全文检索之sphinx源码分析--索引创建流程
2017-08-23 21:40
555 查看
sphinx是c++语言编写的一个开源全文检索项目,索引文件创建速度和检索速度都是不错的。由于公司的项目需要我对其源码进行了解读,并在其上进行了一定程度的改写以适应项目检索提速的需求。这篇文章就是我对sphinx源码的解读心得,sphinx基于2.1.9版本。
大体上来讲sphinx分成indexer和searchd两个最主要的进程,indexer负责创建索引文件,searchd负责接收网络包并进行检索返回结果,当有新的索引文件生成或者旧的索引文件发生了变更(如merge了新的数据)则indexer会通过轮转的方式通知searchd。轮转这个操作就是将索引文件mv成一个.new文件(如有索引文件名为hour.sp*,会被mv成hour.new.sp*),然后向searchd发送一个SIGHUP信号,由searchd接收信号后将.new文件mv回原格式,然后更新自己的维护列表。这其中indexer是通过创建之初就提供给他的一个.conf配置文件知道searchd的pid存放文件路径的。
一个索引文件分为几个主要的子文件,仍然以hour索引为例,通常会有如下几个最主要的文件:
spa 存储文档属性,仅在extern存储模式中使用,用于存储hit信息。
spd 存储每个wordID可匹配的docID列表,这是我们检索的核心文件,通过该文件可以用关键字检索到对应的docID。
spi 存储词列表(词ID和指向.spd文件的指针),可以认为是在spd上的二级索引,检索时先遍历spi得到word在spd上的范围。Spi分为dict和checkpoint两部分,dict为具体每个word的wordid、doc数、hit数等等信息,而checkpoint则每128个word记录一个wordID和该word在spi上的位置。
sph 存储索引头信息,除了必要配置信息外还存了checkpoint在spi上的位置
spe存储skip-lists,skip-lists可以认为是在hits记录(spp)上的二级索引。如果不存储hits则spp文件大小为0。
spp 存储每个词ID的hit(或者说记账,或者词的出现)列表,如果在conf配置文件里配置hitless=all则大小为0。
上面涉及了几个名词docID是一行的标记,可以认为是mysql里一行数据的id,wordID是关键字转化的一个哈希值,hit不太好理解,可以认为是一个关键字在一行记录里的具体位置,例如关键字pokeman出现在mysql某一行的记录中位置为第3个字段的第5个字符,则hit可能为0000000300000005这样的格式,当然这只是个例子,具体格式肯定不是这样的。这里的docID、wordID、hit就是sphinx的核心三元组
关于这核心三元组和几个核心文件的关系可以看这个图:
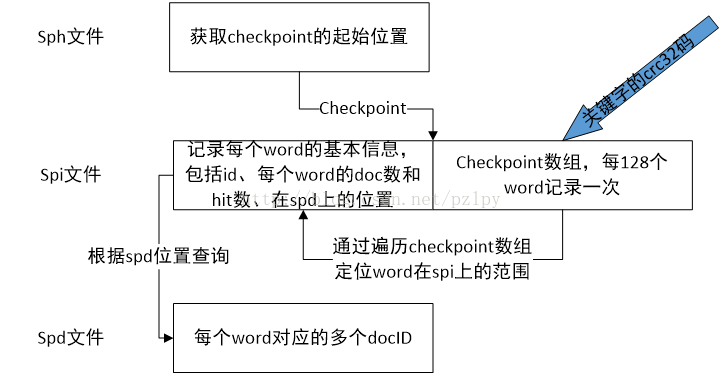
sph作为头文件只存了一些基本信息如分词器信息、文件大小、checkpoint位置等等,而spi存了一个有序的关键字的序列,每次检索的时候就是根据这个关键字在spi里看到底这个字是否命中了,有命中才会去spd文件里找具体命中了哪个document。这张图还省略了spe和spa文件,会将关键字出现的具体位置也返回出来。
索引文件的创建流程如下,创建流程最为核心的是cidxHit函数,该函数实现了将每一个hit压缩到对应文件的功能:

大体上来讲sphinx分成indexer和searchd两个最主要的进程,indexer负责创建索引文件,searchd负责接收网络包并进行检索返回结果,当有新的索引文件生成或者旧的索引文件发生了变更(如merge了新的数据)则indexer会通过轮转的方式通知searchd。轮转这个操作就是将索引文件mv成一个.new文件(如有索引文件名为hour.sp*,会被mv成hour.new.sp*),然后向searchd发送一个SIGHUP信号,由searchd接收信号后将.new文件mv回原格式,然后更新自己的维护列表。这其中indexer是通过创建之初就提供给他的一个.conf配置文件知道searchd的pid存放文件路径的。
一个索引文件分为几个主要的子文件,仍然以hour索引为例,通常会有如下几个最主要的文件:
spa 存储文档属性,仅在extern存储模式中使用,用于存储hit信息。
spd 存储每个wordID可匹配的docID列表,这是我们检索的核心文件,通过该文件可以用关键字检索到对应的docID。
spi 存储词列表(词ID和指向.spd文件的指针),可以认为是在spd上的二级索引,检索时先遍历spi得到word在spd上的范围。Spi分为dict和checkpoint两部分,dict为具体每个word的wordid、doc数、hit数等等信息,而checkpoint则每128个word记录一个wordID和该word在spi上的位置。
sph 存储索引头信息,除了必要配置信息外还存了checkpoint在spi上的位置
spe存储skip-lists,skip-lists可以认为是在hits记录(spp)上的二级索引。如果不存储hits则spp文件大小为0。
spp 存储每个词ID的hit(或者说记账,或者词的出现)列表,如果在conf配置文件里配置hitless=all则大小为0。
上面涉及了几个名词docID是一行的标记,可以认为是mysql里一行数据的id,wordID是关键字转化的一个哈希值,hit不太好理解,可以认为是一个关键字在一行记录里的具体位置,例如关键字pokeman出现在mysql某一行的记录中位置为第3个字段的第5个字符,则hit可能为0000000300000005这样的格式,当然这只是个例子,具体格式肯定不是这样的。这里的docID、wordID、hit就是sphinx的核心三元组
关于这核心三元组和几个核心文件的关系可以看这个图:
sph作为头文件只存了一些基本信息如分词器信息、文件大小、checkpoint位置等等,而spi存了一个有序的关键字的序列,每次检索的时候就是根据这个关键字在spi里看到底这个字是否命中了,有命中才会去spd文件里找具体命中了哪个document。这张图还省略了spe和spa文件,会将关键字出现的具体位置也返回出来。
索引文件的创建流程如下,创建流程最为核心的是cidxHit函数,该函数实现了将每一个hit压缩到对应文件的功能:

相关文章推荐
- 全文检索之sphinx源码分析--检索流程
- 全文检索之sphinx源码分析--配置文件和轮转操作
- 全文检索之sphinx源码分析--优化(二)
- Sphinx创建全文检索的索引
- 关于Sphinx创建全文检索的索引介绍
- 关于Sphinx创建全文检索的索引介绍
- hadoop源码解析之hdfs写数据全流程分析---创建文件
- [Android源码分析]蓝牙打开流程分析——jni层之下的偷偷摸摸(Service Record的创建)
- lucene全文搜索之四:创建索引搜索器、6种文档搜索器实现以及搜索结果分析(结合IKAnalyzer分词器的搜索器)基于lucene5.5.3
- Spring 源码分析《Bean的获取与创建流程》
- Android 7.0 虚拟按键(NavigationBar)源码分析 之 View的创建流程
- lucenc.net 全文检索 创建索引、 查询、分页
- sphinx+scws 全文检索使用之 sphinx配置增量索引及sphinx管理命令
- CloudStack 创建VM 源码流程分析
- dubbo源码分析-consumer端3-Invoker创建流程
- lucene4.5源码分析系列:索引的创建过程
- dubbo源码分析-consumer端3-Invoker创建流程
- 手动创建索引及全文检索
- sphinx索引分析——文件格式和字典是double array trie 检索树,索引存储 – 多路归并排序,文档id压缩 – Variable Byte Coding
- 全文检索Lucene入门之创建索引及简单搜索