C++学习笔记10 各种各样的排序算法复杂度
2017-09-06 10:59
302 查看
各种排序的复杂度
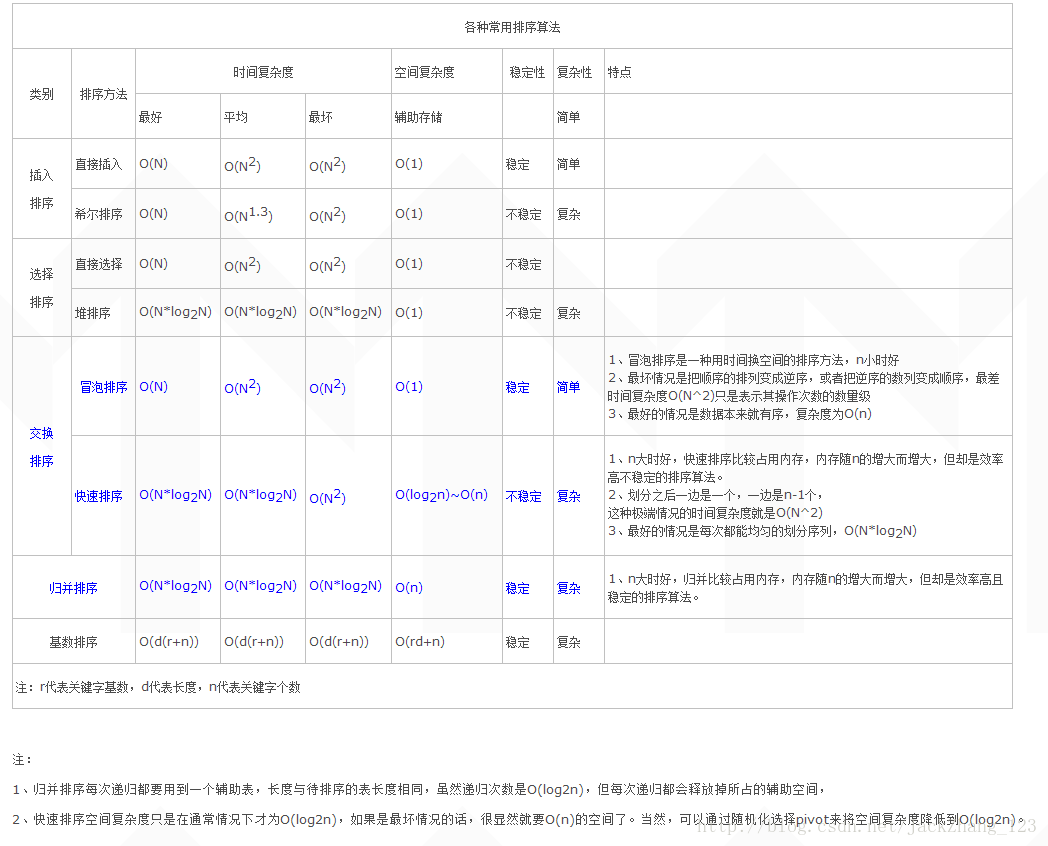
C++中的qsort()采用的是快排算法,C++的sort()则是改进的快排算法。两者的时间复杂度都是nlogn,但是实际应用中,sort()一般要快些,建议使用sort()。
插入排序、冒泡排序、归并排序和基数排序是稳定的,其余的比如希尔排序、选择排序、堆排序、快速排序都是不稳定的。
插入排序 (Insertion Sort): 插入排序的基本思想是,经过i-1遍处理后,L[1..i-1]己排好序。第i遍处理仅将L[i]插入L[1..i-1]的适当位置,使得L[1..i] 又是排好序的序列。要达到这个目的,我们可以用顺序比较的方法。首先比较L[i]和L[i-1],如果L[i-1]≤ L[i],则L[1..i]已排好序,第i遍处理就结束了;否则交换L[i]与L[i-1]的位置,继续比较L[i-1]和L[i-2],直到找到某一个位置j(1≤j≤i-1),使得L[j] ≤L[j+1]时为止。
希尔排序(Shell Sort): 在直接插入排序算法中,每次插入一个数,使有序序列只增加1个节点,并且对插入下一个数没有提供任何帮助。如果比较相隔较远距离(称为 增量)的数,使得数移动时能跨过多个元素,则进行一次比较就可能消除多个元素交换。算法先将要排序的一组数按某个增量d分成若干组,每组中记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量对它进行,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
选择排序(Selection Sort): 选择排序的基本思想是对待排序的记录序列进行n-1遍的处理,第i遍处理是将L[i..n]中最小者与L[i]交换位置。这样,经过i遍处理之后,前i个记录的位置已经是正确的了。
堆排序(Heap Sort) :堆排序是一种树形选择排序,在排序过程中,将A
看成是完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系来选择最小的元素。
快速排序(Quick Sort) :快速排序通过一趟扫描,就能确保某个数(以它为基准点吧)的左边各数都比它小,右边各数都比它大。然后又用同样的方法处理它左右两边的数,直到基准点的左右只有一个元素为止。 快速排序是不稳定的,最理想情况算法时间复杂度O(nlog2n),最坏O(n ^2)。
归并排序 (Merge Sort):设有两个有序(升序)序列存储在同一数组中相邻的位置上,不妨设为A[l..m],A[m+1..h],将它们归并为一个有序数列,并存储在A[l..h]。其时间复杂度无论是在最好情况下还是在最坏情况下均是O(nlog2n)。

相关文章推荐
- C++ 学习笔记(10)泛型算法、lambda表达式、bind函数、迭代器
- C++学习笔记26——泛型算法之容器元素排序(sort unique)
- C++学习笔记10:返回对象
- C++学习笔记(10)——虚基类的作用
- [学习笔记]排序算法之冒泡排序
- 【iOS学习笔记】iOS算法(二)之选择排序
- 算法学习笔记之插入排序
- [算法学习笔记]排序——插入排序
- C++学习笔记10-面向对象
- 数据结构&算法学习笔记: 快速排序
- 黑马程序员—Java基础学习笔记之排序算法:选择排序&冒泡排序
- 【C++学习笔记】10_C风格字符串
- c++ 模板学习笔记:函数模板实现数组通用排序和遍历打印(权哥)
- 麻省理工算法导论学习笔记(5)----线性时间排序
- c++学习笔记-----qsort通用排序函数
- 8大内部排序算法学习笔记--(4)归并、基数排序 Java实现
- 算法学习笔记--排序(简介)
- python学习笔记-Day027 - 算法的复杂度
- C++学习笔记:C++排序函数
- 算法学习笔记之排序--基于指针的插入排序