redis集群实现(五) sentinel的架构与raft协议
2017-08-30 16:48
756 查看
Redis在3.0.0版本开始支持集群功能,但是实现集群就要求redis能够承受单点故障,保证redis的高可用性,在各种软件和硬件的故障情况下仍然能够提供服务。一般来说有两种解决思路,一种是每一个节点互相之间都会进行数据交互以及监控,出现故障的时候,各个节点都可以做协调任务,比如kv分布式存储cassendra。另一种就是增加一个协调组件来对集群进行实时监控以及故障处理,比如zookeeper,chubby等。现在使用比较广泛的是第二种方案,各个模块之间低耦合,工程师能够专注于自己本身的代码逻辑而不需要考虑太多方面,工程实现也比较简单(相对第一种而言)。
说到分布式协调组件,就不能不说下分布式一致性协议。从集中式变到分布式,虽然解决了单个主机宕机带来的服务不可用的问题,但是随之带来的就是分布式的各个节点一致性的问题。在分布式系统的一致性协议方面,paxos一直是标准级别的存在,但是由于paxos在工程实现上的困难,很少有人直接使用paxos协议来实现分布式中的协调组件。所以就有人提出了raft协议。和大名鼎鼎的paxos算法不一样,raft比较通俗易懂,在很多关键的地方甚至给出了伪代码。sentinel使用的就是raft协议,raft在redis内并没有用来实现一些分布式锁以及分布式事务,仅仅是用来做master宕机时的选主,可能后续的版本会逐渐支持。在redis内部有一个哨兵(sentinel)监测master和slave的状态,当有一个master节点宕机的时候,sentinel就会在剩下的slave中选择一个合适的节点作为master。这里有一个网址,非常浅显易懂的介绍了raft协议,希望大家看完后都能明白raft协议的精髓。
http://thesecretlivesofdata.com/raft/
这里也有raft协议的各种语言的实现,一并奉献出来。
https://raft.github.io/#implementations
了解了raft协议,我们就看一下redis的一致性解决方案sentinel的架构设计。sentinel被设计成为类似于chubby,zookeeper之类的一个独立于数据节点的协调组件,sentinel集群内的每一个节点都会监控集群内部的每一个节点的状态,并将定时交换监控的信息,如下图所示:
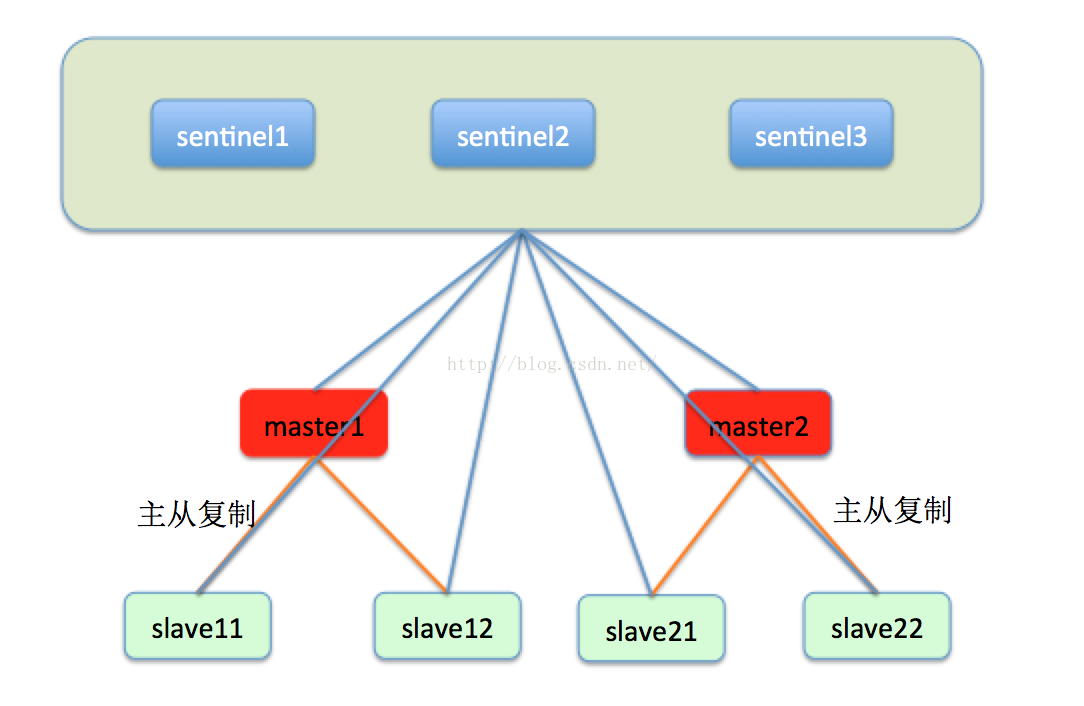
一般来说,sentinel都由五个节点组成,这样能够保证即使一台节点宕机还有四个节点可用,能够提供比较高的可用性和性能,而又不需要太多的节点。sentinel集群中的每一个节点都会实时的监控每一个master和slave,master和slave都会定期的向sentinel1,sentinel2,sentinel3汇报自己的状态。
sentinel在3.0.0版本内并没有提供分布式事务以及分布式锁等同步以及事务的功能,仅仅是提供了故障转移以解决节点宕机问题。我们来看下sentinel是怎么用raft协议来实现节点宕机处理的。
如果一台master节点,比如master1节点宕机下线,sentinel1发现master1没有汇报自己的状态,在sentinel内部有一个节点没有汇报的最长时间上线,当一个节点超出了这个时间上限,就会在本机标记此节点主观下线,就是说在本sentinel节点的视角来看,此节点是下线状态。如下图:
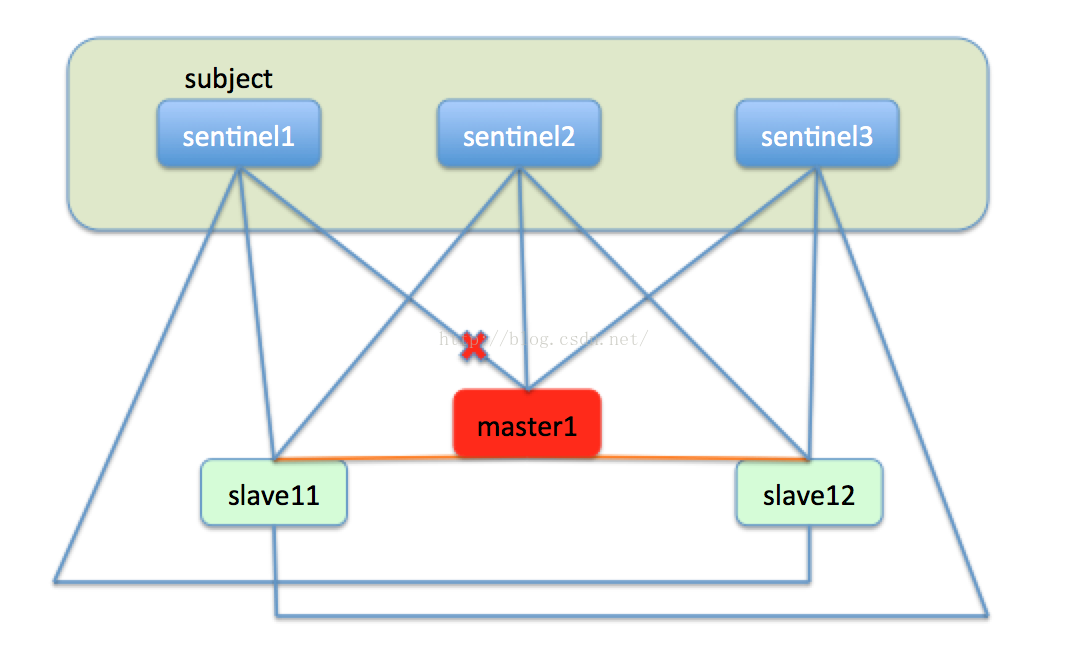
由于sentinel集群中有三个sentinel节点,只有sentinel1认为master1下线,这就仅仅是主观下线,还不能处理故障转移。然后过了一段时间,sentinel2也发现master1好久没有汇报信息,也把master1标记未主观下线。sentinel集群中的三台机器会定时交流自己的监控信息,当sentinel1发现sentinel2也认为master1主观下线了,就是说集群中有超过一半的节点认为节点下线了,这时sentinel集群就会达成一个一致,认为master1已经客观下线了。如下图:
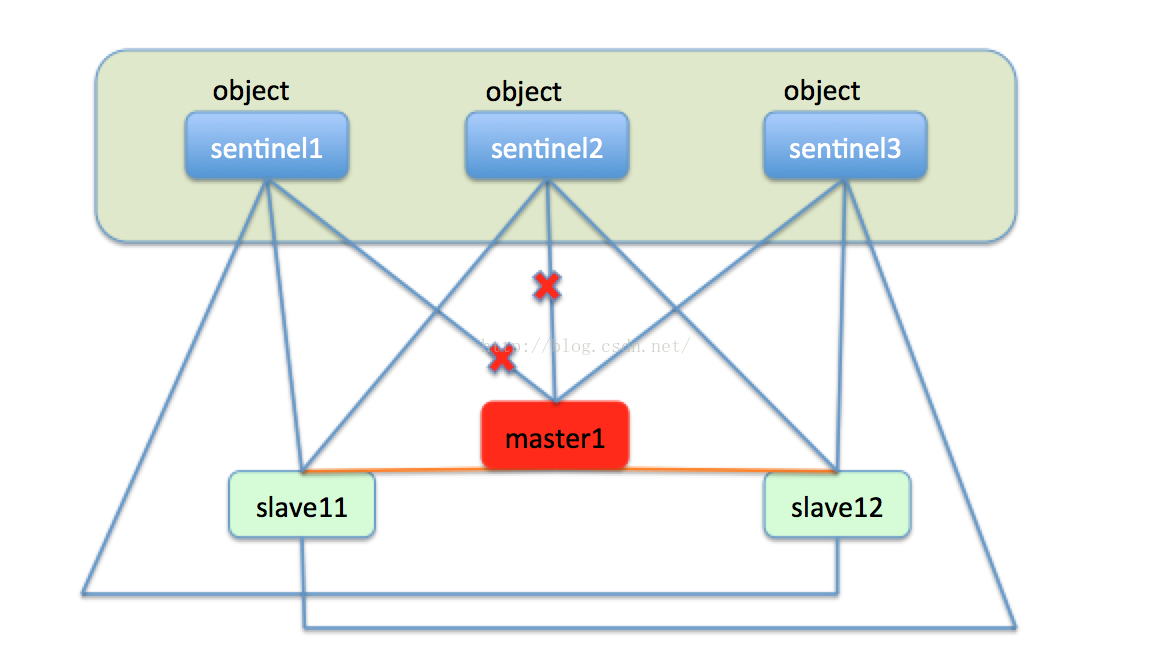
此时sentinel就会开始执行故障转移,在slave11和slave12中选出新的master节点。首先slave11和slave12变成候选者,等待一个0到1s内的随机值,然后向sentinel集群的每一个节点发送求票信息,希望能选举自己成为master,每一个sentinel只能投一次票,最终必然有一个节点成为新的master。比如slave11获取了sentinel1和sentinel2的选票,slave12获取了sentinel3的选票,最终的结果就是slave11成为master。如下图:
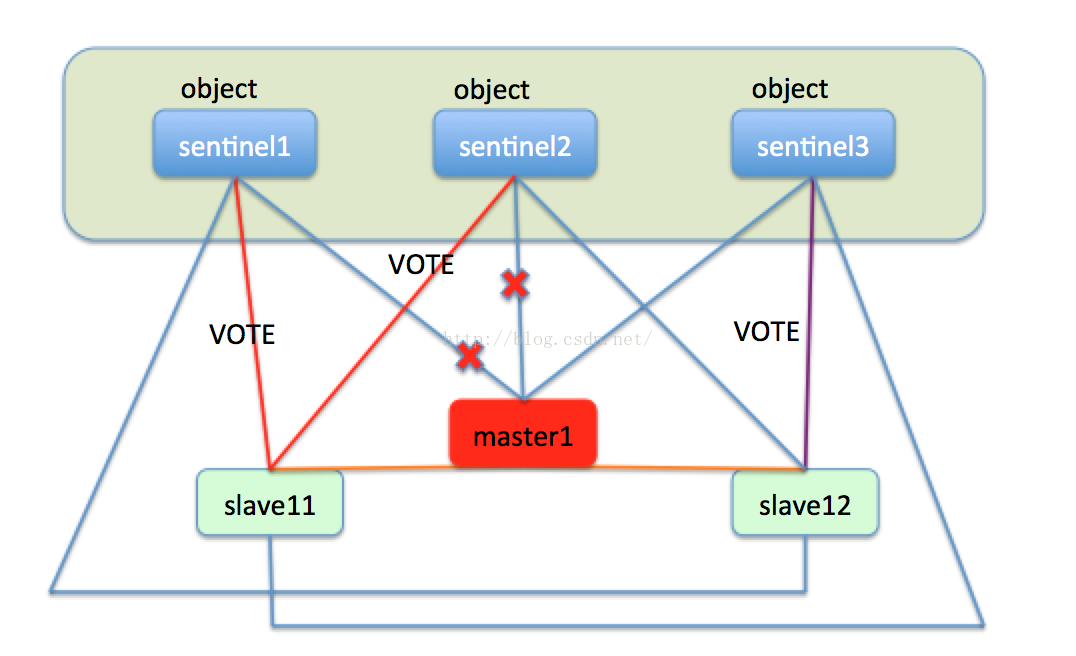
然后slave11成为master,slave12成为slave11的slave,转而向slave11进行主从复制。如下图:
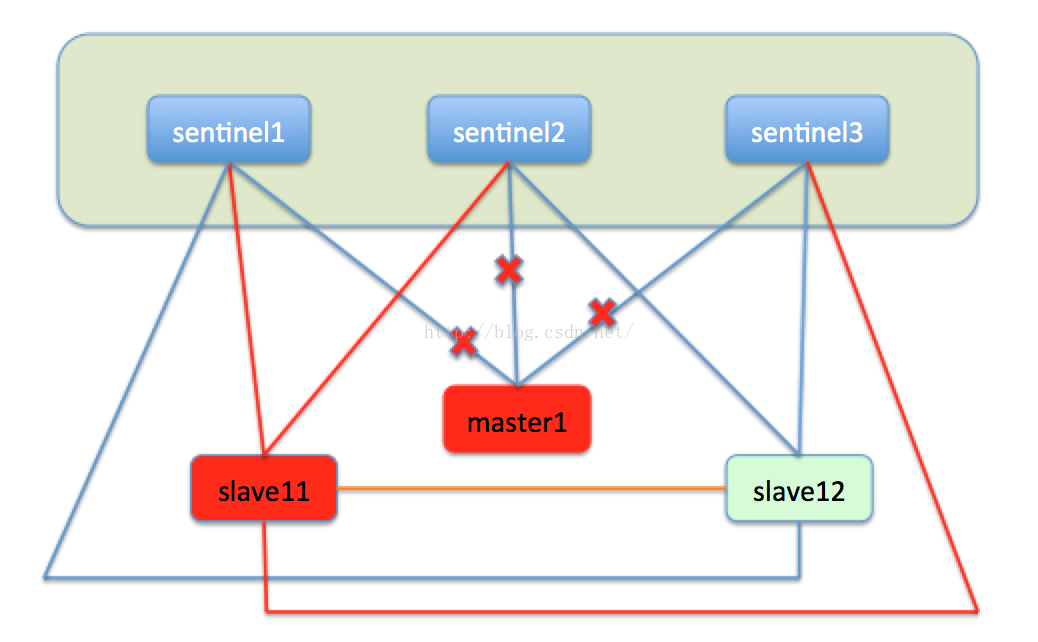
同时sentinel也会监视master1,如果master1经过修复后重新上线,这时的master就会变成slave11的从节点,转而向master进行主从复制。如下图:
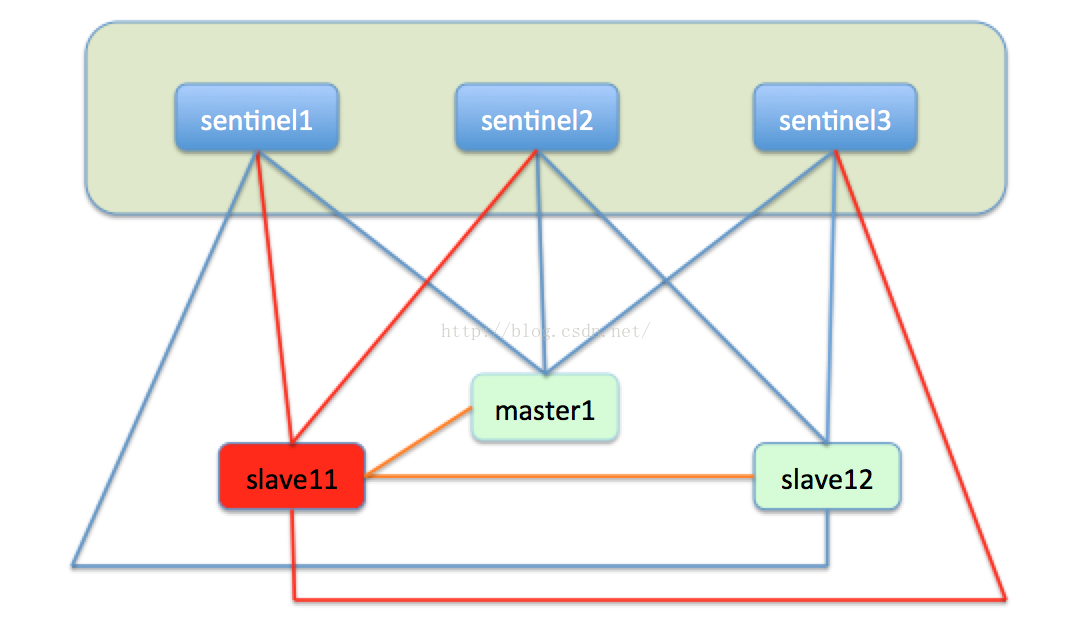
至此,redis的故障转移就完成了,redis利用比较易于实现的raft协议实现了节点宕机的自动化处理,保障了集群的高可用性。
说到分布式协调组件,就不能不说下分布式一致性协议。从集中式变到分布式,虽然解决了单个主机宕机带来的服务不可用的问题,但是随之带来的就是分布式的各个节点一致性的问题。在分布式系统的一致性协议方面,paxos一直是标准级别的存在,但是由于paxos在工程实现上的困难,很少有人直接使用paxos协议来实现分布式中的协调组件。所以就有人提出了raft协议。和大名鼎鼎的paxos算法不一样,raft比较通俗易懂,在很多关键的地方甚至给出了伪代码。sentinel使用的就是raft协议,raft在redis内并没有用来实现一些分布式锁以及分布式事务,仅仅是用来做master宕机时的选主,可能后续的版本会逐渐支持。在redis内部有一个哨兵(sentinel)监测master和slave的状态,当有一个master节点宕机的时候,sentinel就会在剩下的slave中选择一个合适的节点作为master。这里有一个网址,非常浅显易懂的介绍了raft协议,希望大家看完后都能明白raft协议的精髓。
http://thesecretlivesofdata.com/raft/
这里也有raft协议的各种语言的实现,一并奉献出来。
https://raft.github.io/#implementations
了解了raft协议,我们就看一下redis的一致性解决方案sentinel的架构设计。sentinel被设计成为类似于chubby,zookeeper之类的一个独立于数据节点的协调组件,sentinel集群内的每一个节点都会监控集群内部的每一个节点的状态,并将定时交换监控的信息,如下图所示:
一般来说,sentinel都由五个节点组成,这样能够保证即使一台节点宕机还有四个节点可用,能够提供比较高的可用性和性能,而又不需要太多的节点。sentinel集群中的每一个节点都会实时的监控每一个master和slave,master和slave都会定期的向sentinel1,sentinel2,sentinel3汇报自己的状态。
sentinel在3.0.0版本内并没有提供分布式事务以及分布式锁等同步以及事务的功能,仅仅是提供了故障转移以解决节点宕机问题。我们来看下sentinel是怎么用raft协议来实现节点宕机处理的。
如果一台master节点,比如master1节点宕机下线,sentinel1发现master1没有汇报自己的状态,在sentinel内部有一个节点没有汇报的最长时间上线,当一个节点超出了这个时间上限,就会在本机标记此节点主观下线,就是说在本sentinel节点的视角来看,此节点是下线状态。如下图:
由于sentinel集群中有三个sentinel节点,只有sentinel1认为master1下线,这就仅仅是主观下线,还不能处理故障转移。然后过了一段时间,sentinel2也发现master1好久没有汇报信息,也把master1标记未主观下线。sentinel集群中的三台机器会定时交流自己的监控信息,当sentinel1发现sentinel2也认为master1主观下线了,就是说集群中有超过一半的节点认为节点下线了,这时sentinel集群就会达成一个一致,认为master1已经客观下线了。如下图:
此时sentinel就会开始执行故障转移,在slave11和slave12中选出新的master节点。首先slave11和slave12变成候选者,等待一个0到1s内的随机值,然后向sentinel集群的每一个节点发送求票信息,希望能选举自己成为master,每一个sentinel只能投一次票,最终必然有一个节点成为新的master。比如slave11获取了sentinel1和sentinel2的选票,slave12获取了sentinel3的选票,最终的结果就是slave11成为master。如下图:
然后slave11成为master,slave12成为slave11的slave,转而向slave11进行主从复制。如下图:
同时sentinel也会监视master1,如果master1经过修复后重新上线,这时的master就会变成slave11的从节点,转而向master进行主从复制。如下图:
至此,redis的故障转移就完成了,redis利用比较易于实现的raft协议实现了节点宕机的自动化处理,保障了集群的高可用性。

相关文章推荐
- redis集群实现(五) sentinel的架构与raft协议
- 分布式架构学习之:使用Redis3.0集群实现Tomcat集群的Session共享
- Raft协议实战之Redis Sentinel的选举Leader源码解析
- 高性能网站架构之负载均衡的Nginx + tomcat的+ Redis的实现tomcat的集群
- 高性能网站架构之负载均衡 Nginx+tomcat+redis实现tomcat集群
- redis集群部署sentinel—两台服务器实现
- redis集群实现(七)sentinel数据结构和初始
- twemproxy + redis + sentinel 实现redis集群高可用
- redis集群实现(七)sentinel数据结构和初始
- 第一章:Redis+twemproxy+keepalive+ sentinel实现完整的redis集群方案实验
- Raft协议实战之Redis Sentinel的选举Leader源码解析
- 实现redis(主从,sentinel,cluster)的主从复制集群
- redis集群实现(一)集群架构与初始化
- 集群与负载均衡系列(8)——redis主从复制+哨兵实现高可用性架构
- Spring整合Redis-sentinel集群实现03
- redis集群实现(一)集群架构与初始化
- 高性能网站架构之负载均衡 Nginx+tomcat+redis实现tomcat集群
- Redis+Sentinel 实现redis集群高可用
- 分布式架构学习之:032--使用Redis3.0集群实现Tomcat集群的Session共享
- 高性能网站架构之负载均衡 Nginx+tomcat+redis实现tomcat集群