一次一波三折的SQL优化经历
2017-09-04 14:09
134 查看
一次一波三折的SQL优化经历
背景
最近收到一个SQL调优任务,该SQL在开发环境统计一个月的数据将近执行5秒。原本以为是一场波澜不惊的调优,没想到为了得到最优结果,经历了一波三折。第一印象
初见慢SQLselect case when sum(n_xsajs) is null then 0 else sum(n_xsajs) end as value ,ay.c_aymc as name,ay.c_aydm as id, case when tbdata.tb is null then 0 else round( cast ( sum(n_xsajs) - tbdata.tb as numeric )/ cast( tbdata.tb as numeric),2)*100 end as tb, case when sum(n_xsajs) < tbdata.tb then -1 when sum(n_xsajs) > tbdata.tb then 1 else 0 end as tbTag, case when hbdata.hb is null then 0 else round( cast ( sum(n_xsajs) - hbdata.hb as numeric )/ cast( hbdata.hb as numeric),2)*100 end as hb, case when sum(n_xsajs) < hbdata.hb then -1 when sum(n_xsajs) > hbdata.hb then 1 else 0 end as hbTag from db_zntsfx.t_xsaj_ay aj right join ( select c_aydm,c_aymc from db_zntsfx.d_ay ay WHERE ay.c_aylb = '14' ) ay on aj.c_aydm = ay.c_aydm left join ( select sum(n_xsajs) tb,ay.c_aydm from db_zntsfx.t_xsaj_ay aj right join ( select c_aydm,c_aymc from db_zntsfx.d_ay ay WHERE ay.c_aylb = '14' ) ay on aj.c_aydm = ay.c_aydm and substr(aj.c_fydm,0,2)= '3' and aj.c_tjq >= '201608' and aj.c_tjq <= '201608' GROUP BY ay.c_aymc,ay.c_aydm ) tbdata on aj.c_aydm = tbdata.c_aydm left join ( select sum(n_xsajs) hb,ay.c_aydm from db_zntsfx.t_xsaj_ay aj right join ( select c_aydm,c_aymc from db_zntsfx.d_ay ay WHERE ay.c_aylb = '14' ) ay on aj.c_aydm = ay.c_aydm and substr(aj.c_fydm,0,2) = '3' and aj.c_tjq >= '201707' and aj.c_tjq <= '201707' GROUP BY ay.c_aymc,ay.c_aydm ) hbdata on aj.c_aydm = hbdata.c_aydm and substr(aj.c_fydm,0,2) = '3' and aj.c_tjq >= '201708' and aj.c_tjq <= '201708' GROUP BY ay.c_aymc,ay.c_aydm,tbdata.tb,hbdata.hb limit 17 offset 1
原来的慢SQL是经过初步格式化。
但是还要进行手动格式化,原因有三点:
原来格式化的SQL层次依然不清晰
手动格式化的过程是理解SQL业务含义的过程
工具自动的格式化只是按照关键字进行缩进,不利于展现SQL层次
SQL格式化后
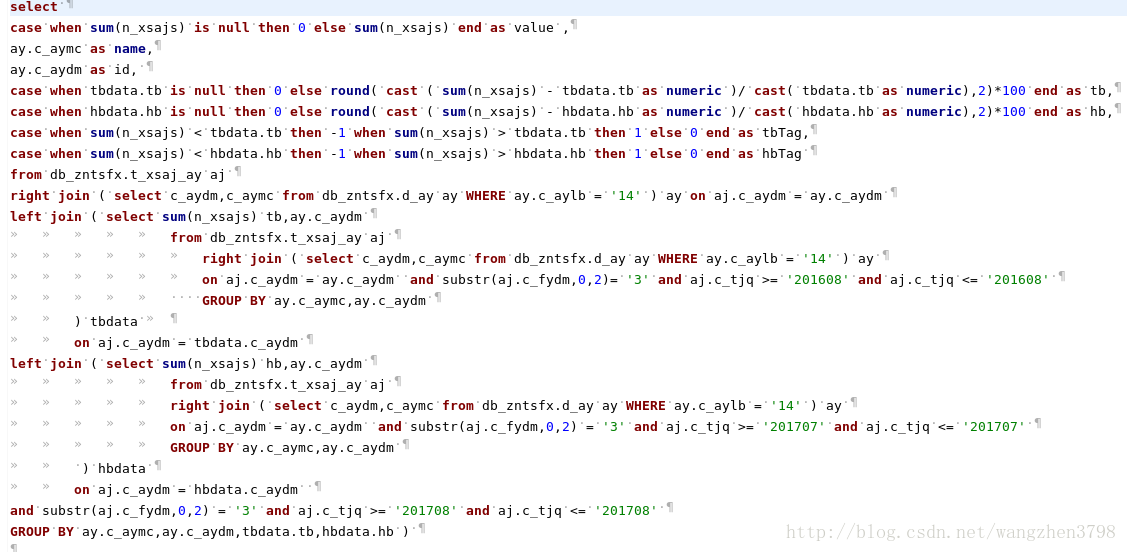
格式化后可以清晰的看出SQL的业务是“统计8月份案由类型14的新收刑事案件数和同比环比数据”
SQL主要的问题:
执行速度慢,开发环境4秒。
SQL体大量重复,重复的子查询和group by。
索引列上使用函数, substr(aj.c_fydm,0,2) = ‘3’。
SQL统计结果是错误的,按照案由聚集后案由是重复的。
--验证SQL select t.id,t.name,count 4000 (*) from ( --原SQL ) t group by t.id,t.name having count(*)>1
验证结果:
| id | name | count |
|---|---|---|
| 0E0401540000 | 农村土地承包合同纠纷 | 2 |
| 0E1014000000 | 第三人撤销之诉 | 2 |
| 0E0601010500 | 追索劳动报酬纠纷 | 2 |
| 0E1003010000 | 申请宣告公民无民事行为能力 | 2 |
| 0E0901000000 | 侵权责任纠纷 | 2 |
| 0E0401551500 | 物业服务合同纠纷 | 2 |
| 0E0802080000 | 股权转让纠纷 | 2 |
| 0E0201030000 | 离婚后财产纠纷 | 2 |
| 0E0201020000 | 离婚纠纷 | 2 |
| 0E1013010000 | 案外人执行异议之诉 | 2 |
| 0E0401350900 | 农村建房施工合同纠纷 | 2 |
第一次调优
查看数据库版本db_zntsfx=# select version(); version --------------------------------------------------------------------------------------------------- PostgreSQL 9.5.4 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.4.7 20120313 (Red Hat 4.4.7-16), 64-bit (1 row)
with语句改写SQL,因为采用的是abase3.5.3,所以想尝试使用with语法解决SQL结构体重复的问题。
改写后的SQL

查看执行计划和速度
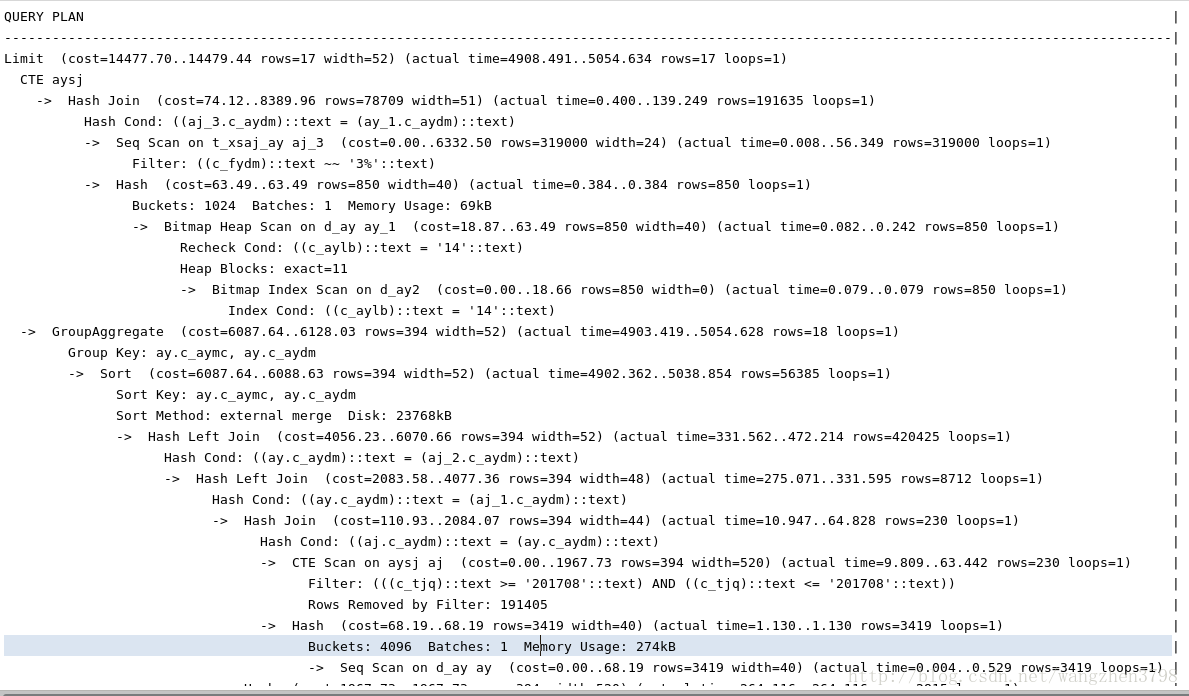
结果
1.SQL语句结构依然不清晰,复杂度和原来差不多。
2.SQL 运行速度比原来还慢,将近6秒。主要原因with 语句的结果集合不能按照月份过滤,后续进行运算结果集太大。
第二次调优
重新改写SQL
查看执行计划
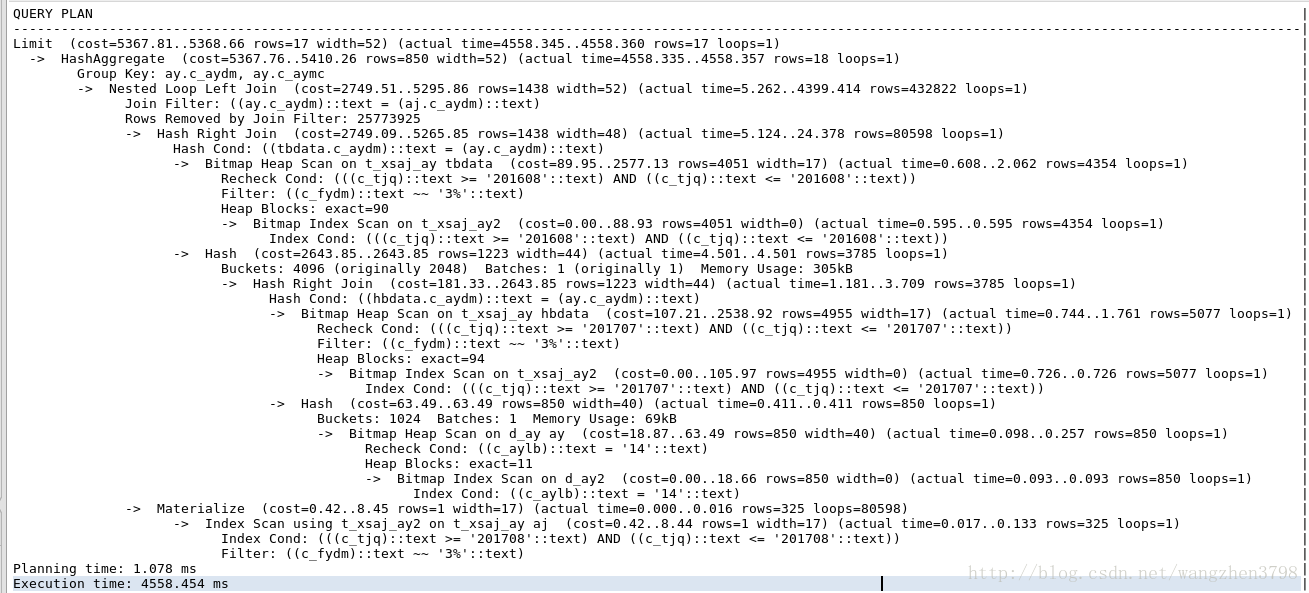
结果
SQL语句的层次清晰很多,执行速度和原来相同。
根据《数据库选择索引探索一》,组合或覆盖索引会加快SQL执行速度,添加覆盖索引。
create index i_ay_zh01 on db_zntsfx.d_ay(c_aydm, c_aymc); create index i_xsay_zh01 on db_zntsfx.t_xsaj_ay(c_aydm, c_tjq, c_fydm, n_xsajs);
再看执行计划
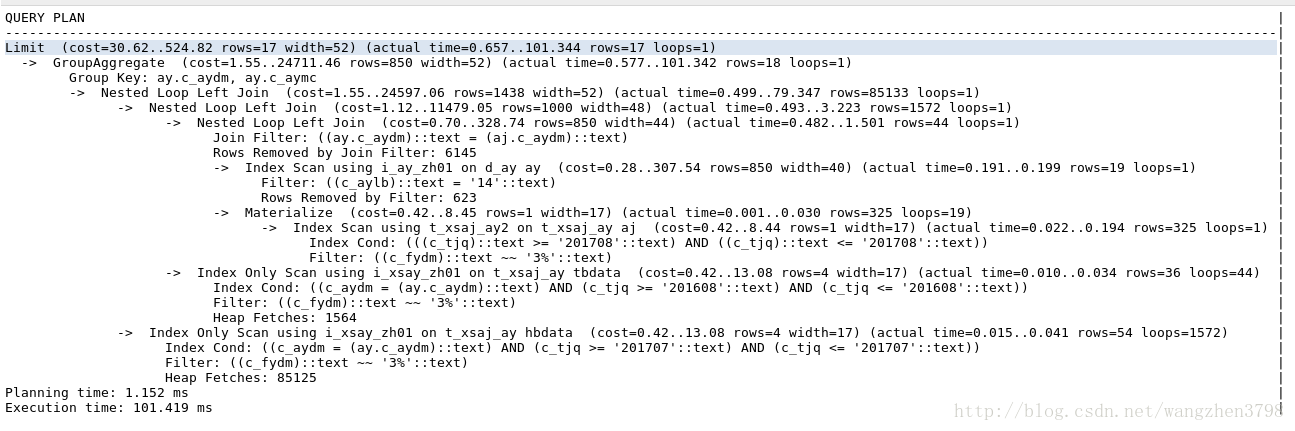
SQL执行时间100ms
初步排查结果正确性
select id,name,count(*) from ( --第二次重写SQL ) t group by t.id,t.name having count(*) >1
验证结果:
| id | name | count |
|---|---|---|
第三次调优
统计结果正确性怀疑正当我以为找到了SQL清晰性与效率兼顾的完美解决方案时,DBA团队刘国明对查询结果的正确性提出了质疑。
国明兄认为应该先group by再left join。
验证过程
单独取一类案由的现在、同比、环比案件数据。
1.用第二次改造后的SQL计算“宅基地使用权纠纷”的同比环比数据。
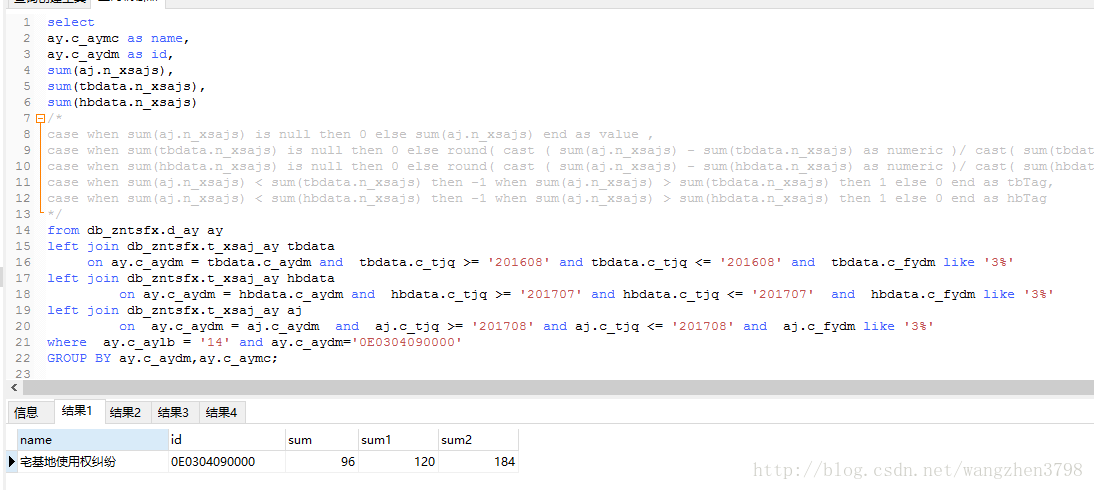
2.新SQL单独计算“宅基地使用权纠纷”的同比环比数据。
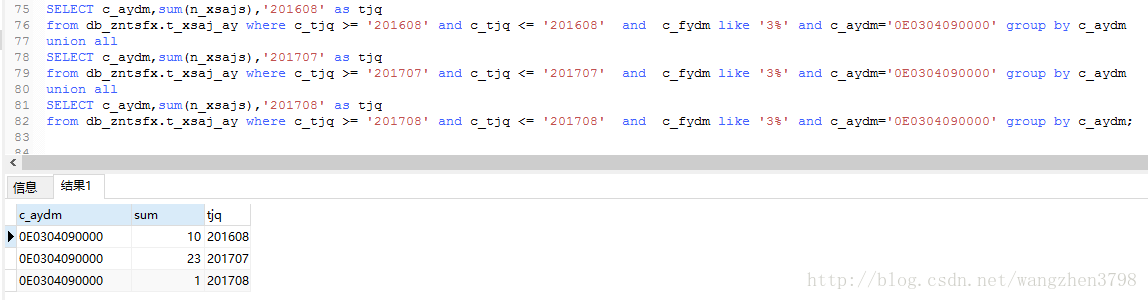
验证结果
改写后”完美SQL”的统计结果是错误的
反思
为什么改写后的SQL统计结果是错的呢?
答案:再看SQL执行计划发现,SQL改写统计错误的原因是,想当然认为同比、环比、和当前月数据是分别和主表d_ay 表进行左连接的,其实不是。其实是主表先和当前月结果集做笛卡尔积,这个结果集再和同比数据做笛卡尔积,新集合再和环比数据做笛卡尔积。导致数据重复。
正确的SQL
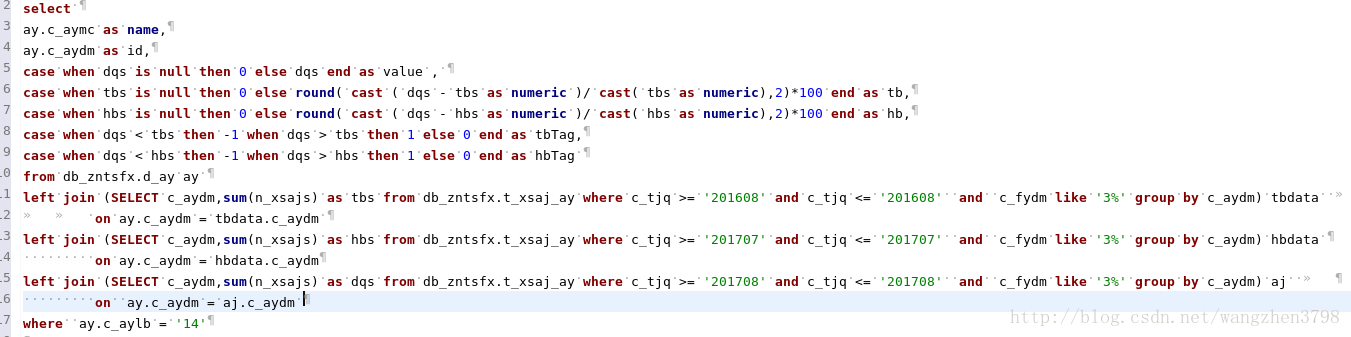
正确的执行计划
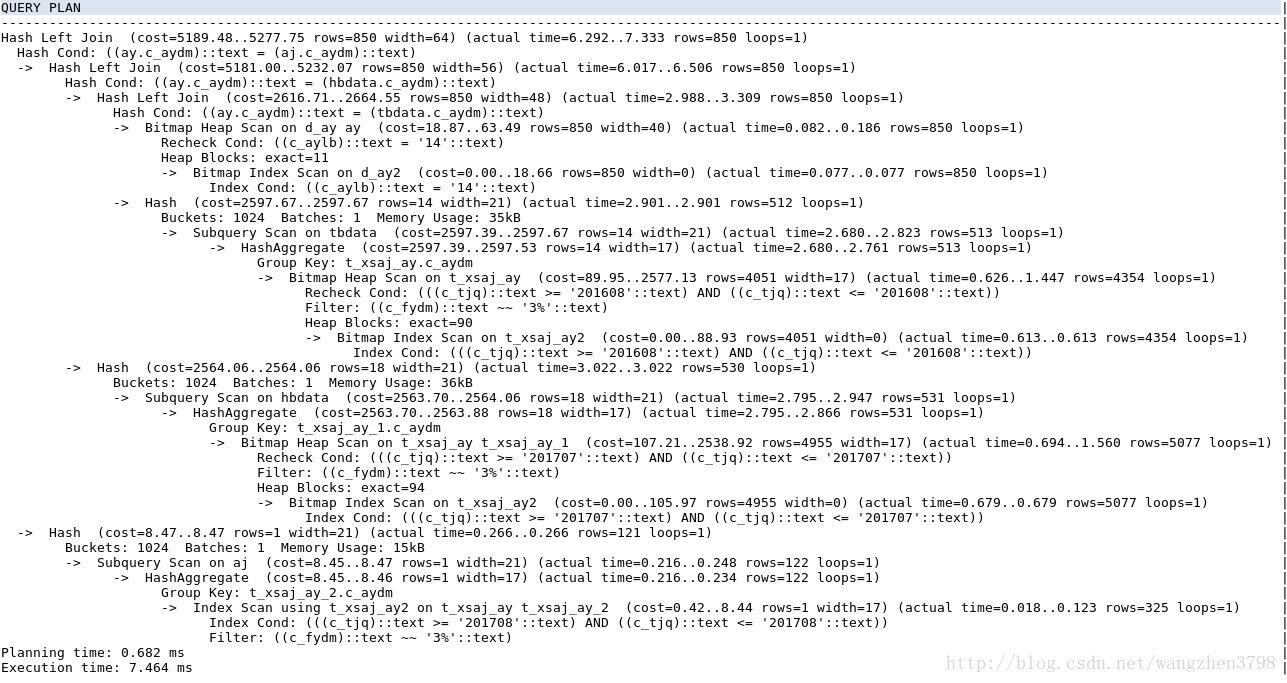
SQL执行时间:10ms以内(开发环境)
总结
在SQL优化过程中,需要经过格式化SQL、理解业务、查看执行计划、尝试索引、改写SQL甚至重新设计表结构等若干步骤,需要经过一次甚至多次的调优才能达到要求的性能标准。对于表的join顺序,不要想当然的认为SQL就是按照编写的顺序执行的。同时SQLFX平台发现很多项目的SQL存在大量join超过四张表的情况,随着数据量的增加这些SQL的笛卡尔积运算量必定成指数级增加,造成CPU和IO资源的紧张。希望项目组能重视这些SQL潜在的性能问题,希望SYBASE切换到ABASE,数据库平台升级带来的性能提升不要被程序中慢SQL所抵消掉,希望“安迪比尔定理”不要发生在我们身边。

相关文章推荐
- 一次非常有意思的 SQL 优化经历
- 一次非常有意思的 SQL 优化经历
- 记一次Oracle Sql优化经历--消耗过多CPU
- 一次非常有意思的 SQL 优化经历
- 一次非常有意思的sql优化经历
- 一次非常有意思的sql优化经历
- 一次非常有意思的sql优化经历
- 一次非常有意思的 SQL 优化经历
- [转]一次非常有意思的sql优化经历
- 一次非常有意思的sql优化经历
- 一次非常有意思的 SQL 优化经历
- 一次非常有意思的SQL优化经历
- 一次查询一条数据花费6分钟的SQL优化到0.05s的经历
- 一次非常有意思的 SQL 优化经历
- 一次非常有意思的sql优化经历
- 一次非常有意思的 SQL 优化经历
- 一次非常有意思的SQL优化经历
- 一次非常有意思的SQL优化经历:从30248.271s到0.001s
- 一次非常有意思的SQL优化经历
- 一次非常有意思的sql优化经历