有诸如IO、CPU、Disk 100%资源类的问题诊断,数据库出现锁等待和慢SQL后的业务优化等,类似这样的问题都是可以通过CloudDB进行解决,所以CloudDBA首先做巡检。
二.健康体检
通过巡检可以直观看到数据库实例是否有问题,将数据库的核心指标比如活跃连接数、CPU、IO、Disk、可用性纳入到评分模型中去,给数据库的健康状况进行打分。通过巡检-优化-巡检这样不断去迭代优化,将数据库中存在的风险点一个个进行修复,提升系统整体的稳定性。在每年的双11保障过程中发现双11当天往往最容易出现问题是用户自身的应用程序问题导致系统卡慢。双11前没有暴露出的问题,会由于双11当天巨量的订单和高频的系统调用将这些潜在问题放大。提前找出并解决问题是保障双11稳定运行的最佳手段。因此双11活动之前,我们就对所有相关数据库进行了全面的体检,将数据库中的潜在风险提前识别出来,并通知用户进行优化和升级。所以我们设计了体检报告,其主要特点:1)诊断报告生成的高度自动化。生成健康诊断报告上万份且全程无人工干预,这一全新的运维方式在之前是不可想象的;2)诊断内容的深度化。从基本的资源使用情况和慢SQL分析,到死锁检测和审计日志全方位统计,再到事务的深层次分析找出应用中的潜在问题等都包含在我们的诊断报告当中;3)运维保障的人性化。双11保障不是简单粗暴的让客户升级系统规格,而是以优化为主升级为辅的方式。提前主动给出诊断优化建议极大的提升了用户体验。
下面分享一个通过诊断报告解决一个大型在线系统压测选型问题。客户压测RDS内存12G和24G两种规格的性能,但是发现内存24G规格的还不如内存12G规格的,为什么规格升级性能反而下降了?我们必须进入到数据库中的每一条SQL去对比到底是那些SQL的执行时间增加了,但是如何在成千上万的SQL中找到性能差异的SQL是关键突破点。体检报告这个时候就成为了英雄,RDS的体检报告中含有TOP SQL的功能,我们发现 TOPSQL中TRUNCATE语句的性能出现了不一致,低规格的truncate语句执行速度优于高规格。通过这个报告定位差异的SQL,那么为什么truncate语句在大内存中变慢了,truncate
属于DDL语句,这个让我们联想到MySQL的一个bug,就MySQL DDL过程中会将内存中的脏页链表遍历一下,如果内存越大,脏页链表也就越长,所以遍历的时间也就越久,所以很快就定位到这里truncate语句变慢是因为内存上升后遍历脏页链表时间变长。
三.产品化
通过前面五年的积累,CloudDBA已经很好支持了我们内部管理人员快速简单的诊断数据库的性能问题,包括实例大盘(实例健康状态)、 实时问题检测、SQL多维度性能分析(全量SQL,慢SQL)、问题事务分析(事务未提交,查询开启事务,长事务,语句时间间隔)、SQL Review(事务列表,事务频率,时间轴分布)、实例空间分析、只读库延迟分析、死锁分析、实时会话状态、热点表/冗余索引分析、 SQL分析(执行计划,相关表DDL,索引建议)、健康体检报告。计划将在今年10月初将其产品化输出到控制台,真正将我们的经验和最佳实践赋能给我们的用户。
可诊断性建设
RDS经过5年的发展在稳定性和易用性上不断积累和沉淀,前面天象和CloudDBA这两个产品是这5年的一个浓缩。同时在产品的可诊断性上,全链路监控可以达到实例级别35个基本监控,主机级别13个基本监控,支持自定义分组监控大盘,监控粒度可达秒级。下面在重点介绍一下RDS的诊断快照。
诊断快照的设计初衷在于诊断过去时间点发生的问题,比如某客户反馈昨天晚上凌晨3点中数据库出现了锁等待,或者数据库cpu瞬间抖动了一下,这个时候由于没有当时出现问题时候的现场,导致问题排查起来显得比较麻烦,不得不去查看慢日志,审计日志,监控数据等指标。所以如果能够把出问题时候的现场保留下来,比如核心的show full processlist,show engine innodb status,慢SQL,数据库中的事务状态等等,那么问题诊断起来将会非常容易。所以诊断快照为了解决保存现场的问题,我们设定了有不同类型的诊断快照,包括定时快照和触发快照。定时快照是每隔2个小时自动触发一次数据库快照,将数据库中的线程,锁,事务,慢SQL等信息保存下来。触发式快照可以设定CPU、磁盘,连接数等关键指标的阀值,触发式引发诊断快照,这样就可以把数据库出现异常情况的时候将现场保留下来,例如上图显示的诊断快照列表中,有一个诊断快照诊断分数为0分,就可以查看process
list这一列发现有很多的慢SQL出现了堆积,将数据库CPU打满,这样就非常方便的排查出问题的根源所在。
此外,可诊断性建设中还有较关键的审计日志,RDS最早的审计日志采用网络抓包的方式进行采集,但是这种方式收集日志存在严重的日志丢失和性能损耗。后面改进了数据库内核,采用类似general_log的方式进行收集审计日志,实现日志0丢失,性能损耗只有2%。审计日志记录字段:源ip,用户名,线程id,扫描行数,latency,执行时间(us),返回行数,更新行数错误号,消耗内存。在一些数据库性能优化中,比如出现QPS抖动,那么就可以通过TOP SQL功能找出QPS异常抖动是那些SQL带来的。还有一些问题比如遇到了锁等待问题,由于数据库已经持有锁的SQL是无法查看的,所以必须通过查审计日志去找到最终的业务调用来自哪里。
可运维性建设
前面说过面对用户的行为习惯是不可控的,不好的使用方法会给后端的实例运维带来极大的压力。第一个就是用户建表时候不指定主键,简简单单的一个主键在用户删除数据的时候可能会导致备库直接hang主,这个时候主备失效,备份无法完成。所以这个简单的最佳实践并不所有用户都遵守的,作为云厂商该怎么处理,我们没有办法控制用户行为。所以我们在产品设计时需要规避掉这样的问题,我们在源码中进行优化,如果用户不指定主键,云端将会自动为用户创建主键。
第二个问题是很多用户选择Memory、Miyisam存储引擎,在用户的眼里这些引擎的性能都是非常好的,却不知这些引擎后面留着非常多的坑。比如Memory引擎的实例宕掉后,数据就会丢失,进而主备同步会断。Miyisam引擎不支持事务,在备份时候会锁住全库,造成主备延迟,对后端维护挑战非常大。所以作为云厂商,我们需要有一定的规范来控制住这些引擎的使用,所以在产品设计的时候,我们将两个存储引擎自动转化成Innodb存储引擎,这样对系统的可维护性是具有非常大的帮助。
第三个问题是主备延迟的问题,MySQL原生复制是单线程复制,5.6版本可以支持库级别的并行复制,对于大部分用户来说,如果主库频繁写入,备库必然会出现延迟,主备失效。所以我们优化了MySQL原生复制,默认开启并行复制。
第四个是在主备复制中断上,MySQL原生的逻辑复制存在很多的问题,你会发现主备中断是一个逃不掉的问题,所以我们在自动化建设上,将常见的主备中断进行自动化修复,减小主备中断给客户带来的影响。
未来,赋能客户
双11是全民的双11,云计算是全民的云计算,我们忠心希望未来用户在使用云计算的时候能够像使用水电煤一样简单。随着双11的全民化,有许多企业公司也开始做双11促销,但是他们的经验往往是比较匮乏的。历年双11当天我们收到了很多用户的援助请求,由于前期没有做好系统压测,导致在双十一当天业务高峰来临的时候系统垮掉,然后才考虑扩容,这个时候往往已经为时已晚。双11的护航保障经验是可以更广的传播到这些客户身上,我们也会不断地将最佳实践和保障经验沉淀到专家系统中,今年双十一,我们将会推出智能优化服务,将我们多年的数据库诊断优化经验直接赋能客户,只有这样才能将其作用最大化,规模化,可复制化,让用户真正简单方便的使用云计算。原文链接:http://click.aliyun.com/m/30252/

相关文章推荐
- 数据库查询优化方案(处理上百万级记录如何提高处理查询速度)
- 我们该如何设计数据库(三)(续)
- 面试技巧,如何通过索引说数据库优化能力,内容来自Java web轻量级开发面试教程
- 大流量网站该如何配置优化?服务器、静态化、数据库优化、负载均衡应多管齐下
- 如何监测和优化OLAP数据库
- 如何优化操作大数据量数据库(几十万以上数据)(四。如何选择聚合索引)
- 网站首页调用数据库数据过多,显示较慢,如何优化?
- 面试技巧,如何通过索引说数据库优化能力
- 如何使用asp.net自带的缓存优化我们的项目?
- mysql处理上百万条的数据库如何优化语句来提高处理查询效率
- 在数据库中条件查询很慢的时候,如何优化
- 如何优化Urchin配置文件每月数据库的磁盘存储空间
- 2.如何优化操作大数据量数据库(改善SQL语句)
- 当数据库变慢时,我们应如何入手
- 从运维角度浅谈 MySQL 数据库优化
- 如何实现数据库的优化
- 关于分页存储过程的优化【让数据库按我们的意思执行查询计划】
- 数据库优化(如何正确建立索引)
- 我们该如何设计数据库(四)
- 如何优化操作大数据量数据库(建立索引)