读书笔记(十)——python简单爬取企查查网企业信息,并以excel格式存储
2017-09-09 00:00
507 查看
摘要: 看得博客越多,越感觉一篇高质量的博客是需要花费许多时间写的,不论是从基层代码还是编程思路,都是非常的清晰,详细的。庆幸自己只敢写个读书笔记,不敢随便扯虎皮扛大旗,有多少能力做多少事情。不足的地方,敬请指正。
今天这个小爬虫是应朋友,帮忙写的一个简单的爬虫,目的是爬取企查查这个网站的企业信息。
编程最终要的就是搭建编程环境,这里我们的编程环境是:
python3.6
BeautifulSoup模块
lxml模块
requests模块
xlwt模块
geany
首先分析需求网页的信息:
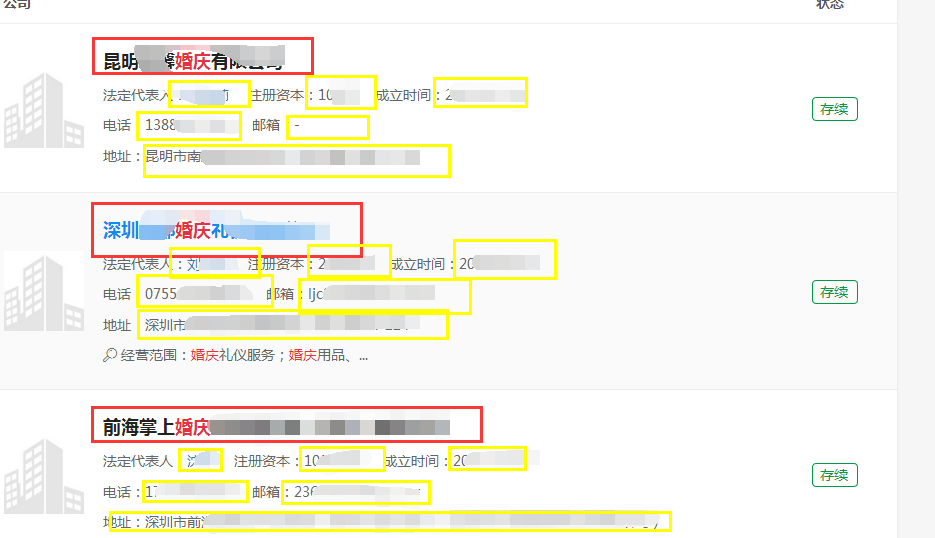
可以看到我们想要提取的消息内容有公司的名字,法定代表人,注册资本,成立时间,电话,邮箱,地址。好的,接下来我们打开firebug,查看各个内容在网页中的具体位置:
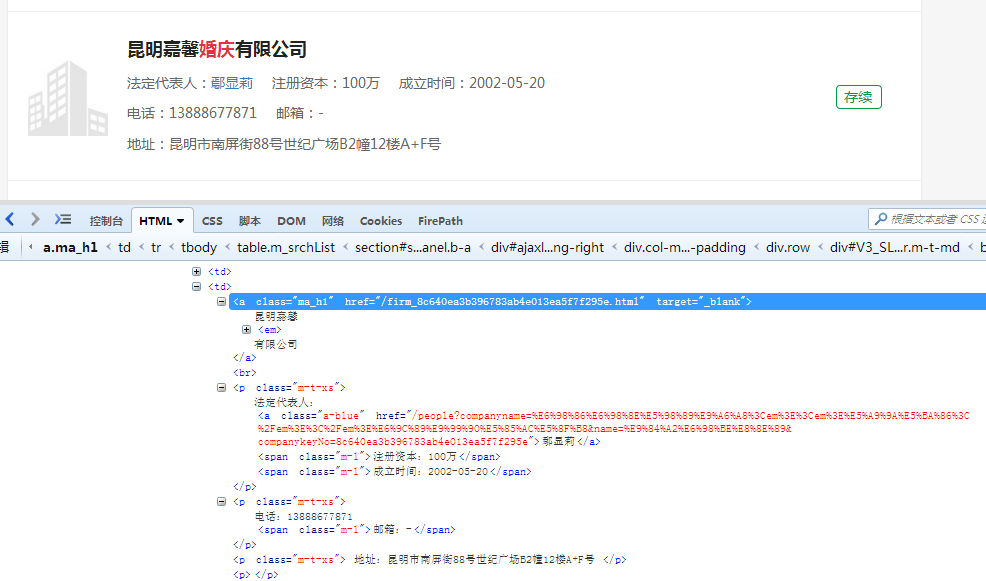
可以看到这些消息分别位于:
但是有一个巨大的问题摆在我们面前,企查查在点击搜索按钮后,虽然也能呈现部分资料,但是首当其冲的是一个登录页面,在没有登录前,我们实际上通过爬虫访问到的是仅有前五个公司信息+登录窗口的网页
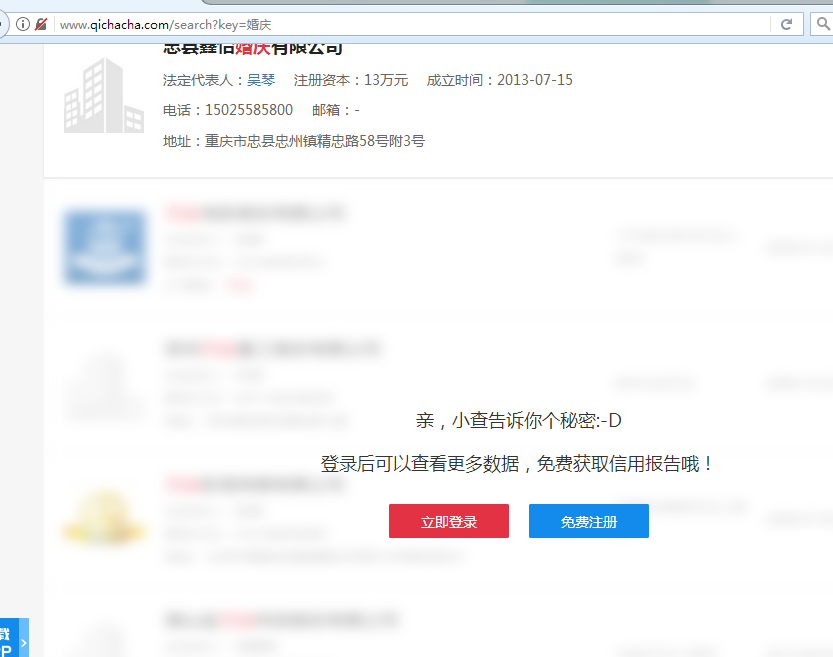
如果我们不处理这个登录页面,那么很抱歉,这次爬取到此结束了。
所以我们必须处理这个问题,首先需要在企查查上注册一个帐号,注册步骤略,一般可以通过
构造请求头,配置cookies
使用selenium
requests.post去递交用户名密码等
selenium模拟真实的浏览器去访问页面,但是其访问速度又慢,还要等加载完成,容易报错,直接放弃。
requests.post方法,这个可能可以,没仔细研究,因为企查查登录涉及三个选项,第一个是手机号,第二个是您的密码,第三个是一个滑块,滑块估计需要构造一个True或者什么东西吧。
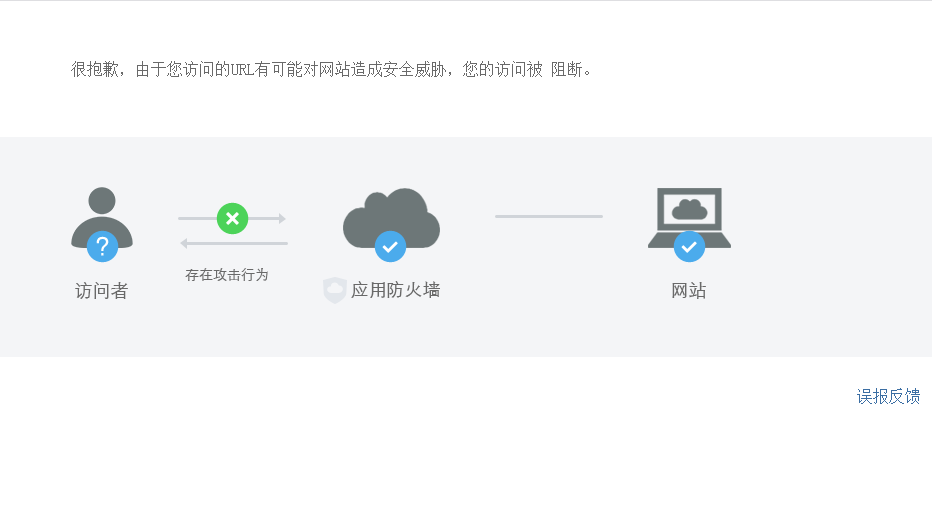
第一先想肯定是构造请求头,配置一个cookies。在这里我要说明自己犯的一个错误,User-Agent写成了User_agent,导致我的请求头是错误的,访问得到的是一个被防火墙拦截的网页页面,如下:
代码仅仅是输出soup,方便调试,请求状态是一个405错误,得到的页面如下:
这个错误也说明了请求头的重要性,这一般是服务器根据你的请求头来简单判断你是一个攻击者、爬虫,还是一个正常访问的人。所以干脆直接把请求头整个复制下来。
这边还有一点要注意,就是你使用的浏览器需打开COOKIES功能,而且关闭浏览器的时候不能自动或守清除cookies,否则都会导致只能得到前五个公司的信息,剩下的还是登陆消息。
直接上代码,一点点的记录:
首先我们引入requests、BeautifulSoup、lxml、xlwt四个模块。
简要说明一下四个模块:
requests是一个第三方模块,源码位于Github上,它相对于urrllib/httplib更加的人性化,一般推荐使用这个,requests具有多种请求方式。
BeautifulSoup这是一个可以从HTML或XML文件中提取数据的python库,它会把HTML转换成文档树,既然是树形结构,它必有节点概念,便于在爬虫中使用它的查找提取功能,它的这个功能一般有两种方法:一、find、find_all等方法;二、CSS选择器。
lxml模块,这是使用XPath技术查询和处理处理HTML/XML文档的库,只会局部遍历,所以速度会更快,占用的内存开销也会比较小。
xlwt模块,这是一个写成excel的模块,但是它只能重新生成一个excel,也就是说,如果在这个路径下,已经有这个excel了,那么就会直接覆盖掉这个excel,而且这个模块不支持读取。如果需要读取功能的可以用xlrd,而写入功能可以用xlutils模块配合着xlrd模块使用,具体我建议可以看看这篇博客《Python excel读写》
接下来就很简单了,定义函数,构造请求头,requests访问网页,如果请求相应码不是200,则输出对应的相应码以及‘ERROR’,用BeautifulSoup和lxml解析网页,从网页中选出所要的信息,定义6个全局变量列表,搜索到的数据通过列表的方法append加入列表。
通过不断的调用函数craw,不断的往list中添加数据,因为企查查非会员只能查看十页的数据,所以我们只需要重复十次即可,这边的range()有一个需要注意的地方,因为一般range都是从0开始循环的,但是网页的第一页就是1(比较网站的url,尤其是第一页的url和第二页的url更容易发现),所以如果我们需要循环十次,那么就需要从1开始,10是最后一次,11是截至,所以需要这么写:rang(1,11)。接下来的就是创建sheet对象,新建sheet,定义sheet的样式,然后通过for循环不断的往excel中存储数据,最后再通过方法save()保存到某个路径下。

代码基本上到这边结束了,爬取效果也还可以。之前只做了个半成品,只处理一页的数据,并没有完善整个功能,后续加了翻页,完善了存储功能。
今天这个小爬虫是应朋友,帮忙写的一个简单的爬虫,目的是爬取企查查这个网站的企业信息。
编程最终要的就是搭建编程环境,这里我们的编程环境是:
python3.6
BeautifulSoup模块
lxml模块
requests模块
xlwt模块
geany
首先分析需求网页的信息:
http://www.qichacha.com/search?key=婚庆
可以看到我们想要提取的消息内容有公司的名字,法定代表人,注册资本,成立时间,电话,邮箱,地址。好的,接下来我们打开firebug,查看各个内容在网页中的具体位置:
可以看到这些消息分别位于:
#公司名字------<a class="ma_h1" href="/firm_8c640ea3b396783ab4e013ea5f7f295e.html" target="_blank"> # 昆明嘉馨 # <em> # 有限公司 # </a> #法定代表人----<p class="m-t-xs"> # 法定代表人: # <a class="a-blue" href="********">鄢显莉</a> #注册资本---- <span class="m-l">注册资本:100万</span> #成立时间---- <span class="m-l">成立时间:2002-05-20</span> # </p> # <p class="m-t-xs"> #联系方式---- 电话:13888677871 #公司邮箱---- <span class="m-l">邮箱:-</span> # </p> #公司地址---- <p class="m-t-xs"> 地址:昆明市南屏街88号世纪广场B2幢12楼A+F号 </p> # <p></p>
但是有一个巨大的问题摆在我们面前,企查查在点击搜索按钮后,虽然也能呈现部分资料,但是首当其冲的是一个登录页面,在没有登录前,我们实际上通过爬虫访问到的是仅有前五个公司信息+登录窗口的网页
如果我们不处理这个登录页面,那么很抱歉,这次爬取到此结束了。
所以我们必须处理这个问题,首先需要在企查查上注册一个帐号,注册步骤略,一般可以通过
构造请求头,配置cookies
使用selenium
requests.post去递交用户名密码等
selenium模拟真实的浏览器去访问页面,但是其访问速度又慢,还要等加载完成,容易报错,直接放弃。
requests.post方法,这个可能可以,没仔细研究,因为企查查登录涉及三个选项,第一个是手机号,第二个是您的密码,第三个是一个滑块,滑块估计需要构造一个True或者什么东西吧。
第一先想肯定是构造请求头,配置一个cookies。在这里我要说明自己犯的一个错误,User-Agent写成了User_agent,导致我的请求头是错误的,访问得到的是一个被防火墙拦截的网页页面,如下:
#-*- coding-8 -*-
import requests
import lxml
from bs4 import BeautifulSoup
def craw(url):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers = {'User-Agent':user_agent,
}
response = requests.get(url,headers = headers)
if response.status_code != 200:
response.encoding = 'utf-8'
print(response.status_code)
print('ERROR')
soup = BeautifulSoup(response.text,'lxml')
print(soup)
if __name__ == '__main__':
url = r'http://www.qichacha.com/search?key=%E5%A9%9A%E5%BA%86'
s1 = craw(url)代码仅仅是输出soup,方便调试,请求状态是一个405错误,得到的页面如下:
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="utf-8"/>
<meta content="IE=edge,chrome=1" http-equiv="X-UA-Compatible"/>
<meta content="a3c0e" name="data-spm"/>
<title>405</title>
<style>
html, body, div, a, h2, p { margin: 0; padding: 0; font-family: 微软
雅黑; }
a { text-decoration: none; color: #3b6ea3; }
.container { width: 1000px; margin: auto; color: #696969; }
.header { padding: 50px 0; }
.header .message { height: 36px; padding-left: 120px; background: ur
l(https://errors.aliyun.com/images/TB1TpamHpXXXXaJXXXXeB7nYVXX-104-162.png) no-r
epeat 0 -128px; line-height: 36px; }
.main { padding: 50px 0; background: #f4f5f7; }
.main img { position: relative; left: 120px; }
.footer { margin-top: 30px; text-align: right; }
.footer a { padding: 8px 30px; border-radius: 10px; border: 1px soli
d #4babec; }
.footer a:hover { opacity: .8; }
.alert-shadow { display: none; position: absolute; top: 0; left: 0;
width: 100%; height: 100%; background: #999; opacity: .5; }
.alert { display: none; position: absolute; top: 200px; left: 50%; w
idth: 600px; margin-left: -300px; padding-bottom: 25px; border: 1px solid #ddd;
box-shadow: 0 2px 2px 1px rgba(0, 0, 0, .1); background: #fff; font-size: 14px;
color: #696969; }
.alert h2 { margin: 0 2px; padding: 10px 15px 5px 15px; font-size:
14px; font-weight: normal; border-bottom: 1px solid #ddd; }
.alert a { display: block; position: absolute; right: 10px; top: 8px
; width: 30px; height: 20px; text-align: center; }
.alert p { padding: 20px 15px; }
</style>
</head>
<body data-spm="7663354">
<div data-spm="1998410538">
<div class="header">
<div class="container">
<div class="message">很抱歉,由于您访问的URL有可能对网站造成安全威胁,您的访问被
阻断。</div>
</div>
</div>
<div class="main">
<div class="container">
<img src="https://errors.aliyun.com/images/TB15QGaHpXXXXXOaXXXXia39XXX-660-117.p
ng"/>
</div>
</div>
<div class="footer">
<div class="container">
<a data-spm-click="gostr=/waf.123.123;locaid=d001;" href="javascript:;" id="repo
rt" target="_blank">误报反馈</a>
</div>
</div>
</div>
<div class="alert-shadow" id="alertShadow"></div>
<div class="alert" id="alertContainer">
<h2>提示:<a href="javascript:;" id="closeAlert" title="关闭">X</a></h2>
<p>感谢您的反馈,应用防火墙会尽快进行分析和确认。</p>
</div>
<script>
function show() {
var g = function(ele) { return document.getElementById(ele); };
var reportHandle = g('report');
var alertShadow = g('alertShadow');
var alertContainer = g('alertContainer');
var closeAlert = g('closeAlert');
var own = {};
own.report = function() {
// SPM
own.alert();
};
own.alert = function() {
alertShadow.style.display = 'block';
alertContainer.style.display = 'block';
};
own.close = function() {
alertShadow.style.display = 'none';
alertContainer.style.display = 'none';
};
};
</script>
<script charset="utf-8" src="https://errors.aliyun.com/error.js?s=3" type="text/
javascript"></script>
</body>
</html>这个错误也说明了请求头的重要性,这一般是服务器根据你的请求头来简单判断你是一个攻击者、爬虫,还是一个正常访问的人。所以干脆直接把请求头整个复制下来。
这边还有一点要注意,就是你使用的浏览器需打开COOKIES功能,而且关闭浏览器的时候不能自动或守清除cookies,否则都会导致只能得到前五个公司的信息,剩下的还是登陆消息。
直接上代码,一点点的记录:
#-*- coding-8 -*-
import requests
import lxml
from bs4 import BeautifulSoup
import xlwt
def craw(url):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers = {
'Host':'www.qichacha.com',
'User-Agent':r'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Accept':'*/*',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate',
'Referer':'http://www.qichacha.com/',
'Cookie':r'UM_distinctid***************',
'Connection':'keep-alive',
'If-Modified-Since':'Wed, 30 **********',
'If-None-Match':'"59*******"',
'Cache-Control':'max-age=0',
}
response = requests.get(url,headers = headers)
if response.status_code != 200:
response.encoding = 'utf-8'
print(response.status_code)
print('ERROR')
soup = BeautifulSoup(response.text,'lxml')
#print(soup)
com_names = soup.find_all(class_='ma_h1')
#print(com_names)
#com_name1 = com_names[1].get_text()
#print(com_name1)
peo_names = soup.find_all(class_='a-blue')
#print(peo_names)
peo_phones = soup.find_all(class_='m-t-xs')
#tags = peo_phones[4].find(text = True).strip()
#print(tags)
#tttt = peo_phones[0].contents[5].get_text()
#print (tttt)
#else_comtent = peo_phones[0].find(class_='m-l')
#print(else_comtent)
global com_name_list
global peo_name_list
global peo_phone_list
global com_place_list
global zhuceziben_list
global chenglishijian_list
print('开始爬取数据,请勿打开excel')
for i in range(0,len(com_names)):
n = 1+3*i
m = i+2*(i+1)
peo_phone = peo_phones
.find(text = True).strip()
com_place = peo_phones[m].find(text = True).strip()
zhuceziben = peo_phones[3*i].find(class_='m-l').get_text()
chenglishijian = peo_phones[3*i].contents[5].get_text()
peo_phone_list.append(peo_phone)
com_place_list.append(com_place)
zhuceziben_list.append(zhuceziben)
chenglishijian_list.append(chenglishijian)
for com_name,peo_name in zip(com_names,peo_names):
com_name = com_name.get_text()
peo_name = peo_name.get_text()
com_name_list.append(com_name)
peo_name_list.append(peo_name)
if __name__ == '__main__':
com_name_list = []
peo_name_list = []
peo_phone_list = []
com_place_list = []
zhuceziben_list = []
chenglishijian_list = []
key_word = input('请输入您想搜索的关键词:')
print('正在搜索,请稍后')
for x in range(1,11):
url = r'http://www.qichacha.com/search?key={}#p:{}&'.format(key_word,x)
s1 = craw(url)
workbook = xlwt.Workbook()
#创建sheet对象,新建sheet
sheet1 = workbook.add_sheet('xlwt', cell_overwrite_ok=True)
#---设置excel样式---
#初始化样式
style = xlwt.XFStyle()
#创建字体样式
font = xlwt.Font()
font.name = 'Times New Roman'
font.bold = True #加粗
#设置字体
style.font = font
#使用样式写入数据
# sheet.write(0, 1, "xxxxx", style)
print('正在存储数据,请勿打开excel')
#向sheet中写入数据
name_list = ['公司名字','法定代表人','联系方式','注册人资本','成立时间','公司地址']
for cc in range(0,len(name_list)):
sheet1.write(0,cc,name_list[cc],style)
for i in range(0,len(com_name_list)):
sheet1.write(i+1,0,com_name_list[i],style)#公司名字
sheet1.write(i+1,1,peo_name_list[i],style)#法定代表人
sheet1.write(i+1,2,peo_phone_list[i],style)#联系方式
sheet1.write(i+1,3,zhuceziben_list[i],style)#注册人资本
sheet1.write(i+1,4,chenglishijian_list[i],style)#成立时间
sheet1.write(i+1,5,com_place_list[i],style)#公司地址
#保存excel文件,有同名的直接覆盖
workbook.save(r'F:\work\2017_08_02\xlwt.xls')
print('the excel save success')首先我们引入requests、BeautifulSoup、lxml、xlwt四个模块。
#-*- coding-8 -*- import requests import lxml from bs4 import BeautifulSoup import xlwt
简要说明一下四个模块:
requests是一个第三方模块,源码位于Github上,它相对于urrllib/httplib更加的人性化,一般推荐使用这个,requests具有多种请求方式。
import requests
r1 = requests.get(r'http://www.baidu.com')
postdata = {'key':'value'}
r2 = requests.post(r'http://www.xxx.com/login',data=postdata)
r3 = requests.put(r'http://www.xxx.com/put',data={'key':'value'})
r4 = requests.delete(r'http://www.xxx.com/delete')
r5 = requests.head(r'http://www.xxx.com/get')
r6 = requests.options(r'http://www.xxx.com/get') 还要说明一点,就是其响应编码:import requests r = requests.get(r'http://www.baidu.com') print(r.content)#返回的是字节形式 print(r.text)#返回的是文本形式 print(r.encoding)#根据HTTP头猜测的网页编码格式,可以直接赋值修改更多的requests后续找个机会补充。
BeautifulSoup这是一个可以从HTML或XML文件中提取数据的python库,它会把HTML转换成文档树,既然是树形结构,它必有节点概念,便于在爬虫中使用它的查找提取功能,它的这个功能一般有两种方法:一、find、find_all等方法;二、CSS选择器。
lxml模块,这是使用XPath技术查询和处理处理HTML/XML文档的库,只会局部遍历,所以速度会更快,占用的内存开销也会比较小。
xlwt模块,这是一个写成excel的模块,但是它只能重新生成一个excel,也就是说,如果在这个路径下,已经有这个excel了,那么就会直接覆盖掉这个excel,而且这个模块不支持读取。如果需要读取功能的可以用xlrd,而写入功能可以用xlutils模块配合着xlrd模块使用,具体我建议可以看看这篇博客《Python excel读写》
接下来就很简单了,定义函数,构造请求头,requests访问网页,如果请求相应码不是200,则输出对应的相应码以及‘ERROR’,用BeautifulSoup和lxml解析网页,从网页中选出所要的信息,定义6个全局变量列表,搜索到的数据通过列表的方法append加入列表。
def craw(url):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers = {
'Host':'www.qichacha.com',
'User-Agent':r'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Accept':'*/*',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate',
'Referer':'http://www.qichacha.com/',
'Cookie':r'UM_di**********1',
'Connection':'keep-alive',
'If-Modified-Since':'Wed, *********',
'If-None-Match':'"59****"',
'Cache-Control':'max-age=0',
}
response = requests.get(url,headers = headers)
if response.status_code != 200:
response.encoding = 'utf-8'
print(response.status_code)
print('ERROR')
soup = BeautifulSoup(response.text,'lxml')
#print(soup)
com_names = soup.find_all(class_='ma_h1')
#print(com_names)
#com_name1 = com_names[1].get_text()
#print(com_name1)
peo_names = soup.find_all(class_='a-blue')
#print(peo_names)
peo_phones = soup.find_all(class_='m-t-xs')
#tags = peo_phones[4].find(text = True).strip()
#print(tags)
#tttt = peo_phones[0].contents[5].get_text()
#print (tttt)
#else_comtent = peo_phones[0].find(class_='m-l')
#print(else_comtent)
global com_name_list
global peo_name_list
global peo_phone_list
global com_place_list
global zhuceziben_list
global chenglishijian_list
print('开始爬取数据,请勿打开excel')
for i in range(0,len(com_names)):
n = 1+3*i
m = i+2*(i+1)
peo_phone = peo_phones
.find(text = True).strip()
com_place = peo_phones[m].find(text = True).strip()
zhuceziben = peo_phones[3*i].find(class_='m-l').get_text()
chenglishijian = peo_phones[3*i].contents[5].get_text()
peo_phone_list.append(peo_phone)
com_place_list.append(com_place)
zhuceziben_list.append(zhuceziben)
chenglishijian_list.append(chenglishijian)
for com_name,peo_name in zip(com_names,peo_names):
com_name = com_name.get_text()
peo_name = peo_name.get_text()
com_name_list.append(com_name)
peo_name_list.append(peo_name)通过不断的调用函数craw,不断的往list中添加数据,因为企查查非会员只能查看十页的数据,所以我们只需要重复十次即可,这边的range()有一个需要注意的地方,因为一般range都是从0开始循环的,但是网页的第一页就是1(比较网站的url,尤其是第一页的url和第二页的url更容易发现),所以如果我们需要循环十次,那么就需要从1开始,10是最后一次,11是截至,所以需要这么写:rang(1,11)。接下来的就是创建sheet对象,新建sheet,定义sheet的样式,然后通过for循环不断的往excel中存储数据,最后再通过方法save()保存到某个路径下。
if __name__ == '__main__':
com_name_list = []
peo_name_list = []
peo_phone_list = []
com_place_list = []
zhuceziben_list = []
chenglishijian_list = []
key_word = input('请输入您想搜索的关键词:')
print('正在搜索,请稍后')
for x in range(1,11):
url = r'http://www.qichacha.com/search?key={}#p:{}&'.format(key_word,x)
s1 = craw(url)
workbook = xlwt.Workbook()
#创建sheet对象,新建sheet
sheet1 = workbook.add_sheet('xlwt', cell_overwrite_ok=True)
#---设置excel样式---
#初始化样式
style = xlwt.XFStyle()
#创建字体样式
font = xlwt.Font()
font.name = 'Times New Roman'
font.bold = True #加粗
#设置字体
style.font = font
#使用样式写入数据
# sheet.write(0, 1, "xxxxx", style)
print('正在存储数据,请勿打开excel')
#向sheet中写入数据
name_list = ['公司名字','法定代表人','联系方式','注册人资本','成立时间','公司地址']
for cc in range(0,len(name_list)):
sheet1.write(0,cc,name_list[cc],style)
for i in range(0,len(com_name_list)):
sheet1.write(i+1,0,com_name_list[i],style)#公司名字
sheet1.write(i+1,1,peo_name_list[i],style)#法定代表人
sheet1.write(i+1,2,peo_phone_list[i],style)#联系方式
sheet1.write(i+1,3,zhuceziben_list[i],style)#注册人资本
sheet1.write(i+1,4,chenglishijian_list[i],style)#成立时间
sheet1.write(i+1,5,com_place_list[i],style)#公司地址
#保存excel文件,有同名的直接覆盖
workbook.save(r'F:\work\2017_08_02\xlwt.xls')
print('the excel save success')代码基本上到这边结束了,爬取效果也还可以。之前只做了个半成品,只处理一页的数据,并没有完善整个功能,后续加了翻页,完善了存储功能。

相关文章推荐
- 简单Python脚本实现数据导出Excel格式的尝试
- Python利用系统命令获取文件(夹)信息以及Python对Excel的简单操作
- python脚本实现数据导出excel格式的简单方法(推荐)
- 简单Python脚本实现数据导出Excel格式的尝试
- python3爬取拉勾网招聘信息存为excel格式
- CSDN上面的一段导出Excel格式文件的存储过程
- python下学生管理系统:从文件中读取30位学生的信息(含邮箱),并实现简单的增、删、查找、统计(邮箱使用人数)。---附程序哦!
- 1.读取excel文件,将输入存储到数据库中(JXL) 2.完成商品的检索相关功能 1.根据分类,显示分类下所有的商品信息,按照库存量从低到高排序(提供补货依据) 2.模糊搜索,根据商品信息(名
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
- 导入Excel至数据库中 "外部表不是预期格式"错误信息
- Python学习1(环境搭建、文件格式与简单编程)
- 使用shell和python分别实现简单菜单功能--打印当前系统状态信息
- 利用python进行数据分析-数据加载、存储与文件格式2
- 将Excel中存储为文本的数字转换为数字格式
- 用python读取json格式内容并保存到excel中
- python抓取招聘信息简单代码
- [Python学习] 简单爬取CSDN下载资源信息
- 举例简单讲解Python中的数据存储模块shelve的用法
- python 使用列表和字典存储信息
- 怎么将word转换成excel表格格式最简单