自然语言处理扫盲·第二天——白话机器翻译原理
2017-09-07 11:37
225 查看
由于最近要做一些自然语言处理的分享,但是我又不是科班出身,所以只能临时抱佛脚的学习以下基本的原理。但是由于底子很薄,所以只能凭借google和baidu有限的资料进行总结。这里不会看到太复杂的公式,因为公式层面我也理解不了....就当做是从0学习自然语言处理的过程的记录吧!
更多内容参考:
自然语言处理扫盲·第一天——自然语言处理的背景、应用、推荐资料
这个方向在几个大厂应该都比较成熟了,比如有道翻译、百度翻译、Google翻译等等。我平时用的有道比较多,一般都是去翻译个英文文档之类的。因为有道做的词典比较专业,因此在英译汉或者汉译英的时候认可度能高点。
我们先来看看机器翻译是怎么被玩坏的吧!
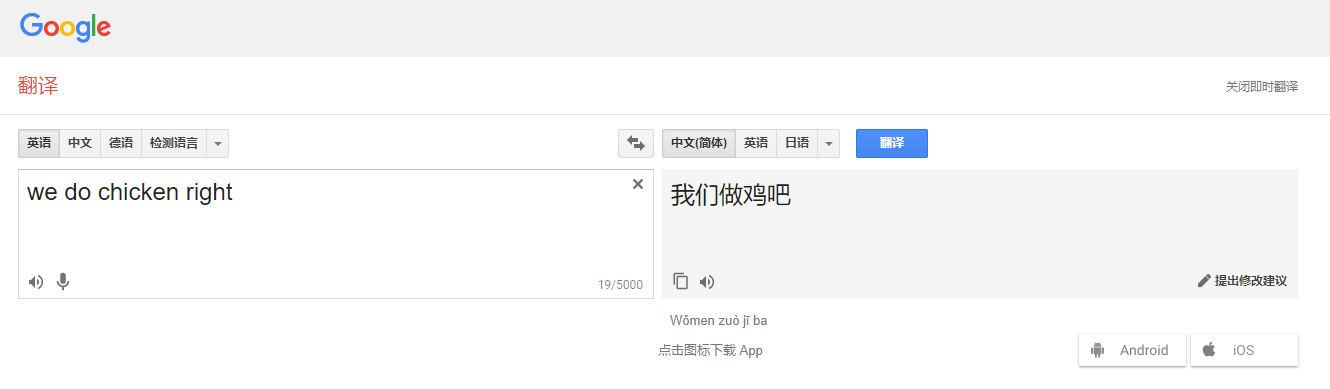
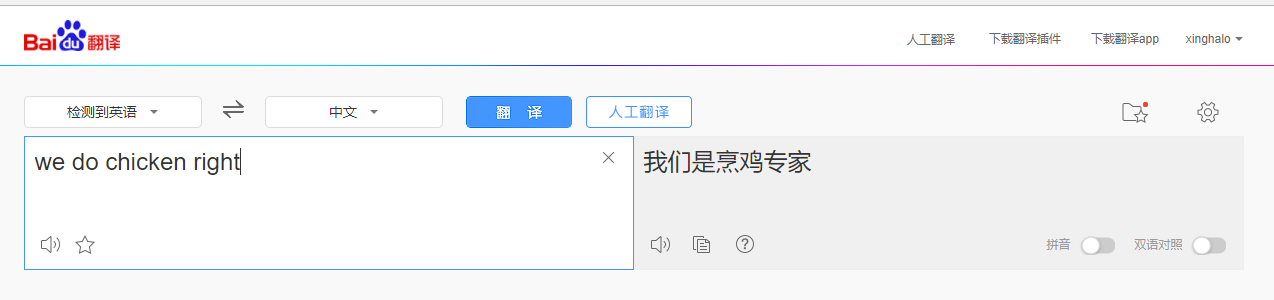
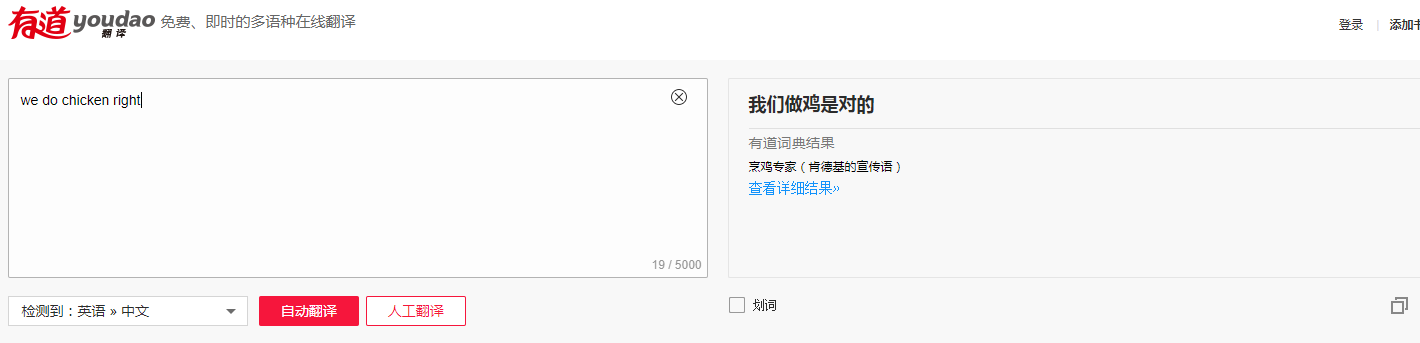
PS: 这个梗真的不是我黑谁!我也是从PPT上面看到的,觉得这个例子很不错.....
话说回来,在机器翻译的领域,有很多难点。比如,语言的复杂程度,上下文的关联等等。想想看,同样是汉语,山东大汉和陕西小哥以及东北姑娘说出来的都是不一样的;再想想汉语中的博大精深,同样一段话,上下文不同表达的含义也是不一样的;再复杂点,涉及到两种语言的切换,就更恐怖了。
目前业内主要的实现手段有基于规则的、基于实例的、基于统计的以及基于神经网络的,看着感觉蒙蒙哒,我们来具体的了解下吧:

根据翻译的方式可以分为:
直接基于词的翻译
结构转换的翻译
中间语的翻译
从字面上理解,基于词的翻译就是直接把词进行翻译,但是也不是这么简单,会通过一些词性的变换、专业词汇的变换、位置的调整等一些规则,进行修饰。
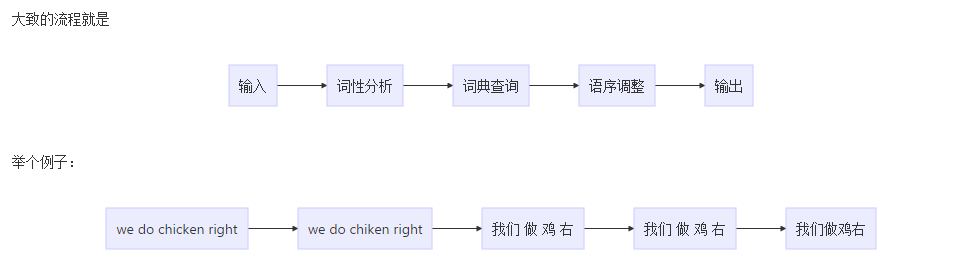
可以看到翻译的质量很差,但是基于这种词规则的翻译,基本上可以辅助我们做一些翻译的工作;而且这种翻译也带来了机器翻译的0到1的飞跃
那么基于结构转换 其实就是不仅仅考虑单个词,而是考虑到短语的级别。比如根据端与
最后一种就是基于中间语的翻译,比如过去在金本位的年代,各国都有自己的货币。中国使用中国的货币,美国使用美国的货币,那么货币之间怎么等价呢?就可以兑换成黄金来衡量价值。这样就可以进行跨币种的买卖了..翻译也是如此,倘若由两种语言无法直译,那么也可以先翻译成中间语,然后通过中间语进行两种语言的翻译。
首先,我们有一段英文想要把它翻译成汉语:
会根据每个词或者短语,罗列它可能出现的翻译结果:
这样的结果有很多种...
然后我们需要一个大量的语料库,即有大量的文章...这些文章会提供 每一种翻译结果出现的概率,概率的计算方式可能是使用隐马尔可夫模型,即自己算相邻词的概率,这个原理在《数学之美》中有介绍,感兴趣的可以去看看。
最终挑选概率最高的翻译结果作为最终的输出。
总结来说大致的流程是:

因此可以看到,这种翻译方式依赖大量的语料库,因此大多数使用这种方式而且效果比较好的都是那种搜索引擎公司,比如Google和Baidu,他们依赖爬虫技术有互联网中大量的文本资料,基于这些文本资料可以获取大量的语料来源,从而为自己的翻译提供大量的依据数据。
就可以抽取他们相似的部分,直接替换不一样的地方的词汇就行。这种翻译其实效果不太好,而且太偏领域背景...

基本的意思就是我们会有很多的输入,这些输入经过一些中间处理,得到输出。得到的输出又可以作为下一个计算过程的输入...这样就组成了神经网络。
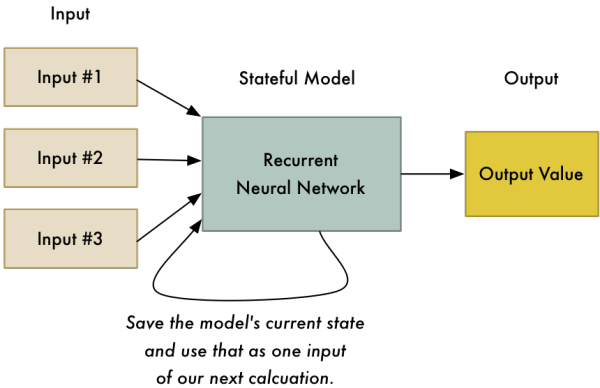
在机器翻译中主要使用的是循环神经网络,即上一次的输出可以作为这次的输入继续参与计算。这样有什么目的呢?
就是在翻译的过程中,虽然是以句子为单位进行翻译的,但是每一句话都会对下一句话的翻译产生影响,这样就做出了上下文的感觉....比如
这种操作模式,在问答系统中也会遇到...之后会有所介绍.
针对机器翻译是否能代替人工翻译,知乎上面也有不少讨论,我这个门外汉也觉得,暂时不太可能,不过机器翻译作为人工翻译的一种辅助手段还是很必要的。比如那些非专业的翻译人士,如写论文的研究生、看前沿技术的程序员小朋友,这种机器翻译可以作为一种很有效的阅读辅助的手段,因为大部分的时候,都是直接把某一段英文粘贴到翻译的输入框,然后按照翻译出来的结果,自己再组织理解...(我想大部分人都是这么用的吧~ 原谅我英语差)

那么机器翻译的扫盲就暂时介绍到这里了,之后会再研究下情感分析相关的内容...
基于统计的机器翻译:https://wenku.baidu.com/view/8ca60c966137ee06eff918fc.html
机器翻译的流程(原理)是怎么样的?:https://www.zhihu.com/question/24588198
自然语言处理为什么从规则转到统计的方法?:https://www.zhihu.com/question/30748126
更多内容参考:
自然语言处理扫盲·第一天——自然语言处理的背景、应用、推荐资料
如果有哪里说的不对的,还请严厉指正,小博主一定虚心领教,仔细研究!以免误导大众...
下面就步入正题吧!这个方向在几个大厂应该都比较成熟了,比如有道翻译、百度翻译、Google翻译等等。我平时用的有道比较多,一般都是去翻译个英文文档之类的。因为有道做的词典比较专业,因此在英译汉或者汉译英的时候认可度能高点。
我们先来看看机器翻译是怎么被玩坏的吧!
PS: 这个梗真的不是我黑谁!我也是从PPT上面看到的,觉得这个例子很不错.....
话说回来,在机器翻译的领域,有很多难点。比如,语言的复杂程度,上下文的关联等等。想想看,同样是汉语,山东大汉和陕西小哥以及东北姑娘说出来的都是不一样的;再想想汉语中的博大精深,同样一段话,上下文不同表达的含义也是不一样的;再复杂点,涉及到两种语言的切换,就更恐怖了。
目前业内主要的实现手段有基于规则的、基于实例的、基于统计的以及基于神经网络的,看着感觉蒙蒙哒,我们来具体的了解下吧:
基于规则的机器翻译
基于规则的机器翻译,是最古老也是见效最快的一种翻译方式。根据翻译的方式可以分为:
直接基于词的翻译
结构转换的翻译
中间语的翻译
从字面上理解,基于词的翻译就是直接把词进行翻译,但是也不是这么简单,会通过一些词性的变换、专业词汇的变换、位置的调整等一些规则,进行修饰。
可以看到翻译的质量很差,但是基于这种词规则的翻译,基本上可以辅助我们做一些翻译的工作;而且这种翻译也带来了机器翻译的0到1的飞跃
那么基于结构转换 其实就是不仅仅考虑单个词,而是考虑到短语的级别。比如根据端与
do chicken有可能被翻译成
烹饪鸡,那么整句话就好多了
我们烹饪鸡好吗
最后一种就是基于中间语的翻译,比如过去在金本位的年代,各国都有自己的货币。中国使用中国的货币,美国使用美国的货币,那么货币之间怎么等价呢?就可以兑换成黄金来衡量价值。这样就可以进行跨币种的买卖了..翻译也是如此,倘若由两种语言无法直译,那么也可以先翻译成中间语,然后通过中间语进行两种语言的翻译。
基于统计的机器翻译
基于统计的机器翻译明显要比基于规则的高级的多,因为引入了一些数学的方法,总体上显得更加专业。那么我们看看它是怎么做的吧!首先,我们有一段英文想要把它翻译成汉语:
we do chicken right
会根据每个词或者短语,罗列它可能出现的翻译结果:
我们/做/鸡/右 我们/做/鸡/好吗 我们/干/鸡/怎么样 ...
这样的结果有很多种...
然后我们需要一个大量的语料库,即有大量的文章...这些文章会提供 每一种翻译结果出现的概率,概率的计算方式可能是使用隐马尔可夫模型,即自己算相邻词的概率,这个原理在《数学之美》中有介绍,感兴趣的可以去看看。
最终挑选概率最高的翻译结果作为最终的输出。
总结来说大致的流程是:
因此可以看到,这种翻译方式依赖大量的语料库,因此大多数使用这种方式而且效果比较好的都是那种搜索引擎公司,比如Google和Baidu,他们依赖爬虫技术有互联网中大量的文本资料,基于这些文本资料可以获取大量的语料来源,从而为自己的翻译提供大量的依据数据。
基于实例的机器翻译
这种翻译也比较常见,通俗点说就是抽取句子的模式,当你输入一句话想要翻译的时候,会搜索相类似的语句,然后替换不一样的词汇翻译。举个例子:I gave zhangsan a pen I gave lisi a apple
就可以抽取他们相似的部分,直接替换不一样的地方的词汇就行。这种翻译其实效果不太好,而且太偏领域背景...
基于神经网络的机器翻译
在深度学习火起来后,这种方式越来越受关注。我们先来了解下什么是神经网络:基本的意思就是我们会有很多的输入,这些输入经过一些中间处理,得到输出。得到的输出又可以作为下一个计算过程的输入...这样就组成了神经网络。
在机器翻译中主要使用的是循环神经网络,即上一次的输出可以作为这次的输入继续参与计算。这样有什么目的呢?
就是在翻译的过程中,虽然是以句子为单位进行翻译的,但是每一句话都会对下一句话的翻译产生影响,这样就做出了上下文的感觉....比如
do chicken单纯的翻译有很多中翻译的结果。但是如果前面出现过厨师等这类的词句,那么这个单词就可以更倾向翻译成
烹饪鸡。
这种操作模式,在问答系统中也会遇到...之后会有所介绍.
总结
总结的来说,如果想要快速搭建一个机器翻译的系统,可以先从基于规则开始,添加一些领域背景的知识,就能达到一个比较快速的效果。而基于统计的方法从数据获取的成本和模型的训练来说,成本都很高...针对机器翻译是否能代替人工翻译,知乎上面也有不少讨论,我这个门外汉也觉得,暂时不太可能,不过机器翻译作为人工翻译的一种辅助手段还是很必要的。比如那些非专业的翻译人士,如写论文的研究生、看前沿技术的程序员小朋友,这种机器翻译可以作为一种很有效的阅读辅助的手段,因为大部分的时候,都是直接把某一段英文粘贴到翻译的输入框,然后按照翻译出来的结果,自己再组织理解...(我想大部分人都是这么用的吧~ 原谅我英语差)
那么机器翻译的扫盲就暂时介绍到这里了,之后会再研究下情感分析相关的内容...
参考
基于规则的机器翻译系统:https://wenku.baidu.com/view/50c979165901020207409c3a.html基于统计的机器翻译:https://wenku.baidu.com/view/8ca60c966137ee06eff918fc.html
机器翻译的流程(原理)是怎么样的?:https://www.zhihu.com/question/24588198
自然语言处理为什么从规则转到统计的方法?:https://www.zhihu.com/question/30748126

相关文章推荐
- 自然语言处理扫盲·第二天——白话机器翻译原理
- 自然语言处理扫盲·第二天——白话机器翻译原理
- 自然语言处理入门——白话机器翻译原理
- 自然语言处理扫盲·第四天——白话人机问答系统原理
- 机器翻译需要的软件 自然语言处理专业所涉及的软件
- NLP汉语自然语言处理原理与实践 1 中文语言的机器处理
- 自然语言处理入门——白话情感分析原理
- 微软所谓的"无人工介入的自动的机器翻译系统"
- 决策树(DecisionTree)的白话原理和简单应用
- 机器翻译系统的搭建
- [计算机英语每日翻译] The Linux Kernel (LInux内核原理解析)1
- 机器视觉-结构光测量之三角测量原理
- [计算机英语每日翻译] The Linux Kernel (LInux内核原理解析)2
- 关于注意力机制(attention mechanism)在神经机器翻译领域的两篇论文的理解
- NOIP2010 机器翻译
- 机器翻译重要过程(3)---抽取短语
- 论文BigTable-Google's BigTable 原理 (翻译)
- 黑马程序员——C语言之机器数真值、原反补码、位运算与变量地址获取及输出原理
- 机器学习数学原理(5)——广泛拉格朗日乘子法
- 机器学习笔记:朴素贝叶斯方法(Naive Bayes)原理和实现